
基于区块链的河长制水质信息存证系统
2020-01-17 03:07:42邹秀清罗得寸沈世平谢振平王玉珏
应用科学学报 2020年1期
邹秀清,罗得寸,林 平,沈世平,谢振平,王玉珏,丁 勇
1.桂林电子科技大学计算机与信息安全学院,广西桂林541004
2.江苏省无锡市河道堤闸管理处,江苏无锡214031
3.江南大学数字媒体学院,江苏无锡214122
“河长制”首创于浙江长兴,最早推广地是江苏无锡[1].2016年底,随着中央《关于全面推行河长制的意见》文书的下达,全国各地已严格推行“河长制”.中国各省份从上至下已明确了省、市、县、乡4 个级别的河长[2],共同领导并组织地方水域的环境污染治理工作.全国各地区政府都在努力加大对河长制信息化的建设力度,相应地开发出了许多河长制管理信息系统.很多省份的河长制管理信息系统的信息覆盖手段多种多样,如网页、手机APP 和微信公众号等,同时与软件相匹配的硬件设施包括物联网检测站、地理信息系统等也发展得较为完善.部分地区的河长制信息系统还结合了大数据、云计算等前沿的计算机技术,共同促进了智慧化的河长制管理信息系统的建设.
河长制河道管理制度是以河长责任制为驱动的河道生态环境保护制度.因此,河道治理工作数据的可信性、公开透明性是河长责任制得到有效发挥的重要前提.尽管河长制信息化建设在不断推进,一些问题仍然得不到有效的解决.在传统的河长制信息管理系统中,其中心化的数据管理方式使得河道治理工作数据难以做到可信和透明.因此,在河长制信息管理系统实际运行过程中,一方面治理数据容易被篡改使得河长制缺乏公信力;另一方面数据的不公开透明使得各部门之间形成信息孤岛,治理工作效率低下,许多实质性的问题难以得到有效的解决.
传统的河长制管理信息系统需要维护大量的数据信息,通常会针对性地建立专题数据库进行数据存储.专题数据库往往采用中心化程度很高的关系型数据库服务,这类中心化数据库存储的数据始终存在着安全隐患.一旦中心数据库被攻破,大量数据的可信性就无法得到保证.然而,河长制信息管理系统往往会有部分数据需要面向公众,并且需要保证信息的透明公开和可追溯,同时为了数据存储的安全性,需要对重点水质信息的存储做冗余备份.当中心化的河长制信息管理系统数据库遭受外部攻击,或是人为操作失误导致核心数据丢失时,系统需要将原先数据核验还原,从而保证整个系统的稳定运行.
区块链[3]作为一种新兴的互联网技术,其底层采用的是分布式数据存储、点对点传输、共识机制、加密算法等核心技术.区块链上的数据具有不可篡改、公开透明、永久保存的特性,它们分布在各个节点中,不会因为中心节点出现故障而导致整体崩溃,可以实现安全可靠的数据备份.因此,本文针对河长制管理信息系统存在的问题,采用区块链技术设计一种去中心化、安全可信、可维护的区块链河长制水质信息存证系统.
1 相关工作
目前,河长制信息建设已有较多有效的实施案例.文献[4]结合德州市的实际情况,明确了本市河湖信息平台的两期建设任务,从河长制信息门户网站、工作管理系统、河长制APP、微信公众号服务、无人机应用等多个方面系统地建设德州市智慧河湖长平台.文献[5]针对河长制实施过程中的信息单一、不对称等问题,利用移动终端、移动互联、GIS、可视化等信息技术提出了基于河长制的河道动态保护监管新模式.文献[6]为实现河长制管理精细化、联防联控高效化和社会监督公开化的河湖管理保护体系,采用云计算、大数据、二三维影像、物联网等先进技术提出建设“互联网+”的河长制信息管理平台.
区块链在众多领域都发挥着关键的作用.随着区块链的快速发展,中国的金融业迎来了新的发展机遇.文献[7]指出,区块链和金融业结合应用涉及到关于数字货币的发行和流通、支付结算、证券交易、数字票据等多个方面.文献[8]梳理了供应链金融特征,发现了区块链与供应链金融业务之间的匹配性关系,并在此基础上分析了区块链技术在供应链金融方面的应用结合点.文献[9]将区块链的技术与金融证券业的登记、清算、结算等业务流程相结合,推动了证券金融业的发展.在电子商务存在安全隐患的大环境下,文献[10]将区块链技术运用到电商产品的溯源防伪、存储物流、商品存储等方面,在一定程度上规范了电子商务市场.
此外,区块链技术在安全隐私领域也有突出表现.文献[11]为防止智能电网中的中心服务器遭受敌手的攻击以及存储数据被恶意篡改的现象发生,选取多个基站组成智能电网中的联盟链存储网络系统,保证了智能电网中的信息可以安全存储.由于架构和资源的约束,物联网技术不能友好地适应多种安全技术.文献[12]将区块链与物联网相结合,不仅增强了物联网中物与物之间的联系,而且也为物联网系统的正常运行提供了安全的技术保障.
在溯源信息领域,区块链的应用相当广泛.在假冒伪劣产品日益增多的社会背景下,文献[13]将区块链技术同IC 芯片卡相结合,设计了一种安全的防伪系统,为防伪市场提出了新的技术参考.文献[14]提出基于区块链技术的RFID 大数据溯源安全模型,在RFID 溯源物品的生产、加工、销售等多个环节建立区块链账本,从而实现了RFID 大数据溯源的安全管理.
