
基于改进ARMA预测模型的电厂风机状态预测
2020-01-03 01:21彭彤宇茅大钧韩万里
上海电力大学学报 2019年6期
彭彤宇, 茅大钧, 韩万里
(1.华电江苏能源有限公司句容发电分公司, 江苏 镇江 212400; 2.上海电力学院, 上海 200090)
目前,电力企业一般采用定期巡检的方式对电厂设备进行计划性检修,在此过程中不仅造成了电厂设备的利用率较低,也产生了较高的维修费用和较长的维修周期。同时,随着自动化水平的提高,电厂设备每时每刻都在产生海量的历史数据,这些数据中隐藏着有关设备运行状态的关键信息,如何从这些高维度的海量数据中挖掘出有价值的信息显得尤为重要。
文献[1]通过对电力设备的状态检修进行分析,提出了一种应用于电力设备时变停运的模型,结合计划检修对设备可用度的影响,可为后续状态检修中的检修决策和风险评估提供一定的借鉴。文献[2]采用改进的灰色模型对某电厂给水泵冷油器出口油温进行了状态参数的预测,预测精度较高,可应用于电厂点检数据的处理。文献[3]采用L-M优化算法对设备的运行状态进行了预测,结果表明该算法误差精度高,收敛速度快,可满足设备运行状态预测的要求。文献[4]通过对海量的工业运行数据进行挖掘分析,提出了一种工业设备状态预警算法,对提高设备可靠性和优化维修策略等具有重要的实用意义。
1 数据挖掘相关理论
数据挖掘是知识发现中的一个核心步骤,是从海量、随机、模糊的数据中挖掘出有实用价值的知识和信息的过程[5-7]。常见的分析方法包括回归分析、相关性分析、聚类分析、主成分分析和因子分析等。
相关性分析法用来描述两个变量之间的密切程度,通过对两个变量进行相关性分析,保留相关性小的变量,剔除相关性大的变量,以达到对数据进行降维的目的。假设两个变量U和V,则两者之间的皮尔逊相关系数为
(1)
式中:cov——协方差;
E——数学期望;
σ——均方差。
一般规定如下:ρ=0~0.2为不相关或极弱相关;ρ=0.2~0.4为弱相关;ρ=0.4~0.6为中等强度相关;ρ=0.6~0.85为强相关;ρ=0.85~1为极强相关。
2 改进ARMA预测模型
自回归滑动平均(Auto-regressive Moving Average,ARMA)模型由美国统计学家JENKINS和BOX提出,是一种时间序列分析的方法,被广泛应用于时间序列数据的建模分析中[8-10]。
ARMA预测模型包含q个移动平均项和p个自回归项,已知一个时间序列{xt},(t=1,2,3…),ARMA预测模型公式为
(2)
式中:Xt——待估参数;
c——序列均值;
εt,εt-j——白噪声序列;
φi——自回归系数;
