
改进回溯搜索优化回声状态网络时间序列预测①
2020-01-15 06:45:32肖治华廖荣涛
计算机系统应用 2020年1期
胡 率,肖治华,饶 强,廖荣涛
(国网湖北省电力有限公司 信息通信公司,武汉 430077)
现实世界中存在各种各样的时间序列数据,分析挖掘数据的隐藏信息,基于合理的假设和推理,建立能够拟合复杂系统行为的模型,并依据该模型对序列未来的发展规律做出估计和判断符合科学规律[1].作为时间序列分析的一个研究分支,时间序列预测在实际中广泛应用.但是,进行时间序列预测依然存在巨大的挑战,主要原因是时间序列数据往往表现出复杂的特性,比如时序性、高维性、非线性和非周期性等.
人工神经网络(Artificial Neural Network,ANN)是一种以数据为驱动的、自适应的人工智能模型,它具有非常良好的非线性映射能力.从理论角度来讲,ANN可以以任意精度无限逼近任何动态系统的行为[2].ANN几乎能够模拟任何线性和非线性的时间序列数据生成过程,因而成为准确且应用广泛的预测模型[3].
2004年,Jaeger等[4]提出了一种全新的递归神经网络——回声状态网络(Echo State Network,ESN).ESN最显著特征是网络训练过程简单:只有储备池(隐藏层)到输出层的输出连接权值矩阵需要计算,其他各层之间的连接权值矩阵在网络初始化阶段随机生成并保持不变.ESN能够克服传统递归神经网络的网络结构难以确定、训练效率低下、收敛速度慢、容易陷入局部最优等缺点,因而应用广泛.例如网络流量预测[5]、变风量空调内模控制[6]和非线性卫星信道盲均衡[7]等.标准的ESN在计算输出连接权值矩阵时会采用最小二乘估计或者岭回归等线性方法,这类方法在节约计算成本的同时会造成网络过拟合.因此,对ESN的输出连接权值矩阵进行优化以提升其性能具有现实意义.
本质上,对ESN的输出连接权值矩阵进行优化是一个离散、高维和强非线性的复杂问题.研究指出进化算法(Evolutionary Algorithm,EA)在解决此类问题时性能卓著.宗宸生等[8]运用改进粒子群算法优化 BP神经网络的初始权重,建立粮食产量预测模型,该模型具有更高的预测精度和较大的适应度.朱海龙等[9]利用GA优化 BP神经网络的初始权值和阈值进而建立胎儿体重预测模型,模型收敛速度和预测精度都得到提升.针对ESN的优化,田中大等[5]利用经典的GA对ESN储备池参数进行优化,进行网络流量预测时获得不错的精度.Chouikhi等[10]应用PSO对ESN的固定权值矩阵进行预训练,以降低连接权值矩阵在具体应用问题上的随机性.也有学者使用进化算法对ESN的储备池到输出层之间的连接进行优化,例如Wang等[11]提出使用BPSO对ESN的储备池到输出层之间的连接进行优化,优化模型在系统识别和时间序列预测问题上获得更好的实验结果.本文将从提升ESN的预测精度出发,提出使用自适应回溯搜索算法(Adaptive Backtracking Search Optimization Algorithm,ABSA)对ESN的输出连接权值矩阵进行优化.
1 相关知识
1.1 回声状态网络
回声状态网络因为其相对简单的网络结构、训练算法和性能而广受关注.ESN是储备池计算方法之一,采用“储备池”作为信息处理媒介,储备池将网络的输入信号映射到高维的复杂动态状态空间.储备池的神经元之间的连接在网络初始化阶段随机生成并在整个训练过程中保持不变[12].正是由于储备池计算特征,ESN相对于传统的RNN具有明显的优势.标准结构的ESN如图1所示,可以分为3个组成部分:一个输入层(K个神经元),一个储备池(N个神经元)和一个输出 层(L个神经元).