针对当前河长制信息管理系统中存在的中心化程度过高、数据容易被篡改、无法公开透明、系统安全性难以得到保证等问题,本文提出了一种基于区块链技术的河长制信息管理系统.该系统利用区块链技术的特性,解决了传统河长制信息管理系统中存在的弊端,从而实现了河长制信息管理系统中关键水质信息的透明公开、可追溯、可信任.本系统是以区块链作为底层可信数据存储的网络环境,同时还包括了智能合约、SDK 应用接口以及上层Web 河长制信息管理系统页面.
智能合约层负责对交易数据的背书以及对区块链分布式账本的读写;SDK 接口层为应用层提供相关水质信息的存证功能服务;河长制信息管理系统的Web 页面主要记录并展示河道治理工作,可分为工作展示模块和区块链功能模块.工作展示模块包含了对河长治理工作历史进展和最新进展的相关介绍;区块链功能模块则是向各部门用户提供关键河道水质信息的上链和链上查询的服务.
本文对基于区块链的河长制信息管理系统中的河道水质信息的上链、查询功能进行测试,测试结果表明:本方案能够在实现数据去中心化管理、防篡改、公开透明的前提下使系统的性能和效率方面基本达到实际的应用需求.与传统的河长制信息管理系统相比,本文设计实现的河长制信息管理系统首次将河长制与区块链技术相结合,利用区块链为系统中的重要信息提供数据存证,进而扩展系统中的数据信息可追溯、模糊数据的链上核验还原等功能.本方案旨在打造一个数据信息更加牢固、不易篡改、不易丢失的新型可信的河长制信息管理系统.
2 超级账本技术
区块链根据用户范围可以划分成公有链、联盟链和私有链.其中联盟链和私有链都是针对特定企业机构,与公有链中任何人都可以参与的无权限设定不同,联盟链和私有链对参与者进行严格的权限规定[15].超级账本(Hyperledger Fabric)是一种面向企业级项目开发的开源联盟区块链应用框架,最初是由Linux 基金会在2015年12月主导发起的项目之一.超级账本基于模块化的框架设计理念,提供了可插拔的共识机制、成员身份管理服务、节点数据库、背书策略以及验证策略等,非常灵活易于扩展.超级账本目前提供基于Kafka 消息队列的共识机制[16],通过排序节点分离出区块链网络的共识服务,在性能方面优于大多数公有链和其他联盟链.
2.1 超级账本架构
超级账本作为联盟区块链的开源框架,在设计上偏向于联盟架构的特性.首先,超级账本包含了一个成员服务提供者模块,用于对新加入成员的授权以及系统内成员权限的管控.其次,超级账本的节点类型分为4 种,包括证书(CA)节点、背书(Endorser)节点、排序(Orderer)节点、提交(Committer)节点.业务分离的节点有利于区块链网络的弹性伸缩,提高了系统的可扩展性.同时,超级账本为平台应用提供支持远程调用的GRPC 接口[17]和封装完整的SDK.GRPC 为超级账本底层的各种节点提供彼此交互的通道,使节点相互连接组成P2P 网络,并且节点之间的通信遵循分布式网络的Gossip 协议.封装之后的SDK 可供应用平台访问联盟区块链中的资源.应用层通过超级账本封装的SDK 访问区块链中的数据,包括账本、区块交易、智能合约、事件以及权限管理服务.账本是超级账本的核心组件,它由记账节点和共识机制共同维护,其交易内容存储在负责记账的节点中;智能合约即超级账本中的链码模块,以代码的形式描述交易过程中的逻辑;在区块链资源调用过程中的发生事件都可以被相关服务访问;权限管理负责成员、节点对账本的写入以及访问权限控制.超级账本的架构如图1所示.
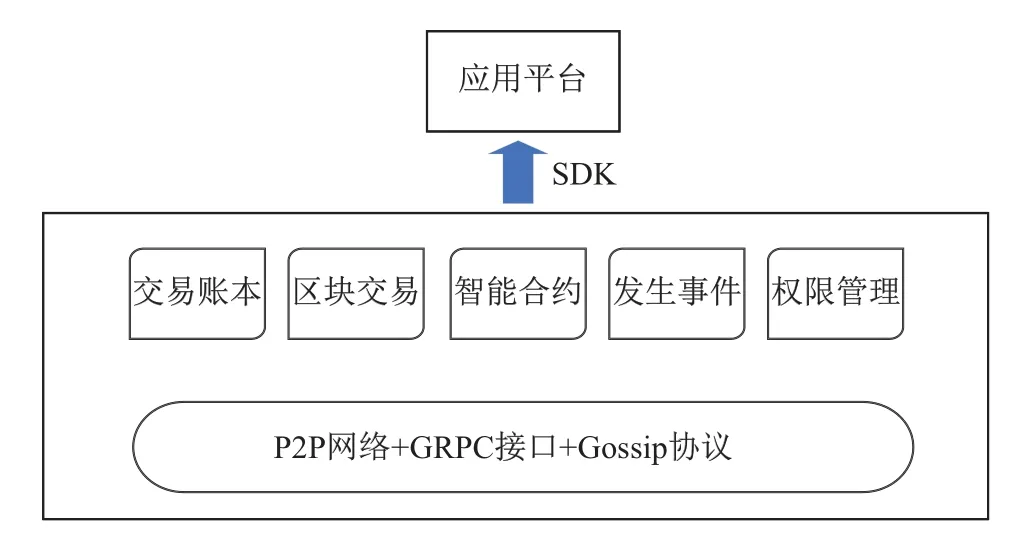
图1 超级账本架构Figure 1 Framework of Hyperledger Fabric
2.2 超级账本交易过程
区块链技术的重要特征之一就是保证实现安全可靠的交易.从收到平台应用的交易请求开始到完成交易数据上链的整个流程中,超级账本中不同类型的节点会执行不同的任务流程.超级账本中参与交易过程的实体主要分为平台应用、CA 服务、Endorser 节点、Orderer 节点、Committer 节点[18],各部分的功能如下:
1)平台应用
平台用户是一种应用程序客户端.应用程序客户端访问区块链之前,首先需要调用CA 服务来获取身份证书进行注册,完成注册后才可以通过身份证书对区块链中网络进行相关操作.应用程序在上链时,通过调用SDK 向区块链网络发起一个交易提案(proposal),只有合法有效的交易提案才会被记录到账本当中.
