
一种适应GPU的混合访问缓存索引框架∗
2020-01-02 03:45张鸿骏武延军张立波
软件学报 2020年10期
张鸿骏,武延军,张 珩,张立波
1(中国科学院 软件研究所,北京 100190)
2(中国科学院大学,北京 100049)
在系统软件与高性能数据应用中,散列表(hash table)是一类重要和常见的数据索引结构.通过把关键码值(key value)映射到表中一个内容位置来访问对应的数据记录,以大幅度加快数据查找的速度.在内存关系型数据库[1-3]和关键码值类型数据库[4,5]领域,散列表作为核心的系统组件提供了关键的数据索引接结构,通过映射函数将数据索引至对应位置.具体地,网络、云计算和物联网服务的重要系统组件[6],基于键值的内存缓存系统,如memcached[5]、Ramcloud[7]和MemC3[8],都采用了散列表来提供内存内的高性能数据索引服务.内存缓存系统通过将数据从相对内存访问速度慢的磁盘等存储介质加载入内存,以提升应用程序对数据访问的性能.由于内存通常不能容纳所有数据,当内存空间满时,缓存替换系统通过缓存替换算法踢出部分缓存数据为新数据提供空间.
在散列表的现有工作中,基于cuckoo 算法的散列表CHT(cuckoo hash table)[9]通过将原有单一数据映射到多个桶(bucket)中.CHT 代替了传统散列表的映射与链表式操作的方法,具有快速访问与节省空间的特征,在散列表管理[10-12]和数据存储系统[4,8,13-16]上得到了广泛的应用与研究.
典型的CHT 不支持插入和查询操作同时发生.它将数据通过两种不同的散列算法映射到两个不同的桶中,每个桶中有4 个槽(slot)允许存放数据.每个数据对应一组键值数据(key-value pair).在执行插入操作时,判断映射桶中是否有空闲槽,如果有,则进行插入;如果没有空闲槽,则通过对现有单元中存储数据进行散列与替换获得空闲槽进行插入.进而,如果在键值对数据插入时需要替换槽中数据,CHT 会随机选择一个待替换键值对KV′进行置换,通过散列算法计算KV′对应另一可选桶,将KV 放入原有KV′所在槽中;如果另一可选桶有空闲槽,则将KV′放入该空间槽中;如果该桶没有空闲槽,则在该桶内随机选择一个槽中的数据按相同方式继续进行置换,直至找到空闲槽.装载率是存储数据数量与散列表槽数量的比值,用于衡量散列表当前负载情况.当装载率高时,由于剩余空闲槽数量少,插入操作中数据置换频发,导致CHT 频繁访问内存,同时CPU 中出现大量临时性缓存,散列表性能受到影响.
在基于键值的内存缓存系统中,这类系统主要的工作负载特点是读操作相比写操作更为频繁[17,18].当读操作的请求未命中时,系统将读操作请求的数据写入内存缓存[19].当未命中的读操作请求数量增多时,由于频繁写入缓存未命中的数据,导致了基于键值的内存缓存系统工作负载引入了更多的替换操作.当散列表装载率高时,基于键值的内存缓存系统CHT 频发,导致了大量内存访问,降低了缓存系统整体性能.因此,基于键值的内存缓存系统散列索引方法在减少写操作访问内存的同时,需要保证系统的命中率,减少写操作数量.随着内存缓存数据量的大幅增加,在多核CPU 上并行散列表结构的索引系统已经逐渐出现性能瓶颈,亟需进一步改进散列表的高性能和可扩展性.
硬件的发展与变迁推动着系统软件的演化[20].随着GPU 硬件计算能力和并发性能的提升,更多的系统任务在GPU 上运行.键值存储缓存系统和关系型数据库中的CHT 相关工作,在GPU 等硬件的性能上得到了一定的提升[10,21-24].然而,现有的CHT 在多核CPU 和GPU 硬件上的并行优化方法中,系统在获取数据时的操作并不高效,计算系统的性能仍然受到内存带宽的限制[25-28].首先,由于散列表的稀疏性和随机性,在访问数据保存在芯片缓存后,下次访问之前,被其他访问的数据替换逐出芯片缓存,导致芯片缓存的低效利用以及大量获取数据的内存访问,从而系统性能受到影响.Xie 等人[29,30]提出了针对GPU 的cache bypassing 方法来减少芯片缓存的低效使用.其次,在采用GPU 硬件作为计算核心单元时,在CPU 与GPU 内存之间的频繁数据传输引入了更多的系统中断、进程切换、驱动调用等额外开销.因此,减少散列表内存访问次数与减少数据在GPU 访存与内存之间的频繁移动仍是优化散列表系统性能的重要途径.
在上述背景下,本文提出了一种适应GPU 的混合访问缓存索引框架CCHT(cache cuckoo hash table).该索引框架可应用于缓存替换系统进行索引管理.CCHT 通过多级缓存索引数据结构与支持并发读写的缓存插入查询算法实现了较低的内存访问次数.多级索引数据结构在提供了索引位置信息与全部缓存踢出优先队列信息的同时,提供了散列表桶内踢出优先队列.支持并发读写的缓存插入查询算法,给出了在内存缓存系统中插入和查询数据时散列表的操作方法.包括:当散列表桶内索引存储空间满与全局存储空间满时的踢出算法和插入查询时桶内踢出队列与全局踢出队列的更新算法.本文根据内存缓存系统的命中率与索引空间占用开销,分别提出了命中率相对更高的双重LRU CCHT 与缓存空间开销占用相对更小的粗粒度LRU CCHT.其中,双重LRU CCHT 通过两个缓存踢出优先级队列,在全局踢出与桶内踢出过程中独立使用,实现了高缓存命中率.粗粒度LRU CCHT 方法则仅通过一个缓存踢出优先级队列,在全局踢出与桶内踢出过程中共同使用,在保证了缓存命中率的同时,进一步减少了优先级队列对索引空间的占用开销.本文将CCHT 在GPUCPU 异构环境下进行了实现,并为减少内存带宽的占用与GPU 的访问次数,提出了基于外存计算系统(out-of-core)的多级索引数据结构.通过这种结构,实现了在CCHT 的请求处理过程中,在CPU 与GPU 内存间仅传输键数据,避免了值数据占用GPU 内存空间以及带宽资源.通过实验验证,当缓存空间大小与散列表比值为80%时,插入与全局负载的平均访存次数分别最高降低了30.39%和32.91%;当缓存空间大小与散列表比值为90%时,分别降低了94.63%和97.29%.这表明,CCHT 在散列表高装载率的情况下,仍能提供较低的内存访问次数,保证了缓存替换系统的性能.在CPUGPU 异构环境上的实验说明,CCHT 相对其他数据索引方法,在系统吞吐性能上得到了提升,验证了采用的多级索引数据结构与实现方法的有效性.
1 相关工作
Cuckoo 散列是一种高效空间利用率的开放寻址方法[9].它对每个对象指定多个候选散列表桶位置,同时允许将已存储的对象替换到其他候选桶位置中.SILT[13]通过两种散列方法实现了空间的高占用率,但受到了散列表大小的限制,不能应用于大存储空间的内存缓存中.MemC3[8]在保证空间高利用率的同时,通过标签与优化锁机制,消除了对散列表尺寸大小的限制.Hopscotch hashing[14]和Cache-oblivious hashing[15]通过增加索引指针空间保证访问并发性,提高了吞吐性能.Li 等人[31]通过硬件事务内存(HTM)与粗粒度锁机制,实现了访问的高并发.FlashStore[15]通过Cuckoo 散列将一个对象映射到16 个桶位置上,提高了插入时对象寻找空闲槽的几率.Kirsch 等人[16]采用附加隐藏空间减少了插入寻找空闲空间的开销.