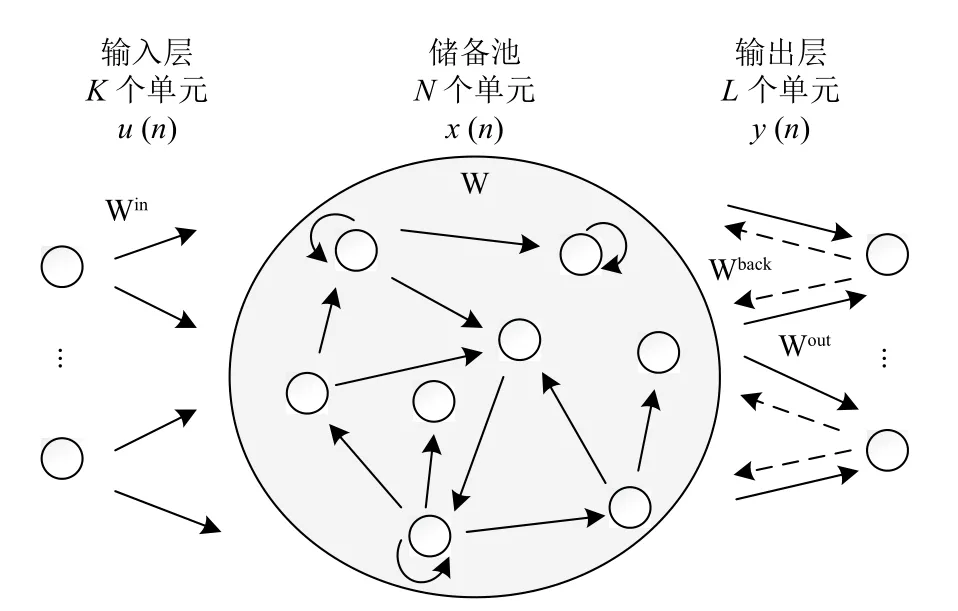
图1 回声状态网络的标准结构
ESN在时刻n的输入,储备池神经元的状态和输出层神经元输出分别表示如下:
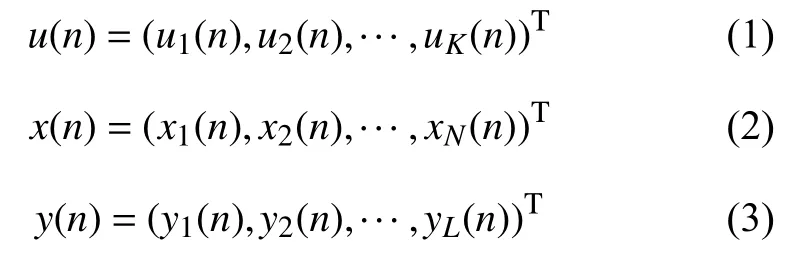
如图1所示,在标准结构的ESN中,当输入信号u(n+1)输 入到网络时,储备池内部神经元在时刻n+1的状态和网络的输出分别按照方程(4)和(5)进行更新:
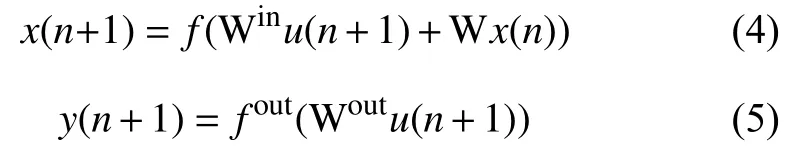
其中,Win(Win∈RN×K)、W (W∈RN×N)和Wout(Wout∈RL×N)分别代表网络的输入层到储备池、储备池内部神经元和储备池到输出层之间的连接权值矩阵.f=[f1,f2,···,fN]表示储备池中神经元的输出函数.一般来说,fi(i=1,2,···,N)采用“S-型”函数,比如双曲正切函数 tanh .fout=[f1out,f2out,···,fLout]表示网络输出层神经元的输出函数.通常情况下,fiout(i=1,2,···,L)会取恒等函数.
1.2 回溯搜索算法及其改进
回溯搜索算法(Backtracking Search optimization Algorithm,BSA)是由Civicioglu在2013年提出的一种属于进化算法范畴的新智能算法[13].BSA自从被提出就吸引了众多学者进行研究并应用到不同的领域,比如数值优化[13,14]、自动发电控制[15]和功率流[16]等.标准的BSA主要包括5个基本算子:初始化(Initialization)、选择I (Selection-I)、变异(Mutation)、交叉(Crossover)和选择II (Selection-II),其算法流程如图2所示.
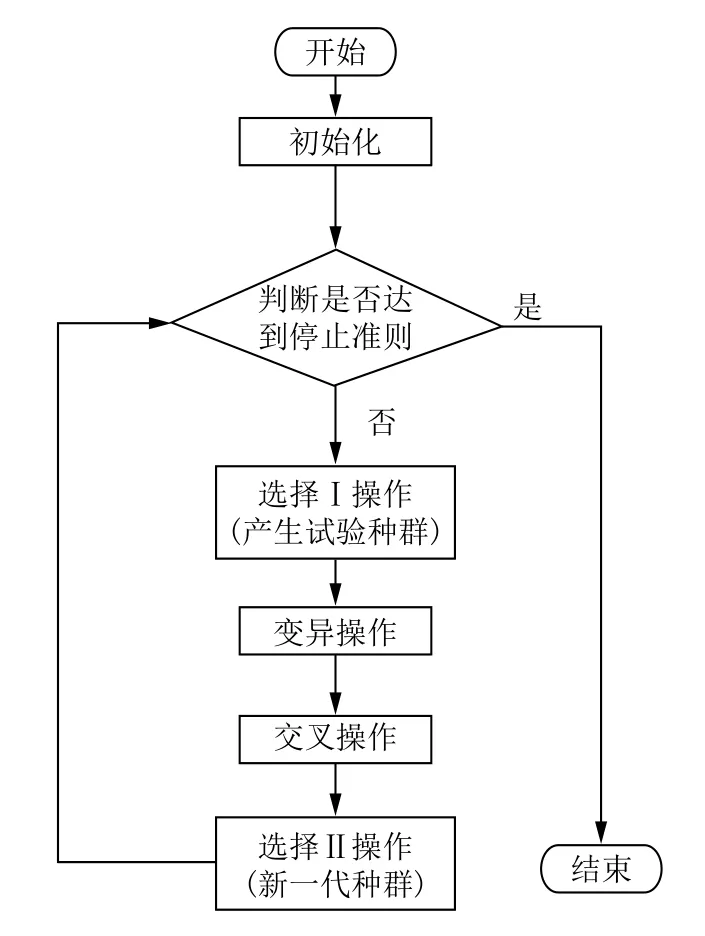
图2 标准BSA算法流程
在标准BSA中,变异因子F在初始化过程中随机给定并在整个过程中保持不变,这种策略不能平衡BSA算法的搜索能力和收敛性之间的关系.如果变异因子F取值大,BSA的全局搜索能力会很强而获得的全局最优解可能展现出低精度.如果变异因子F取值小,BSA在迭代过程中会加速收敛而其全局搜索能力会减弱.可以说,变异因子F是平衡BSA的全局搜索能力和收敛性的关键参数.为了充分考虑变异因子F对BSA性能的影响,本文提出自适应回溯搜索算法(ABSA).ABSA使用自适应变异因子策略去替换标准的随机给定策略,其策略方程表达如式(6)所示:
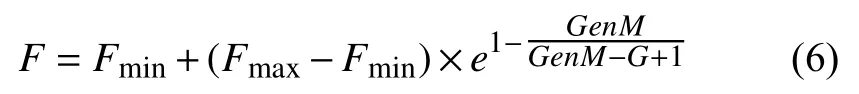
其中,Fmax和Fmin分别代表变异因子F的最大值和最小值.GenM是BSA的最大迭代次数,G是当前迭代次数.e是自然常数.从式(6)可以得出:变异因子 的取值是随算法迭代过程的进行而不断改变的.在开始迭代阶段,F取值较大用于扩大搜索范围,保证搜索时种群的多样性;在随后的迭代过程中,变异因子F取值逐渐变小,种群的搜索范围将缩小且种群中已经获得的优秀个体将会以较大概率被保留.
