
基于人工智能的电商大数据分类与挖掘算法
2020-02-04 06:33:14宋广科
电子技术与软件工程 2020年21期
宋广科
(广东女子职业技术学院应用设计学院 广东省广州市 511450)
1 电商大数据应用模式
随着电商产业的不断发展,电商数据源出现了内容丰富化、结构复杂化的特点。采用传统的数据收集、存储、分析和应用模式,则难以适应新时期电商大数据的应用需要。基于此,人们要求建立与电商产业向适应的信息数据平台。从数据来源来看,在传统BI数据模式下,内部操作系统、管理系统是平台数据的主要来源;而在大数据时代下,企业经营数据的来源本身具有丰富性的特点,在多种数据来源中,互联网是大数据时代下电商数据的主要来源。相比于传统的经营管理及数据处理模式,大数据时代下的电商数据在收集、存储、分析处理和应用上具有较大差异。
为满足电商产业发展需要,越来越多的企业开始构建电商大数据平台;该平台一般包含外部数据和内部数据两个数据源。就外部数据源而言,其主要指的是超文本、图像、视频等网络上的非结构数据;而内部数据源包含多种类型,除电商经营CA 系统、ERP 系统外,电商企业财务报表系统等都是其数据的主要来源。在电商大数据平台应用中,工作人员一般会采用互联网网页爬虫的方式,实现各类数据的全方位采集;同时其会通过分布式文件和数据库的形式完成数据存储;在数据存储、分析和应用中,需要对各类数据进行深层次的挖掘和分类,结构化数据和非结构化数据在处理过程中存在一定的差异,有必进行不同类型数据算法和分类方式分析。值得注意的是,在新时期,人们对于电商大数据挖掘和分类的人工智能程度提出了较高要求,这要求在具体操作中,深化技术应用,实现电商大数据挖掘和分类的智能化发展。
2 电商大数据的挖掘算法分析
与以往相比,电商大数据的信息来源范围较广,信息形式较为复杂,这使得信息挖掘的难度较大。为实现电商大数据的快速挖掘和处理,本研究在会出要注重两个层面的要点把控:其一,在对电商大数据进行挖掘处理前,应先建立必要的维度控制机制,这样能在获取节点数据后,实现这些数据信息的有效分割,继而使得数据在分布时处于离散状态,为高维度数据的挖掘提供有效支撑。其二,在进行数据挖掘过程时,要较为快速的形成所挖掘数据的对应集合,提升数据挖掘精度,还必须建立Spark 机制,以此来解决以往数据挖掘中数据信息冗余的问题。
2.1 建立维度控制机制
建设数据模型树是补充并完善电商大数据维度控制机制的重要方式。对于电商企业而言,准确获取用户信息对于自身决策和经营管理工作的开展具有深刻影响。对此,有必要在电商大数据管理中,建立必要的用户信息模型树,以此来实现用户行为的有效挖掘。
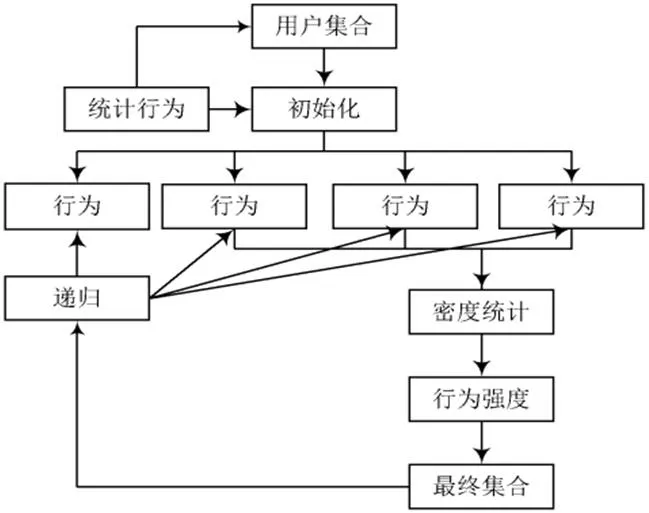
图1:用户行为挖掘树模型

图2:挖掘速度和挖掘错误率参数对比
就数据模型树本身而言,要确保模型树与电商企业经营模式高度匹配,确保电商大数据的准确性、全面性,首要任务就是对全网的所有数据进行全面的扫描,这样能知晓具体的网络节点,并获得较为完整的数据集合。将数据集合作为基础,从中选择数据量最大的节点作为数据挖掘的初始节点,然后对剩余的数据节点进行排序处理。在每个排序周期内,仅选择数据量最大的节点,然后进行数据挖掘处理,并由此形成最基本的数据模型树。