新媒体的快速发展给思想政治教育者提出了更高的要求,使得教育主体的知识结构由过去“一对多”单一传输模式发生改变,学生可以依托新媒体这个平等互动的平台,自主选择接受的信息。传统的思想政治教育,因教育主体理论知识扎实,比学生有更大信息获取的优势,起到主导的作用。然而,新媒体的出现打破了这种教育者教育主导的地位,学生能在新媒体平台上搜索、捕捉、获取到自己想要的信息,可以不依靠教育者来获取。教育主客体之间的地位由隶属关系逐渐变成相互平等,主客体之间的关系开始转化,教育的客体也可以转为教育的主体,大学生思想政治意识由新媒体调动起来,思想政治教育者主体地位被弱化,被动摇。
θj——滑动平均系数。
记Mh为h步滞后算子,则有
Mhxt=xt-k
(3)
若忽略常数项,自回归模型AR(p)和移动平均模型MA(q)可分别表示为
(4)
(5)
综上,ARMA预测模型可表示为
(6)
ARMA预测模型针对的是平稳时间序列,但在实际应用中,所采集的时间序列一般都是非平稳随机序列,且受季节等因素的影响,预测精度较低。因此,本文在ARMA预测模型基础上融合了差分操作和季节性差分环节,不仅将非平稳时间序列转化为平稳时间序列,更考虑了季节性因素的影响,使得预测结果更加准确。
改进后的ARMA预测模型为
φf(B)φF(Bs)(1-B)d(1-Bs)Dyt=
θg(B)ΨG(Bs)ut
(7)
式中:φf(B)——非季节自回归多项式;
B——滞后算子;
φF(Bs)——季节自回归多项式;
F——季节AR项阶数;
s——季节周期长度;
d——非季节差分的次数;
D——季节差分的次数;
yt——非平稳序列;
θg(B)——非季节滑动平均多项式;
g——非季节MA项阶数;
ΨG(Bs)——季节移动平均特征多项式;
G——季节MA项阶数;
ut——高斯噪声。
3 应用实例
本文以某电厂二期2×1 000 MW超超临界燃煤发电机组配套锅炉的节能型轴流式引风机为例进行分析,引风机型号为HU27046-221。在转速为745 r/min下,引风机的性能曲线如图1所示。表1为引风机的相关参数表。
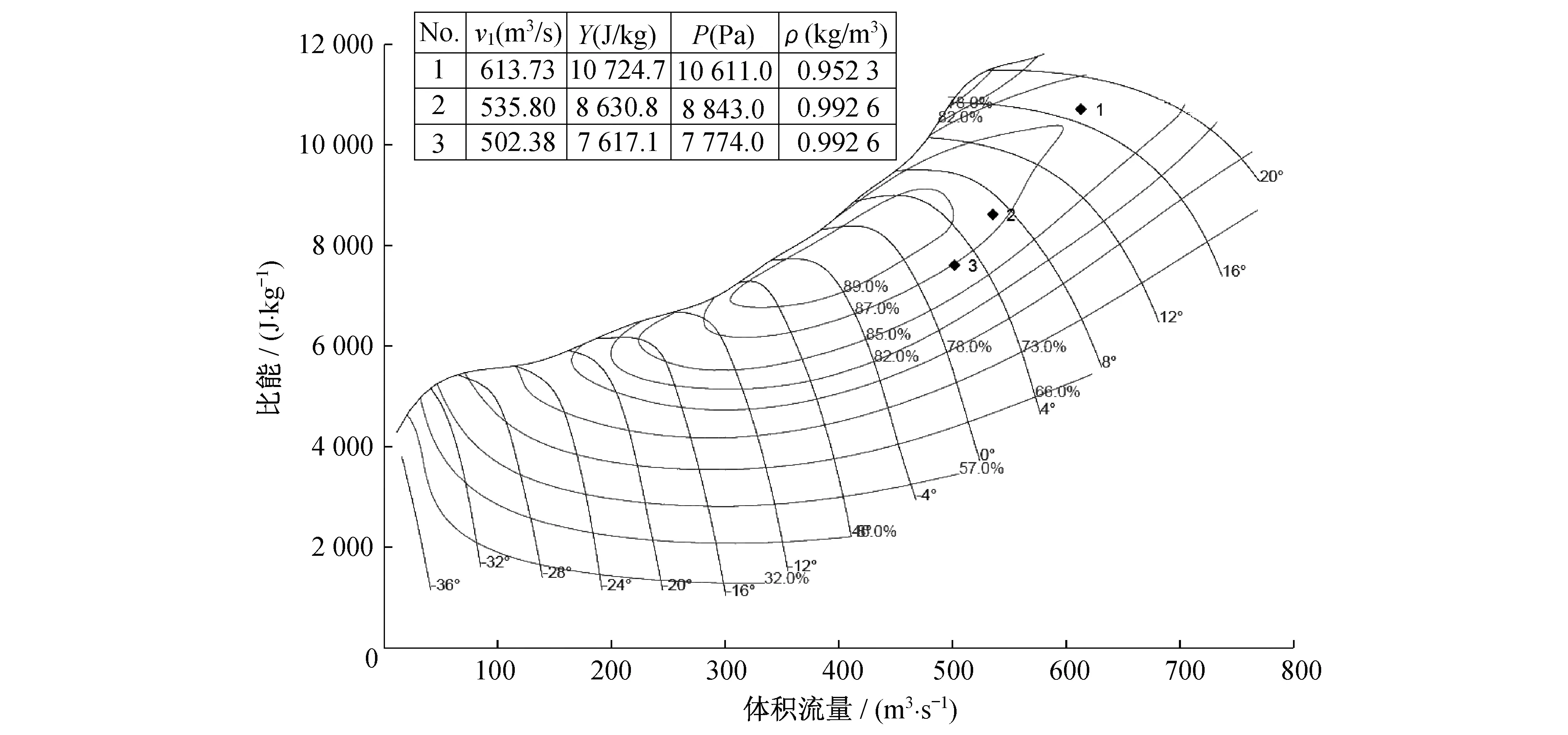
图1 引风机的性能曲线
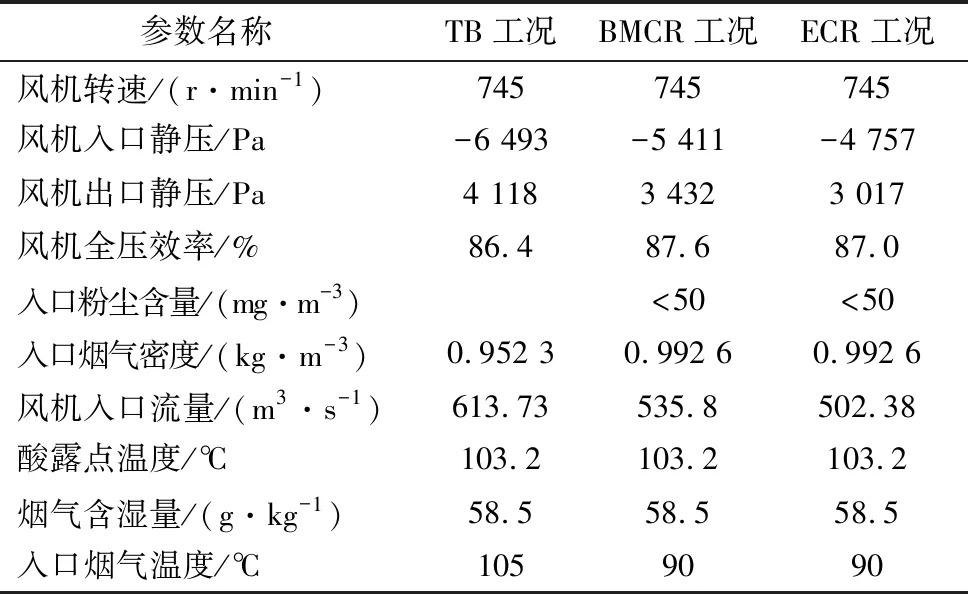
表1 引风机的相关参数
现从该厂厂级监控系统(Safety Instrumented System,SIS)中选取与HU27046-221引风机相关的测点共20个,采集2019年7月15日09:00至2019年7月23日09:00期间共20×2 593个状态的正常历史数据,采样间隔为5 min。其中,2019年7月15日09:00至2019年7月21日09:00的数据用于状态预测模型的建立,2019年7月21日09:00至2019年7月23日09:00的数据用于状态预测模型的验证,采样间隔为5 min。