2 预测模型
2.1 模型介绍
为了验证本文拟采用的自适应回溯搜索算法优化回声状态网络(ABSA_ESN)的性能,将设计其他的四种预测模型用于与ABSA_ESN进行比较.具体而言,本文将设计以下5种预测模型:
(1)ESN.标准的ESN模型.
(2)GA_ESN.使用遗传算法(Genetic Algorithm,GA)优化ESN输出连接权值矩阵.
(3)DE_ESN.使用差分进化算法(Differential Evolution,DE)优化ESN输出连接权值矩阵.
(4)BSA_ESN.使用标准回溯搜索算法(BSA)优化ESN输出连接权值矩阵.
(5)ABSA_ESN.使用自适应回溯搜索算法(ABSA)优化ESN输出连接权值矩阵.
以上5种预测模型中,GA_ESN、DE_ESN、BSA_ESN和ABSA_ESN是四个优化的ESN模型.其中,GA、DE、BSA和ABSA都属于进化算法(Evolutionary Algorithm,EA)的范畴.
2.2 ESN的优化流程
利用ABSA (GA,DE或者BSA)优化ENS的输出连接权值矩阵Wout的流程图如图3所示.
ESN的Wout优化流程分为以下几个步骤:
Step 1.设置ESN参数并收集网络输入产生的状态矩阵.
Step 2.设置ABSA (GA,DE或BSA)的参数并生成初始化种群.设置ABSA的初始迭代代数G=0.
Step 3.判断ABSA (GA,DE或BSA)的迭代是否达到最大迭代次数.如果当前迭代次数G等于最大迭代次数GenM,则ABSA (GA,DE或BSA)的迭代过程结束,获得最优种群和最优个体;否则,流程继续执行.
Step 4.依次执行ABSA (GA,DE或BSA)的选择I (或没有)、自适应变异(或变异)、交叉和选择II (或选择)等几个操作,获得当前迭代过程G的新种群.
Step 5.计算新种群中每个个体的适应值,按照贪婪选择原则更新当前迭代过程的种群.比较当前迭代过程获得的最优个体与当前获得的全局最优个体的适应值,适应值较小的将作为新的全局最优适应值且相应的个体更新为全局最优个体.
Step 6.更新G=G+1.返回Step 3.
Step 7.将进化算法获得的最优个体设置为ESN的最优输出连接权值矩阵Wout,ESN网络训练完成.
Step 8.将测试集中样本按顺序输入到训练好的E SN中,进行预测.