在CPUGPU 异构环境上CHT 实现的研究过程中,Horton table[10]采用了附加空间与附加散列映射函数的方式,代替了原有无空闲槽时进行的替换方法.Stadium hashing[11]采用了CPU 和GPU 混合使用的方式以提升性能,即将键(key)存储在GPU 中,值(value)存储在CPU 内存中.它通过添加票板(ticket board)的辅助数据结构来区分对于CPU 和GPU 的操作,同时允许对同一散列表的并发读写操作.Barber[12]采用了相似的位映射结构实现了两个压缩类散列表.Xie 等人[29,30]采用GPU 上程序编译和插桩的方式静态或动态地指定临时或不常用的数据跳过部分芯片缓存,以减少芯片缓存的频繁置换.
实际应用中,散列表被广泛用于各种类型的系统软件及数据处理程序.很多内存键值存储系统通过应用于GPU 上的散列表来加速键数据的查找[23,32,33].早期实现在GPU 上的散列表用于数据库操作、图形处理和计算机视觉[34-38].在内存数据库中,有很多相关的工作在CPU 平台[39-42]、GPU 平台[43-45]和Xeon Phi 平台[21,46]上对散列表进行优化.
2 研究背景
本节介绍了我们工作的基础.其中,第2.1 节描述了CHT 的基本概念,第2.2 节给出了CHT 的典型实现方式,第2.3 节描述了基于LRU 的缓存替换策略,第2.4 节给出了CUDA 编程技术的基本概念.
2.1 CHT基本概念
典型的CHT 包含两种散列方法对键值数据(KV)进行映射[9].图1 给出了两个典型的插入场景,即将两个不同的键值数据KV1和KV2插入到CHT 中.其中,行号标明了散列索引的位置信息,每个位置的桶内按照典型的CHT 设置有4 个槽对键值数据进行存储.例如,H1和H2表示两个独立的散列方法,每个键值数据可以通过这两种散列方法映射到两个不同的候选位置上.对于KV1,映射到位置0 和位置2,对于KV2,映射到位置3 和位置5.当插入KV1时,通过两种散列方法找到对应的候选位置0 和2,这两个位置的桶中均有空闲槽用于插入新的键值数据.根据具体CHT 的算法,选择0 或2 位置的桶加以插入.
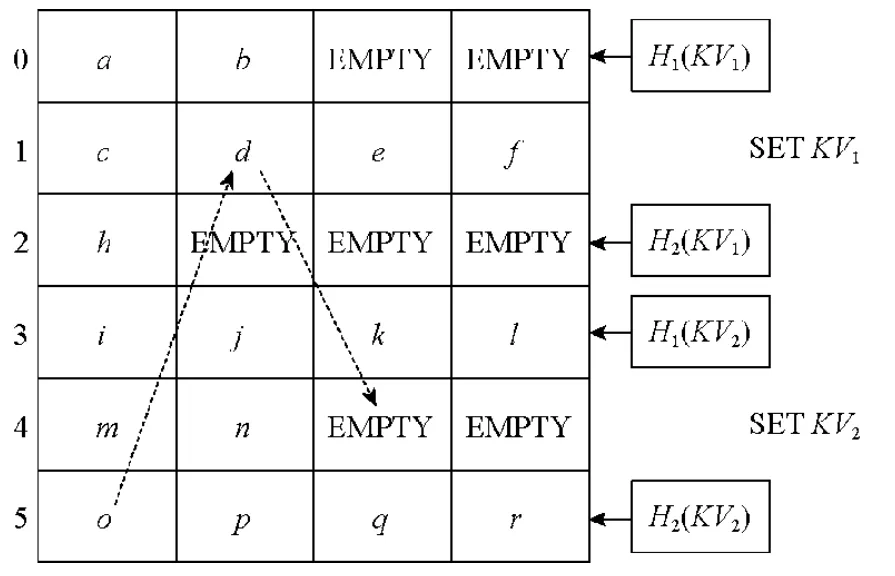
Fig.1 Set KV1 and KV2 on a CHT图1 在CHT 中插入KV1 和KV2
当插入KV2时,通过两种散列方法找到对应位置3 和5,发现位置3 和位置5 的桶中已无空闲槽.当遇到此种情况时,CHT 会在候选位置的桶中选择一个槽内的键值数据进行踢出,将新的数据放入该槽内,同时通过散列方法计算踢出键值数据的另一候选位置,如果有空闲槽,则放入,如果没有,则重复踢出置换操作,直至找到空闲的槽.典型的CHT 设有踢出置换次数阈值,当达到阈值后,停止踢出替换操作,CHT 进行扩容.CHT 踢出置换操作的引入,使CHT 中的空闲槽能更多地被使用,从而使得CHT 的负载率可以大于95%.在KV2的插入场景中,由于对应候选位置3 和位置5 的桶中已无空闲槽,则随机选择位置5 桶中槽内值为o的键值数据进行踢出置换,将KV2放入原有位置5 桶中o对应的槽中.通过散列方法计算o的另一候选桶位置为1,查询位置1 的桶,发现无空闲槽,则继续选择一个键值数据d进行踢出置换,将o放在原有d的槽空间中.再对d进行散列值计算,查看另一候选位置4 的桶,有空闲槽.将d放入空闲槽中,结束本次插入操作.Li 等人[29]证明了采用宽度优先,直至找到一条可以置换的路径查找策略,是一种有效的踢出置换方式.
当进行查询时,通过H1与H2计算散列值,查找对应位置的桶中槽内键值数据,通过遍历与比较槽内键数据来获取存储的值数据.
CHT 仅支持同一种任务类型同时发生,如并发插入操作或并发查询操作.当插入和查询操作同时发生时,插入操作可能因无空闲槽,发生置换操作.此时,若查询正在置换的目标数据,或查询的目标数据在未正确返回前,目标数据置换入另一桶中的槽内,将造成对已索引数据的查询失败.当发生上述两种情况导致插入与查询同时进行时,散列表即丧失了数据完整性.CCHT 相对于CHT 移除了无空闲槽时的置换操作,因此,支持插入和查询操作并发执行,提升了散列表的并发性能.
2.2 CHT的典型实现
CHT 在实际应用中的性能,受到大量参数的影响.在CHT 中,关键的散列函数个数与每个位置中的存储空间个数影响了CHT 的负载率及访问的延迟.当增加CHT 中散列函数个数,允许键值数据映射到更多的位置上时,由于对请求数据的候选地址变多,因此查找空闲槽的机会变大.这种多散列函数的方式可以有效地提升CHT的负载率.但当进行查找操作时,由于散列函数的增多,导致需要查看更多位置的桶与槽,进而导致了访问延迟的增高与处理器中cache line 中加载次数的增多.在实际使用过程中,CHT 的散列函数设置成在能够保证槽的充分利用和高负载率的同时,还能有效缩短查找时间,降低访问延迟.
在CHT 中,增加每个桶内槽空间的数量,可以有效提升负载率.当桶内槽数量增加时,在一次插入和读取操作的过程中访问单一桶中槽的数量增多,从而减少了第2 次或者更多次的散列操作,有效增加了CHT 的负载率.在CHT 实际应用中,大部分的设计采用了每个桶配有4 个或8 个槽空间[9].采用这种配置的原因是一个处理器中的cache line 可以一次缓存一个或者两个位置的数据.如果每个桶中使用更多的槽,在进行键值数据比较时,将导致更多的处理器cache line 加载,访问延迟有所增加.
CHT 的主要特性是能够提供快速的查询.在响应读取请求时,最大的查找空间数为n×s,其中,n为散列函数个数,s为单个桶中对应的槽空间个数.对于桶中用于槽的存储区域,采用定长存储空间的分配方式,方便通过数组或者向量的方式对数据进行访问.这种方式使CHT 更易于在不同处理器架构上进行实现,如CPU、GPU 和Xeon Phi.
