
基于多模态深度融合模型的广告点击率预估
2020-01-14 09:36宋永强王露潼
小型微型计算机系统 2019年12期
宋永强,王 红,王露潼
1(山东师范大学 信息科学与工程学院,济南 250358)2(山东省分布式计算软件新技术重点实验室,济南 250014)
1 引 言
随着网络技术的发展,互联网凭借信息量大、操作方便等优点,在人们日常生活中占据了至关重要的地位作为互联网衍生品,在线广告不仅对互联网发展做出卓越贡献而且成为现代市场营销的重要组成部分.国内外的众多公司的绝大部分收入来自其广告部分,如谷歌、亚马逊等.据近期调查显示,中国互联网广告的市场规模保持着25%的增长.因此,互联网广告效果研究对于提高三方利润,增强用户体验等方面具有重要指导意义.
与线下广告不同,互联网广告存在各种的自动决策的付费方式,而这些付费方式依据的是点击率的预估结果.目前,互联网广告主要包括搜索广告[1]和实时竞价广告两种方式,无论哪种方式,广告主在推送广告之前会预估用户点击广告的概率,以实现媒体收益的最大化.因此,如何提升广告点击率的预测准确率成为互联网广告精准投放的核心问题.
互联网广告计算领域主要以广告点击率预测为主,现阶段点击率预测仍面临众多挑战,主要体现在:
1)无差异性假设:在广告点击率预测过程中会涉及到各种各样的用户,随着广告业务的发展,广告、用户数量以及累计用户记录会急剧增长,但数据研究多基于无差别假设,甚少涉及不同的用户浏览方式以及浏览行径等影响.
2)特征挖掘:挖掘到的用户信息具有一定的时效性,广告数据特征之间具有高度非线性关系,复杂度高,难以发现用户点击行为隐藏特征之间的交互性.
3)数据稀疏:由于广告数目巨大,只有少数的广告具有丰富的历史点击率数据,因此蕴含用户偏好的历史点击记录相当稀疏.
4)冷启动:当新的广告加入时,缺少足够的历史数据使得预测模型难以精准的预测广告的点击率,当新用户加入时,预测模型对用户相关特征缺少经验,也无法将相关的广告精准投放给用户.
目前,国内外研究人员主要通过捕捉数据特征内部的复杂关系[2,3]、组合底层特征表示属性类别特点,发现数据特征之间的关联.本文进一步优化,主要贡献如下:
1.通过断点检测消除噪音获取用户点击序列,以马尔科夫链分析点击序列信息,利用频繁序列挖掘不同用户的点击行为特点.
2.利用眼动追踪实验获取用户行为信息,捕获实验数据背后的潜在用户兴趣度,了解兴趣变化情况,获得普通实验难以收集的用户信息.
3.利用因式分解机模型融合广告和用户属性特征映射隐空间向量,使用向量内积对特征交互建模.
4.基于在线学习算法融合混合式深度神经网络构建多模态深度融合模型(Multimodal Depth Integration MDI)预估点击率.
2 相关工作
互联网广告由于其强大的流通能力,被视为一种有效的广告传播方式.越来越多的企业工作人员和学术科研人员加大对互联网广告效果研究,互联网广告成为网络公司的重要收入来源,实现互联网广告最大化经济效益也成为网络公司的研究热点.点击消耗(The cost per click CPC)模型[4]是互联网广告中最常见的支付模式,大约百分之66的广告交易依赖于CPC,因为CPC可以准确地揭示转化率的意义[5],在CPC模型中,点击率(Click Through Rate CTR)是衡量广告投放的重要指标.
早期的点击率预估(CTR)模型有ChaPell利用机器学习框架使用最大熵实现逻辑回归,有效的解决大量样本及参数问题,McMahan[6]利用逻辑回归模型解决Google的广告点击率问题.上述模型以用户信息,搜索关键词,利用广告数据等多特征为模型提供了一种在线系数学习算法,可以融合广告中大量特征,并在分布式计算系统中有效并行化,但数据表达能力有限,无法从数据中学习复杂的映射关系.Anhphuong[7]利用特征二项式组合建立非线性模型并通过矩阵分解将高维稀疏特征向量映射到低维连续向量空间,但处理具有复杂关系的数据时,难以捕捉数据中的高阶特征非线性表达和复杂的映射关系,He[8]组合梯度提升(Gradient Boosting Decision Tree GBDT)树生成非线性特征,这种方法在近期点击率预估中取得了不错的效果,但由于弱学习器之间存在依赖关系,使模型难以训练数据.
