
基于数据相似度的无线传感器网络节点休眠调度策略*
2020-01-02 06:34:04任秀丽
传感技术学报 2019年12期
李 伟,任秀丽
(辽宁大学信息学院,沈阳 110036)
无线传感器网络(Wireless Sensor Networks,WSN)由大量低成本的微型传感器组成,主要用于监测感兴趣区域的环境因素,如温度、声音、压力等。传感器利用有限的电池能量进行环境感知,数据处理以及无线通信。它们收集感知数据,在本地进行处理后,将其传输到基站。由于其具有小型化、低成本、低能耗的特点,已经被广泛应用于医疗监控、战场监视、目标跟踪和智能家居等领域[1-2]。
传感器节点通常采用电池供电,其能量有限,由于节点大都部署在危险复杂区域中,电池一般难以更换,能量效率成为WSN设计中的主要问题[3]。如何减少冗余数据收集,降低传感器能耗成为一个热门研究问题。文献[4]提出一种基于线性距离的休眠调度方法(Linear Distance-based Scheduling,LDS),LDS考虑传感器节点到簇头的距离。距离簇头远的节点具有较高的休眠状态概率。随着节点距簇头距离的增加,节点进入休眠状态的概率也增加。但簇头附近的节点可能会始终处于活动状态,这样会导致节点过早因能量耗尽而死亡。文献[5]提出一种基于地理信息的睡眠调度和链式路由算法(Geography-Informed Sleep Scheduling and Chaining based,GSSC),GSSC根据节点的地理位置信息,使得小范围内感知到相同信息的节点只有一个处于活动状态,其他节点处于睡眠状态。然而由于处理能力和RAM的限制,用于提供位置信息的GPS难以部署在传感器节点上。文献[6]提出一种完全分布式的休眠调度算法,传感器节点不依赖于任何地理信息便可找到休眠节点,并使其进入休眠状态。但该算法不能保证传感器节点间的连接。文献[7]提出一种休眠调度和基于树的聚类路由协议(Sleep Scheduled and Tree-Based Clustering,SSTBC),SSTBC将监控区域划分为网格,通过休眠不必要的节点来保持整个网络的能量,此外还建立以簇头为根的最小生成树,以此来降低长距离传输的能耗。但该协议没有考虑网络覆盖率的问题,仅以节点剩余能量作为筛选休眠节点的依据,可能会导致感知盲区的产生。文献[8]提出一种基于相似性度量的节能睡眠调度机制(Energy-efficient Sleep Scheduling Mechanism,ESSM),ESSM首先根据最优竞争半径划分多个簇,然后根据活动节点采集的数据构造模糊矩阵来度量相似度,从而选择出冗余节点进行休眠调度。从数据的角度出发,仅以一次测量数据作为冗余节点的判断标准可能存在偏差,同时非邻居节点间的相似度无实际意义,同样会使大量节点同时进入睡眠状态从而导致感知盲区的产生。
为此,本文提出一种基于数据相似度的节点休眠调度策略(Node-Sleeping Schedule Strategy Based on Data Similarity,N3SDS)。N3SDS利用相似度函数计算簇内活动节点感知数据间的相似度,对相似度高的邻居节点进行聚类分析得到冗余节点。然后,为避免感知盲区,在冗余节点的基础上采取相应地选择方法进一步筛选出休眠节点,并进行休眠调度,减少冗余数据收集,均衡网络能耗。
1 网络模型
假设N个传感器节点随机部署在监测区域A内,网络节点密度足够大,可以覆盖整个区域A。现假设无线传感器网络满足以下条件:①传感器节点均为静态节点,一旦部署后位置不会改变。但由于节点能量耗尽或节点故障等其他原因,其拓扑结构可能会发生改变[9]。②所有传感器节点均为同构类型,即拥有相同的初始能量、通信半径R和感知半径rs,并具有一定的计算能力。每个节点具有唯一的ID[10]。③节点可以感知到所有位于其通信半径内的处于活动状态的节点。④节点的通信功率可调节,可以根据距离调整发射功率大小。⑤传感器节点通过RSSI测距方法[11]计算自身到其邻节点的距离。⑥节点间在数据传输过程中不考虑冲突问题。
2 能量模型
假设传感器发送l比特数据到其邻居节点,两节点间距离为d,传输能耗公式如下[12-13]:
(1)

