
基于编码知识的关键字搜索在电子数据取证中的应用
2020-02-14 05:58程琳
计算机时代 2020年1期
程琳

摘 要: 随着计算机技术和网络技术的飞速发展,电子数据在证明案件事实、扩展侦查线索等方面起着越来越重要的作用。电子数据取证过程中,往往要对存储介质底层数据进行分析,而字符编码分析、基于编码知识的关键字搜索查询则是其中的重要工作之一。本文结合常见编碼特点和文件系统存储原理,从文件名搜索、文件内容搜索、邮件内容搜索三个方面对搜索方法进行分析总结。基于编码知识的关键字搜索能够有效的解决电子数据取证工作中目标区域关键字的存在性问题,提高取证工作的效率。
关键词: 电子数据取证; 编码知识; 文件名搜索; 文件内容搜索; 邮件内容搜索
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2020)01-43-04
Abstract: With the rapid development of computer technology and network technology, digital data plays an increasingly important role in proving the authenticity of cases and expanding investigation clues. The underlying data of storage medium often needs to be analyzed in the process of digital forensics, while character coding analysis and keyword search based on coding knowledge are one of the important things. Combining with the common coding characteristics and file system storage principle, this paper analyzes and summarizes the search methods from three aspects: file name search, file content search and mail content search. The coding knowledge based keyword search can effectively solve the problem of keyword existence in the target area of digital forensics and improve the efficiency of the digital forensics work.
Key words: digital forensics; coding knowledge; file name search; file content search; email content search
随着信息技术的不断发展和法律制度的不断完善,电子数据取证在各类案件中的重要性日益凸显[1]。电子数据取证与鉴定在司法实践中的应用越来越多,涉及到的行业领域也越来越广[2]。在电子数据取证过程中,结合取证工具,灵活运用相关知识,对取证介质进行底层的数据分析具有非常重要的意义。
编码是不同国家的语言在计算机中的一种存储和解释规范。用户可以在不知道编码的原则及方法的情况下使用计算机,但对于电子数据取证从业人员来讲,学习和掌握编码知识是至关重要的,字符编码、文件存储原理等知识的不足有可能造成对电子数据分析不够全面透彻,也有可能错失一些线索。在电子数据取证过程中,关键字搜索查询是一项重要的常规工作,只有理解和掌握相关知识,熟悉字符集的各项标准,理解大小端字节顺序,理解文件系统存储原理,确定正确的搜索和解析方案,才能从数据底层进行分析判断,从而发现线索,解决相关问题。
1 编码基础知识
1.1 常见字符编码
ASCII码即美国信息交换标准码,是使用最广泛的编码之一,适用于所有的拉丁文字字母。ASCII码可以表示128个字符,其中包括数字0-9、大小写英文字母、标点符号、运算符和控制码等。