随着深度学习架构成熟,Zhang[9]利用循环神经网络(Recurrent Neural Networks RNN)随时间反向传播训练算法(Back Propagation through time BPTT)训练模型预估点击率,Yu[10]进一步改进神经网络利用长短时间记忆网络(Long Short Term Memory LSTM)优化RNN,成功的解决了梯度消失或爆炸问题,Jiang[11]采用深度置信网络(Deep Belief Networks DBN)和逻辑回归(Logistic Regression LR)提出深度置信网络(Deep Belief Networks Logistic Regression DBNLR)模型,该模型融合深度置信网络和逻辑回归优点研究广告数据的关键特征是否被完全挖掘,特征之间的非线性关系是否被发现.Chen[12]提出利用卷积层提取视觉特征,基于视觉特征使用全链接网络学习复杂的非线性关系,最后应用于逻辑回归模型预估点击率.Qu[13]通过在嵌入层和全连接层之间引入点击层,提出基于乘积的神经网络(Product-based Neural Network PNN)模型.为了更好的解决特征组合问题,Shan等[14]提出可以自动组合特征的深度交叉模型.谷歌、微软的研究人员提出了混合网络结构模型(Wide&Deep)[15],在混合模型的影响下,Xiao[16]进一步提出基于注意力的因式分解机(Attention Factorization Machine AFM)模型,He[17]提出基于网络的因式分解机(Neural Factorization Machine NFM)模型等,上述方法总结为架构深度网络自动学习数据特征增强数据表达能力,但在训练模型时,由于数据多来源于客体收集信息,默认用户主体间是无差别性,忽略用户所处的环境、情绪、心态、自身固有行为特点等信息对点击率预估的干扰.
尽管深度网络架构可以有效的利用结构化神经网络模型,适应广告数据集中复杂的非线性映射关系,但它忽略了用户在点击预测的实际反馈,不同特点用户可能产生不同的点击序列.用户点击行为是一个时间序列,现有数据多将点击基于静态特征建模处理,破坏了点击序列的时序性,现阶段,对于具有顺序性、时效性的序列特征难以基于深度网络中表达.随着眼动追踪技术发达,越来越多的科研人员利用眼动追踪技术基于行为假设预测用户点击行为[18],Xu[19]利用眼动追踪实验提出基于顺序点击的时间点击模型(Temporal Click Model TCM)模型基于行为假设用于描述用户在广告搜索中的点击序列,Wang[20]提出局部马尔可夫链(Partially Observable process Makorv POM)模型基于马尔科夫链建模预测用户点击序列,Wang[21]利用眼动追踪分析用户浏览过程,总结用户浏览行为.上述实验的成功,使点击序列挖掘成为可能,点击行为作为数据中重要的静态信息直接影响点击率预估,在实际操作中除了应用简单数值特征和类别特征之外,往往忽略分析用户点击序列特征,目前利用频繁序列挖掘技术是序列数据分析的重要工具,其本质是通过时间序列相似性度量挖掘不同用户行为特点.基于上述研究本文收集用户眼动实验数据,分析用户浏览过程中的点击序列,利用频繁序列挖掘技术,寻找用户点击行为特点融合多模态特征构建混合式的深度神经网络,提出多模态深度融合模型(Multimodal Depth Integration MDI)模型预估点击率.
3 序列挖掘
3.1 基于局部马尔可夫链模型点击序列分析
用户点击是一种有动机,有目标和特点日常活动[22],点击序列具有一定的结构、内容以及规律,但在记录这些信息时往往只能记录可观察的用户单次点击行为,无法细化每一次的点击动作和不可观察行为[23],通过局部马尔可夫链模型(Partially Observable process Makorv POM)对部分可测点击信息,挖掘相邻点击事件,求解隐藏数据的最大似然解,使用马尔科夫链的转移概率构造完整的点击序列,可以获取更多用户信息和更准确频繁序列的挖掘结果.进行如下定义:
定义1.用户点击事件是一个部分可观察的随机事件,如图1所示.其中e1表示用户的首次点击事件,对于任意点击行为ei,在可观察事件序列O={e1,e2,e3…}两个点击行为之间,模型可以挖掘用户可能已经点击但是没有被记录的点击行为信息.