ER(l)=lEelec
(2)
簇头除收发数据外,还要聚合来自簇内活动传感器节点的数据。计算能耗公式如下:
Eclac(l)=nlEDA
(3)
式中:EDA为数据融合系数,n表示簇内活动节点数量。

图1 网络生命周期图
3 N3SDS休眠调度策略
当监测区域的环境变化缓慢时,同一区域内的传感器节点采集的感知数据将会存在高度冗余。本文根据传感器节点感知数据间的相似度和节点的邻居表来选择休眠节点,进行休眠调度以减少冗余数据收集,均衡节点能耗。N3SDS的操作按轮进行,一轮为一个周期。每轮由两个阶段组成:①收集阶段,将其划分为3个子周期,每个子周期包括数据收集和数据传输,该阶段在簇内及簇间进行;②调度阶段,包括聚类分析、休眠节点选取和休眠调度,该阶段在Sink节点处进行。网络生命周期,如图1所示。
3.1 数据收集与传输
本文使用分布式非均匀分簇路由协议[14](Distributed Energy-Balanced Unequal Clustering,DEBUC)对网络进行分簇。DEBUC采用基于时间的簇头竞争算法,广播时间取决于候选簇头的剩余能量和其邻居节点的剩余能量。同时,通过控制不同位置候选簇头的竞争范围,使得距离基站较近的簇的规模较小。这样,网络中不同位置节点之间的簇内和簇间通信能耗得以相互补偿。
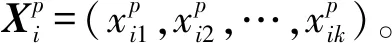
定义1邻居表。存储在传感器节点中的一种数据结构,其结构,如表 1 所示。其中每一行记录该节点的一个邻居节点信息。每行中的ID表示邻居节点的唯一标识;Eres表示节点的剩余能量;Distance表示节点到其邻节点的距离;Mode表示节点状态:W表示活动状态,S表示休眠状态。

表1 节点邻居表
每轮每个子周期数据采集结束后,节点将感知数据信息发往簇头。第一个子周期除了发送感知数据外还需要发送节点邻居表信息,簇头收到簇内所有活动节点的数据后将其聚合形成数据矩阵Y。第p个子周期内收集的感知数据形成的数据矩阵记为Yp,如式(4)所示:
(4)
式中:m为簇内活动传感器数量,k表示子周期k个时隙内传感器收集的感知数据数量。
簇头通过单跳或者多跳方式将数据发往Sink节点。Sink节点接收到数据后进行聚类分析以及休眠调度。
3.2 基于模糊聚类的休眠节点筛选方法
3.2.1 构造模糊等价矩阵
定义2相似度。衡量传感器节点感知数据间的相似程度。取值范围在[0,1]之间,0表示感知数据完全不同,1表示完全相同。取值越接近1,相似程度越高,反之越低。
Sink节点根据不同子周期感知数据形成的数据矩阵Yp构造相应地模糊等价矩阵。根据模糊聚类分析理论可知,传感器节点i与传感器节点j的感知数据间的相似度rij由式(5)计算可得:
(5)