2.3 基于LRU的缓存替换策略
在内存缓存系统中,系统将部分数据从持久化存储介质缓存到内存中,用来降低数据访问延迟.由于内存的存储空间有限,小于所有的数据存储空间需求,当内存缓存空间占满时,需要通过缓存替换策略踢出已缓存数据,获取空闲空间存放新的缓存数据.缓存替换策略保证了更有价值的缓存数据留在内存中,通常采用命中率来衡量其有效性.在系统实现时,通常将增加访问吞吐与延迟作为综合的考量指标.在实际使用中,需根据不同的应用负载选择适合的替换策略.如在Web 应用的场景下,最近热门的数据被频繁访问,则适用最近最少使用(LRU)替换算法[7,8].
LRU 算法是典型的缓存替换算法.其核心思想是将最近访问的数据单元作为最有价值单元,需要替换时,踢出距离上次访问最长时间的数据单元.LRU 算法流程如图2 所示,LRU 算法的数据单元存储空间上限为4,存储空间右侧为最近访问的数据,同时,对于每个数据单元标记操作的时间标签,操作包含插入与读取操作.在执行第1 步~第4 步时,在存储空间未满的状态下,依次将数据单元A,B,C,D插入到存储空间中.在第5 步时,由于存储空间已满,LRU 算法选择距离上次访问最长时间的数据单元A进行踢出,并插入新数据单元E;在第6 步时,由于数据单元B被访问,将数据单元B移至存储空间最右侧,同时更新时间标签;第7 步时,需要插入新数据单元F,由于存储空间已满,与第5 步相同,此步踢出最左侧数据单元C,将F放入最右侧存储空间中.LRU 由于存在算法实现简单、在一定场景下命中率高、对应用性能影响小的特点,被缓存替换系统广泛使用,如memcached[5]、memC3[8]、MICA[4]等.
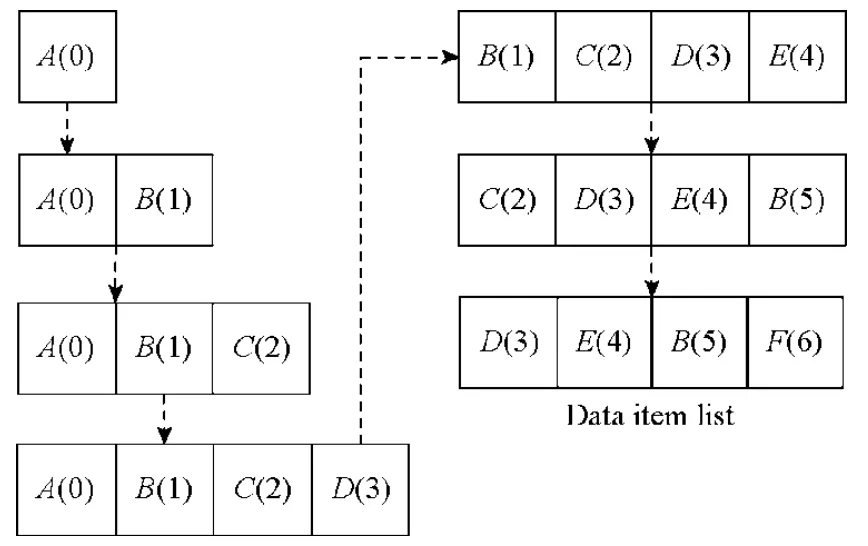
Fig.2 Using LRU replacement police manages data items图2 通过LRU 缓存替换策略管理数据单元
LRU 算法在实现过程中,通常采用链表和时间戳两种方式.采用链表方式进行实现时,通常与邻接散列表结合使用[5],通过数据单元内的指针快速访问散列表和LRU 算法管理的数据结构.采用时间戳的方式,常用于固定单元大小的索引结构,通过对时间戳的比较,选取最早访问的数据单元进行踢出[47].
2.4 CUDA编程技术
计算统一设备架构(compute unified device architecture,简称CUDA)是显卡厂商NVIDIA 推出的并行计算架构,已逐步发展成为NVIDIA GPU 的编程标准规范.
CUDA 提供了基于标准C 语言的编程模型,支持对GPU 操作相关的关键字与结构体.基于CUDA 的GPU编程程序中包含CPU Host 端执行代码与GPU Device 端代码,程序中的两部分代码通过CUDA 的编译器自动地分为两部分进行编译与链接[48].
CUDA 支持程序开发人员编写称为内核(kernel)的设备方法代码.内核被GPU 以单指令多线程(single instruction multiple thread,简称SIMT)形式执行.在程序执行过程中,加载一个内核方法相当于调用内核方法,同时,程序开发人员需要指定对应的GPU 空间网格(grid)执行.一个网格包含多个线程块(block),构成一个二维空间,每个块中包含多个线程,构成一个三维空间.每个GPU 中的线程都通过线程标识符(thread id)进行标识.在一个块中的线程可以通过栅栏实现同步.
GPU 线程在内核方法执行过程中获得GPU 内存的访问权限.每个线程对存储的操作包括读写私有寄存器和本地内存.内核方法中的本地变量被自动地分配到寄存器或者内存中.GPU 其他内存中的变量可以通过接口创建与管理.在CUDA 程序中可能包含多个内核,所有的操作都可以应用于每一个内核.在下文介绍的CCHT 设计与实现过程中,将所有的CHT 与替换操作全部实现于内核中,以提高程序的执行效率,同时面向单一的处理器实现能够更方便地向其他平台进行移植.
3 基于不同索引空间占用缓存索引CCHT 方法
在本节中,我们主要介绍了基于不同索引空间占用的缓存索引方法的设计与实现,包括索引结构设计与缓存替换算法.其中,第3.1 节给出了面向内存缓存的散列索引分析,第3.2 节描述了双重LRU 索引访问方法,第3.3节描述了粗粒度LRU 索引访问方法.
3.1 面向内存缓存的散列索引分析
在内存缓存系统中,散列索引与缓存替换策略一般分别加以实现[5,8].散列索引用于对内存中的缓存数据进行索引,在缓存系统处理查询请求时可快速访问目标数据.常见的散列索引,如本文提到的应用于MemC3[8]中的CHT 和memcached[5]中的开散列(open hashing)方法.替换策略用于当内存缓存被所需缓存数据存储已满时,有新的数据需要进行缓存,则在已缓存数据中通过某一策略选择待踢出数据,进行替换.常用的缓存索引方法有本文中提到的LRU、FIFO(先进先出算法)、LFU(最近最常使用算法)、CLOCK(时钟算法)[49].其中,LRU 由于实现简单,维护方便,策略符合一般工作负载需求而被广泛使用.
当通过CHT 进行数据索引时,每个数据对应两个可选的桶,如果两个桶中已无空闲槽,则需要在两个位置中选择随机槽内数据进行置换,之后根据置换出的键值数据进行散列值计算,可能会导致更多次的访存操作,如第2.1 节中所述.在内存缓存系统中,缓存数据无持久化存储需求.缓存替换策略可根据多维度指标,如命中率、访问延迟、空间占用率、吞吐等踢出缓存数据.因此,我们设计了内置缓存策略的CCHT,即在内存缓存系统中,以CHT 为基础,当索引散列表需要进行踢出置换时,调用缓存替换策略,进行踢出.我们依据索引开销与命中率需求实现了两种方法,在后文中将分别加以描述.
3.2 双重LRU CCHT缓存索引方法
CCHT 设计的核心思路是通过添加桶内缓存队列操作移除CHT 原有的无空闲槽时进行的置换操作,达到减少内存访问和支持插入与查询操作并发执行的目的.