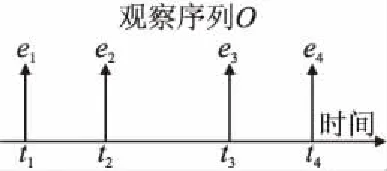
图1 观察序列Fig.1 Observation sequence
定义2.对于每一条观察序列O={e1,e2,e3…},可能存在不同的潜在序列假设Q1或Q2如图2所示,其中不可观察的用户点击行为以虚线表示,变量Vk表示随机点击的第k个对象,布尔变量Sk(Sk=1没有被点击,Sk=0被点击)表示是否跳过Vk.
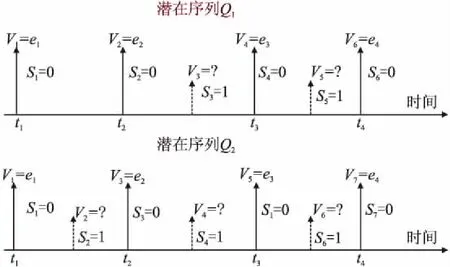
图2 潜在序列Fig.2 Potential sequence
定义3.对于任意一条点击行为可能存在无限多个点击序列假设Qi={(V1,S1)(V2,S2)…(Vni,Sni)},每条点击序列假设的长度记为ni,对于图2所示假设序列的长度分别为n1=6,n2=7.观察到的用户点击序列O,可能满足以下部分可测序列的结果:
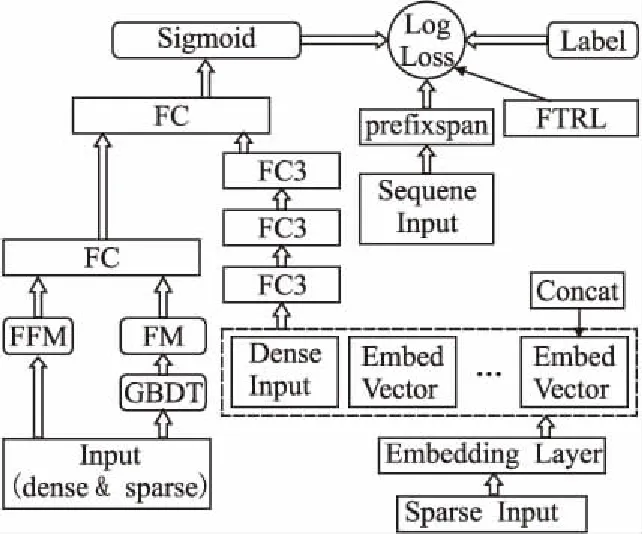
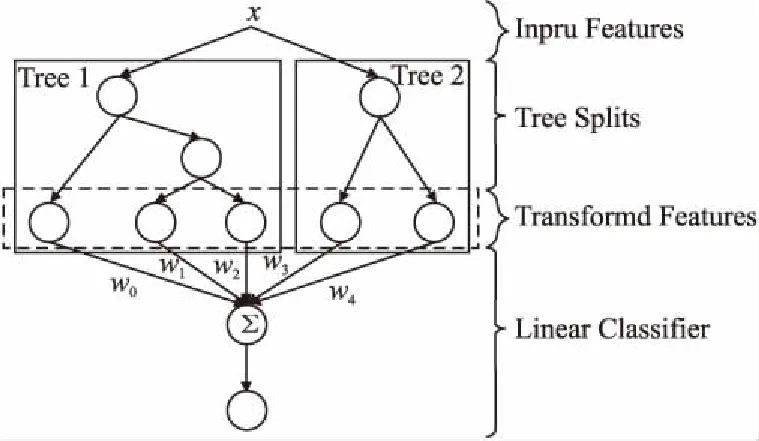
Vi=em,Vj=em+1,Si=Sj=0⟹Sl=1,∀m,l,i (1) 定义4.定义符号Qk可由Qk→O表示,其中Qk表示用户点击的部分可测事件,则存在公式: P(O)=∑Qk→QP(Qk) (2) 定义{V1,V2…}为观测序列,可通过眼动追踪实验获取到的扫描路径的浏览行为.利用马尔科夫链,对每一条点击序列加权定义后的公式: P(O)=∑Qk→QP(Qk)=∑Qk→OP(V1,S1)P(V2,S2|V1,S1)…P(Vnk,Snk|V1,S1…Vnk-1,Snk-1) (3) 通过上述定义,可将传统的预测点击序列问题,转化为求解点击序列的马尔科夫链问题.进一步求解模型: 对于可观测序列Qi,求解POM模型的参数Λ′的最大似然估计: (4) 利用迭代法改进最大似然估计求解算法,其中于第l次迭代: (5) 由于Gibb不等式对求和项的约束,因此最大化问题可使用Gibb不等式条件解决,可将公式(5)转化为公式(6)和公式(7),选择Viterbi加速近似算法优化模型. (6) (7) 综上所述训练模型步骤: 算法1.Viterbi加速近似算法 1. Start with an initial model Λ(0) 2. For iterationlapply the segmental decoding method with Λ(l-1)to find top N hypotheses for each observation. 3. Obtain Λ(l)using() 4. Repeat step 2 and 3 until the process converges 时间序列的特点体现在每个时间节点的数值及独特结构.频繁序列模式可以挖掘一段时间内用户特定行为规律,利用组合性质将原始问题分解为子问题,基于序列格的搜索技术和特定的连接操作,寻找频繁模式序列.由于点击行为序列是一个时间序列,因此本文基于时序信息挖掘频繁序列模式,寻找用户在一定时间内的点击行径,利用时序性序列(随着时间改变的序列事件)和点击广告之间的关联规则寻找用户点击广告前后的点击特点.在挖掘频繁序列模式之前需要进行如下定义: 定义5.序列是完整的信息流,通过项的集合构成的有序表.对于扩展后的点击序列记为S={At1,At2,…,Am},其中每个A是一个观测属性,ti是观测时间.序列的长度通过项的个数决定,若序列的长度为k,则记为k序列. 定义6.序列S1={At1,At2,…,Am}{t1 本文采用PrefixSpan算法[24]寻找序列的频繁模式.PrefixSpan算法在工作不需要产生候选序列,使得投影数据集合更小、内存消耗稳定.