2)CA 服务
CA 是超级账本中的证书颁发机构,是超级账本内一个可选的组件.CA 在实际应用中采用树形分层结构,包含一个根部CA 和至少一个中间CA.CA 的主要功能是对网络内各个实体的身份证书进行管理,负责Fabric 网络内所有实体(identity)身份的注册,负责对数字证书的签发,包括身份证书(ECerts)、交易证书(TCerts)以及对证书的续签或吊销.
3)Endorser 节点
Endorser 节点负责接收来自应用平台的交易提案,对提案完成合法性检验并进行权限控制;确定提案提交者有权执行操作之后,根据背书策略模拟运行交易;完成模拟后的状态变化将会以背书形式返回给客户端程序.
4)Orderer 节点
Orderer 节点在区块链网络中负责排序的作用,将全网中的合法交易进行全局排序,并将排序之后的节点打包成区块,最后发送给Committer 节点.
5)Committer 节点
Committer 节点收到Orderer 节点排序过的批量交易区块后,会再次对区块中的每笔交易进行合法性检查,检查通过后将最终结果写入账本,并且构成新的区块.一个完整的超级账本的交易记账流程如图2所示.
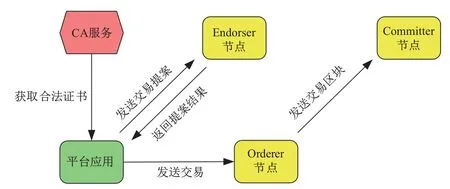
图2 超级账本交易流程Figure 2 Transaction process of Hyperledger Fabric
具体的交易步骤如下:
步骤1平台的用户作为客户端调用SDK 向背书节点发起一个交易请求.
步骤2背书节点收到请求后,调用相应的智能合约模拟执行交易并对结果进行背书,之后将背书结果返回给用户.
步骤3用户再将该结果发送给排序节点,排序节点通过共识机制将交易打包成区块,并交付给提交节点.
步骤4提交节点将区块分发给组织内的记账节点,记账节点验证交易合法性之后即可添加到自身账本当中.
3 系统需求
3.1 功能需求
基于区块链的河长制信息管理系统需要利用区块链技术维护、管理并展示河长制治理工作的相关数据信息.本文按照系统各个业务的内容进行模块化分类,分为河长履职、河湖管理、河湖水质、交互督办、重点工作、在线办公、公众参与和基础信息.各模块及其子模块功能详情如图3所示.
河长履职模块负责展示河长人员信息以及记录市级、区级河长的巡河日志;河湖管理模块主要展示河湖信息、河道治理方案等;河湖水质模块负责对各类河道的水质进行展示与数据统计分析;交互督办、重点工作模块对河湖治理工作的进度、效果、政策进行展示;在线办公模块包含河长工作人员对河湖水质信息的填报、上传与存证,并进行水质检测的公开通知;公众参与模块为公众提供了一个河湖污染情况反馈的平台;基础信息模块支持系统对各个用户、部门、资源、区域划分的统一管理.
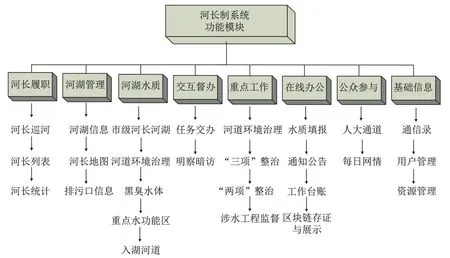
图3 区块链河长制系统功能模块Figure 3 Function modules of blockchain-based river chief-oriented system
系统在线办公模块中的水质填报子功能包含了河长制信息管理系统中的关键数据,这些数据敏感度最高,故需要安全可靠的存储.传统河长制信息管理系统的水质填报操作流程较为简单,部门用户只需填写数据并且上传至中心数据库.本系统利用区块链技术对水质信息的填报功能进行完善,将用户上传的水质信息上传到区块链网络进行存证,并且能够根据区块链中的存证数据进行核验与还原.区块链存证部分是以需要处理的水质填报数据模型为基础,编写智能合约和中间层的代码,并且完成上层REST 接口[19]的封装,为河长用户完成水质信息填报、上传以及区块链存证.河长用户能够从水质填报模块跳转至区块链存证展示模块,可进一步浏览区块链中的交易数、区块数、节点数等状态信息,查询最新水质信息存证记录、水质信息存证变更历史等详细信息.
