
扩展无极限 解析全新Imagination B 系列GPU
2020-01-25 16:19张平
微型计算机 2020年22期
张平


之前本刊介绍过Imagination的全新A系列GPU,并给予了高度评价。现在,跟随着Imagination的发布时序,全新的B系列GPU也已经准备完毕。相比全面革新的A系列GPU,B系列GPU又带来了那些激动人心的特性呢?
满足市场需求通过多GPU扩展提高性能
Imagination目前在移动GPU市场中的艰难现状几乎是众所周知的事情。作为ARM之外的唯一移动GPU提供方,Imagination的客户数量在持续下降,主要原因就是ARM也可以提供具有竞争力的CPU和GPU知识产权,且需要高性能移动GPU的客户数量其实并不多。诸如高通等厂商其内部的Aderno GPU在性能和功能设计上也居于领导地位,并且对其他供应商施加了巨大压力,这导致其他供应商在很多情况下会直接选择ARM的GPU产品,除了联发科之外。联发科是历年来唯一一个在SoC产品中经常使用Imagination GPU产品的企业,但是最近的Helio又改回了ARM Mali GPU,并且短期内再度使用Imagination GPU的可能性应该也不大。
随着苹果使用Imagination的架构许可来设计定制GPU,三星和AMD合作计划在Exynos中引入AMD的技术,华为海思在设计自主GPU架构以及前景不够确定的情况下,Imagination面临需求不足的问题。
这样一来,Imagination需要将发展空间聚焦在移动之外的市场,比如高性能计算、汽车市场等。但是从传统的移动设备转移至高性能GPU是非常困难的,因为这将直接影响整个GPU架构的平衡和设计,毕竟移动GPU面向的是低功耗市场。这实际上是绝对性能、可扩展性和功耗效率之间的平衡问题,毕竟高性能GPU的能耗比肯定不会高,但是低功耗、高效率的移动GPU无法扩展性能。
因此在B系列GPU上,Imagination引入了一种新方式来解决这个问题,那就是使用多GPU。在看到多GPU的时候,大家首先想到的是台式机的多GPU并联技术,比如英伟达的SLI或者AMD的CrossFire,但是由于现代游戏API和多GPU技术存在一些冲突,因此这个技术已逐渐被厂商抛弃。
Imagination在多GPU的处理上和过去完全不同,其主要区别在于GPU处理工作负载的方式。B系列的工作模式将从传统的“推送”模式转变为新的“拉动”模式,其中前者表示GPU驱动程序将工作推送至GPU进行渲染,后者则表示GPU将拉入工作负载并进行处理,这是GPU在数据馈送工作方式的根本性转变,Imagination称之为“分散式”设计。
根据Imagination的介绍,在一组GPU中,其中一个充当“主”GPU,带有一个额外的控制固件处理器,该处理器将一个工作负载(比如一个渲染帧)划分为不同的工作块,然后其他“从”GPU可以从这些工作块中拉出不同的工作以进行处理。在这里,Imagination使用了“tile-based”用于形容这个工作方式,这里的“tile”实际上就是它的本意,指不同的工作区块,也就是说GPU基于区块的渲染方法是这个全新机制的核心,这里需要注意的是,区别之前AFR备用帧渲染或者SFR分割帧渲染。同样的,由于使用区块渲染的单个GPU可以针对给定的帧进行不同尺寸的区块渲染处理,那么相应的B系列GPU也可以针对单一帧针在一组GPU中进行不同尺寸大小的分配,这将有助于提高整体的渲染效率。
最重要的是,Imagination推出的这个全新的多GPU系统对于高层的API和軟件工作负载来说是完全透明的,这意味着从软件角度来看,运行多GPU配置的系统只需要面向一整个大型GPU,这和目前大多数使用多GPU的离散渲染系统形成了鲜明的对比,后者会在系统中显示每一个离散GPU信号,这也是Imagination这项全新技术的特别之处所在。
从实现的角度来看,这项技术使得Imagination和其客户在配置选择方面有了更多的灵活性,Imagination不再需要设计一个巨大的GPU,并且这种大型GPU往往由于时序收敛或者微体系结构扩展方面需要做更多的工作。现在Imagination可以设计一个高效率的GPU核心,并且允许客户对GPU核心根据需求进行规模上的缩放。另外,Imagination还声称自己将提高GPU的频率,比如针对高端市场、云计算等方面计划实现1.5GHz的产品频率。
