
基于数据挖掘的服务器日志预警方法研究
2020-02-03 09:36王栋张云龙唐琨
价值工程 2020年2期
关键词:数据挖掘
王栋 张云龙 唐琨

摘要:本文通过介绍服务器日志的内涵、特点、用途以及当前日志分析方式的现状和存在的问题,分析了常用系统日志分析方法的优缺点和存在问题,提出了一种基于KNN算法改进型文本挖掘方法,并以此为基础设计了服务器日志安全预警系统架构,为服务器系统的安全监管提供了一种可行的解决方案。
Abstract: This paper introduces the connotation, characteristics, use of server logs, and the current status and problems of current log analysis methods. It analyzes the advantages and disadvantages and existing problems of common system log analysis methods, and proposes an improved text mining method based on KNN, and designs a server log security early warning system architecture is designed based on this, which provides a feasible solution for the security supervision of the server system.
关键词:服务器日志;数据挖掘;KNN算法
Key words: server log;data mining;KNN algorithm
中图分类号:TP274 文献标识码:A 文章编号:1006-4311(2020)02-0222-02
0 引言
伴随着计算机技术和互联网的飞速发展,人们已经进入了一个信息量极为丰富、数据量极为海量的大数据时代。然而人们在享受大数据带来的各种便利的同時,信息安全事件也越来越多,如何预防和阻止安全事件的发生变得尤其重要。日志用于记录系统日常运行的状态,检查发生错误、入侵时的线索,可以有效实时的防止安全事件的发生,因此,利用日志来进行系统安全分析是目前计算机科学的一个重要研究方向。
1 日志分析现状
系统日志信息安全审计想法是由Anderson在1980年提出的,他指出在入侵发生时,向安全管理员提供已经冗余过滤的信息以达到查找漏洞及相关责任人的目的[1]。目前在国际上已经有通过基于机器学习能力的数据挖掘技术来进行日志分析研究的方式。国内在该方面的研究以国家自然科学基金会首次支持日志安全审计的研究为标志于上世纪90年代初期开始,其主要通过高校课题研究而展开。
1.1 日志分析存在的问题 由于服务器将所有的系统事件都记录在日志中,这些事件包括系统异常、登陆注销、用户审计、硬件变动、应用改变、网络状况、系统更新等,致使日志的数据量巨大。系统对日志的存储时间依赖于系统存储划分空间的大小,且由于日志的权限归属问题导致日志文件内容易被修改、保存时间不确定、误删除概率大。系统无法对日志进行安全有效的保护。目前的分析方法只对日志进行收集和关建字或类别的筛选,然后将选出结果进行字面意思的分析。这只是对表面所描述的问题进行分析,并且分析方法单一化,缺少整合式的分析,致使日志间隐藏关系难以发现,出现信息匮乏现象。