投影数据集合的减少,有助于缩短频繁序列模式挖掘的工作时间,通过分而治之思想扫描数据集合找到所有长度固定的序列模式,把这些序列模式作为前缀映射到多个局部投影集合,最后利用递归方法在集合内实现序列模式挖掘算法.算法2如下所示,给定一个序列数据集合S,根据前缀划分,产生多个投影S1,…,SN然后再多个投影数据库中进行递归挖掘,直到找到所有的频繁序列. 算法2.PrefixSpan算法 Input:A sequence databaseS,and the minimum support threshold min_sup Output:The complete set of sequential patterns Parameters:α:a sequential pattern;l:the length ofα;S|α′:theαprojected database,ifα≠();otherwise,the sequence databaseS Method: 1.ScanS|αonce,find the set of frequent itemsbsuch thatbcan be assembled to the last element ofαto form a sequential pattern; (b)can be appended toαform a sequential pattern 2.For each frequent itemb,append it toαto form a sequential patternα′and outputα′ 3.For eachα′constructα′databaseS|α′ 点击率是互联网公司网络流量分配的核心依据,互联网广告平台精确的点击率预估有利于最大化提升三方利益.点击率预估技术从传统的逻辑回归发展到深度学习,其本质是通过设计网络结构进行组合特征的挖掘,也可以描述为一个经典的二分类问题,依据用户侧信息、广告测信息、上下文信息等去建模预测用户是否会点击广告.本文利用经典的深度学习架构MDI模型预估点击率,如图3所示,由梯度提升树(Gradient Boosting Decision Tree GBDT)[8]、因式分解机(Factorization Machines FM)[25]、域因式分解机(Field Factorization Machines FMM)[26]模块组合而成,每一个模块不是独立的,是整个模型共同训练完成.FM模块接受低阶特征信息构造特征交互,GBDT代替传统的人工特征工程方法,可以将低阶特征映射到隐向量空间;FFM模块可以将同类别的特征组合,提出了域(field)的概念,将同类别的特征组合在同一field内便于处理,并通过卷积层(FC)构造高阶特征表达,并利用Prefixspan挖掘出用户的时序信息,更好预估点击率. 图3 MDI模型Fig.3 MDI model MDI由多个模块集成,使用GBDT代替连续特征离散化等人工特征工程,具有强的非线性拟合能力以及鲁棒性,利用FM自动学习任意特征的一阶交叉,扩展特征空间,吞吐稀疏特征空间,提高模型的表达能力,通过FFM将同性质特征归于一个域,在实验过程中自动省去零值特征,提高模型训练速度.输入数据为数值特征(dense)和类别特征(sparse)以及序列特征(sequence input),模型将类别特征传至至嵌入层,获取多个嵌入向量,将嵌入向量和数值特征连接传入三层全连接层(Fully Connected layer FC),将第三层全连接层的输出和FFM以及FM的输出连接在一起传入全连接层,结合频繁序列模式挖掘到的信息学习广告是否被点击. 在传统的特征处理过程中为了提升分类器准确度,针对连续特征通过离散化bin,将bin的编号作为离散特征;针对离散特征,生成笛卡积组合特征,但是上述操作需要消耗大量的资源.