
互联网金融个人信用风险评估的指标选择方法
2019-12-30 01:43曾鸣谢佳
时代金融 2019年33期
曾鸣 谢佳


摘要:完善的个人信用风险评估体系是降低信用风险的决定性因素,而风险评价指标的构建是信用评估的基础。本文选取Prosper.com网贷平台2005年至2014年间部分信贷数据进行实证,研究了主成分分析法(PCA)在筛选信用评估指标上的应用,在此基础上结合支持向量机(SUM)技术,建立评估模型进行验证。结果表明,采用主成分分析法可以有效地剔除无关变量和冗余变量,提高互联网金融个人信用评估的预测精度。
关键词:互联网金融 信用风险 个人信用评估 主成分分析法
一、引言
随着国民信用消费需求的不断上升,互联网技术的不断更新,互联网金融行业得到了飞速的发展。互联网金融行业在模式不断丰富、规模不断扩大的同时,也面临着诸多亟待解决的问题。由于在客户群体的选择和产品类型的定位上与传统商业银行存在巨大差异,同时缺乏有效的客户信用评估体系,互联网金融平台面临比传统银行更高的交易对手违约风险,这一现象严重阻碍了互联网金融个人信贷业务的发展。
如今产生个人信用数据的各类电商平台、社交平台的数量不断增加,信用数据的规模呈现爆炸式增长,不同于标准的经过财务核实的银行数据,互联网的信用数据是非标准化的,个人信用风险也呈现出不同的特点,信息不对称现象更加明显。个人信用风险的评估大致经过数据清洗、输入变量的生成和建模进行风险评估这样几个阶段,无论是传统的信用风险评估还是基于互联网大数据的信用风险评估,输入变量的质量都会直接影响风险评估模型的预测效果。由于传统信贷和互联网金融的数据特征不同,互联网金融的数据覆盖维度广且数据较为稀疏,单项数据的信用评估价值密度较低,单变量的风险区分能力较弱[1],因而基于大数据的信用评估指标也会有所不同。对输入的评估指标进行有效筛选,可以减少模型训练时间和数据搜集成本,提高模型预测精度,构建有效的互联网金融信用风险评估体系。
二、互联网金融平台信用风险评估指标体系的现状
大部分互联网金融平台的大数据应用得并不成熟,借款人的电商购买记录,社交网络信息等数据来源的匮乏,会给互联网金融平台的信用评价带来严重的滞后和误判。很少有平台在信用风险评价指标中完全涵盖了借款人的职业信息、电商数据、线下行为数据、征信数据等指标。
国内的互联网金融平台指标体系的设计主要参考了国外平台的信用评估指标体系,如FICO评分模型和Prosper指标体系,评估大类基本一致,主要分为用户的基本信息、工作信息、历史交易信息、偿还贷款能力信息、借款信息等。在一级指标上主要继承传统商业银行和国外网贷平台的指标体系,但在二级指标如所在城市类型、工作年限、房产情况、社交媒体活跃度、社交关系密度等方面,侧重点各不相同。
国外互联网金融平台的信用评估指标体系则不局限于借款人的基本信息和历史借贷信息,普遍比国内研究者更关注借款人与借贷平台直接相关的借款信息:如在该借贷平台的贷款金额、所获贷款年利率、还款期限以及逾期金额等指标。在个人基本信息方面,对性别、婚姻状况、学历和工作行业的关注不高,相对更关注工资范围、是否有房、居住地、年龄、职业、照片等。对项目投资人数、社交媒体文本描述状况、平台注册时长等关注度较低。
三、个人信用风险评估指标的PCA筛选方法
由于互联网金融信用风险涉及的指标众多,部分指标之间呈现出较高的关联性,容易引起数据冗余问题,影响评估效果,因此需要对评估指标进行降维处理。本文采用主成分分析法对评估模型的指标进行降维筛选。
主成分分析法通过观察原指标集合之间的内容结构关系,将原本相互之间具有一定相关性的众多指标重新组合成一个新的、互不相关的指标集合。对于一个特征矩阵来说,通过将其对角化产生特征根及特征向量,将其在标准正交基上投影,该特征向量方向上的投影长度就对应到其特征值,特征数值越大说明对应的特征向量所携带原有数据的信息越多,通常在特征筛选过程中,选择特征值累计贡献率85%的指标就能满足大多数研究的需求。主成分分析法的优点在于得到的新的综合指标之间相互独立,减少数据冗余,且权数的计算基于数据分析得到的指标内部结构关系,不受主观因素干扰。
四、数据选取及实证分析
文中数据来自Prosper Loan Data数据集,使用MARLAB软件进行实验,首先对所获得数据进行预处理,然后利用主成分分析方法筛选数据指标,确定最终输入模型的变量,最后采用粒子群算法优化的支持向量机模型(PSO-SVM)进行验证。
(一)数据预处理