3.2 安全需求
河长制信息存证系统主要针对河长信息管理系统产生的关键数据进行安全可靠的存证,主要安全需求包含如下内容:
1)系统运行安全
在系统组件运行过程中出现程序崩溃、节点异常的情况下,系统能够具备一定的容错性,保障数据存证与查询服务一切正常.
2)数据库存储安全
数据库用户访问时应具备密码访问安全性.
3)操作数据可追溯
对于敏感数据的操作需要在系统后台进行日志处理,追溯该类数据的变化情况,并且对于某类关键操作需要进行安全审计.
4)系统防御安全性
可防御一般的恶意攻击和病毒入侵.
5)用户权限安全
对于不同身份的用户,系统需要设置不同的操作权限.管理员用户可以在水质信息模块填报、上传、存证、核验、恢复数据,并且在水质信息存证的同时能够将用户信息也保存至区块链中;普通用户调用存证接口将提示权限不足或存证失败,只能通过区块链的存证模块查询相关水质信息.
4 系统设计
4.1 系统架构
基于区块链的河长制信息管理系统是以数据安全存证、展示为核心的.系统根据平台数据的来源类型可以划分为静态数据和动态数据,前者是纸质化保存下来的数据,后者是通过实时考察、民众反馈等多媒体形式上传提交的数据.平台以这些数据为基础,并根据功能层次的不同将系统架构划分为应用层、支撑层、数据层、硬件和网络环境层、数据采集层.
1)应用层
应用层以Web 的形式展现系统各个功能模块.
2)支撑层
支撑层为应用层数据提供支撑服务,包括河湖地理环境服务、监控数据采集服务、数据分析服务、实时在线数据服务;
3)数据层
数据层负责数据存储.
4)环境层
环境层提供平台运行时所需要的网络和硬件环境;
5)采集层
采集层以静态或动态方式获取数据并上传至系统.
详情如图4所示.

图4 区块链河长制信息管理系统架构Figure 4 Architecture of blockchain-based river chief-oriented information management system
4.2 智能合约设计
系统数据层所依赖的区块链分布式存储环境是基于超级账本构建的联盟链.系统建立在4 台云服务器上,通过Docker 容器部署并启动4 个节点[20].联盟链采用Kafka 共识机制实现区块链账本状态的强一致性,并通过编写智能合约实现对区块链账本的读写操作.智能合约以逻辑代码的形式运行在区块链节点中,是超级账本中间层与区块链网络资源交互的必要途径.本系统使用Go 语言实现合约开发,开源集成库Shim 和Peer 可用来完成二次开发.本智能合约的核心算法逻辑包含水质信息上链存储和链上查询两部分.
算法1智能合约水质信息存储
中间层通过GRPC 请求传输参数调用相应智能合约,数据以JSON 数组的形式传给智能合约.本算法以安全而简洁的方式将JSON 数据转换成字节流,并以数据ID 字段为键值写入分布式账本.算法需要对JSON 数据进行合法性、完整性检查,并通过Go 语言自带安全的JSON 库将JSON 数据解析到对象中,再将对象序列化成JSON 字节流保存到分布式账本中,从而通过返回序列化成功与失败来实现JSON 数据的合法性以及完整性检查.算法关键步骤如下.
步骤1获取shim.ChaincodeStuInterface 中的参数D,检查D是否合法并且是否包含一个ID 和一个JSON 对象.若不满足条件,则返回失败.
步骤2调用JSON 库的Marshall 函数将JSON 解析成对象Obj,检查解析是否成功.若不成功则返回失败,再调用函数将对象Obj 序列化成JSON 字节流.检查序列化是否成功,若不成功则返回失败.
步骤3若步骤1 和2 结果成功,则调用shim.putState(ID, bytes)将字节流保存到账本中.
智能合约水质信息存储算法的详细流程如图5所示.