对于客户而言,Imagination这样的设计给予了客户极大的灵活配置空间,客户不需要等待Imagination为其设计实行目标相匹配的GPU,而是利用现有GPU进行“缩放”,就可以获得目标性能,并且能够自主配置和扩展,尤其是客户需要为多个目标设计多个SoC的时候,那么只需要使用一种GPU模块就可以轻松实现多个性能目标。
本文将在后续段落详细介绍Imagination的缩放功能。目前B系列GPU最多可以支持扩展至4个GPU,和一个较大的GPU相比,在SoC上放置多个B系列GPU时并不要求GPU必须相邻甚至可以完全不相邻。这是因为每个GPU都是独立的设计模块,设计人员甚至可以在满足设计要求的前提下,SoC的四周放置4个GPU。
对SoC设计人员而言,要使用Imagination的B系列GPU的唯一要求是他们必须使用标准的AXI互联总线并将多个GPU连接到内存,对于GPU之间的连接则没有那么麻烦,因为GPU之间只需要一些比较简单的连接用于实现不同的GPU核心之间的中断即可,这种连接并不传输具体的数据。因此,这种设计特别适合现在比较流行的Chiplet或者多硅片芯片设计,尽管当前单个GPU设计很难使用和CPU群组相同的方式分解为多个小芯片,但是Imagination的分散式多GPU在横跨多个小芯片时应该不会出现特别的问题,同时在软件端和系统层面,看起来依1日是一个整体的GPU。
总的来看,Imagination正在使用这种新的多GPU方法来实现之前无法提供的更高性能的设计。Imagination宣称,通过多GPU扩展,他们基于移动设备、更高效的GPU lP可以与英伟达和AMD当前提供的其他产品相竞争(Imagination将其最大配置扩展到6TFLOP),并提供PCle的外在设计,还带来了高达70%的计算密度提升,这个数据是Imagination定义的,其单位是TFLOPs/mm2。尽管该指标在性能方面相对没有意义,原因是集群GPU的性能上限依旧受到架构和当前B系列GPU所能实现的最高MC4扩展所限制,但是在小尺寸芯片上,这个数据能够带来极高的成本收益,因此也呈现出非常出色的市场竞争力。
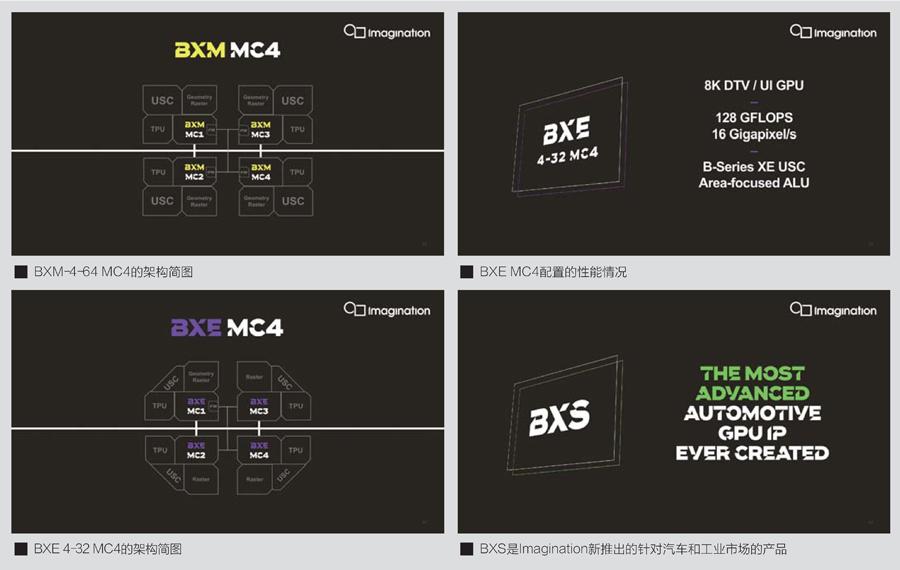
目前,Imagination的新B系列GPU目前包含了很多不同的等级的产品,并且该公司继续将其划分为不同的性能等级-BXT系列是旗舰GPU设计,BXM系列是更加平衡的中端GPU,BXE系列是该公司的最小、最高效的兼容Vulkan的GPU。
从BXT开始4个GPU如何达到6TFLOPS性能
在本部分,本文将继续讨论B系列GPU的扩展性和架构内容。从架构角度来看,新的B系列GPU和之前公布的A系列GPU在微架构上非常接近,不过Imagination提出新的B系列大约可以带来性能或者效率15%的提升。另外,B系列GPU还带来了一些新加入的功能比如IMGIC( ImaginationImage Compression,Imagination图像压缩技术),这个技术后文还有介绍。
更进一步来看的话,BXT系列GPU采用了新的SPU设计,包含了新的、功能更强大的TPU(纹理处理单元)以及新的128宽度的ALU,这些新的功能加入了被称为USC( (UnifiedShading Clusters统一像素计算簇)的单元。
BXT系列中最大规模的单元被称为BTX 32-1024,将其中4个集成在一起,可以创建被称为BXT 32-1024 MC4的GPU,这个GPU在高达1.5GHz的主频下能够提供6TFLOPS的FP32计算能力,虽然这个性能还不足以和AMD以及英伟达的顶级显卡相提并论(RTX 3090的FP32性能约35TFLOPS),但是考虑到Imagination是一个移动领域GPU架构的提供商,这样的性能也还是相当不错了。
在BXT之外就是BXM系列GPU。相比BXT,BXM的定位要低一些,因此没有加入XT系列的超宽ALU设計。在这个系列的GPU中,如何实现最高的面积效能需要仔细地衡量。以BXM-4-64为例,这个系列如果使用8XT系列的32宽的ALU,并将4个同样型号的GPU组合在一起实现BXM-4-64 MC4的GPU的话,那么其面积效率和性能相比单一的、规模更大的BXM-8-256GPU可能要更高一些。