完成基本的数据模型树,出于精准营销目的,电商企业还应考虑消费者的行为,然后分析消费者具体行为与特定节点的关系,以此来构建用户行为挖掘树。值得注意的是,电商企业大数据的形成与用户行为之间并没有一个具体的正向波动关系,这要求在用户行为挖掘树建设中,其不仅要考虑消费者消费行为,而且需要对查看等行为进行相应的更改,然后在考虑周期性的特征下,对用户行为进行排序,并且在排序中,应注重用户行为最多节点与数据总量最大阶段的有序对应,最后采用二叉树的方式进行数据排列,可获得较为完整的用户行为挖掘树。电商大数据用户行为挖掘树模型如图1所示。
2.2 创建Spark机制
电商企业经营大数据管理中,在建立维度控制机制后,不仅可以获得较为完整的基础数据模型树,而且能建成用户行为挖掘树;然从数据应用过程来看,这两种数据模型的关联性并不突出。针对这一情况,创建Spark 机制,能进一步增强两个数据模型之间的关联度。

表1:仿真测试参数
在Spark 机制下,可通过“以列排序”的方式,对电商大数据中的节点进行排序,随后按照傅里叶变化的方式,对排列后的数据进行处理,并开展基础数据模型树和用户行为挖掘树的耦合处理,由此可得到一个全新的数据序列,该序列可通过Spark 机制进行映射,其映射方式可表达为:
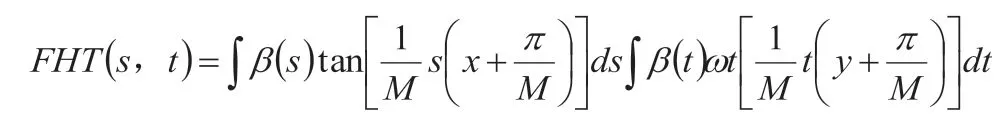
在该映射方式下,可通过随意变换序列的方式,对原有数据序列进行变化;随后在RSO 机制的作用下,对随意变化的序列进行两次结构混淆操作,待整个网络中全部节点数据变换结束后,得到基于RSO 机制的全新混淆序列和最终的Spark 机制映射序列。
3 电商大数据的数据分类
科学合理地进行数据分类,能有效提升电商大数据的应用价值。通常电商大数据分类在数据挖掘后进行,在对数据分类前,现需要对挖掘的数据进行清洗,并且在完成数据清洗后,还需要通过人工智能算法进行处理。这样能较为准确的发现数据中所包含的规律,继而获得较为具体的模型。本研究中,采用KNN 算法进行数据分类处理,该模式下,电商大数据的分类按照用户数据预处理、特征项目提取、构造分类、数据分类的流程进行操作。
3.1 电商大数据预处理
进行电商大数据的预处理,能为后期数据分类和应用创造有利条件。以电商企业挖掘的用户大数据为例,在进行用户数据处理时,就必须根据用户数据的具体类型,对所有的数据信息进行初步分类,然后实现具体分类栏目与数据类型的初步对应。在用户数据初步分类中,不仅可以根据消费意向、常住地、消费习惯的模式进行分类,也可以根据消费规模、个人爱好等进行处理,此外,根据用户年龄段、性别等进行分类也是较为常用的这样能较为常用的数据预处理方式,这样清晰的获得用户的消费情况,进而为电商企业的经营管理提供参考。
3.2 电商大数据特征编码
对初步完成分类的电商大数据进行特征提取,并拟定相应的编码,能为后期的数据的存储管理和调取应用提供保证。基于电商大数据人工智能管理需要,对数据编码过程中,还需要进行编码种类的有效区分。现阶段,除文字编码、语义编码外,电子编码、神经编码、记忆编码也是较为常用的编码形式。并且受互联网自身开放性的影响,电商大数据在应用中存在一定的外部风险,此时基于数据安全管理需要,在编码过程中,还需要进行编码数据的加密和译码的有效处理,以此来确保电商大数据应用的灵活性、安全性。
3.3 KNN分类算法应用