双重LRU CCHT 缓存索引结构与典型的LRU CHT 的结构类似.如图3 所示,在结构中通过散列表对键值数据进行索引.每个散列值对应一个桶,每个桶中包含有固定数量的槽.每个槽中包含有键值数据,占用标示,两个用于桶内LRU 的槽指针,两个用于全局LRU 的槽指针.其中,与典型的LRU CHT 结构不同的是增加用于桶内LRU 的槽指针.为方便理解与后续方法描述,我们在图3 中对每个桶添加时间戳标签,该时间戳等同于每个桶中LRU 队列队尾单元的时间戳,标记每个桶中现有最早放入元素的时间.
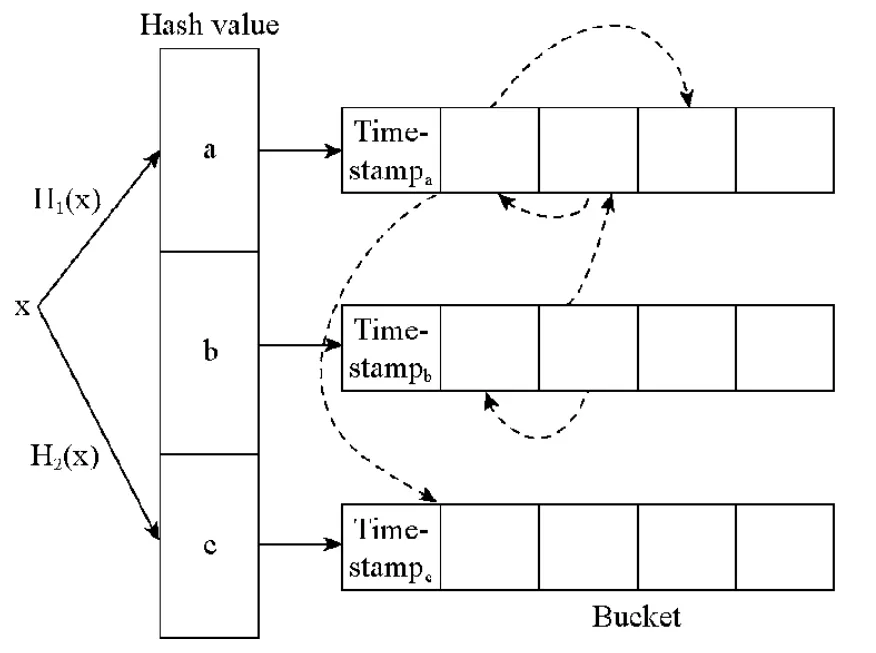
Fig.3 Double LRU CCHT structure图3 双重LRU 的CCHT 缓存索引结构
在通过CCHT 向内存缓存中插入键数据key 和值数据value 时,如算法1 所示.如果内存缓存中有空闲缓存空间,通过散列函数Hash1(key)得到对应的散列值H1,检查H1对应的桶中是否有空闲槽.如果有空闲槽,则将键值数据插入该槽,更新占用标记,并将该槽置于全局LRU 队列队首和桶内LRU 队列队首;如果没有空闲槽,则通过Hash2(key)计算得到散列值H2,检查对应桶中是否有空闲槽,如果有空闲槽,则进行上述相同操作.如果H1和H2对应的桶中都没有空闲槽,则比较timestamp,选择时间戳较小的桶.如果H2的时间戳较小,说明散列值H2对应的桶中LRU 队尾的槽相对散列值H1对应的桶中LRU 队尾的槽更久没有被访问.踢出散列值H2对应的桶中LRU 队尾的槽,包括释放对应的键值数据,在全局LRU 队列与桶内LRU 队列中进行踢出.将待插入的键值数据插入该槽中,并将该槽置于全局LRU 队列和桶内LRU 队列队首.如果插入键值数据时,内存缓存中无空闲缓存空间,则需要先通过全局LRU 队列踢出队尾槽对应的键值数据与LRU 队列槽指针.
通过CCHT 查询方法与第2.1 节中描述的通过CHT 进行查询类似,如算法2 所示.在返回查询结果的同时,如CCHT 中包含所需查询的键值数据,则将键值数据对应的槽放置在全局LRU 队列队首和桶内LRU 队列队首.
通过双重LRU CCHT,将原有键值数据插入过程中的踢出置换操作变为缓存替换,去除了由于置换操作引发的内存访问次数和查询空闲槽的时间.双重LRU CCHT 通过全局LRU 队列和桶内LRU 队列独立使用保证了内存缓存系统的命中率.这种方法相对于LRU CHT,增加了用于桶内LRU 队列的指针存储空间开销.因此,我们提出了粗粒度LRU CCHT,相对双重LRU CCHT,节省了指针占用存储空间的开销.
算法1.双重LRU CCHT 插入算法.


算法2.双重LRU CCHT 查询算法.

3.3 粗粒度LRU CCHT方法
为了节省CCHT 中指针占用的存储空间,我们提出了粗粒度LRU CCHT 方法,如图4 所示.相对双重LRU CCHT 索引结构,取消了用于全局LRU 队列的槽指针,添加了基于桶的LRU 队列操作.每个桶中包含有两个桶指针,用于维护粗粒度的LRU 队列.
当通过粗粒度LRU CCHT 方法进行插入操作和查询成功后,将对应桶放置于桶LRU 队首,对应的索引单元放置于桶内LRU 队首.当插入数据时,若内存缓存中无空闲缓存空间,则选择桶LRU 队列中位于队尾的桶,选择队尾桶中的桶内LRU 队列队尾的槽进行键值数据的踢出与释放.
粗粒度LRU CCHT 方法通过桶LRU 算法取代了双重LRU CCHT 方法与LRU CHT 方法中的全局LRU 索引.相对于双重LRU CCHT,减少了2×m×(s-1)个槽指针占用,其中,m为CCHT 内桶的个数,s为单个桶中槽的个数,为CCHT 节省了索引存储开销.
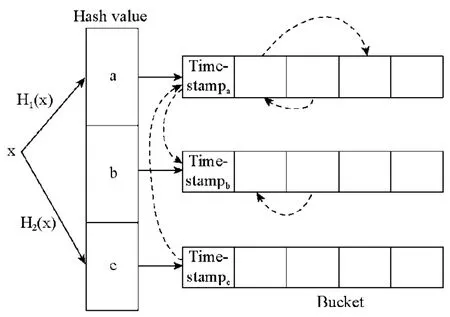
Fig.4 Coarse LRU CCHT structure图4 粗粒度LRU CCHT 缓存索引结构
4 CCHT 在面向CPUGPU 异构环境上的实现
根据第3 节中CCHT 的方法描述,本节主要介绍了CCHT 在CPUGPU 异构环境上进行的实现.其中,第4.1节描述了面向CPUGPU 异构存储下的多级数据索引结构,第4.2 节给出了异构环境下CCHT 的应用接口函数,第4.3 节描述了CCHT 的实现细节,第4.4 节给出了CCHT 在实现过程中的优化.
4.1 异构存储下的多级索引数据结构
在现实应用中,如图数据、日志数据及视频数据为值数据的散列表值数据存储空间开销大.以GPU 内存为散列表的处理设计与性能受到了系统PCI 总线带宽和GPU 内存大小的限制.因此,我们采用了基于外存计算系统的方式设计了多级索引数据结构.在存储空间初始化时,在CPU 内存中分配连续的存储空间.在对GPU 上散列表进行操作时,用CPU 上原始值数据对应的索引序列值进行表示,减少了GPU 内存空间的占用及PCI-E 带宽传输开销.