本文利用GBDT代替传统特征处理方法,GBDT是基于集成学习的建立的非线性模型,其工作原理是对于每一次迭代过程,选择在减少残差的梯度方向新建立一颗决策树.GBDT可以发现多种区分性的特征以及特征组合,决策树的路径可以直接作为不同模型的输入,从而减少特征处理步骤. 图4 GBDT模型Fig.4 GBDT model GBDT算法的构造如图4所示,图中Tree1、Tree2为通过GBDT模块得到的两颗决策树,当输入样本后遍历两颗树,样本落到叶子节点上,每个节点对应一个维度的特征,遍历结束后可以得到该样本的所有特征,树的每条路径通过最小化均方差分割方法进行路径区分.举例说明:对于图4的第一棵树包含3个叶节点,第二棵树包含2个叶节点.对于某一个输入样本落入叶子节点2和叶子节点1,那么可以得到特征向量(0 1 0 1 0). FM可以有效解决数据量大、特征稀疏等特征组合过程中的问题.本文利用FM模块通过隐向量做内积来表示组合特征,目的是解决高、低阶组合特征的提取问题,而且大大提升训练效果.FM模块前面两部分是传统的线性模型,最后一部分通过互异特征分量之间的相互关系构成.针对点击率预估的FM模块为: (8) 其中,参数w0∈R,w∈Rn,V∈Rn×k.[vi,vj]表示的是两个大小为k向量vi和vk的点积: (9) 其中vi表示系数矩阵V的第i维向量,且vi=(vi,1,vi,2,…,vi,k),k∈N为超参数.由于FM模型在基本线性回归模型的基础上引入交叉项概念,即公式(9)可由公式(10)表示: (10) (11) 令 (12) 则 (13) 通过上述变化关于FM模块可由SGD算法求解: 算法3.SGD算法 Input:Training data S,regularization parametersλ,learning rateη,initializationσ Repeat fori∈{1,…,p}Λxi≠0do forf∈{1,…,k}do FFM模块是根据域(field)概念提出的FM模块的改进,其本质是将同性质的特征引入同一个域(field).FFM针对每一个特征关于不同的field使用不同的隐向量,可以提升模型的准确率.例如′Day=26/11/15′、′Day=26/11/15′、′Day=26/11/15′三个特征都是代表日期,可以放到同一个域(field);如果以三种类型的字段:publisher、advertiser、gender分别代表媒体、广告主、性别.假设publisher有5种数据,advertiser有10种数据,gender有男女2种,经过one-hot编码以后,每个样本有17个特征工.如果使用FM模型,则17个特征每一个特征对应一个隐变量.使用FFM模型,则17个特征,每个特征对应3个隐变量,即每一个类型对应一个隐变量,publisher、advertiser、gender三个域(field)各有一个隐变量.根据上面的描述,可得FFM模块: (14) 其中j1,j2表示特征的索引.假设j1特征属于f1,j2特征属于f2,则Vj1,f2表示j1特征对应f2的隐变量,Vj2f1表示j2特征对应的f1的隐变量.在实验过程中,FFM模块往往只保留二次型,即: (15) 对于FFM模块的训练算法使用SG算法[]: 算法4.SG算法 1.Let G ∈Rn×f×kbe a tensor of all ones 2.Run the following loop for t epochs 3.fori∈{1,…,m}do 4.Sample a data point (y,x) 6.forj1∈non-zero terms in{1,…,n}do 7.forj2∈non-zero terms in {j1+1,…,n}do 8.calculate sub-gradient by gj1,f2≡▽Vj1,f2f(V)=λ·Vj1,f2+kVj2,f1xj1xj2 gj2,f1≡▽Vj2,f1f(V)=λ·Vj2,f1+kVj1,f2xj1xj2 9.ford∈{1,…,k}do 10.Update the gradient sum by 11.Update model by 本文在预测点击行为过程中,除了考虑固有特征之外还增加用户点击序列及性格特征等数据,但现阶段缺少考虑用户情绪状态、认知风格等多模态特征数据,因此进行大规模的数据采集工作. 