通过Spark 机制建立电商大数据平台后,通过数据的算法分析和分类处理训练,可得到一个K 值,按照KNN 分类算法,将K 值相接近的数据归为一个组别,这样可根据用户的实际情况,分类投放相应的营销内容,这不仅降低了电商企业的营销成本,而且有效地提升了精准程度,为电商企业的精准营销铺平了道路。
电商大数据的仿真测试:
针对本研究提出的电商大数据挖掘算法和分类模式,进一步确定其在实际应用的智能化程度,还需对于数据挖掘、数据分类的过程进行仿真测试。本研究中,采用Matlab 进行仿真测试,得到测试结果后,将测试结果与现阶段数据挖掘中最常用的SCM 及SGM算法结果进行对照,由此可获得一定的方针参数。利用本研究算法模式及分类方式,对某电商企业的大数据进行处理,随后经Matlab进行仿真测试,所得仿真测试的参数如表1所示。
为实现本研究设计数据挖掘算法和分类方法的有效评估,将上述测试结果与SCM,SGM 两种算法进行对比,在实际对比中考虑挖掘速度和挖掘错误率两个参数。实际对比结果如图2所示。
由图2 可知,在同种挖掘强度下,本研究所提出的挖掘算法和分类方法挖掘时间较短,这表明在电商大数据挖掘应用中,本研究所提算法具有较高的效率性;这不仅解决了传统算法陌模式下,电商大数据挖掘应用的缺陷,而且有效地避免了电商大数据挖掘周期频繁等问题。
值得注意的是,当挖掘强度区域无限大时,各算法对于电商大数据的挖掘速度区域平缓,这主要是受到了电商企业用户具体行为、具体算法整合节点资源等因素的影响。
传统算法模式下,电商大数据挖掘处理中存在数据冗余程度较高的问题,较多的数据容易对电商企业信息的挖掘和应用造成干扰。然而从错误率两个层面来看,在同等挖掘前度下,本研究所提出算法和分类方式的错误率较小,这表明在电商数据挖掘应用中,本研究所提供的算法具有较高的准确性,其能有效满足电商企业应用需要。
4 结语
实现电商大数据的智能化挖掘和分类是电商数据高质量应用的基础。新时期,电商企业发展尤为迅速,这使得企业的经营数据类型不断丰富,数据总量不断增加,在以往数据分类、挖掘和利用中,受数据挖掘算法滞后、人工智能程度不高等因素的影响,电商大数据的挖掘、应用存在周期频繁、递归效率低下、待挖掘信息冗余程度高等问题。对于这一问题,本文基于人工智能背景,提出了一种全新化电商大数据分类和挖掘方式,该数据分类及挖掘模式下,对所有需要挖掘的数据进行离散处理,然后在人工智能工具下,依托Spark 架构对其进行挖掘,并按照依次映射的方式对户行为树及其数据的集合进行分类处理,通过仿真测试得出:本研究所提供的数据挖掘和分类方式具有较高适用性,其能在解决传统电商大数据挖掘处理问题的基础上,为电商企业的精准营销提供相应的技术支持。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
大众投资指南(2021年35期)2021-02-16 01:06:26
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:48
电子测试(2017年12期)2017-12-18 06:35:36
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2014年18期)2014-02-27 12:00:13