(6)
由于模糊相似矩阵R仅满足自反性和对称性,不满足传递性,并不是模糊等价关系。因此,为了便于聚类分析,根据传递闭合性质将模糊相似矩阵改造为模糊等价矩阵。
从模糊相似矩阵R出发,依次求平方:R→R2→…→R2i→…,当第一次出现式(7)时:
Rk∘Rk=Rk(k≥1)
(7)
则Rk即所求模糊等价矩阵[15]。
由式(6)和式(7)计算可得模糊等价矩阵R*,如式(8)所示:
(8)
3.2.2 聚类分析
定义3冗余节点。数据相似度大于等于相似度阈值且互为邻居的节点。
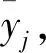
(9)
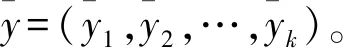
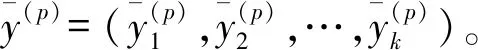
(10)
每个聚类的聚类中心向量到总体样本的中心向量的距离之和Dsum为:
(11)
每个聚类中所有的节点数据到其各自的聚类中心向量的距离之和dsum为:
(12)
则F统计量如式(13)所示:
(13)
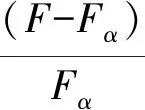
本文提出一种基于节点邻居表与相似度阈值的聚类标准。在相似度阈值的基础上考虑节点的邻居情况并对节点进行聚类,聚类标准具体实现如下:
①根据模糊等价矩阵R*求其δ对应的λ-截矩阵Rδ。若任意两节点间的数据相似度大于等于δ,即r′ij≥δ,则将其对应的r′ij值置为1;否则,置为0。由此可得到一个布尔型λ-截矩阵Rδ=(rδ)m×m。
②根据λ-截矩阵中1对应的所在行i和列j,即所关联的传感器节点i与传感器节点j,判断其是否能聚为一类。若rij=rik=rim=rin=1,由等价矩阵的对称性可知rij=rji,再根据其传递性可推导出rij=rji=rik=rjk=1。同理,可得集合{i,j,k,m,n}中任意两节点间的rδ=1。因此,可将其聚为一类记为A={i,j,k,m,n}。
③集合A中的节点可能存在非邻居节点。根据实际应用环境可知,非邻居节点间的相似度无意义,这是因为无法产生覆盖,可能产生感知盲区。故对集合A做进一步划分。若{i,j,k}互为邻居,{i,m,n}互为邻居,则将其分别聚为一类,记为A1={i,j,k},A2={i,m,n},则集合A可表示为A={A1,A2}。若节点在集合中无邻居节点,则将其从集合A中剔除。
3.2.3 冗余节点选取
根据上述聚类标准,可将节点聚类分为两类:基础类和扩展类。扩展类可扩展出具有相同聚类特征的不同表示,节点聚类情况,如图2所示。

图2 节点聚类图
(1)基础类
冗余节点A={i,j,k,…}聚为一类,即所有冗余节点互为邻居,如图2(a)所示。
(2)扩展类
①令A1={i,j,k,…},A2={i,p,q,…},A1中所有节点互为邻居,A2中所有节点互为邻节点。A1中的节点和A2中的节点不是邻居节点但存在公共节点。对其分别聚类,得到冗余节点集合A={A1,A2},如图2(b)所示。对图2(b)可扩展到多种情况,如图2(c)和 2(d)所示。此种聚类的共同特征是:公共冗余节点被不同集合所包含。②令A1={i,p,q,…},A2={j,m,n,…},A3={i,j},对其分别聚类,得到冗余节点集合A={A1,A2,A3},如图2(e)所示。对图2(e)可扩展到多种情况,如图2(f)和 2(g)所示。此种聚类的共同特征是:公共集合中的所有节点分别被不同集合所包含。
③A1={i,j,k,…},A2={j,m,n,…},A3={i,p,q,…},对其分别聚类,得到冗余节点集合A={A1,A2,A3},如图2(h)所示。对图2(h)可扩展到多种情况,如图2(i)所示。此种聚类的共同特征是:公共集合中的部分节点分别被不同集合所包含。
3.2.4 休眠节点选取
假设每轮每个子周期得到的冗余节点集合分别记为RN1,RN2,RN3。最终冗余节点集合记为RN,则RN=RN1∪RN2∪RN3。RN1,RN2和 RN3取并时,以节点的邻居情况为合并标准,RN的最终聚类与上述分析的聚类情况相同。为了避免感知盲区的产生,针对不同聚类,休眠节点的选择方法也有所不同。
①基础类中休眠节点选择方法
假设每轮每个子周期传感器节点向簇头发送l比特数据,根据能量衰减模型可知,传感器节点i可工作的轮数Ri为:
(14)
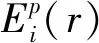
(15)
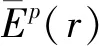

(16)
k为当前聚类中冗余节点的数量。当冗余节点的当前剩余能量低于平均剩余能量时,即:
(17)
则将该冗余节点选为休眠节点。
②扩展类(1)中休眠节点选择方法

③扩展类(2)中休眠节点选择方法
④扩展类(3)中休眠节点选择方法
3.3 节点休眠调度
每个轮次的3个子周期数据采集结束后,进行节点的休眠调度。由于节点调度按轮进行,这里仅对一轮内的节点调度进行描述。假设网络初始运行时,所有节点都处于活动状态。调度过程,如图3所示。