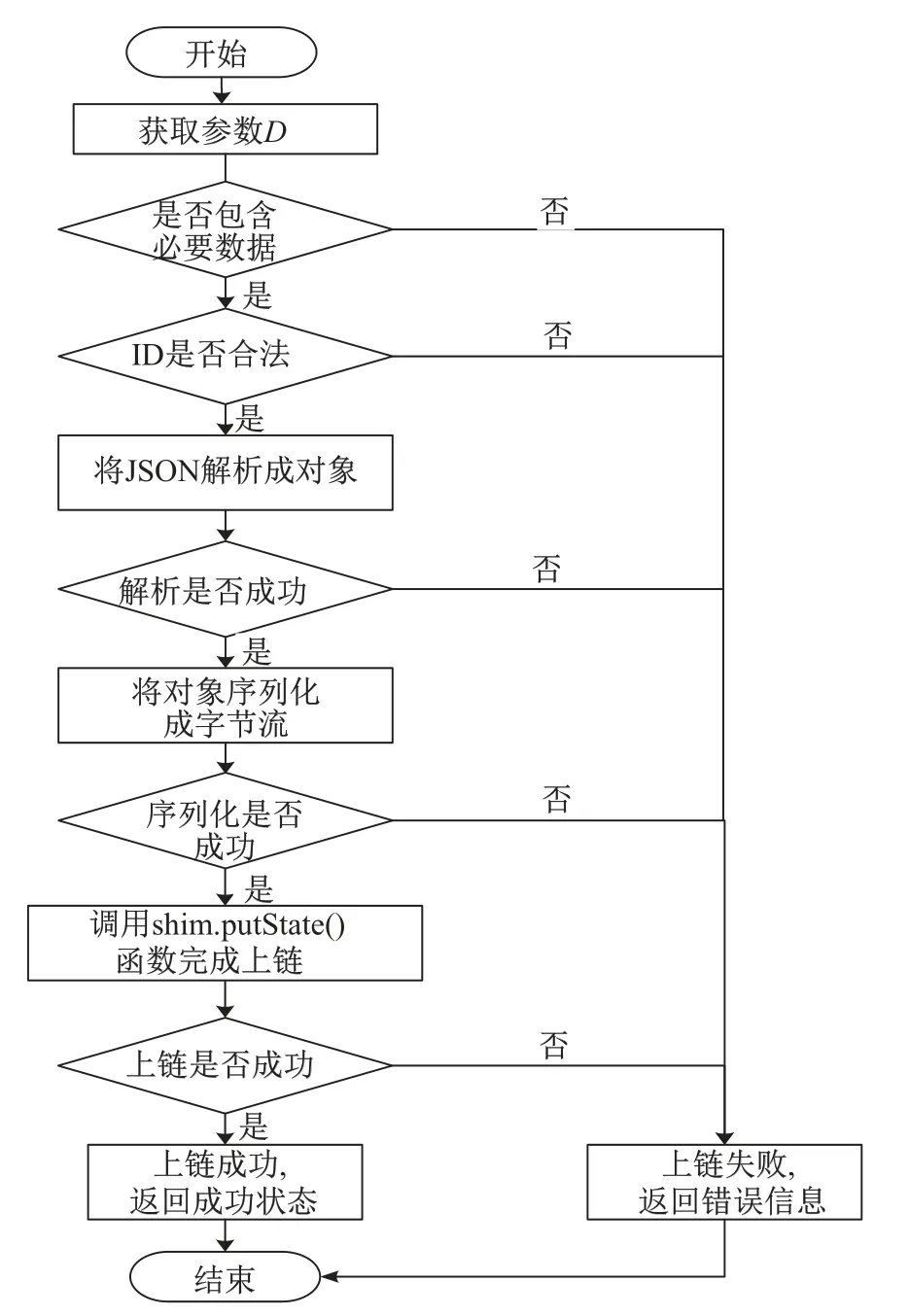
图5 基于智能合约实现水质信息存储的流程Figure 5 Flow chart of water quality information storage algorithm based on smart contract
算法2智能合约水质信息查询算法
本系统将超级账本的节点状态数据库设置为LevelDB[21],超级账本通过中间层发送的查询请求也为JSON 数据的格式,其中包含查询索引.查询存证数据需要基于数据的ID 字段或者哈希值实现,本智能合约水质查询算法关键步骤如下:
步骤1首先需要检查数据索引I的合法性,若数据合法,则继续执行查询步骤;若不合法,则返回失败结果.
步骤2调用shim.GetState()函数获取账本数据D,检查函数调用是否成功.若调用成功,则将序列化成功后的对象值返回;若函数调用失败或序列化失败,则返回失败结果.
水质查询算法的详细流程如图6所示.
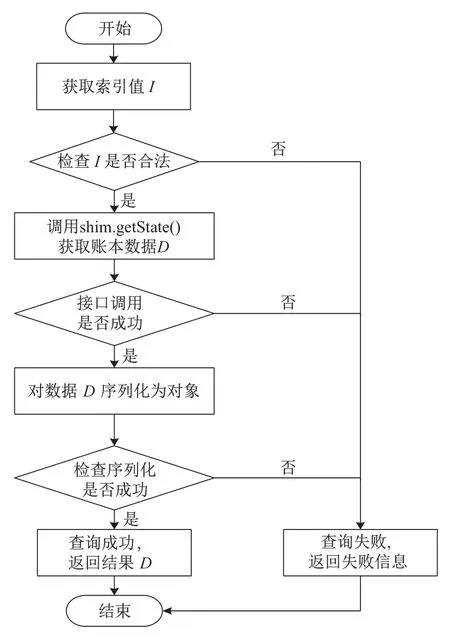
图6 基于智能合约的链上查询流程Figure 6 Flow chart of data query algorithm based on smart contract
4.3 中间层设计
中间层是智能合约和应用层交互的桥梁,负责接收应用层的客户端请求并调用已完成的智能合约代码.中间层在合约调用过程中严格限制操作权限,只有管理员用户才能使用水质信息的存证功能,普通用户只能查询链上存证数据.本系统中间层基于Fabric-go-sdk 设计开发,在智能合约完成基本的存储、查询逻辑的基础上进一步完善中间层的相关功能.为实现高效的用户权限管理以及向上接口服务,中间层将实现数据上链和查询的两种算法.
算法3中间层水质信息上链算法
本系统应用层以Web 的形式为用户提供服务,因此中间层采用RESTful 风格的API 接口.在数据传输时,以HTTPS 搭载JSON 数据为安全传输机制防止黑客攻击.JSON 数据包含一个索引,由数据在中心数据库的表名和数据的ID 字段构成.当算法检查用户权限时,从CA 查询用户是否为管理员,只有管理员用户才能使用水质数据存证功能.本算法的关键点在于:用户注册之后将私钥保存在用户账户下,当用户发起数据存证的请求提案时,使用用户的私钥对提案进行签名,且提案在交易验证阶段必须通过用户公钥验证才能写入账本.用户登陆后,采用JWT 技术[22]保持用户的在线状态的检测.中间层水质信息上链算法的详细流程如图7所示.本算法的关键步骤如下:
步骤1在区块链上部署智能合约,完成用户的注册和登录.初始化连接Channel 并完成Peer 节点和Orderer 节点的实例化.