我国于1980年制定了国家标准GB2312-80《信息交换用汉字编码字符集·基本集》。GB2312收录了绝大部分常用汉字,得到了最广泛的支持,但是它并不包含人名、古汉语等方面出现的罕用字。
GBK是双字节表示的汉字内码扩展规范,它的收录范围包括GB2312中的全部符号、BIG5中的全部汉字、与ISO 10646相对应的国家标准GB13000中的其它CJK汉字等。
GB18030可以看成GBK的超集,它的收录范围扩展到国内少数民族的文字、繁体汉字以及日韩汉字,编码空间庞大。从ASCII、GB2312、GBK到GB18030,这些编码方法是向下兼容的。
Unicode是国际组织制定的字符编码方案,能够使计算机实现跨语言、跨平台的文本转换及处理。UTF-8是在互联网上使用最广泛的一种Unicode实现方式,它由Unicode编码变形而来。Unicode对应UTF-8编码方式如表1所示。
1.2 邮件编码
早期的一些邮件传输协议不允许在邮件消息中使用ASCII码字符集以外的字符。MIME(Multipurpose Internet Mail Extensions)扩展了电子邮件标准,使其能够支持非ASCII字符文本、非文本格式的附件等多种格式的邮件消息。Base64与QP(Quoted-Printable)是两种基本的MIME内容传输编码。
Base64的原理是将一组连续的字节数据按6个bit位进行分组,每组数据用一个ASCII字符来表示。具体实现时使用64个ASCII字符来对应这64个数值,这64个ASCII字符为:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/,这样将二进制数据转换成可打印的ASCII字符。
QP编码的原理与Base64不同,它对ASCII字符不进行转换,只对非ASCII字符的数据进行编码转换,每个非ASCII字符的字节数据,都被转换成一个“=”号后跟这个字节的十六进制数据。
1.3 字节顺序
字节顺序是指内存中字节的排列,操作系统并不负责指定字节顺序,字节顺序是基于CPU技术的[3]。通常有小端、大端两种字节顺序。在小端字节序中,高字节数据存放在内存高地址处,低字节数据存放在内存低地址处,而大端字节序正好相反。例如编码“6C49”,对应的大端存储顺序为“6C49”,而小端存储顺序则是“496C”,大端和我们从左到右的习惯是一致的,小端则不同。在取证分析中要搞清楚数据是以什么样的字节顺序存储的,读取时要按照相应的字节顺序读取,这样才能保证解析出来的数据准确无误。
2 文件名关键字搜索
文件名關键字搜索是介质取证中非常重要的一部分内容,对于系统中不能正常显示或打开的文件,以及彻底删除的文件,在存储介质的底层数据中利用字符编码知识及文件系统存储原理查找文件名的存储管理项目,从而找到文件的存储位置,在没有被新的数据覆盖之前可以提取文件内容。
2.1 FAT32文件系统文件名搜索
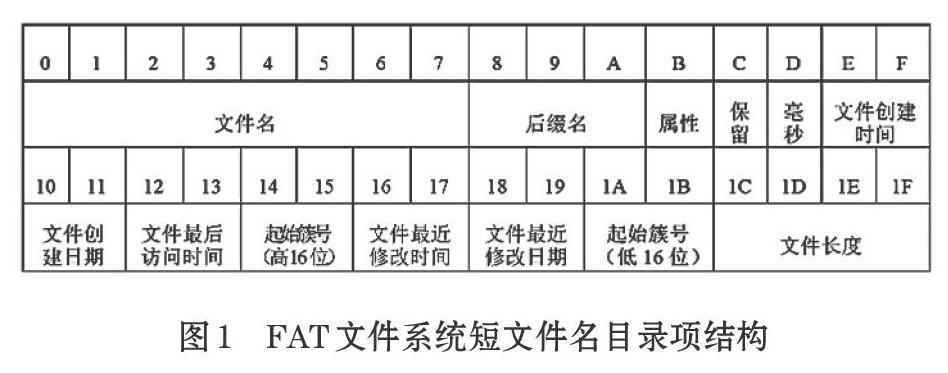
FAT32文件系统中,每个文件或目录都分配有一个大小为32字节的短文件名目录项,即文件目录表FDT,用以描述文件或目录的属性。短文件名目录项具体的记录方式如图1,它记录着文件的文件名、扩展名、起始存储单元、文件的属性、文件的大小、创建时间等信息。
短文件名目录项的偏移0-7字节记录文件的主文件名,8-A字节记录文件的扩展名,取GBK码值。主文件名与扩展名之间的“.”不予记录,主文件名不足8个字符、扩展名不足3个字符均以空白字符20H填充。文件删除后,短文件名目录项0偏移处的值变为E5H。
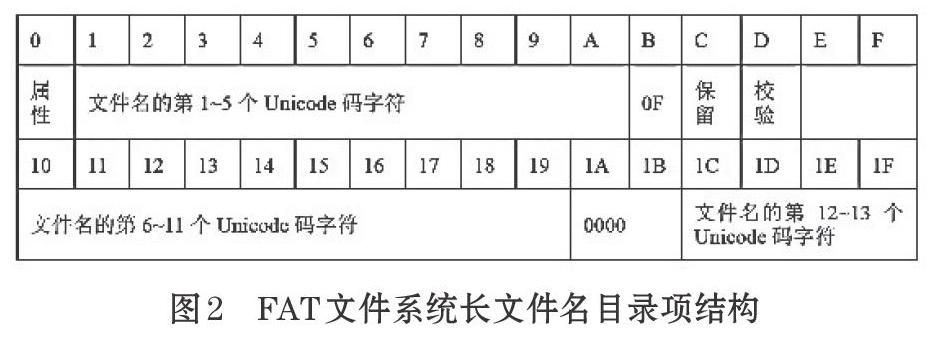
当文件名超过8个字符,系统取前6个加上“~1”形成短文件名,扩展名不变,同时在短文件名目录项的前方创建相对应的长文件名目录项。长文件名目录项采用Unicode编码记录完整的文件名。一个长文件名目录项能记录13个Unicode字符,若超过13个,系统会在此目录项的前方再增加一个两行的长文件名目录项,如果还不够则继续增加,直到能够存储下文件的完整文件名为止。多个长文件名目录项代表同一个文件,它们之间就会存在一个校验和,通过这个校验和,可以将其与对应的短文件名目录项关联起来[4]。长文件名记录格式如图2所示。
2.1.1 短文件名关键字搜索方法