1.2 日志数据挖掘存在的难点 服务器日志将服务器操作系统中的所有事件都进行记录,如何对这些记录进行合理的利用,得到其内在的联系和规律,并为系统的安全、应用程序、系统硬件等方面应用这些信息是大数据时代数据处理技术的一个重要研究方向。数据挖掘就是从大量的数据中发现隐含的规律性的内容,解决数据的应用质量问题[2]。对服务器日志数据而言,形式上为描述性质的文本格式,类别为已知有限的类别,主要的价值信息存在于文本内容当中。传统的数据库多为关系型类别,其中数据结构性规范,易于计算机识别处理。因服务器操作系统版本各异导致系统日志结构不同的文本数据为非结构化数据,难以进行直接分析。如何处理异构的非结构化日志数据是日志数据挖掘的重点和难点[3]。
2 数据挖掘技术简介
数据挖掘可以看做信息技术自然进化的结果。数据库和数据管理产业在一些关建功能的开发上不断推进,以数据收集和数据库创建为基础传统的数据管理技术被不断地研究和应用,数据存储、检索以及查询和事务处理的商业应用遍地开花。随着大数据时代的到来推进数据处理技术发展到新的高级阶段。该阶段的数据处理技术不仅可以进行传统意义上对数据的查询检索,并且能够从海量杂而无章的数据中提取出具有价值的知识和信息。今天,在互联网、电子商务、传媒界、公共事务管理、医学界等领域,数据挖掘技术已经开始扮演重要角色。以数据挖掘为基础的决策支持、趋势预测、网络安全预警、内容推荐等技术正在深刻的影响着人类社会。数据挖掘[4](Data Mining)可以定义为从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
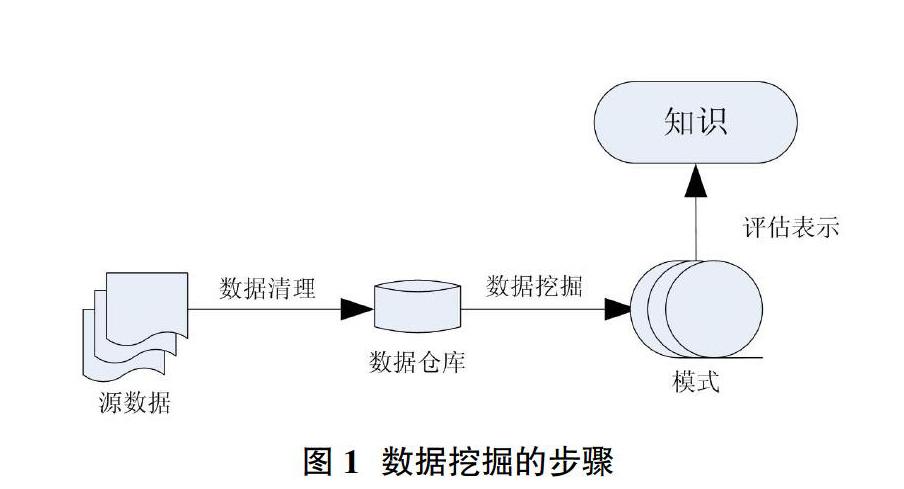
2.1 数据挖掘的步骤 不同于普通的数据分析如检索、筛查和仓储应用,数据挖掘是新知识发现的一个过程,即在未知目标前提条件下去挖掘未出现过的信息和知识。因此,数据挖掘得到的知识应该是从前未有的、能反映出问题的、可直接使用的有价值信息。数据挖掘的过程类似于在数据库中发现知识,其步骤如图1所示。
由图1中可以看到数据挖掘的过程为:首先,对杂乱的无规律的源数据进行规范化处理,将处理后形成的规格化的数据存入数据仓库中;然后,将数据仓库中存留的规格化的数据通过一定的算法进行挖掘处理,形成所预定的模式;最后,对挖掘后的结果根据一定的标准进行取值筛选,选出符合要求的结果进而表达成为最终的知识。其中数据清理的工作就是将非结构化的数据如文本、音视频、图像进行提取,形成可以被计算机理解和处理的结构化的数据,而数据挖掘工作就是将这些结构化之后的数据通过特定的挖掘算法计算形成特定的模式,评估表示工作既对挖掘结果进行优劣的排序选择出满足用户需要的知识。
2.2 KNN算法介绍及改进 KNN算法基于类比学习,它广泛用于模式识别领域。该算法的原理是:在特征空间中,如果待分类元组周围有K个最相近(近似)的元组,那么待分类元组的类别就是这些最近似元组中数量最多的类别,待分类元组和其近邻元组的远近常用欧几里得距离来计算。在特征空间中用两个点来表示两个元组P1=(x1,x2,…,xn)和P2=(y1,y2,…,yn)他们之间的欧几里得距离为:
而相似度为其倒数:
在实际应用中,除了计算K近邻训练元组个数最大类别以外还常用一种最相似类方法,该方法将待分类文本的K个近邻训练文本相似度计算出,然后将其划分到这些最相似训练文本的类别中所用计算公式为:
在式(3)中sim(d,ti)是待分类元组d和其近邻元组ti的相似度,f(ti,cj)是一个二值函数,当训练元组ti属于类别cj时其值为1,否则其值为0。