步骤2将需要上传的水质数据D1、调用合约名和合约函数封装成一个请求体数据包,调用getUserContext(user)函数,查看当前用户信息是否存在或已经登陆过.若不存在或未登录,则返回失败结果.
步骤3查询用户是否在区块链网络中具有管理员身份.若不是,则返回失败状态.
步骤4调用peer.sendTrasactionProposal()向背书节点发送交易提案.若提案失败,则返回失败.
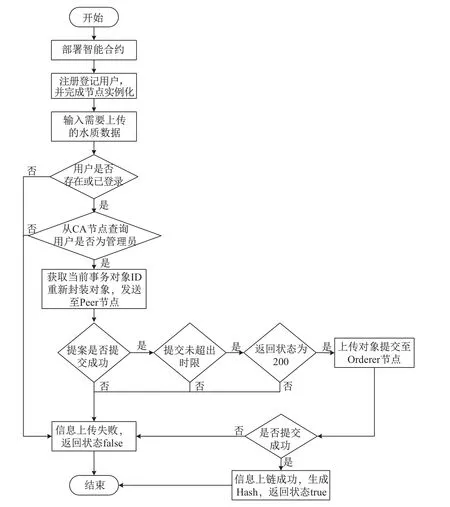
图7 中间层水质信息上传算法流程图Figure 7 Flow chart of algorithm for intermediate layer water quality information uploading to chain
步骤5设置定时器,判断提案是否超时.若超时,则返回失败.
步骤6获取背书结果并且封装新的交易请求体request,通过调用系统内部的封装函数channel.sendTrasaction(request)将交易请求提案给Orderer 节点.
步骤7获取新提案的返回状态,根据状态判断上链是否成功.若成功,则返回成功结果值交易提案的Hash;若提案不成功,则返回失败结果.
算法4中间层水质信息查询算法
由于区块链上的数据对所有用户公开透明,本算法需获取用户登陆后在CA 服务商的证书身份来参与水质信息的查询.当用户发起查询请求时,算法针对用户身份和查询内容进行判断,根据请求中的数据ID 或者交易的Hash 进行链上查询.算法关键步骤如下:
步骤1初始化Channel,并且完成Peer、Orderer 节点的代理.
步骤2将水质查询的请求参数中的Hash 或者ID 同链码名和函数名封装成一个request对象.
步骤3调用函数getUserContext(user),判断当前用户是否存在或登录.若不满足条件,则返回失败结果.
步骤4通过调用SDK 函数channel.queryByChaincode(requset)获取查询结果,判断链上查询结果是为空.若不满足条件,则返回操作状态和查询结果.
中间层水质信息查询算法的详细过程如图8所示.
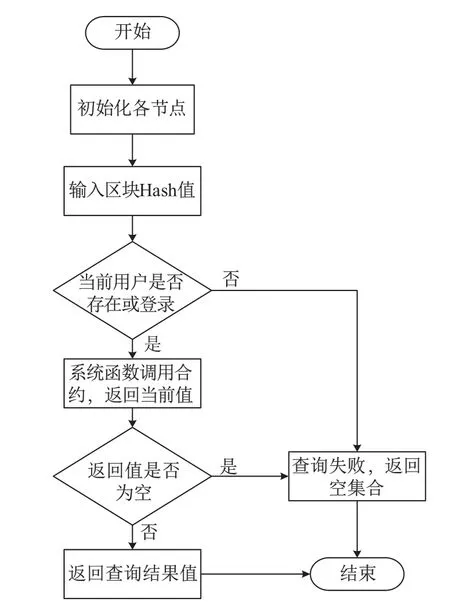
图8 中间层水质信息查询算法流程图Figure 8 Flow chart of algorithm for intermediate layer water quality information query
中间层向应用层提供封装的RESTful 风格的API 接口,供应用层调用.为实现本系统区块链存证模块以及区块链信息展示模块,设计相关接口以提供区块链相关数据存储与查询服务,所设计的功能接口如表1所示.

表1 RESTful 接口设计Table 1 RESTful API design
5 性能测试及分析
5.1 测试场景
本系统部署在4 台2 核4G 的Linux 云服务器上,并在服务器上搭建了超级账本联盟链网络集群.集群由多个分布式节点构成,超级账本中的节点类型有Orderer 和Peer 两种.Orderer 节点连接到Kafka 集群,利用Kafka 的共识功能完成交易的排序和打包.Peer 节点负责记账,在集群中负责承担交易背书、完成与Orderer 节点的通信、区块验证等功能.集群的各个节点通过Docker 容器部署在Linux 系统中,每个Orderer 和Peer 维护单独的账本数据,并且需要通过CA 管理节点的准入权限.物理节点上的具体部署情况如表2所示.

表2 物理节点部署方案Table 2 Deployment scenario of physical node
5.2 水质信息存证测试
本系统使用Postman 作为链上信息存证测试工具.Postman 可以模拟客户端发送任意HTTP 网络请求,接收服务端的正常响应并显示出返回的完整数据.对于链上信息存证,使用Postman 发送HTTP 请求到后台服务器,并且接收后台响应的JSON 格式的数据.若在响应数据中包含了区块链上链产生的特征哈希值,并且可以使用该值查询到原先上链的完整数据,即可证明系统的存证功能测试通过.