根据短文件名目录项存储原理,短文件名在存储时采用的是GBK编码,如果文件名中含有英文字符,不论用户设置的是大写还是小写,在短文件名目录项中存储的都是大写,搜索时应先将短文件名中的英文字母转化为大写,再获取短文件名的GBK编码,文件已删除则将第一个字节改为E5。例如硬盘上原来存储有某公司的财务报表,对应名称为“恒胜科技公司第一季度财务报表.xlsx”,已被删除,可以采用短文件名搜索,短文件名存储取前三个汉字,后面加上“~1”,同时英文字符转化为大写,即为“恒胜科~1.XLS”,删除后文件目录项首字节变为E5H,因此在搜索时应将搜索条件设为“E5E3CAA4BFC67E31584C53”。根据此搜索条件找到已删除文件的目录项,同时结合文件分配表即可找到文件的存储簇链,在此位置如果没有写入新的数据,则可以提取被删文件的内容。
2.1.2 长文件名关键字搜索方法
根据长文件名目录项的记录规则,1个长文件名目录项存储13个文件名字符,并采用Unicode编码[5]。需注意在长文件名目录项的两行数据中记录的文件字符位置不完全连在一起。在搜索过程中,可以根据规则来构建长文件名目录项。
若有某公司四个季度的财务报表,名称分别为“恒胜科技公司第一季度财务报表.xlsx、恒胜科技公司第二季度财务报表.xlsx、恒胜科技公司第三季度财务报表.xlsx、恒胜科技公司第四季度财务报表.xlsx”,四个文件已被删除。欲搜索“恒胜科技公司第三季度财务报表.xlsx”,可采用如下策略进行长文件名搜索,首先获取文件名的Unicode编码“5260DC80D 17980626C51F8532C7B094E635BA65E228DA152A56268882E0078006C0073007800”,接着构建它的长文件名项目,将文件名的第1-5、6-11、12-13个字符的编码复制到对应位置,文件若已删除,第0字节改为E5,其余地方填充3F,最后搜索的十六进制数值为“E55260DC80D17980626C513F3F3FF8532C7B094E635BA65E228D3F3FA152A562”,3F在搜索时作为通配符出现。找到长文件名目录之后,紧挨着的下方是短文件名目录项,真正有价值的是短文件名目录项中文件存储的起始位置,同理,结合文件分配表可以提取文件数据内容。
以上搜索时需要注意的是,如果在不同目录下存在同名文件,则要首先搜索父目录的文件名,找到对应存储簇号,再转到相应的簇,在此簇中搜索已删除的文件名。理解短文件名、长文件名所采用的编码及存储原理后,可以根据情况灵活设置搜索条件,找到所需要的数据。
2.2 NTFS文件系统文件名搜索
NTFS分区中设置了一个文件管理机构,即主控文件表MFT,所有的文件相关的信息都保存在MFT中。NTFS文件系统视每个文件为一个文件属性的集合,文件名、文件大小、文件的父目录、文件时间标记等都是文件的属性。MFT是一个与文件相对应的文件属性数据库,它记录了除文件数据信息以外的属性,甚至当文件内容很短时,其内容直接在MFT的数据属性中存放[6]。
在NTFS文件系统定义的主要文件属性中,30H属性用于存储文件名,80H属性存储文件数据相关信息。30H属性结构如图3所示。通过搜索文件名找到30H属性位置,紧挨着下方可以找到80H属性中的文件数据或数据存储索引。
例如搜索已经删除的文件“恒胜科技公司第三季度财务报表.xlsx”,可以先定位到$MFT的位置,再查找文件名对应的Unicode编码“5260DC80D 17980626C51F8532C7B094E635BA65E228DA152A56268882E0078006C0073007800”,定位到要找的文件记录位置,再通过其80H属性找到数据运行,最后确定文件存储的簇号索引。在搜寻一个文件记录项的时候,除了判断是否是合法的文件记录项外,还要判断搜寻的文件所处的文件夹位置是否正确。可以先记下搜寻文件的父目录名,然后搜寻到父目录的文件记录项,记下MFT编号,再搜寻文件的MFT记录项,查看30H属性中父目录的编号是否和记下的一致,如果一致则说明找到的文件正确。
3 文件内容搜索
文件内容搜索是存储介质目标区域取证的一项常规工作,很多时候我们需要搜索存储介质中底层的文件内容,根据常用的编码特点和相关知识可以构造一个查询字典,以提高查询的成功率。例如,我们需要查询一个硬盘的文件内容中是否存在关键字“望江西路559号”,可采用如下方法进行搜索:
使用“望江西路559号”GBK编码的16进制值:CDFBBDADCEF7C2B7353539BAC5;
使用“望江西路559号”Unicode编码的16进制值:671B6C5F897F8DEF00350035003953F7;
使用“望江西路559号”UTF-8编码的16进制值:E69C9BE6B19FE8A5BFE8B7AF353539E58FB7。
数字和英文字符如果采用的是全角字符,则要采用以下编码:
使用“望江西路559号”GBK编码的16进制值:CDFBBDADCEF7C2B7A3B5A3B5A3B9BAC5;
使用“望江西路559号”Unicode编码的16进制值:671B6C5F897F8DEFFF15FF15FF1953F7;
使用“望江西路559号”UTF-8编码的16进制值:E69C9BE6B19FE8A5BFE8B7AFEFBC95EFBC95EFBC99E58FB7。
具体搜索过程中,字符编码应灵活设置,同时考虑多种因素,如各种编码特点、全半角字符、大小端字节序、空格等。
4 邮件内容搜索
在Internet电子邮件标准MIME中,主要有两种编码方式:Base64与QP编码。例如,我们需要查询邮件中是否存在关键字“望江西路559号”,可将编码分成常见的这两类来查询。
4.1 Base64编码
Base64编码原理是将3个8位字节的数据转化为4个6位字节的数据,如果8位字节数据的字节个数不能被3整除,在最后添加几个为0的bit位来凑成6个bit位;如果编码后文本的字符个数不是4的整数倍,则需在最后填充“=”字符来凑成4的倍数。
将关键字“望江西路559号”转换为GBK编码,CDFBBDADCEF7C2B7353539BAC5,根据此GBK编码我们可以生成三个特征编码。若从开始部分到此关键字的字节数刚好为3的整数倍,将它转换为编码zfu9rc73wrc1NTm6xQ==,因为不知道关键字后面的字符,最后的Q有可能会参与下一个字节的编码,所以我们去掉“Q==”,最后采用的第一个特征编码为:zfu9rc73wrc1NTm6x;若从开始部分到此关键字的字节数除以3余数为1时,“望”与前面的字符构成一组三字节并进行编码,直接取“江西路559号”对应的Base64编码va3O98K3NTU5usU=,同理取第二个特征编码va3O98K3NTU5us;若从开始部分到此关键字的字节数除以3余数为2时,“望”的高位字节与前面的字符构成一组三字节并进行编码,则使用第三个特征编码+72tzvfCtzU1ObrF。
4.2 QP编码
QP编码原理相对简单,对ASCII字符不进行转换,非ASCII字符的字节数据转换成“=”号后跟这个字节的十六进制数据。根据它的编码原理,关键字“望江西路559号”使用GBK编码转换成QP编码,为“=CD=FB=BD=AD=CE=F7=C2=B7559=BA=C5”,使用UTF-8编码转换成QP编码,则是“=E6=9C=9B=E6=B1=9F=E8=A5=BF=E8=B7=AF559=E5=8F=B7”。
5 结束语
基于不同编码方式的关键字搜索查询是电子数据取证中底层数据分析的重要部分,不同的编码方式、不同的存储原理对应不同的搜索方法。本文在常见编码特点和文件存储原理的基础上,对文件名搜索、文件内容搜索、邮件内容搜索进行了分析总结,本文不可能分析所有编码,而是为相应的搜索方法提供了思路。当有新的编码方式,必须深入研究编码方式和对应的存储原理,找到对应的搜索方法,才能够提高查询的准确度和成功率。
參考文献(References):
[1] 刘金波,郝万里,麦永浩.电子数据取证的复杂度研究[J].计算机科学,2016.(B12):127-129
[2] 金波,杨涛,吴松洋等. 电子数据取证与鉴定发展概述[J]. 中国司法鉴定,2016.1:62-74
[3] 刘浩阳.字节顺序在计算机取证中的应用[J].警察技术,2012.2:43-45
[4] 刘伟.数据恢复技术深度揭秘(第二版)[M].北京:电子工业出版社,2016.
[5] 黄步根,赵兵.关键词搜索漏判研究[J].信息网络安全,2013.4:70-71
[6] 高洪涛,李孟林,赵璇元.基于NTFS文件系统的数据恢复编程技术[J].信息安全与技术,2015.6:33-36