1.数据清洗。本文采集美国Prosper.com平台2005年至2014年间部分信贷数据,数据集包含11万余条原始记录,首先对数据进行清洗,一是无意义字段的舍弃,如原始数据中部分管理识别符号的变量,以及关于贷款申请、批准日期、规定的还款日期等对于本次研究没有任何意义的字段。二是缺失数据的处理,对缺失值达到一半以上、严重影响了数据真实性的字段进行了直接剔除。对于缺失率较小的数据进行补齐,连续型数据用中位数补齐,对离散型数值变量使用众数补齐。三是噪声数据的处理,为对整个数据表进行了遍历,通过将数据值与标准数据的对比,找出噪声数据,并用众数对其进行替换。
在对原始数据集進行以上一系列操作后,数据集剩余指标51个,其中输入变量指标50个,输出变量指标1个。如表1所示:
2.数据赋值。一是对输入变量的赋值:
借款人信息特征中包含定量信息和定性信息,对定性信息需要在数据准备过程中做离散化处理。对定性数据分别取0和1。
二是对输出变量的赋值:
在Prosper数据集中,借款人的借款状态共有12种,为实现SVM二分类效果,实验前需要将输出变量转化为1或-1的状态。由于无法判断处于“Current(正常还款中)”状态的贷款最终会不会违约,所以在研究时,将状态为Current的样本进行了删除;同理,“Cancelled(交易取消)” 的数据也进行删除。
从风险发生的可能性出发,笔者把剩余10类数据归为两个大类:第一大类“good”(只包含Completed、Final_Payment_In_Progress两种数据);第二大类“bad”(包含Defaulted、Chargedoff和所有的Past Due,共8种数据)。将“good”和“bad”两个类的数据分别编码为1和-1。
3.数据标准化。由于数据集各个特征值的区间范围和数据纲量不同,为了避免因数据差异过大对预测结果产生干扰,影响模型性能,本文选择将数据归一到[0,1],采用的归一化公式如下式:
(1)
其中,X'∈[0,1]表示数据归一化后的结果,X表示数据原始值,和分别表示X所在数据列中的最小值和最大值。
4.数据缩减。经过上述一系列处理后,原数据集还剩下共43878条数据,其中守约样本39730条,违约样本4148条,守约样本与违约样本比例为9.58 :1。本文按照与原始数据结构分布接近的9:1选取比例进行分层随机抽样,得到包含5000条样本的实证数据集,其中包括4500条守约样本和500条违约样本。
(二) 基于主成分分析的指标筛选
在经过清洗后个人信用指标仍然还有50个,较多的特征数虽然注重了指标的多样化,但冗余指标会直接影响模型的评估效率和分类效果。因此使用主成分分析(Principal Component Analysis,PCA)方法进行指标筛选,一般情况下,在选择主成分时只需要所选择的主成分满足累加方差贡献值达到85%即可。
首先,将获得的新数据集中的所有数据特征汇总到一个1000*50维的特征矩阵里,并通过对这个特征矩阵进行计算得到一个50*50的特征相关矩阵:
R= (2)
其中rij代表各个特征之间的相关系数,计算公式如下式:
(3)
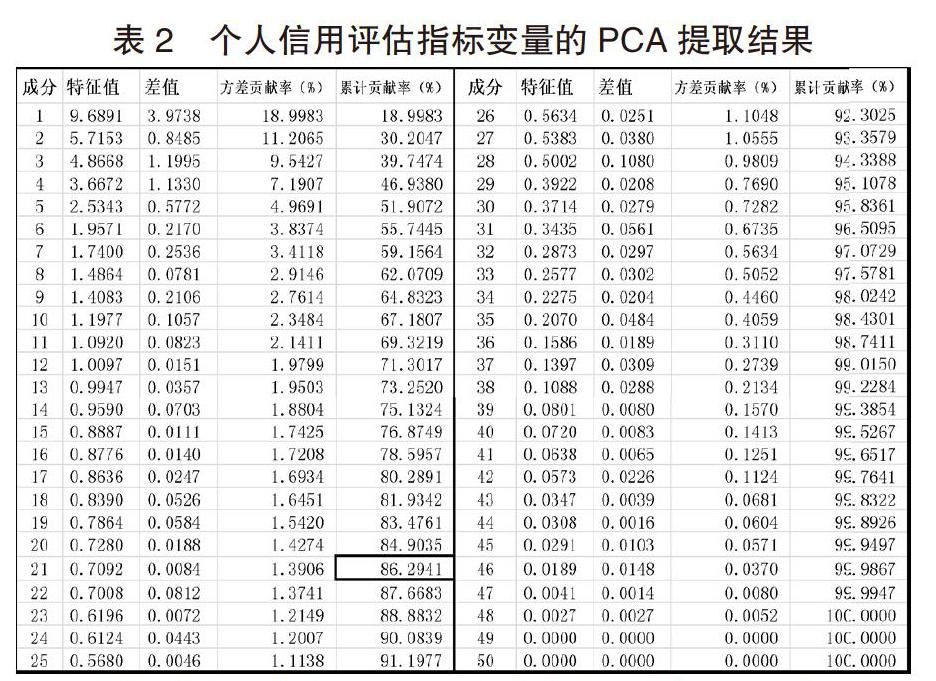
在得到相关系数矩阵后,在MATLAB中调用pcacov函数根据相关系数做主成分分析矩阵,计算出相关系数矩阵的特征值向量和主成分贡献率,最后将这些特征值向量和主成分贡献值降序排列,计算得到主成分的累计贡献值,得到的主成分提取结果如表2所示。
经过筛选,前21个变量累计方差贡献率已经超过了85%,对已得到的主成分列表进行反归一,由此得到经过主成分分析后被提取出的输入变量特征,最终确定的21个变量如表3:
(三)PSO-SVM建模分析
為了验证本文提出的筛选方法的有效性,采用PSO算法对SVM进行优化,建立PSO-SVM模型进行验证。PSO-SVM模型选择已被证明具有较强的非线性映射能力的RBF核函数,在参数的优化上,利用PSO对全局和个体的搜索能力来寻找最优的C和σ。本文选用模型的整体分类精度以及第一类误判率、第二类误判率来对模型的分类效果进行评价。
(四)实证结果
将处理后的Prosper数据按照7:3的比例划分为包含3500样本的训练数据和包含1500样本的测试数据。其中,训练样本中,守约客户(类别标签为“1”)样本3150条,违约客户(类别标签为“-1”)样本350条;测试样本中,守约客户样本1350条,违约客户样本150条。
PSO-SVM模型对测试样本分类结果如表5所示,测试样本数据量为1500,预测正确的样本有1394个,将守约客户判断正确的准确率为93.111%,将违约客户判断正确的准确率为91.333%。模型分类准确率结果汇总至表4。