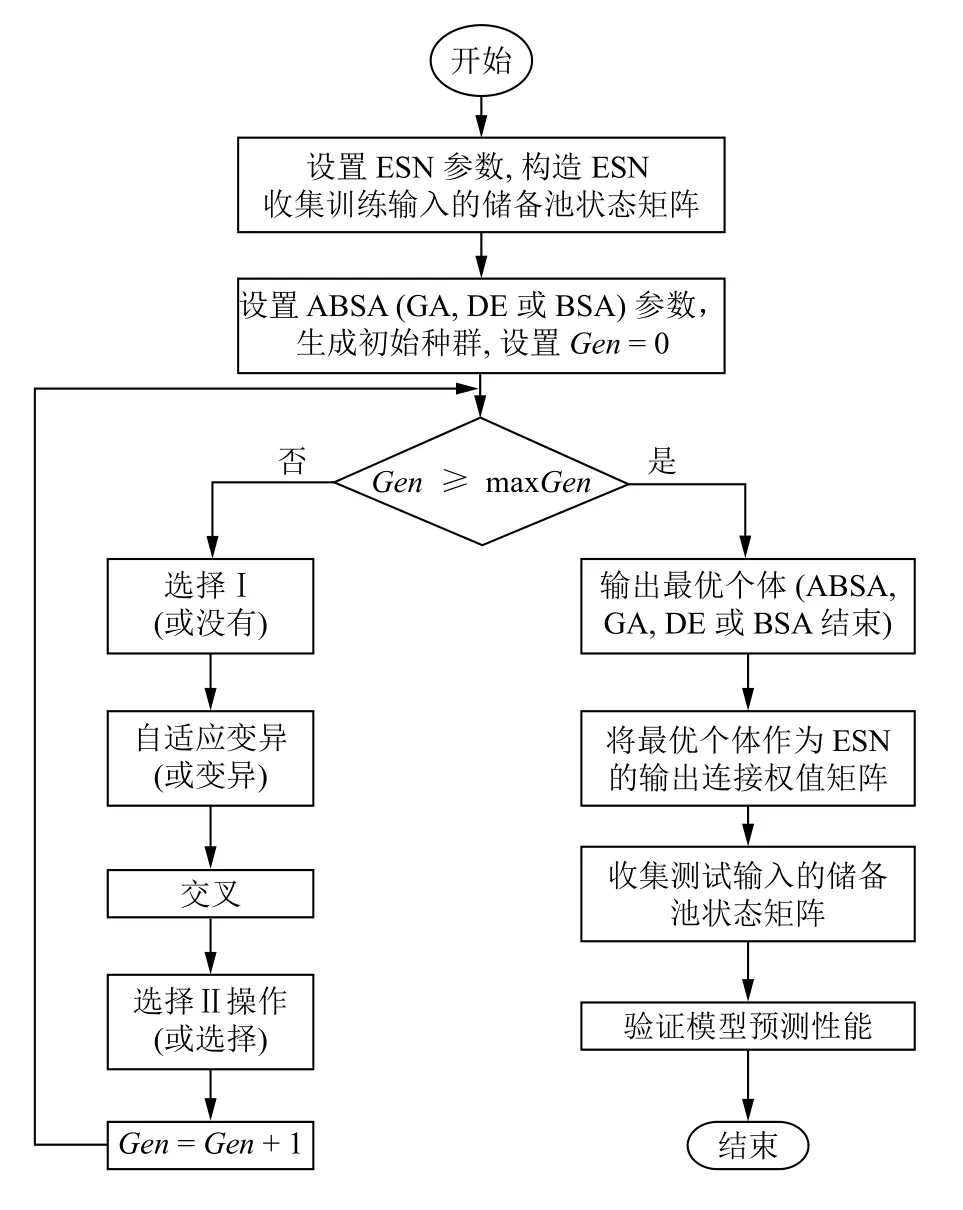
图3 利用ABSA (GA,DE或BSA)优化ESN的Wout的流程图
2.3 模型合理性分析及模型比较
本文所采用的5种模型的建模方法在上述2.1和2.2小节已经介绍.本小节将对5种模型进行比较并讨论选择它们的合理性.
(1)ESN是最先进的时间序列预测模型之一.ESN因为其网络结构简单、训练效率高且耦合“时间参数”,因而能够有效地应用于时间序列预测问题研究.然而,标准的ESN计算地输出连接权值矩阵容易致使网络陷入过拟合状态,影响ESN性能的发挥.
(2)GA_ESN,DE_ESN和BSA_ESN是优化的ESN预测模型.GA、DE和BSA 3种智能算法的算法流程、算子和参数个数不尽相同.使用3种智能算法对ESN进行优化的目的是克服标准ESN容易陷入网络过拟合状态的缺陷,增加优化方法的多样性.相对于GA和DE,BSA在全局寻优时只有一个参数需要设定,在很大程度上能够简化算法参数设置过程,进而节约计算成本.
(3)ABSA_ESN是采用改进BSA优化的ESN预测模型.标准BSA的参数变异因子在算法初始化过程中随机给定并在整个过程中保持不变,这种策略难以平衡BSA算法的搜索能力和收敛速率.ABSA是采用自适应变异因子策略改进的BSA,其能够有效地克服上述缺陷.具体而言,ABSA在迭代初期变异因子取值较大,能够扩大搜索范围从而保证种群的多样性.此时,ABSA的收敛速度较慢且收敛精度较低.随着迭代过程的进行,变异因子的取值将逐渐变小,种群的搜索范围将围绕已经获得的优秀个体展开以保证优秀个体将会以较大概率被保留.此时,ABSA的收敛速度和收敛精度逐步加快和提高.总体而言,ABSA_ESN在算法的参数设置、收敛速度和收敛精度上较GA_ESN,DE_ESN和BSA_ESN等均有优势.
3 数值实验和结果分析
3.1 实验设置
为了验证本文所提出的ABSA_ESN和其他四个用于对比的模型预测性能,两个混沌时间序列将被采用作为实验数据集.完成所有实验的个人电脑配置如下:操作系统是64位Windows 10专业版、处理器是Intel(R)Core(TM)i7-7700 CPU @3.6 GHz和内存为16 GB.运行实验的软件环境是Python 3.6和Matlab 2016b.
3.2 数据集及性能评估标准
本文将采用两个混沌时间序列数据集用于验证所提出的五种预测模型的性能.第一个混沌时间序列是非线性自回归滑动模型(Nonlinear Autoregressive Moving Average,NARMA),这是一种有输入的非线性自回归移动平均数数列,该模型已经成功应用于非线性系统[17].第二个混沌时间序列是Mackey-Glass时间序列[18].以上两个时间序列模型经常被使用作为测试时间序列预测算法的性能.