首先将需要上传的水质信息封装成JSON 格式的数据,在测试工具中填写对应服务器IP、端口、路径和请求方式.使用工具发送请求后获取到的后台响应结果如图9所示.
可以看出:水质信息已作为一笔交易成功添加到区块中,并且系统会返回此交易对应的具体交易ID 作为其存在于区块链的特征属性值.获取此交易ID 值后再次以Postman 工具修改路径和请求方式,以交易ID 作为参数向服务器发送一笔新的查询请求,后台相应结果如图10所示.

图9 水质信息上链接口测试结果Figure 9 Test results of water quality information uploading to chain interface
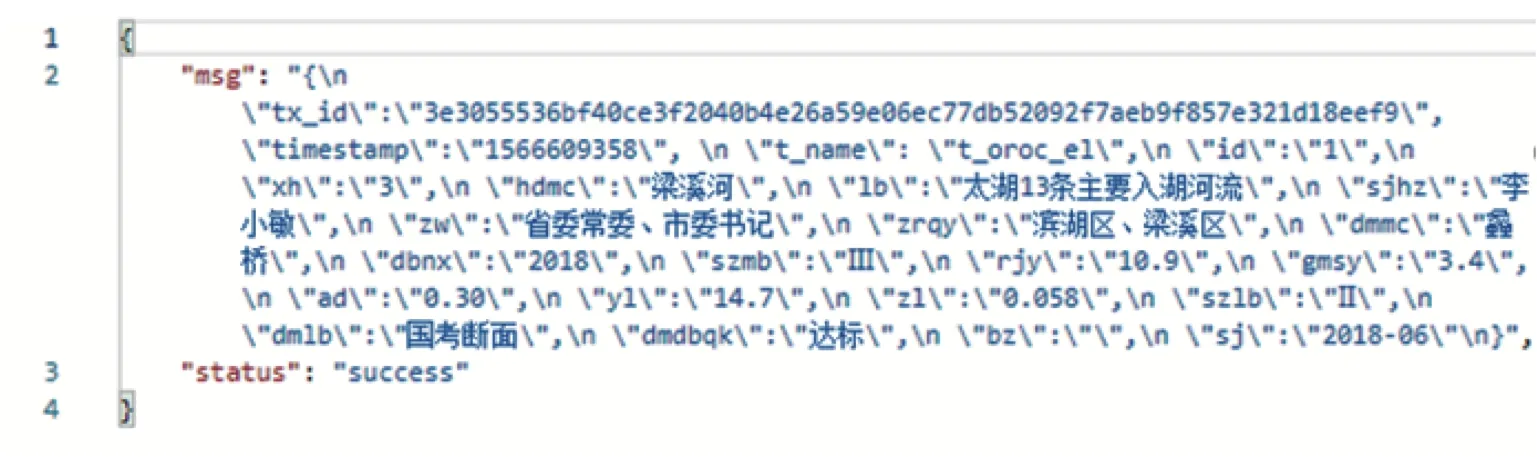
图10 水质信息查询接口测试结果Figure 10 Test results of water quality information querying interface
查询结果不仅包含已上传的水质相关信息和特征值交易ID,还包括此条交易在经过Orderer 节点排序后产生于区块中的时间戳,证明其在链上的存在性.
5.3 区块链性能测试
系统底层区块链性能测试使用压力测试工具JMeter,该工具运行需要依赖JAVA 运行环境,在测试前需先安装JDK.本测试工具通过建立多线程组并设置请求时间,在设定时间范围内的每个线程都会单独发送一次请求,从而模拟多用户同时在线对Web 服务器接口调用的并发场景.每秒产生的并发量对于调用功能接口会产生相当大的负载量,用此工具测试本系统中的上链和查询接口,并且通过测试结果中接口调用成功率、每秒的平均交易事务量S吞吐量(transaction per second, TPS)和交易平均响应时间tRTT(round-trip time, RTT),进一步分析系统底层区块链的性能.
系统使用JMeter 分别对系统的资源上链接口和链上查询接口进行5 组不同数量级的压力测试.首先设置线程组数分别为1 000、1 500、2 000、2 500、3 000,并且设置请求间隔时间为1 s;接着设置Http Request 为测试样本,添加服务器IP、端口号、请求方式、请求参数等信息;最后为测试添加监听器,由监听器选择测试总结报告和TPS 测试报告作为最终测试结果.经过5 组测试获取的结果如表3所示.