通过数据挖掘理论中的相关分析法对上述正常历史数据进行相关性分析。对于与引风机运行状态相关的20个测点,按相关性大小进行排序,选取6个与引风机运行状态相关的主要状态参数,包括引风机X向轴振、引风机Y向轴振、引风机前轴承温度(3个)、电机前轴承温度(2个)、电机润滑油压力和电机电流等,共计9个测点的历史数据。从最初的20个测点压缩至9个测点,达到了对原始正常的历史数据降维的目的,减少了数据的冗余问题。
现对2019年7月15日09:00至2019年7月21日09:00期间共9×2017个正常的历史数据采用改进ARMA预测模型进行建模,将2019年7月21日09:00至2019年7月23日09:00期间共9×577个正常的历史数据用于预测模型的验证。以HU27046-221引风机X轴向振动为例,振动原始信号和预测信号趋势如图2所示。图2中,实线为2019年7月15日09:00至2019年7月21日09:00(前2 017个样本点)期间正常的历史数据,虚线(后577个样本点)为采用改进ARMA预测模型预测的趋势。
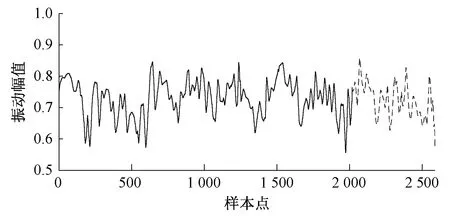
图2 引风机X轴向振动原始信号和预测信号趋势
图3为采用改进ARMA预测模型对2019年7月21日09:00至2019年7月23日09:00(共577个样本点)进行引风机X轴向振动参数状态预测的曲线图。由图3可知,采用改进ARMA预测模型较ARMA预测模型的误差更小。经计算,采用改进ARMA预测模型的均方根误差为0.025 5,ARMA预测模型的均方根误差为0.040 3。因此,采用改进ARMA预测模型的预测精度较高,可满足引风机状态预测工程实践的要求。
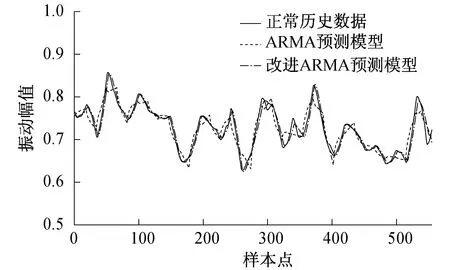
图3 引风机X轴向振动参数状态预测曲线
4 结 语
针对电厂引风机运行条件复杂多变、极易发生故障的问题,本文从高维度、海量的原始历史数据出发,提出了一种基于改进ARMA的电厂风机状态预测方法。与传统的ARMA预测方法进行对比分析发现,改进ARMA预测模型的预测精度较高,可满足引风机状态预测工程实践的要求。
猜你喜欢
智能制造(2021年4期)2021-11-04
河北电力技术(2021年2期)2021-07-29
汽车实用技术(2021年10期)2021-06-04
中国环保产业(2019年10期)2019-11-21
军事文摘(2018年24期)2018-12-26
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
通信电源技术(2018年3期)2018-06-26
电脑知识与技术(2017年16期)2017-07-14
新课程·下旬(2016年12期)2017-06-07