3.2.1 NARMA模型
NARMA模型方程式表示如下:
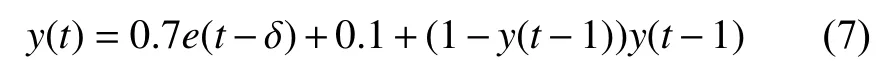
其中,e(t)为独立分布在( 0,1)之 间的时刻t的模型输入,y(t)是时刻t的模型输出,δ 为时滞参数.通常取δ =3.
在本实验中,我们设定NARMA模型的样本大小为1000.训练集、验证集和测试集样本的产生过程如下:首先,随机产生1000个取值范围在( 0,1)的样本作为系统输入e(t).根据式(7)计算出NARMA方程式相应的期望输出y(t).第二,分别取系统输入样本和期望输出样本的前80%(样本编号1–800)样本作为训练集样本.第三,紧接着选取10%(样本编号801–900)样本作为确定回声状态网络模型结构的验证样本.最后,选取剩余10%(样本编号901–1000)样本作为预测集样本.本文设计验证集的主要目的是为了在训练阶段选择合适的ESN模型结构.含有1000个样本的系统输入如图4及其对应的系统输出如图5所示.
图4 NARMA模型输入序列
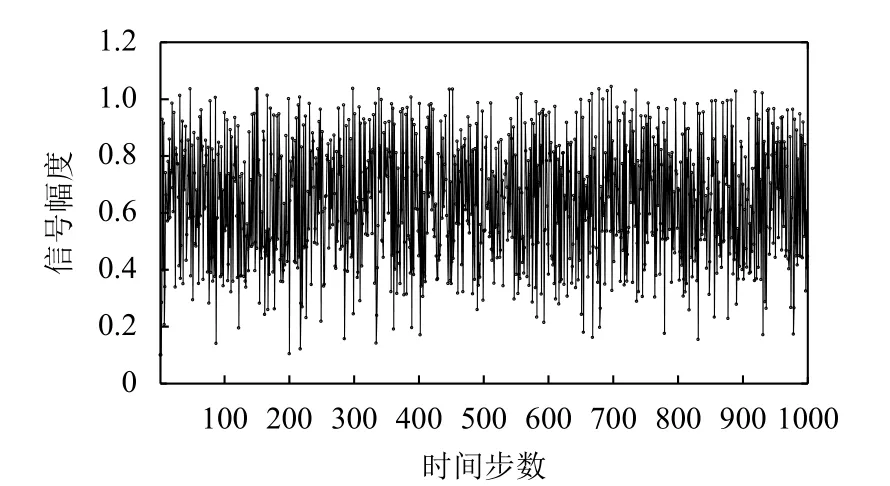
图5 NARMA模型输出序列
3.2.2 Mackey-Glass混沌系统
Mackey-Glass时间序列是从时延差分系统导出,其方程如式(8)所示:
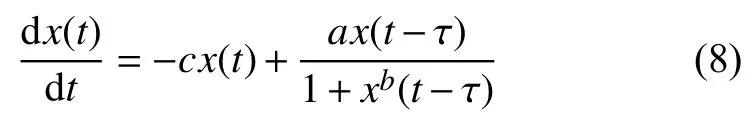
其中,x(t)是时间序列在时刻t时的取值.a、b和c为参数,通常取a=0.2、b=10 和c=0.1.Farmer对Mackey-Glass方程的行为特性做过深入研究,研究结果表明当时滞参数 τ>16.8 时 该方程呈现混沌性,并且τ 值越大,混沌程度越高[19].本文依照一般情况设置时滞参数取值为τ =17.
在本实验中,我们设定Mackey-Glass时间序列样本大小为1000.训练集、验证集和测试集样本的划分同NARMA模型一样,即编号1–800的样本作为训练集,编号801–900的样本作为验证集和编号901–1000的样本作为测试集.使用二阶Runge-Kutta方法以步长为0.1构造的样本长度为1000的时间序列如图6所示.
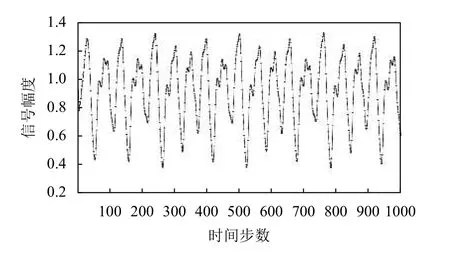
图6 Mackey-Glass时间序列
3.2.3 性能评估标准
用于测量时间序列预测模型性能的指标多种多样,本文将采用均方根误差(Root Mean Square Error,RMSE)作为评估预测精度指标,其定义如式(9)所示:
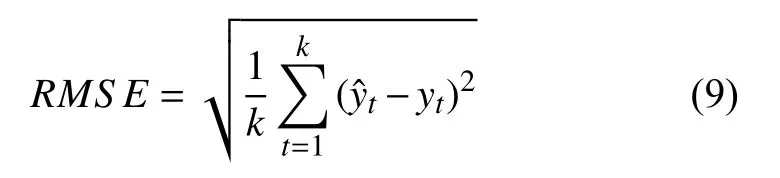
3.3 参数设置与分析
3.3.1 参数设置
本文所提出的预测模型的性能受ESN结构选择和相应参数设置的影响.结合本文所使用的两个时间序列数据集的特点,拟采用ESN的结构参数如下:(1)输入层单元的数目为2(在每个时刻t,ESN有一个常数输入0.1);(2)储备池的大小从集合{ 20,30,50}中选择;(3)输出层单元数目为1.ESN的其它的参数,比如储备池内部连接权值矩阵谱半径SR和储备池稀疏性SP根据已有文献的推荐进行设置,即SR=0.8 和SP=5%[12].输入单元尺度IC及位移尺度IS分别设置为IC=0.3和IS=−0.2.