图3 调度流程图
具体实现如下:
步骤1 网络初始化时,每个传感器节点维护一个轮数计数器(初始值为0),记录每个节点的当前实际轮数(活动节点与曾休眠过的节点所处轮数不同)。每进行一轮数据收集,计数器值加1。
步骤2 每轮每个子周期簇内活动节点采集完感知数据后,将感知信息发往簇头。第一个子周期除了发送感知数据外,还需要发送邻居表信息。
步骤3 簇头收到所有节点的数据后,将其聚合发往Sink节点。Sink节点利用数据矩阵构造模糊等价矩阵,对节点进行聚类分析以及休眠节点的选取。最后,Sink节点广播休眠节点ID号。
步骤4 节点收到消息后,进行以下两项检查:①判断自身是否为休眠节点。若是,则进入休眠状态,关闭传感功能与通信功能以节省能耗。休眠节点经过预设的休眠时间后被唤醒,重新进入活动状态。②判断休眠节点是否是其邻居节点。若是,则将邻居表中节点Mode值修改为S。
步骤5 一轮结束后,簇头检查当前剩余能量是否低于阈值。若是,则重新执行分簇算法。否则继续下一轮数据收集,重复执行步骤2~步骤5。
由于休眠节点都是感知数据高度相似的冗余邻居节点,因此节点休眠后,休眠节点监测区域的数据可由其邻节点采集的数据代替,相应地冗余数据收集减少。同时,由于休眠节点选取时综合考虑了节点的相对位置以及剩余能量,剩余能量低于平均能量的节点进入休眠状态;高于平均能量的节点继续工作,等待下一轮休眠节点选取,因此能够有效地均衡节点能量。
4 仿真与结果分析
4.1 仿真环境及参数设置
本文使用OMNET仿真环境,对N3SDS方案的性能进行验证,并根据不同仿真指标对N3SDS方案与SSTBC、ESSM进行比较。仿真的详细参数,如表2 所示。

表2 仿真详细参数
4.2 实验结果
4.2.1 节点存活率分析
网络中节点存活率反映了网络中节点能量的消耗情况,是评价网络能效性的标准之一。图4是不同休眠调度策略的节点存活率随网络周期的变化情况,随着运行轮数的增加,网络中的失效节点逐渐增加,可用节点逐渐减少。从图4可以看出,与ESSM和SSTBC相比,N3SDS的网络寿命分别延长了28.2%和 72.4%。在第450轮时,第一个节点才开始失效。这是因为N3SDS分别对每个子周期的感知数据进行模糊聚类分析,从而选出了三组冗余节点集合。在确定最终冗余节点时,采用合并标准,可能将更多的冗余节点选为休眠节点,增加了休眠节点的候选数量,从而能更有效的均衡网络能量,相应的节点存活时间也更长。
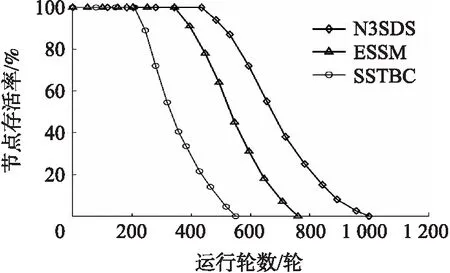
图4 不同休眠调度策略的节点存活率比较
4.2.2 网络能耗分析
网络能耗是指网络中所有节点每轮所消耗的能量,图5是不同休眠调度策略的网络能耗随网络周期的变化情况。从图上看出,与ESSM和SSTBC相比,N3SDS网络能耗变化趋势更加缓慢,相同轮数下节点总能耗更低。这是因为N3SDS在选择休眠节点时,针对冗余节点中的活动节点和休眠过的节点分别计算理论剩余能量值,然后通过它们的平均剩余能量作为阈值与节点进行比较,低于阈值的节点全部休眠。因此,休眠节点的选取更加合理,在保证数据准确度的条件下有更多的节点进入休眠状态。因此,N3SDS能更有效地均衡网络能量,降低网络能耗。