键值数据在CPU 和GPU 的分布如图5 所示.如插入键值数据对KV1,值数据V1存储在CPU 内存的连续值存储区,位置标识ID 为0;键数据K1与索引位置ID 值0,通过系统总线传输至GPU 内存中,并存储在对应散列值桶中的空闲槽内.当查询KV3时,将K3通过系统总线传输至GPU 内存中,待查询完成后,通过总线返回对应位置标识 ID 值 2.通过多级CPUGPU 异构值索引结构,有效地减少了GPU 中内存的占用和总线带宽占用.在GPU 内存中,除查询必须的键数据,仅包含值数据的位置标识外,相对于原始值数据,减少了有限GPU 空间内存的占用.在请求处理时,插入与查询的值数据均不通过总线传输至GPU 内存,有效地避免了因值数据过大造成的总线带宽占用以及性能损耗.
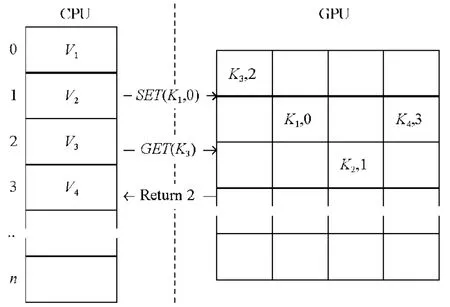
Fig.5 The CCHT data structure under CPUGPU图5 CPUGPU 下的CCHT 数据结构
4.2 异构环境下CCHT的应用接口函数
CCHT 实现的方法主要包含接入库函数,数据存储区域初始化函数及操作散列表的GPU kernel(核)函数.我们采用的CUDA 9.1 版本的GPU 编程框架,代码行数共计1 385 行,其中接入库函数与数据存储区域初始化函数为324 行,GPU kernel 函数为953 行,其余为宏定义及全局变量索引.
实现的方法与功能描述见表1 和表2.表1 给出了在CPU 上实现的函数,主要包含用于其他CPU 程序调用进行键值操作的接入库函数、CPU 与GPU 存储区域索引与内容初始化的数据初始化函数,以及向GPU kernel函数提交任务与键值数据的函数.CPU 上的函数主要向其他程序提供了键值数据操作的接口,对GPU 上的kernel 函数进行了封装,实现了其他程序调用时对GPU 操作的透明化.表2 给出了GPU 上的kernel 函数.主要包含了GPU 用于接收与解析CPU 提交键值操作任务和数据的global 函数、散列表操作的device 函数、缓存队列踢出操作的device 函数.GPU 上实现的kernel 函数用于在GPU 存储区域中的散列表上处理对应的键值数据.

Table 1 Interface and implemented methods on CPU表1 CPU 接口与实现函数

Table 2 Kernel method on GPU表2 GPU 核函数
CCHT 在GPU 上的操作仅包括CCHT_set、CCHT_get、CCHT_del 和CCHT_evict 这4 个分支核函数操作,符合GPU 以单指令多线程(single instruction multiple thread,简称SIMT)形式执行.CCHT 在CPUGPU 异构环境下执行可以获得更好的并发性能.
4.3 实现细节
在数据存储区域初始化时,采用malloc 与cudaMalloc 分配所需存储区域.其中包含了在CPU 上执行缓存操作与键值数据的存储区域、GPU 执行结果返回的存储区域;在GPU 上接受执行操作与键值数据的存储区域、以槽为单元的散列表键值数据存储区域、桶中标识的存储区域及散列表操作执行结果的存储区域.在完成分配后,通过memset 与cudaMemset 实现数据存储区域的初始化.
在CPU 上操作键值数据的函数,将其他程序调用传递进的键值数据与操作,复制至CPU内存中的键值数据与任务的缓冲队列中.所有操作键值数据的函数共用同一数据与任务缓冲队列,允许任务缓冲队列中包含多个写操作和多个读操作.当达到向GPU 提交任务数的阈值时,则调用flush_ops 函数,通过global 函数CCHT_process 向GPU 传递数据及相应的操作标识.当向GPU 提交的任务执行完成后,将结果返回至指定的存储区域.在CPU 上运行的程序对结果进一步处理,如判断读操作是否命中、更新可用缓存空间大小等.
在GPU 上执行核函数时,每个核函数线程执行单一任务及键值数据操作,根据GPU 线程的全局id 进行指定,CCHT_process 接受传递进入GPU 内存的键值数据及任务数据,并根据任务数据的标识进行解析,以获取操作类型.对不同的散列表操作选择调用CCHT_set、CCHT_get 或CCHT_del,完成后将结果返回至指定的GPU内存存储区域.当内存缓存空间已满时,CPU 传递的写操作的任务数据包含替换操作与写操作,GPU 在调用CCHT_evict 执行踢出操作后,再调用CCHT_set 进行写操作.
4.4 优化细节
CCHT 采用任务批处理提交方式.在其他程序调用接入库函数时,将传入的键值数据及对应的操作复制到键值数据与操作的缓冲区,当达到批处理提交的任务数阈值时,将键值数据及操作提交至GPU 核函数,由GPU线程根据线程id 并发对相应操作的键值数据进行处理.通过任务批处理提交的方式,减少了CPU 与GPU 间内存的访问与传输频次,减少了PCI-E 总线的访问,同时能够充分利用GPU 多线程的并发性,提升散列表任务的处理性能.
通过GPU 执行维度参数配置实现单一warp 中执行一种指令.在CCHT 中,指令分支出现于各线程运行global 函数CCHT_process 后,需要根据散列表操作类型,调用不同的device 函数.如果采用同一warp 中混合多种操作,将导致由warp divergence 引发的同一warp 中的不同散列表操作类型将顺序执行.我们通过限定同一warp 执行单一线程实现避免指令分支造成的同步等待.虽然同一warp 中仅执行单一线程影响了GPU 的并发性能,但基于warp 粒度的并发仍能达到很好的吞吐效果,这一点,在后文的第5.5 节中得到了验证.
在键值数据与任务缓存区的实现上,采用了混合与复用的方式.所有操作的键值数据与任务共享一个连续的缓冲区.在返回结果时,将数据返回至提交任务的数据缓冲区中.这种混合与复用的实现方式减少了CPU 与GPU 内存的空间开销,释放了更多内存空间用于键值数据的存储.同时,相对多段缓存区的设计,连续的内存访问操作比例增大,减少了因为数据存储在多段缓存区域造成的内存访问.
基于CUDA 原生的原子操作锁机制.在CCHT 中,包含并发写入、读取槽数据与变更LRU 队列的操作,需要对每个槽和LRU 队列进行读写锁设计.即需要支持多个线程同时操作数据可以获得更好的并发性能,防止因锁等待导致单个线程任务延迟过长.我们在GPU 内存中设置了锁标识数据,默认值为0.对于写操作,采用了原子atomicMax()方法实现,返回现有标识数据,并将标识数据更新为现有标识数据与置入数据的最大值.在置入数据值为1 的情况下:当返回值为0 时,表明锁空闲,完成后通过atomicExch()置0 解锁;当返回值不为0 时,表明有其他读或写线程正在访问数据.对于读操作,基于atomicAdd()的方法进行实现,返回现有标识数据,并将标识数据更新为现有标识数据与置入数据之和.当返回值模2 值不为0 时,表明有写线程正在访问数据;当返回值模2 结果为0 时,表明无其他写线程访问数据.成功占用锁并完成操作后,通过atomicSub()方法释放当前读线程对锁占用.通过上述方法实现了允许同一时间单一写操作或多个读操作同时进行.基于CUDA原生的原子操作锁机制代替了CUDA 传统原子数据操作赋值方法,打破了对依赖CUDA 库函数的原子操作数据大小的上限限制.在CCHT 的GPU 端处理任务请求过程中,线程同一时刻仅可能获取单个槽的锁,不会因为多个锁资源同时抢占而造成死锁.
5 实验结果与分析
实验在CPU+GPU 异构服务器上进行,其中,CPU 为Intel(R)Core(TM)i7-6700K,四核4.00Ghz 主频,内存DDR4 32GB,GPU 为NVIDIA GeForce GTX 1080Ti,显存11GB.