通过招募的方式随机抽取本校各专业本科学生(18-21岁,平均19.7岁)自愿参加实验.所有被试者需要进行验光实验,以保证被试者符合测试实验要求. 选择SMI RED眼动仪器(Version 2.4),利用眼动仪器中的IView X、Experiment Center 和BeGaze记录、收集、分析被试者行为及眼动数据. 实验材料分为两部分:一部分用于获取被试者的主观特征(例如对于用户认知风格划分使用镶嵌图形测验(Embedded Figure Test,EFT)),另一部分用于获取被试者的外部行为特征的搜索引擎页面,并要求被试者在实验过程中尽可能的遵循其日常的行为特点. 1.主观特征收集.利用测试题目收集相关数据判断用户兴趣、认知风格等特征.例如对于认知风格的测试,在实验过程中要求被试者在较复杂的图形中找到并描绘出隐藏在其中的简单图形. 2.网页浏览.在整个实验开始之前,需要对被试者进行眼睛标准矫正,使其满足实验测试要求.根据实验人员的提示,被试者要像平时浏览网页一样浏览特点页面,并可根据自身情况随时停止实验. 实验收集鼠标特征、用户性格特征、SERP眼动特征,广告体的眼动特征、广告体的特征等.类(Label)标签用于指示是否点击广告:如果点击广告,Label的值为1;否则Label的值为0.为了后续充分评价模型性能,防止数据集合被数据时效性诸多因素的干扰,在实验中随机干扰原始样本的顺序,同时为了防止过拟合,实验训练过程采用交叉验证[27]. 本文选择逻辑回归(logistic regression LR)、因式分解机(Factorization Machines FMS)[25]、域的因式分解机(Field Factorization Machines FFM)[26]、GBDT组合FM[10]模型作为和本文的MDI模型性能比较的基线模型. 本文选择Area Under Curve(AUC)[28]作为广告CTR主要的性能评价指标.通过混淆矩阵,求解真阳率(TPR),假阳率(FPR)的混淆矩阵对应的TPR和FPR值,得到坐标点对.点对构成接收器工作特性(ROC)曲线,AUC是ROC下面的总面积.AUC越大广告CTR预测更准确,对应的广告投放效果更好. 本文选择经典的点击率logloss(logarithmic loss function)作为广告CTR预测的辅助性能指标. (16) 本文首先将MDI模型同基线模型进行比较,如图5和图6所示,可以发现提出的MDI模型具有最好的性能.进一步分析,传统的LR具有较差的性能,在训练模型过程中,可以发现LR模型训练速度快,但效果并不理想,当LR用于预估CTR时,需要具有复杂经验的专家通过人工实施特征工程;另一方面,LR的简单结构限制了它的表示能力,导致LR不能学习复杂的特征交互,对异常值和缺失值不敏感,传统的人工智能技术越来越难以直接有效地从原始广告数据中提取和组织鉴别信息.FM性能相较于LR具有更好的表现力,FM扩展了LR的思想,在一阶特征拟合的基础上增加二阶特征拟合,它可以自动从不同维度来学习任意两个特征组合,任意两个特征组合产生的交叉特征用嵌入向量表示,FM模型在实验过程中有较少的人工干预,同时具有更高的效率,然而由于结构相对简单,FM难以学习到复杂的特征相互作用.继而GBDT+FM解决方案优于FM模型,该方法在该数据集上的AUC(logloss的0.01%)提高了0.09%以上,数据的质量对模型的效果有很大影响,由于数据中含有大量的噪声数据,GBDT和FM组合的方式无反力支撑的叠加组合模型,在理论上对CTR预测的效果改善方面相对出众,在数据表示能力和预测精度方面,显示出相对较好的性能. 