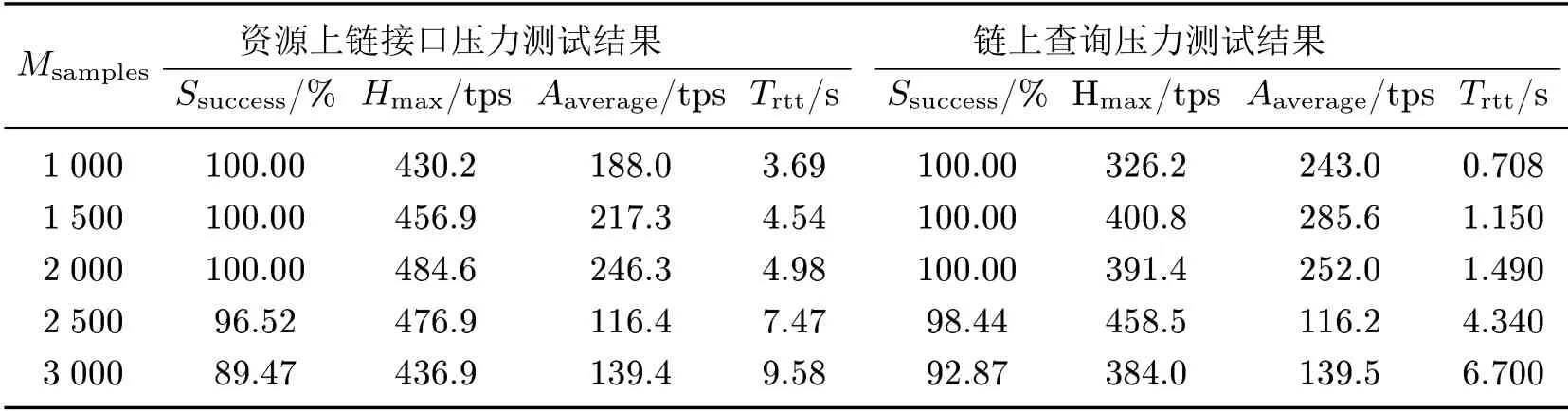
表3 RESTful 接口压力测试结果汇总表Table 3 Summary of RESTful interface stress test results
综合测试结果,选取模拟用户组数为2 000 的测试结果作为本次系统的最优测试情况,其对应的上链接口的测试总结报告详情如表4所示.

表4 2 000 线程数的上链接口压力测试表Table 4 Uploading to chain interface pressure test table with 2 000 threads
经过测试得到以下结果:2 000 次用户并行请求对接口的调用成功率为100%,每笔交易的响应时间为4.98 s,每秒吞吐量可达到246.3 tps,最高每秒吞吐量可达484.6 tps.具体的TPS 测试报告如图11所示.
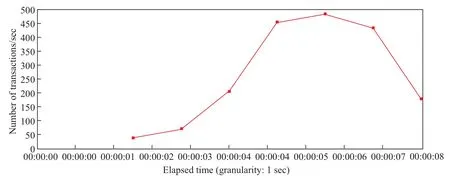
图11 线程组数为2 000 的数据上链接口的TPS 测试报告Figure 11 Data uploading to chain Interface throughput test report with thread group number 2 000
测试报告中对应的并行2 000 次查询接口压力测试的报告如表5所示.报告显示:接口的调用成功率为100%,每笔交易的响应时间为1.49 s,每秒吞吐量可达252.0 tps,最高每秒吞吐量为391.4 tps.具体的TPS 测试报告如图12所示.
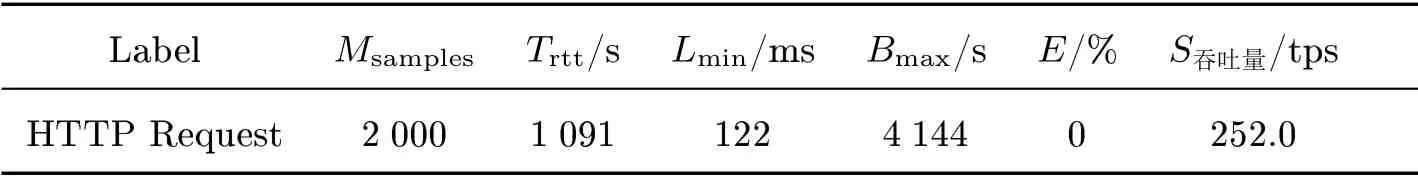
表5 2 000 线程数的查询接口压力测试Table 5 Query interface stress test with 2 000 threads
综合接口功能验证情况和接口压力测试报告可看出:本文提出的河长制信息管理系统能够满足对关键水质信息的链上存证的功能,并在接口承载一定压力的情况下,平均每秒的交易吞吐量可达200 tps,最高可达500 tps,接口的调用成功率较高,可以满足一般性的系统要求.
6 结 语

图12 线程组数为2 000 的数据查询接口的TPS 测试报告Figure 12 TPS test report of data query interface for 2 000 threads
本文将区块链技术与“河长制”相结合,将河长制系统中重要的水质填报信息放在区块链中存储,并且向用户提供链上数据存储证明的功能接口.使用区块链对河长制数据信息加以备份,可以有效防止数据篡改.详细的功能测试结果表明本系统具备完善的水质存证功能,系统用户不但可以将水质信息上传至区块链网络环境,而且可以查询链上水质信息的详情以及追溯某条水质信息的历史变更情况.系统的数据上链和链上查询的压力测试结果也表明,在一定量用户同时在线的场景下,系统接口的调用成功率较高,同时每秒处理的事务能力和平均响应时间均可满足正常的业务需求.
猜你喜欢
选煤技术(2022年2期)2022-06-06 09:13:12
煤气与热力(2021年12期)2022-01-19 05:19:38
当代党员(2019年19期)2019-11-13 01:43:29
中国交通信息化(2019年7期)2019-10-08 09:04:36
四川环境(2019年6期)2019-03-04 09:49:00
山西水利(2019年4期)2019-02-14 14:27:22
学生天地·小学中高年级(2018年10期)2018-12-13 02:45:34
小学生导刊(2018年31期)2018-12-06 08:36:42
消费导刊(2018年10期)2018-08-20 02:56:52
小学科学(学生版)(2018年1期)2018-01-31 01:51:45