评价指标 PSO-SVM
第一类误判率 93/1350 (6.889%)
第二类误判率 13/150 (8.667%)
总体分类精度 1394/1500 (92.933%)
从表4结果可见,采用主成分分析法筛选变量进行模型测试,第一类误判率6.889%;第二类误判率8.667%;模型整体分类准确率为92.933% (1394/1500) 。实验结果表明PCA能够提高SVM模型的整体预测精度,对降低模型的第一类误判率和第二类误判率都具有较明显的效果。
五、结论
在评估互联网金融个人信用风险时,评估指标的选取和模型构建应当考虑互联网金融的数据来源和数据特征。主成分分析法对于减少数据冗余,降低数据维度,保留原有指标内部结构关系方面具有明显的优点,在互联网金融信用风险评估的指标选择上具有较好的适用性。如果能有效地运用定量的科学的方法从数据中选择判别性好、冗余低的特征集,将为构建合理有效的信用风险评估体系提供重要的依据。这也将是今后学者们不断探索和深入研究的课题。
在前文的个人信用评估指标变量的PCA提取结果中可以看到,Porsper的评价指标中并没有国内金融机构在进行信用评估时普遍关注的一些指标,如性别、年龄、婚姻状况、教育背景等人口描述性特征。比起个人基本情况,Porsper平台更关注借款人的信用数据,以及与平台产品相关的信息包括产品类型、贷款利率、还款期限等。方差贡献率排在前几位的特征值是借款人在Prosper平台的信用评分、过去7年的违约次数、信用等级、信用卡信用总额以及每月贷款支付等。而国内金融机构普遍较为关注上述人口描述性特征,特别是对借款人履约能力有较大关联的家庭稳定情况和工作具体情况。由此可见国内外金融机构在指标选取时侧重点有较大差异,有研究者认为这种差异的产生主要是受到各国人文历史和传统文化的影响。这些人口描述性特征的判别性如何需要进一步的实证检验。
参考文献:
[1]朱良平.基于大数据的信用风险评分模型辨析[J].中国金融电脑,2016(3).
[2]Fritz S and Hosemann D.Restructuring the Credit Process:Behavior Scoring for Deutsche Bank' s German.Corporates [J].International Journal of Intelligent Systems in Accounting ,Finance &management ,2000.9 :9 -21 .
[3]Joos P ,Banhoof L,Ooghe H ,and Sierens N .Credit classification:A comparison of logit models and decision trees[ A].10th European Conference on Machine Learning ,Workshop notes:Application of machine learning and data mining in finance[ C].TU Chemnitz,Germany :1998 :59-70.54-56.
[4]Hand DJ and henley WE.Statistical Classification Methods in Consumer Credit Scoring :A Review[ J].Journal of the Royal Statistical Society ,1997,Series A 160(3):523-541 .
[5]肖曼君,欧缘媛,李颖.我国P2P 网络借贷信用风险影响因素研究——基于排序选择模型的实证分析[J].财经理论与实践(双月刊),2015,36(1):2-7.
基金项目:本文受到成都理工大学哲学社科基金项目“基于金融科技创新的金融风控模型的应用研究”(项目编号YJ2017-JX005)的资助。
(谢佳为成都理工大学管理科学学院硕士研究生;曾鸣为成都理工大学管理科学学院副教授)
猜你喜欢
辽宁经济(2017年6期)2017-07-12
贵州财经大学学报(2016年6期)2016-12-19
经济研究导刊(2016年28期)2016-12-14
当代经济(2016年26期)2016-06-15
新疆财经大学学报(2015年3期)2015-12-10
特区实践与理论(2014年5期)2014-07-24