图5 不同休眠调度策略的网络能耗比较
4.2.3 数据准确度分析
定义4数据准确度。通过数据融合得出的结果与所有活动节点采集的实际数据之和的比值。
(18)
式中:xDA表示由Sink节点通过文献[16]中的数据融合方案得出的数据,xij表示第i个活动节点在第j个时隙采集的数据,m表示活动节点总数。
图6显示了不同休眠调度策略的数据准确度比较。从图上可知,随着活动传感器数量的增加,数据准确度逐渐提高。并且当数据准确度上升到一定值时总体趋于稳定。与ESSM和SSTBC相比,N3SDS的数据准确度分别提高了5.4%和18.1%。节点数量在200到350之间时,N3SDS的数据准确度总体变化趋势更加稳定。这是由于随着传感器节点数量的增加,监控区域拥有足够数量的传感器节点来监测事件,使得数据准确度最终趋于稳定。N3SDS从节点采集到的感知数据本身出发,基于数据间的相似度选择冗余节点。在冗余节点集合中进一步筛选休眠节点时,考虑节点间的相对位置以避免感知盲区。存在邻节点并且剩余能量低于冗余节点集合能量平均值的节点进入休眠状态,使得剩余的活动节点足以实现相同水平的数据收集。
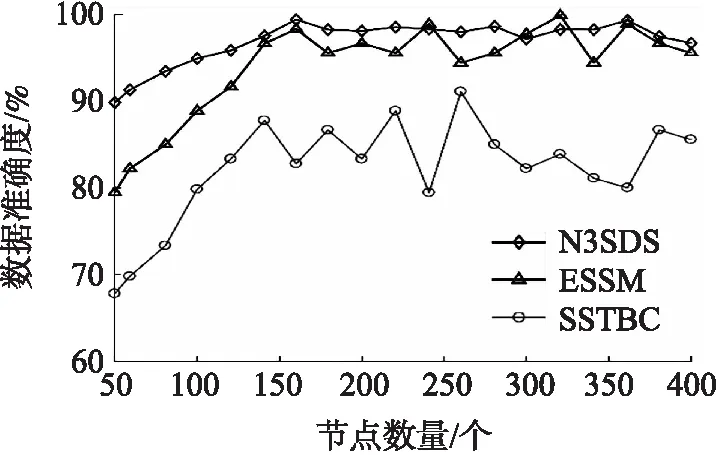
图6 不同休眠调度策略的数据准确度比较

图7 不同网络规模下的休眠节点数量比较
4.2.4 休眠节点数量分析
本文还分析了N3SDS在不同节点密度下每轮的休眠节点数量情况,如图7所示。从图7可以看出,随着运行轮数的增加,休眠节点数量大体保持稳定,并在一定范围内上下波动。网络规模为200个节点时,休眠节点数量大体在40~60间上下波动。网络规模为400个节点时,休眠节点数量大体在100~140间波动。高密度部署下的休眠节点数量明显多于低密度的休眠节点数量。这是因为相邻节点收集的感知数据的时空相关性要高得多,因此,休眠的冗余节点的数量相对更多,并且选择的更多休眠节点对后续的数据处理几乎没有影响。此外,从图中还可以发现不同节点密度下的休眠节点的数量相对稳定,这为维持所有节点的平均能耗的稳定性提供了基础。
5 结语
本文从减少冗余数据收集,均衡网络能耗,延长网络生命周期的角度出发,提出一种基于数据相似度的节点休眠调度策略(N3SDS)。N3SDS利用每轮不同子周期簇内活动节点形成的感知数据矩阵,计算不同节点间的相似度。通过模糊聚类分析理论,得到每个子周期的冗余节点。再根据不同子周期的冗余节点集合确定最终的冗余节点,为避免感知盲区,在冗余节点是基础上进一步筛选出休眠节点。通过对节点的休眠调度大大地减少了冗余数据的收集,从而降低了网络能耗。仿真结果表明,N3SDS在保证数据准确度的前提下,有效地均衡了网络能量,极大地延长了网络生命周期。在后续的工作中,如何将休眠节点更加合理地唤醒将会做进一步研究。
猜你喜欢
昆钢科技(2022年2期)2022-07-08 06:36:14
当代水产(2021年10期)2022-01-12 06:20:28
建材发展导向(2021年23期)2021-03-08 01:05:38
华人时刊(2018年15期)2018-11-10 03:25:26
建筑科技(2018年6期)2018-08-30 03:40:54
电子测试(2017年15期)2017-12-18 07:19:27
中国交通信息化(2016年5期)2016-06-06 03:51:43
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
天津冶金(2014年4期)2014-02-28 16:52:58