图5 各个模型AUC Fig.5 AUC of each model 图6 各个模型损失函数 Fig.6 Loss function of each model 图7 各个模块效果测试Fig.7 Effectiveness test of each module 本文进一步对比各个模块之间的准确率及收敛速度(由时间信息反馈),定义横坐标为时间,纵坐标为模型每个时刻的准确率,利用平滑实验处理之后,得到结果如图7所示.可以发现MDI模型具有最好的收敛性.进一步分析,MDI模型将各个模块的优点结合,利用深度模块同线性模块结合(即wide & deep),一部分增加了模型的表征能力,另一部分又提升了模型的准确度,因此具有最佳的实验效果;忽略GBDT模块,使得数据不经过GBDT处理直接输入到模型,虽然可以在一定程度上提高模型的收敛速度,但是实验效果比MDI模型低了5个百分点,导致模型的准确率下降;忽略FFM模块使得模型无法将同一类型的特征归化到同一域内,这使模型收敛时间增长,在实验过程中无法准确学习特征的表征能力,导致准确率也大大下降;忽略FM模块,使得模型利用两两组合的形式构建线性部分,大大增加了模型收敛时间,由于稀疏数据的存在,模型也无法准确的进行低纬特征组合,从而导致模型无法准确的学习模型表征能力,导致准确率降低. 本文针对CTR预测问题,提出一种MDI模型.将序列模式挖掘与经典的CTR预测模型结合,使得MDI模型可以处理具有点击序列特征的数据集合,符合用户浏览网页时的实际点击情况.由于将序列模式挖掘技术引入到该模型中,除了能够学习高阶特征交互,还可以使得处理方式更符合人们的点击模型,有助于处理和发现有价值的信息,能在具有点击序列的广告数据集中表现出良好的表示能力和鲁棒性.未来的工作将研究点击率预测中用户实时反馈情况.现阶段的研究多利用用户历史点击率预测其未来点击率,这种做法还有很大的提升空间,广告投放系统应当根据用户的反馈实时调整广告投放,并利用wide&deep的方式建立模型.因此,以实时反馈的方式预测点击率也成为今后的研究方向.3.2 基于Prefixspan序列模式挖掘
4 多模态深度融合模型
4.1 GBDT模块
4.2 FM模块
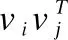
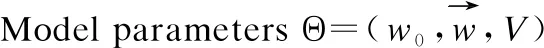
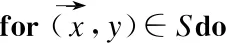
4.3 FFM模块
5 实验数据收集
5.1 实验对象
5.2 实验器材
5.3 实验材料
5.4 实验程序
6 实验结果分析
6.1 基线模型
6.2 模型性能评估度量
6.3 模型时间复杂度分析
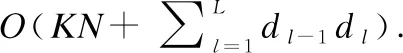
6.4 损失函数
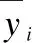
6.5 实验结果和分析

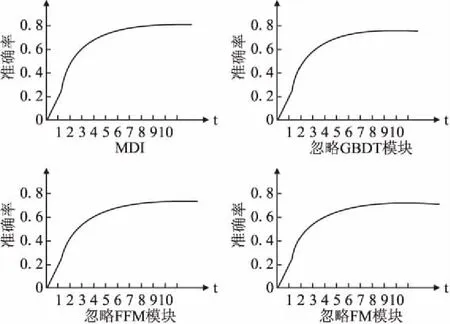
7 结 语
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21中学生数理化(高中版.高考理化)(2022年5期)2022-06-01中学生数理化(高中版.高考数学)(2022年3期)2022-04-26初中生世界·七年级(2019年5期)2019-06-22当代陕西(2019年10期)2019-06-03华东师范大学学报(自然科学版)(2018年3期)2018-05-14海峡姐妹(2015年8期)2015-02-27海外英语(2013年3期)2013-08-27汽车与新动力(2012年1期)2012-03-25阅读(中年级)(2009年11期)2009-04-14