关于BSA和ABSA的参数设置主要是基于一列实验和已有参考文献的推荐.BSA和ABSA的具体参数设置如下:(1)种群大小均设置为100;(2)最大迭代次数均设置为100;(3)交叉概率mixrate均设置为1.0[13];(4)BSA的变异因子F设置为F=3∗randn(randn∈N(0,1),N(0,1)是标准正太分布)[13],而ABSA的最大和最小的变异因子分别设置为0.9和0.1.另外,GA和DE的参数分别设置如下:(1)种群大小设置为100;(2)最大迭代次数设置为100;(3)交叉概率为0.6;(4)变异概率为0.01.
3.3.2 自适应变异因子F取值分析
ABSA的变异因子F取值如图7所示.从图中可以看出,在算法迭代初期变异因子F取值较大(第一个迭代阶段,F取值为最大设定值0.9).此时,ABSA的种群中的个体以较大概率进行变异,ABSA主要是在种群个体空间中进行全局寻优,形成的新种群个体随机分布在个体空间之中且个体之间的关联性较小.可以说,ABSA在迭代初期的全局寻优能力非常强而局部寻优能力非常弱,种群个体的相似性很小.随着迭代过程的更迭,变异因子F取值逐步减小,ABSA种群中的优秀个体逐渐沉淀并且这些优秀个体以逐渐减小的概率进行变异.此时,ABSA逐渐由全局寻优转变为局部寻优.新种群的形成主要是围绕已经获得的优秀个体进行局部寻优.即随着迭代的进行,ABSA的局部寻优能力逐渐加强而全局寻优能力逐渐减弱,种群个体的相似性逐渐加强.直到迭代进行到后期(图7中的迭代次数达到90次左右),变异因子F取值趋于稳定(最小设定值0.1),ABSA已经由全局寻优过渡到局部寻优.此时,ABSA全局寻优能力非常弱而局部寻优能力非常强.所以,ABSA的自适应变异因子取值策略能够平衡算法的全局寻优能力和局部寻优能力.
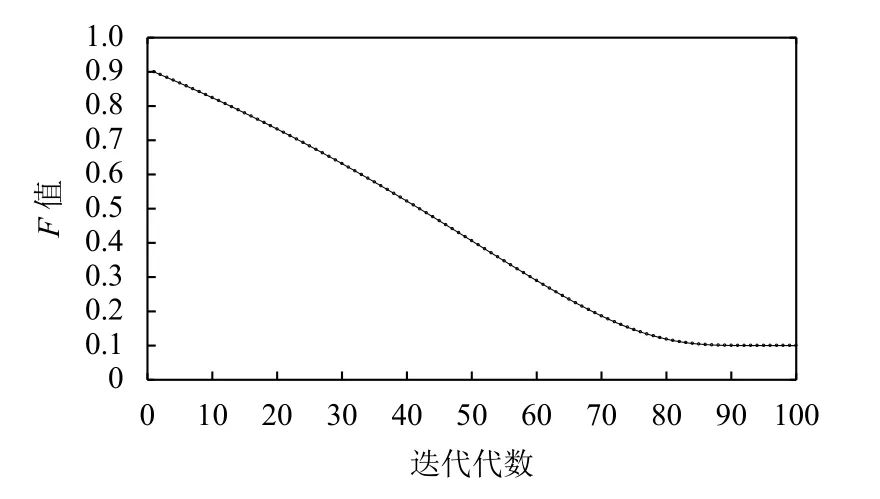
图7 ABSA的变异因子F取值曲线
3.4 参数设置与分析
对于本文所使用的5个预测模型中的每个预测模型,在训练阶段由于ESN储备池大小不同而会设计3个候选模型结构,并且根据验证集的结果选择一个最优模型结构作为该预测模型的最优结构.表1给出所有5种预测模型的最优模型结构.5种预测模型在两个时间序列数据集上的性能分别如图8 (NARMA模型)和图9 (Mackey-Glass混沌系统)所示,其中“Actual”代表时间序列数据集的期望值.在以RMSE为误差度量评价标准的前提下,5种预测模型在两个时间序列数据集上的误差如表2所示(最优的预测结果用黑体特别标注).