在更注重性价比、更小的BXE上,集群使用就变得更有趣了。因为BXM系列的设计目的极为注重面积效率,但绝对性能不高,因此BXT和BXM往往作为主要GPU提供,BXE既可以作为主要的GPU,也可以作为辅助GPU形式存在,当BXE作为辅助GPU存在的时候,将不加入固件处理模块或者几何图形模块,这部分计算将完全依赖于主GPU的几何计算单元。Imagination表示,这种特殊的设计能够在极其微小的区域面积占用的情况下提供相当高的计算能力和纹理填充率。
根据Imagination提供的规格并组织成表后,我们看到了Imagination只需要8钟不同的硬件设计就可以创建RTL并进行物理设计、确定时钟频率等,面向低端领域的GPU设计在这里也可以扩展到高端移动SoC中,设计非常巧妙。对客户来说,如此灵活的设计方案能够为其带来最大的便利,客户可以通过不同的GPU组合来实现自己需要的性能。
值得注意的是,虽然在入门级产品的计算能力组合搭配上出现了一些重叠,但是不同的区域效率和不同的填充率可能会影响产品倾向和用户选择。高端市场则可以通过最大的MC4 GPU配置使得高端性能提高4倍。Imagination特别指出,未来他们将不再设计比BXT-32-1024更大的单-GPU方案,因为用户可以通过BXT-32-1024的多核扩展,这样做投资回报率更高,并且不涉及更复杂的大核心芯片设计工作。
引入IMGIC实现更好的帧缓冲压缩
除了多GPU扩展的特性外,新的B系列GPU的另一个特点是带来了全新的图像压缩算法,简称为IMGIC。
从现代GPU的发展来看,数据压缩是非常重要的一环,否则GPU将面临带宽不足的窘境。迄今为止,Imagination-直在使用PVRIC进行数据压缩,PVRIC的问题在于其数据压缩率相对几个竞争对手而言都显得比较低。比如ARM使用的AFBC (ARMFrame-Buffer Compression,ARM帧缓冲压缩)就能够实现更高的压缩率。这导致Imagination的GPU在日常使用中需要更高的带宽才能发挥出更好的性能。
IMGIC则是Imagination提出的全新一代、重新设计的压缩算法,Imagination称其为现在最先进的图像压缩技术。和之前的PVRIC相比,新的IMGIC能够节约大量带宽并具有极高的灵活性,尤其是IMGIC不光能对图像、较小的图块或者像素组进行压缩,还能够直接处理单个像素。另外,有消息称IMGIC的算法也要比PVRIC算法简单大约8倍,这意味着硬件方面也可以大大简化,并且在面积上有比较明显的降低。
IMGIC的灵活性还体现在它能够根据不同的场合,提供不同的压缩比选择。比如在最大限度节省带宽的情况下,压缩比可以达到有损的25%,或者是在平衡模式下选择50%压缩比同时获得视觉无损质量,或者选择75%压缩比获得节约带宽的无损压缩模式等。但无论如何,整个B系列GPU在内部数据传输和处理上都做出了改进,节约了大约35%的带宽。考虑到内存带宽在移动处理器中是一个非常昂贵的资源,因此B系列GPU在带宽方面的改进是非常有益的。
BXS系列安全性优先
除了针对更高性能的设计外,Imagination还将重点放在了汽车和工业市场上,并针对这些市场的需求推出了BXS系列GPU,其中S代表的是“safety”。从规格来看,新的BXS系列产品基本和BXT、BXM和BXE系列配置相同,但是增加了对IS0 26262/ASIL-B安全功能的支持。
Imagination推出了__项名为“区块区域保护(Tile Region Protection,简称为TRP)”的新功能,该功能可将渲染帧上可配置的渲染区块标记为关键安全区块,GPU可以检查其执行和渲染的结果,使其符合IS0 26262认证的需求。这个功能最小需要等效BXE的BXS GPU才能支持。此外,Imagination还允许通过CRC来检查进出GPU的所有数据,实现端到端的数据完整性保护,进一步帮助特殊用户实现安全要求。