2.3 KNN算法的改进 KNN算法具有稳定性好、分类精度高、实现建议、调整速度快等优点,但其分类受到K值选取影响和训练样本分布密度较大。在样本分布不均情况下易出现误分类状况。为了减少训练样本密度对待分类日志文本所造成的误差可对KNN算法进行改造。
算法改进思路为:在求出待分类样本临近的K个训练日志文本后,按类别计算它们之间的相似度,然后除以K得到平均值M,在计算这个待分类日志文本和不同类别样本日志中心的相似度(训练样本类别中心距离)L,然后求两者的比例:M/L,值最大的类别即为所求的结果。
设Cj为样本日志类别,d为待分类样本,tj为待分类样本周围的训练日志,sim(d,Sj)为待分类样本到类别中心的相似度,则L/M可表示为:
改进的KNN算法的实现步骤为:
首先,对日志训练集合中的文本进行包括分词,正规化在内的数据清理。其中训练集合中的类别已经处理完毕。其次,利用处理完成后的训练集合中的样本词汇组成一个多维度的空间,每个样本用该纬度空间的向量表示。第三,让待分类日志经过数据清理后,同样表示为样本集多维空间中的向量。计算训练样本中每个类别的中心向量。第四,计算待分类向量和各类别中心向量的距离,计算待分类样本和周围不同类别K个向量的平均值。第五,将第四步计算的相同类别的结果进行相除。并将不同类别的计算结果进行排序,值最大的类别即为待分类样本的类别。
在服务器系统日志得到相应的类别之后进行归类,并利用专家系统进行对比就可以分析出系统的状态并进行预警。
3 服务器日志挖掘预警系统的设计
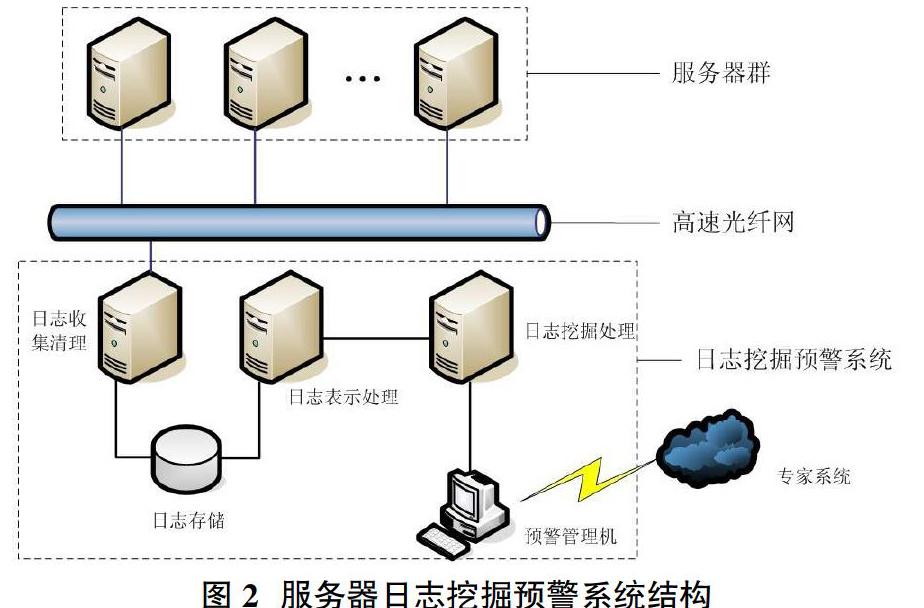
利用我们提出的数据挖掘方法对日志挖掘预警系统进行设计。需要一个专用的存储和处理日志文本的服务器来对源数据进行收集和清理并将结果进行存储,需要一台处理能力较强的服务器对规格化的数据进行多维空间的建立和向量化的表示,然后利用计算平台对向量化后的数据进行计算和排序,将结果提交给一台管理计算机,管理计算机根据收到的数据对比专家知识系统进行预警。系统架构如图2所示。
经过实验部署测试,服务器日志挖掘预警系统可以有效的对服务器群所产生的日志进行分析挖掘,根据具体的日志内容进行分类对比并对系统出现的故障等状况进行预警。极大的帮助管理員实时掌握服务器的动态状况。
4 结束语
总之,服务器日志分析是一种有效的服务器系统检测手段,日志分析方法众多,利用数据挖掘技术对海量的日志进行基于内容的分析对比可以查找到日志背后所隐藏的系统状态。本文所提出的利用基于KNN的改进算法所设计的服务器日志挖掘预警系统可以有效的帮助管理者分析和归类日志,实时的对服务器群的工作状态进行掌控。
参考文献:
[1]卢鹏.计算机网络安全及其防护策略探析[J].硅谷,2009(12):62-63.
[2]冯绿音.网络信息系统日志分析与审计技术研究[D].上海:上海交通大学,2007.
[3]李村合.网络信息挖掘技术及其应用研究[J].情报科学,2002,20(11).
[4]毛国君,段立娟,王实,等.数据挖掘原理与算法[M].二版.北京:清华大学出版社,2007.
猜你喜欢
中国交通信息化(2020年1期)2020-07-27
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
河南科技(2014年19期)2014-02-27
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年18期)2014-02-27
智能系统学报(2013年1期)2013-01-28
智能系统学报(2013年2期)2013-01-28