表1 5种预测模型的最优模型结构
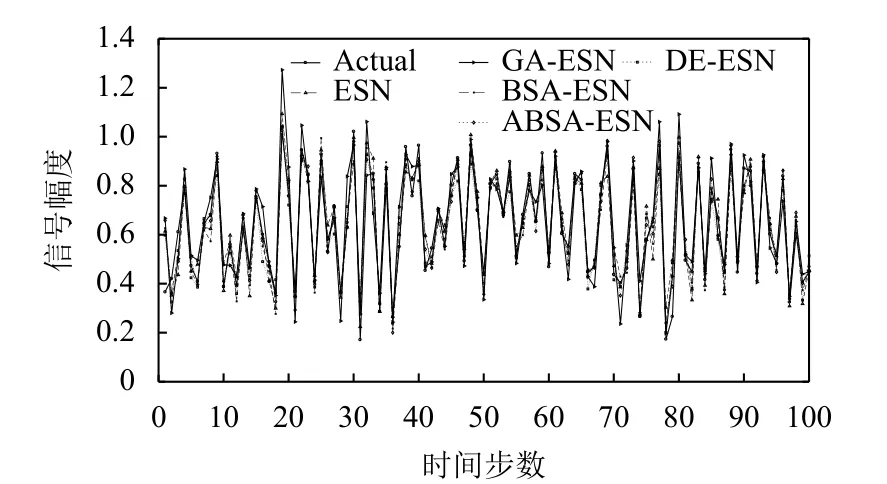
图8 NARMA上5种模型的预测值和期望值
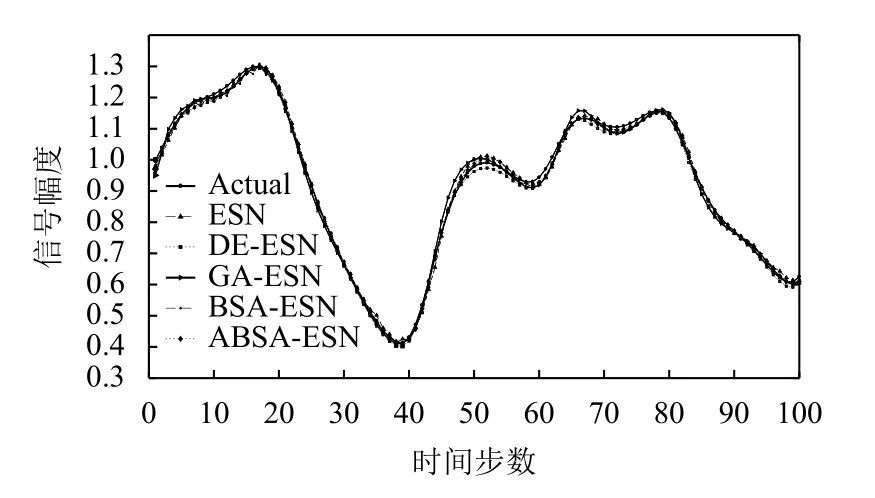
图9 Mackey-Glass上5种模型的预测值和期望值
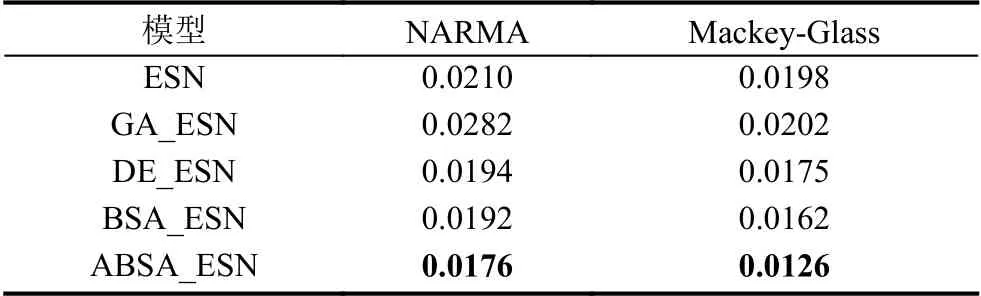
表2 5种预测模型的最优结果(以RMSE为度量方式)
为了评估两个相比较模型之间的性能差异,相对误差将被采用作为度量方法.相对误差是一种流行的用于比较两个方法之间的性能的度量方法[20].对于两种方法A(基本方法)和B(对比方法),其误差分别记为δA和 δB,则相对误差为相对误差小于0,说明对比方法B比基本方法A性能更优.另外,相对误差的平均指两种比较方法在两个或两个以上数据集上的相对误差的平均值.相对误差的均值小于0说明对比方法B相对于基本方法A在所有数据集上预测性能有改进.
3.4.1 优化的ESN与标准的ESN
在本文中,为了验证所提出的使用进化算法优化的ESN (GA_ESN、DE_ESN、BSA_ESN和ABSA_ESN)与标准的ESN之间的预测性能差异,将使用标准的ESN作为基本方法,使用GA_ESN、DE_ESN、BSA_ESN和ABSA_ESN作为对比方法进行预测性能比较.表3给出了两两比较模型之间的相对误差.
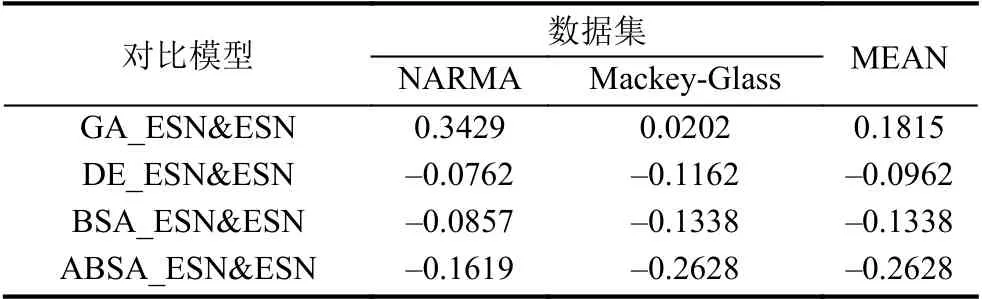
表3 两种比较模型之间相对误差(以ESN为基本方法)
从表3可以得出:标准的ESN预测模型无论是在单个数据集还是在两个数据集作为整体的性能评估中,其性能都只比GA_ESN优越而比DE_ESN、BSA_ESN和ABSA_ESN等预测模型差.具体而言,GA_ESN相对于ESN的性能单独在NARMA和Mackey-Glass上分别下降34.29%和2.02%,在两个数据集的整体性能上平均下降18.15%(如表3最后一列“MEAN”所示).而DE_ESN、BSA_ESN和ABSA_ESN相对于ESN单独在两个数据集上的性能分别提升7.62%/11.62%、8.57%/18.18%和16.19%/36.36%,在两个数据集的整体性能上平均提升9.62%,13.38%和26.28%(如表3最后一列“MEAN”所示).总体来说,使用进化算法对ESN的输出连接权值矩阵Wout进行优化能够提升ESN的预测性能.