继续说TRP。由于TRP需要单个GPU来反复检查和校验,因此往往会带来性能损失,在这里,用户可能需要配置多GPU来满足性能的同时启用TRP功能。不仅如此,在汽车设计中,多GPU配置还可以达到将GPU划分为多个独立工作的负载区域,来实现不同的功能并确保整个系统工作的有效性和安全性。比如有4个GPU,可以分为3个分区,其中2个GPU协同工作为诸如信息娱乐系统等提供计算支持,另外2个GPU则用于汽车其他部分的数据处理甚至监控等。
在虚拟化功能方面,Imagination为B系列GPU配置了支持最多8个“来宾”通道的硬件虚拟化技术,拥有这个技术,GPU用户可以将2个GPU虚拟化为3个分区,实现不同的功能,当然这种虚拟化不会带来性能的提升。
BXS系列除了增加安全功能外,還针对汽车这种使用场合,对GPU的架构进行了一些特定的增强,从而可以为汽车领域更独特的工作负载实现更好的性能扩展。其中之_是对几何形状处理能力的加强,因为汽车供应商倾向于使用更多的三角形。Imagination表示,他们已经对设计进行了调整以涵盖这些更苛刻的使用场景,并且与一些MSAA特定的优化措施相结合,与常规的非汽车GPU产品相比,这些支持汽车应用的GPU在边缘处理应用场景下的性能可提高60%。
性能、效率和即将来临的光线追踪支持
总的来说,B系列产品在GPU设计拥有非常显著的创新。虽然相比A系列产品,B系列产品在GPU架构上进步不大,但是在多GPU方面具有显著的创新,并且和之前的多GPU方案都有巨大差异和优势。新的多GPU设计带来了很大的灵活性,能够在很多场合提供更出色的性能。不过在某些极端情况下,这种多GPU设计还是会带来性能瓶颈,这也是不可避免的。Imagination希望在大部分场景下能够拥有比较良好的效果。
在GPU性能方面,Imagination宣称B系列GPU相比A系列GPU在相同的功耗目标下带来了大约30%的性能提升,其中15%通过微体系架构和物理设计实现,其余的部分则是通过选择多核心GPU配置的PPA优势来实现的。
在实际产品方面,Imagination宣布B系列GPU现在已经有实际客户和产品了。一家名为Innosilicon的厂商基于Imagination推出的B系列GPU设计并推出了名为“风华”的显卡产品。在之前,Innosilicon专门设计各类ASIC知识产权产品,比如英伟达的GDDR6存储控制器,但是这次借助Imagination的B系列的特性,在英伟达和AMD之外推出了类似独立显卡的产品,面向云计算和高端数据中心等。当然,作为首款产品,Innosilicon的努力还值得观察,但是相比之前从未见过的A系列GPU、8XT、9XT等产品而言,B系列初战告捷。
除了B系列GPU外,Imagination还预告了即将到来的C系列GPU,并宣称C系列GPU将带来原生光线追踪支持。实际上,Imagination在十年前就已经拥有有关光线追踪的专利和相关lP设计,但是直到英伟达和AMD纷纷加入光线追踪技术、整个市场环境逐步成熟后,Imagination才提出在C系列中加入光线追踪计算以适应市场变化。不仅如此,Imagination还确认自家的光线追踪技术将拥有全面而完整的功能,包括BVH以及硬件相干排序等,这些功能被Imagination称之为“第四级”,相比之下,Imagination定义现有的英伟达和AMD的光线追踪为“第三级”。
小结
总的来看,Imagination推出的全新B系列GPU带来了前所未有的扩展性,再加上其在数据压缩、安全性方面的努力,使得Imagination的GPU产品能够有机会扩展至移动GPU之外的其他领域,包括汽车、高性能计算、数据中心等。从这一点来看,如果Imagination坚持这样的发展方向的话,那么未来几年业界应该会发生一些有趣的变化,尤其是新的分布式多GPU的设计,可能会带来一些意想不到的结果。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
科学(2020年5期)2020-11-26
科学(2020年6期)2020-02-06
家庭影院技术(2019年8期)2019-08-27
传媒评论(2018年4期)2018-06-27
现代企业文化(2018年13期)2018-06-09
电信科学(2017年6期)2017-07-01
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