实验中采用YCSB[50]生成的数据集进行测试,数据键值的长度为24B,值类型为100B,插入数据集的规模为3×106个元素.数据操作请求包括3 种典型的工作负载,Zipf、latest、uniform.其中,Zipf 工作负载分布偏度为0.99,latest 工作负载为最近使用的数据请求,uniform 工作负载查询的数据概率相同.每个工作负载请求中包含两类插入与查询操作比值,分别为全部是查询操作以及查询操作占比50%.根据内存缓存典型运行环境特征[12],在查询返回丢失后,进行插入操作.在实验过程中,首先进行数据集加载与缓存预热操作,然后再进行工作负载请求操作.
为了对CCHT 应用性能进行验证,我们实现了以CCHT 为核心的缓存替换系统原型.为了对比,还实现了另外3 种缓存索引算法:LRU CHT、LRU 开散列表(LRU open hash)、随机CHT(random CHT),其中,LRU CHT 与随机CHT 在CPUGPU 异构平台下进行对比验证.LRU 开散列表由于动态分配数据空间的特性不适用于CPUGPU 异构平台的初始化固定存储空间,我们在CPU 平台进行了实现与对比验证.设置CCHT 与CHT 的散列值长度为24,每个散列值对应的桶包含4 个索引存储单元.CHT 的踢出替换操作上限为5 000 次.CCHT 批处理的阈值设为2 000.散列表装载率由缓存空间大小与散列表最大索引数量的比值来表示.
5.1 插入平均访存
插入平均访存是指在进行数据集加载与缓存预热操作过程中的平均访问内存次数.本文中,latest、zipf、uniform 工作负载预热与加载的数据内容与顺序相同,实验结果如图6所示.当缓存空间大小与散列表比值大于60%时,双重 LRU CCHT 与粗粒度 LRU CCHT 均显著低于其他算法.当缓存空间大小与散列表大小比值为 80%时,双重 LRU CCHT 与粗粒度LRU CCHT 的平均访存次数对比LRU CHT 均降低了30.39%.当缓存空间大小与散列表大小比值为90%时,双重LRU CCHT 与粗粒度LRU CCHT 的平均访存次数对比LRU CHT 均降低了94.63%.说明CCHT的两种方法能够有效地减少内存访问次数,当缓存空间大小与散列表大小比值较高时,CCHT 对比CHT 去除了踢出与替换操作,大幅度地减少了散列表的访问次数,从而减少了内存访问次数.
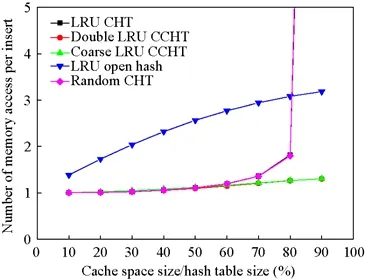
Fig.6 Average memory access per insert with Hash table size图6 插入平均访存次数随缓存空间大小变化
5.2 全局平均访存
全局平均访存是指在工作负载测试集加载过程中的平均访问内存次数.图7 描述了在6 种不同的工作负载下,5 种缓存索引算法的全局平均访问内存次数随缓存空间大小发生变化的实验结果.
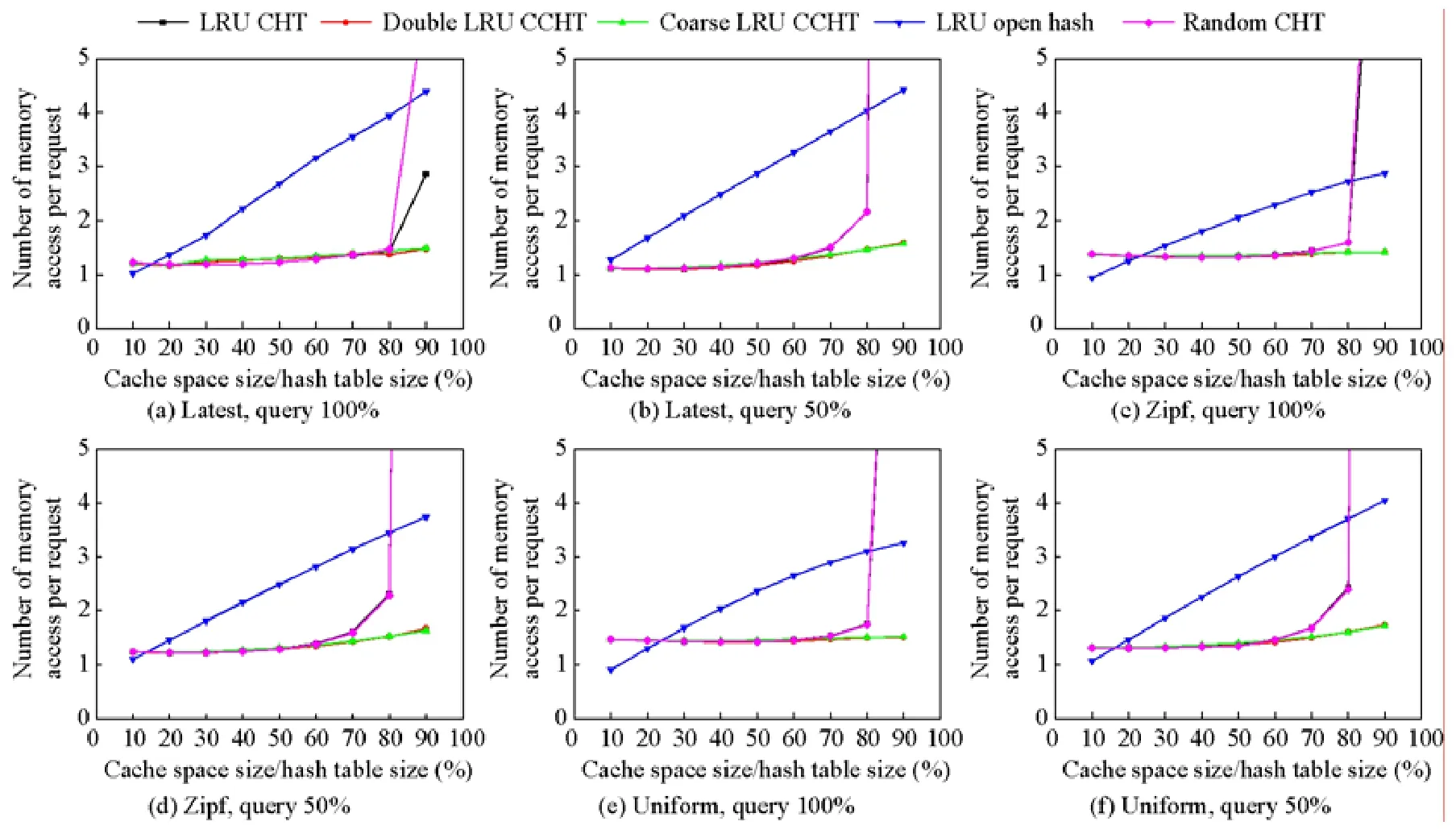
Fig.7 Average memory access per request with hash table size图7 全局平均访存次数随缓存空间大小的变化
当缓存空间大小与散列表比值大于60%时,双重LRU CCHT 与粗粒度LRU CCHT 均低于其他算法.其中,当query 占比为50%时,双重LRU CCHT 与粗粒度LRU CCHT 的效果对比LRU CHT 更加明显地减少了平均访问内存次数.在latest,query 50%、zipf,query 50%、uniform,query 50%中的70%、80%、90%,双重LRU CCHT平均降低了10.59%、32.86%、97.25%,粗粒度LRU CCHT 平均降低了9.50%、32.91%、97.29%.原因是在query占比为50%的工作负载中,有大量的插入操作.随着缓存空间的增加,LRU CHT 和随机CHT 方法需要更多的踢出替换操作以获得空闲的索引空间,导致了大量的内存访问.而双重LRU CCHT 和粗粒度LRU CCHT 随着缓存空间的增加,没有访问更多的索引位置.