3.4.2 ABSA_ESN与其他4种模型
由3.4.1小节可知,使用进化算法对ESN的输出连接权值矩阵Wout进行优化相对于标准的ESN具有一定的性能优势.本节将具体讨论本文所提出的ABSAESN相对于标准的ESN和其他3种优化的ESN的优势体现.具体而言,将ABSA-ESN作为对比方法,而ESN、GA-ESN、DE-ESN和BSA-ESN等分别作为基本方法,然后比较它们两两之间的模型性能.表4列出了两两相比较模型之间的相对误差.
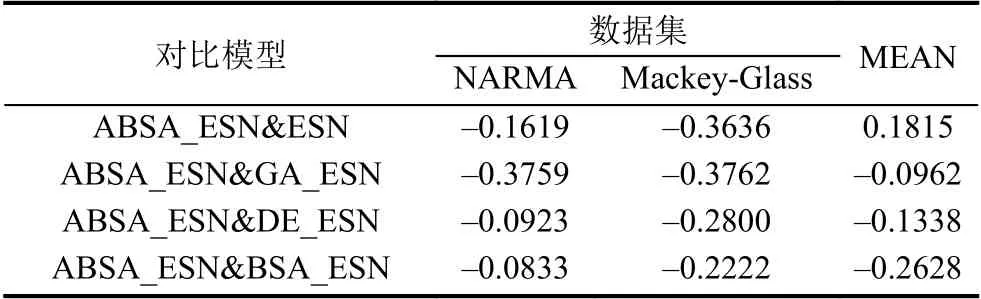
表4 两种比较模型之间相对误差(以ABSA_ESN为对比方法)
从表4可以得出:ABSA_ESN预测模型比所提出的其他4种预测模型ESN、GA_ESN、DE_ESN和BSA_ESN的预测精度大幅提升,具体体现在以下两个方面:
(1)当单独关注NARMA或者Mackey-Glass数据集时,ABSA_ESN能够比ESN、GA_ESN、DE_ESN和BSA_ESN等模型在两个数据集上都能获得更好的预测结果,主要表现在ABSA_ESN在两个数据集上的预测精度提升比例分别为16.19%/36.36%、37.59%/37.62%、9.23%/28%和8.33%/22.22%.
(2)当关注所有5种预测模型在两个数据集上的总体性能时,ABSA_ESN模型比其他4个模型在预测精度上也有大幅提升.ABSA_ESN模型相对于ESN、GA_ESN、DE_ESN和BSA_ESN等模型的平均相对误差提升比例分别为26.28%、37.61%、18.64%和15.28%.这个信息如表4中最后一列“MEAN”所示.
由此可见,本文提出的使用自适应回溯搜索算法优化的回声状态网络模型(ABSA_ESN)能够比未优化的回声状态网络模型(ESN)和采用其他进化算法优化的回声状态网络模型(GA_ESN、DE_ESN和BSA_ESN)在两个混沌时间序列数据集上获得更好的预测精度.
4 结束语
本文提出使用自适应回溯搜索算法优化回声状态网络的时间序列预测模型(ABSA_ESN),以解决标准回声状态网络中使用的线性方法求解输出连接权值矩阵容易陷入过拟合的问题,从而提升回声状态网络的预测性能.为了验证本文所提出ABSA_ESN在时间序列预测问题上的可行性和有效性,本文还设计了4种预测模型用于比较,它们分别是标准的回声状态网络(ESN)、遗传算法的优化回声状态网络(GA_ESN)、差分进化算法优化的回声状态网络(DE_ESN)和标准回溯搜索算法优化的回声状态网络(BSA_ESN).通过对实验结果进行分析可以得出如下结论:(1)使用进化算法优化的ESN (GA_ESN、DE_ESN、BSA_ESN和ABSA_ESN)相对于标准的ESN在预测性能上具有一定的优势;(2)ABSA_ESN相对于4种对比模型能够获得更好的预测精度.值得注意的是本文使用的是基本结构的回声状态网络,其自身性能可能会受到一定的限制.在未来,可以研究使用其他更加有效的进化算法优化具有复杂结构的回声状态网络的输出连接权值矩阵,进一步提升回声状态网络的性能.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
趣味(数学)(2020年4期)2020-07-27 01:44:16
支部建设(2020年15期)2020-07-08 12:34:32
自动化学报(2017年7期)2017-04-18 13:41:02
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
百科知识(2015年18期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