5.3 命中率
命中率是指在工作负载测试集加载过程中,查询成功的次数占所有查询次数的比值.图8 描述了在6 种不同的工作负载下,5 种缓存索引算法的命中率.在zipf 和uniform 分布的4 种工作负载中,双重LRU CCHT 和粗粒度LRU CCHT 与LRU CHT 的命中率表现相同,命中率均随着缓存空间的增加而增加.其中,双重LRU CCHT与LRU CHT 的命中率差值最大不超过0.12%,粗粒度LRU CCHT 与LRU CHT 的命中率差值最大不超过0.22%.在latest 分布的两种工作负载中,双重LRU CCHT 与LRU CHT 的命中率差值最大不超过0.18%,粗粒度LRU CCHT 与LRU CHT 的命中率差值最大不超过0.56%.CCHT 中引入了在散列表桶内无空闲槽时,通过桶内LRU 算法踢出槽用于插入操作.CCHT 相对LRU CHT 和LRU 开散列表增加了缓存踢出次数,导致了命中率的偏差.同时,由于采用了基于LRU 队列的踢出策略,保证了CCHT 的命中率相对CHT 偏差要小.
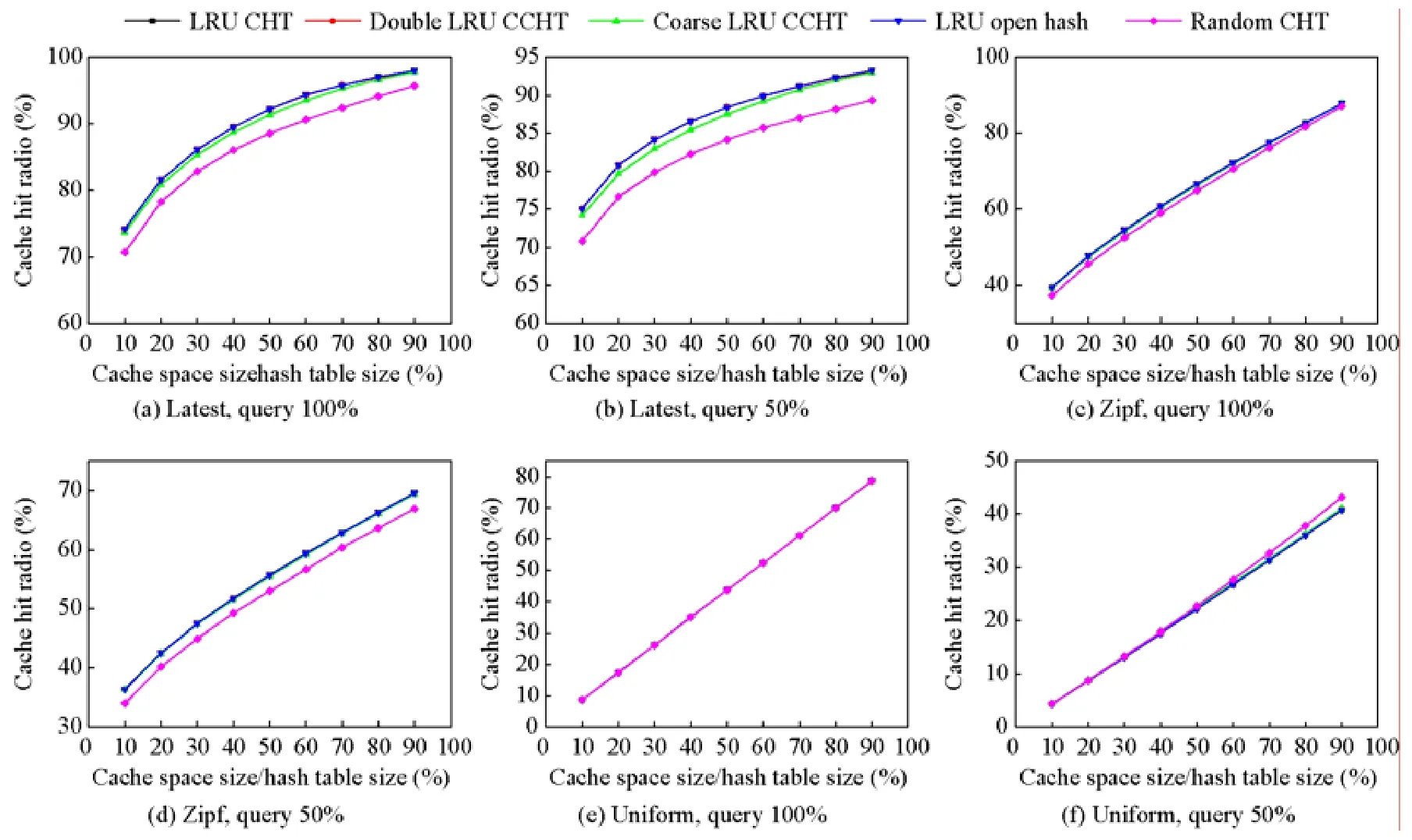
Fig.8 Cache hit radio with hash table size图8 命中率随缓存空间大小的变化
5.4 索引开销分析
索引开销是指,在存储过程中,当缓存空间已满时,LRU 队列中槽索引指针的数目.CCHT 在移除CHT 置换操作的同时,引入了用于LRU 队列的槽指针索引空间开销.本节实验分析了双重LRU CCHT 与粗粒度LRU CCHT 在不同缓存空间大小情况下的索引开销,见表3.当缓存空间大小与散列表大小比值大于等于30%时,粗粒度LRU CCHT 的开销明显小于双重LRU CCHT 的开销.当缓存空间大小与散列表大小的比值为90%时,粗粒度LRU CCHT 比双重LRU CCHT 减少了31.71%.当比值小于等于20%时,粗粒度LRU CCHT 索引开销大于双重LRU CCHT 的开销,原因是粗粒度LRU 的一部分索引开销来源于散列表散列值对应桶之间的索引,没有随缓存空间大小的变化而变化.当缓存空间增大后,使用的槽增多,索引开销主要来源于槽间的链接索引.而双重LRU CCHT 的全局LRU 队列的槽索引开销大于粗粒度LRU CCHT 的开销,导致了两种CCHT 算法的开销比值逐渐增加.
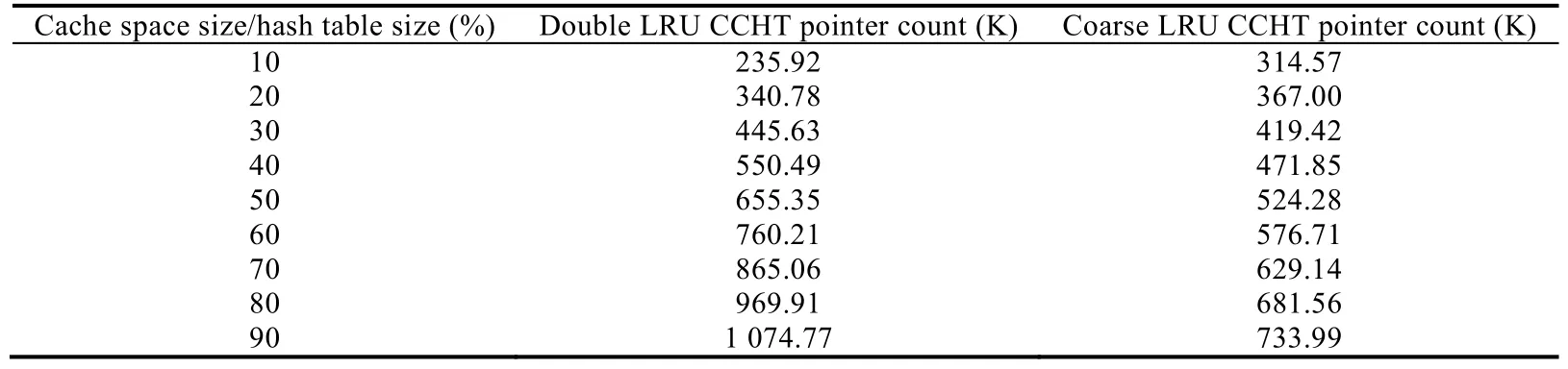
Table 3 The point count with different cache size for CCHT表3 CCHT 在不同缓存大小情况下的指针索引开销
5.5 CCHT在CPUGPU上的吞吐性能
我们将CCHT 在CPU+GPU 异构服务器环境上的吞吐性能进行了实验.在CPUGPU 异构环境上的吞吐性能是指CCHT 每秒钟处理的请求数.在80%缓存空间占比的工作负载下,性能实验结果如图9 所示.在不同的工作负载中,CCHT 相对LRU CHT、Random CHT 和LRU 开散列表均有显著的性能提升,最高达126.43 倍、143.17倍和1.78 倍.其中,造成LRU CHT 和Random CHT 性能最低的原因是对于CHT 的读写请求只能顺序执行,无法并发执行,进而导致每次操作类型切换时,需要通过PCI-E 总线进行数据传输,带来了频繁的内核上下文切换与驱动调用,最终导致了性能的大幅度降低,甚至远低于CPU 平台上的LRU 开散列算法的性能.相对于LRU CHT,CCHT 支持了所有操作类型的并发执行,最大程度地利用了GPU 上的流处理器等硬件并发资源,同时有效减少了CPU 与GPU 之间由于频繁的数据传输带来的额外开销;去除了写操作在高负载率下频发的置换操作,减少了GPU 处理过程中的内存访问次数,使散列表索引访问性能得到提升.
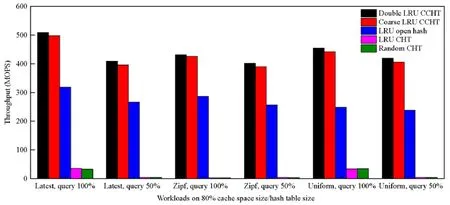
Fig.9 Performance on workloads with 80% cache space size/hash table size图9 在80%缓存空间工作负载中的性能表现
5.6 CCHT在CPUGPU上的延迟
我们将CCHT 在CPU+GPU 异构服务器环境上的延迟进行了实验.延迟实验包括在CPU+GPU 异构服务器环境上的数据传输延迟和单次操作的平均延迟.其中,数据传输延迟表示散列表在运行过程中单次调用GPU时,数据在CPU 和GPU 内存间传输的延迟时间.在CCHT 中具体是指调用GPU 处理散列表请求时,请求数据与操作命令缓冲区由CPU 内存拷贝到GPU 内存和请求结果由GPU 内存拷贝到CPU 内存的时间总和.数据传输延迟时间见表4,4 种散列表在各工作负载中单次调用GPU 数据传输的规模相同,我们采用以80%缓存空间占比的latest、query 100%工作负载为代表进行实验验证.其中,双重LRU CCHT 和粗粒度LRU CCHT 的数据传输延迟均高于LRU CHT 和随机CHT,原因是CCHT 采用了批处理操作,允许散列表在GPU 上大规模并发处理请求.以实验设置的批处理阈值2 000 为例,CCHT 在调用GPU 时,单次的传输数据包括2 000 个操作数据和操作请求类型,平均单个操作数据和操作请求类型的传输延迟远低于LRU CHT 和随机CHT.
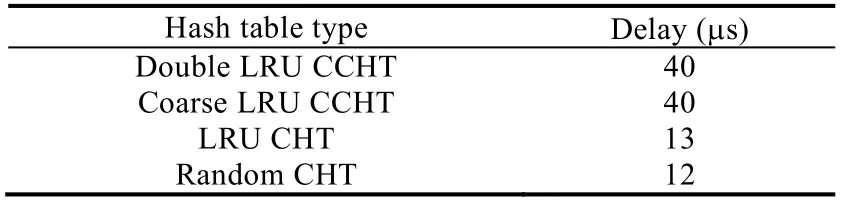
Table 4 CPUGPU data transfer delay表4 CPUGPU 数据传输延时
进一步地,我们对单次操作的平均延迟进行了对比评估,即散列表处理单次请求在CPU 或GPU 环境上的平均延迟时间.其中,LRU 开散列表为单次请求处理在CPU 环境上的平均延迟时间,其余散列表为单次请求处理在GPU 环境上的平均延迟时间.单次操作的平均延迟如图10 所示.双重LRU CCHT 和粗粒度LRU CCHT 的延迟时间高于其他散列表,原因是CCHT 实现了GPU 上大规模的并发操作,虽然通过warp 分配避免了分支等待的延迟开销,但各线程间仍存在着对于槽和LRU 队列锁的竞争操作,以及在同一次批处理中的同步开销,即执行完操作的线程需等待未执行完操作的线程完成后一同返回.这类操作均带来了额外的开销,导致了延迟的增加.同时,从实验结果可以看出,粗粒度LRU CCHT 的延迟同样高于双重LRU CCHT.这是因为粗粒度LRU CCHT 在全局和桶内共用的同一LRU 队列均在GPU 环境上进行操作,相对双重LRU CCHT 仅桶内锁在GPU环境上进行操作,粗粒度LRU CCHT 存在更多的锁竞争.LRU CHT 和随机CHT 虽然低于前两者,但由于受高负载下可能发生插入操作出现频繁槽数据置换的影响,单次延迟最高达到了143μs,远高于平均延迟时间.LRU 开散列表由于没有锁竞争以及运行在CPU 环境上,延迟时间在0.36μs~0.49μs.
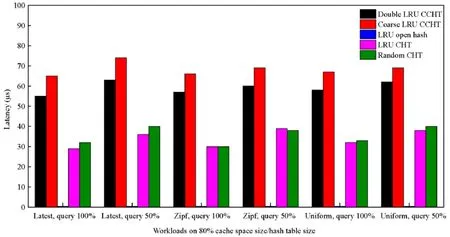
Fig.10 Latency on workloads with 80% cache space size/hash table size图10 在80%缓存空间工作负载中的延迟表现
6 结束语
数据索引的性能依赖于平均访问内存数.传统的CHT 数据索引在缓存中应用时,当缓存空间大小与CHT空间比值较高时,CHT 频繁的踢出替换方法增加了内存访问数,进而对缓存性能造成了影响.本文分析了基于键值的内存缓存系统命中率与索引开销因素,依据索引指针开销给出了双重LRU CCHT 和粗粒度LRU CCHT,提供了用于CPUGPU 环境下减少总线传输与GPU 内存占用的多级索引数据结构,并在CPUGPU 异构环境下加以实现.通过实验验证,CCHT 在保证缓存命中率的同时,能够有效地减少内存访问次数,在GPU 上有良好的可扩展性与吞吐性能.
未来的工作我们希望进一步优化索引指针的开销,提升缓存的命中率.在GPU 的实现方法中,考虑通过优化槽单元锁和LRU 队列锁以提升并发插入的性能,在散列任务提交任务队列前识别任务类型,预先分配任务执行所在的warp,达到同一warp 中并发执行多个散列表操作,并达到线程粒度的并发性能,提升GPU 硬件资源利用率.
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
电脑爱好者(2020年18期)2020-09-26
小读者之友(2019年9期)2019-09-10
东坡赤壁诗词(2018年6期)2018-12-22
意林·少年版(2018年1期)2018-02-07
电脑爱好者(2017年9期)2017-06-01
CHIP新电脑(2016年3期)2016-03-10
网络与信息(2009年9期)2009-10-30
