
基于Python的电影数据爬取与数据可视化分析研究
2019-12-23 09:28成文莹李秀敏
电脑知识与技术 2019年31期
关键词:可视化
成文莹 李秀敏

摘要:该文借助Python功能完备的标准库、强大的第三方库requests、BeautifulSoup以及正则表达式,编写程序快速实现中国票房网页及豆瓣电影TOP250数据的抓取,通过matplotlib图形库以图形化的方式直观地展示数据结果,并加以分析,得出相关结论。该文研究为培养学生数据处理能力和可视化分析能力奠定了基础。
关键词:数据爬取;Python;可视化
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2019)31-0008-03
1背景
随着大数据和人工智能时代的到来,人们在数据的价值上逐渐取得共识,而获得数据是数据挖掘与分析的首要工作。论文利用Python丰富的标准库,研究网络爬虫的原理并实现电影网络数据的获取,并将获得的数据进行可视化显示和数据分析。
Python语法简洁清晰,易学,可扩展性强,具有丰富的标准库和第三方库供程序员使用。Python爬虫工具包使用方便,对数据抓取提供了可能嘲。
2数据爬取与可视化方法分析
网络爬虫是一个从Web上自动下载网页的计算机程序。爬虫技术是一个可以连接数据和解析数据,并将这些数据进行分析并将分析结果利用图表进行展示的工具。Python具有丰富的网络爬虫模块,具有很强的可扩展性与可嵌人性。
可视化分析可以提高科研人员对数据隐藏信息的洞察力。可视化分析是一种综合利用可视化界面和分析理论来帮助用户解释复杂数据的技术。可视化是用户与数据交互的接口,表现形式通常有直方图、饼图、散点图等。
2.1数据采集
数据采集的执行过程分为:第一,分析网址信息找到网页页面并分析网页源代码结构;第二,根据网址抓取网页并将网页内容分离开来;第三,处理数据且将抓取后的数据写人到数据库中。上述三步重复执行直至数据采集结束。抓取网页内容,一般有两种方法,一种是使用python库,另外一种是使用正则表达式去提取相关内容。
2.2分析及解析网页
论文使用Python中的requests库进行数据采集。Beautiful-Soup是一个HTML/XML的解析器,来解析URL的文本信息。通过确定每个数据对应的元素及Class名称后,使用find,find_all,select等方法进行标签的定位,进行数据提取。
2.3正则表达式提取数据
使用正则表达式对豆瓣电影TOP250进行数据采集。正则表达式(re)可匹配、搜索、替代高级文本模式,并为其他的一些功能提供基础。正则表达式描述了字符与字符之间的某一种重复方式,是由字符以及特殊符号组成的,所以能按照某种已经设定好的模式和有类似特征的字符串集合进行匹配,依次读取每个需要爬取的字段名称和提取规则。
2.4数据整理
采用Python中的pandas库对采集到的数据进行必要的整理,采用mean、loc、sort_values、groupby、merge等方法进行数据的统计与处理。将爬取的数据组合成DataFrame表格格式。pandas的基本功能是对数据进行索引查找、过滤和函数应用,除此之外,还有数据汇总和统计等功能,是实际数据分析中应用最为广泛的模块。
2.5数据存储与可视化输出
爬虫获取的数据可以将数据存储为txt、xls、esv格式,也可存储在数据库中(包括MySQL关系数据库和MongoDB数据库)。论文数据存储为CSV格式,具有方便导人数据库的特点。除此之外,还可以存储成pdf格式的文件。然后,采用Python中的matplotlib库以散点图、饼状图、条形图等形式进行数据的可视化输出。
2.6数据结果分析
对数据清洗和预处理后的票房、评论文本进行描述性数据统计分析。
3电影数据爬取与分析
3.1提取数据
打开中国票房网页页面并分析网页源代码结构。分析代码过程中,可利用开发者工具确定每个数据对应的元素及Class名称。例如用语句soup.find_all('table',{id:'tbContent'1},找到表格,id名称为tbContent。下载并解析中国票房网页,提取想要的数据信息,通过BeautifulSoup库提取了电影名、电影类型、上映地点以及电影票房并且将每个数据用DataFrame放人对应列表中,见表1和表2,然后生成数据图,分析数据。name,types,place,boxoffices字段分别是电影名,电影类型,上映地点,票房。
3.2数据分析
从网页中提取数据后,将数据保存成csv文件。然后采用Python的统计方法对数据进行简单的统计和分析。
3.2.1统计各电影类型在中国电影市场的平均票房
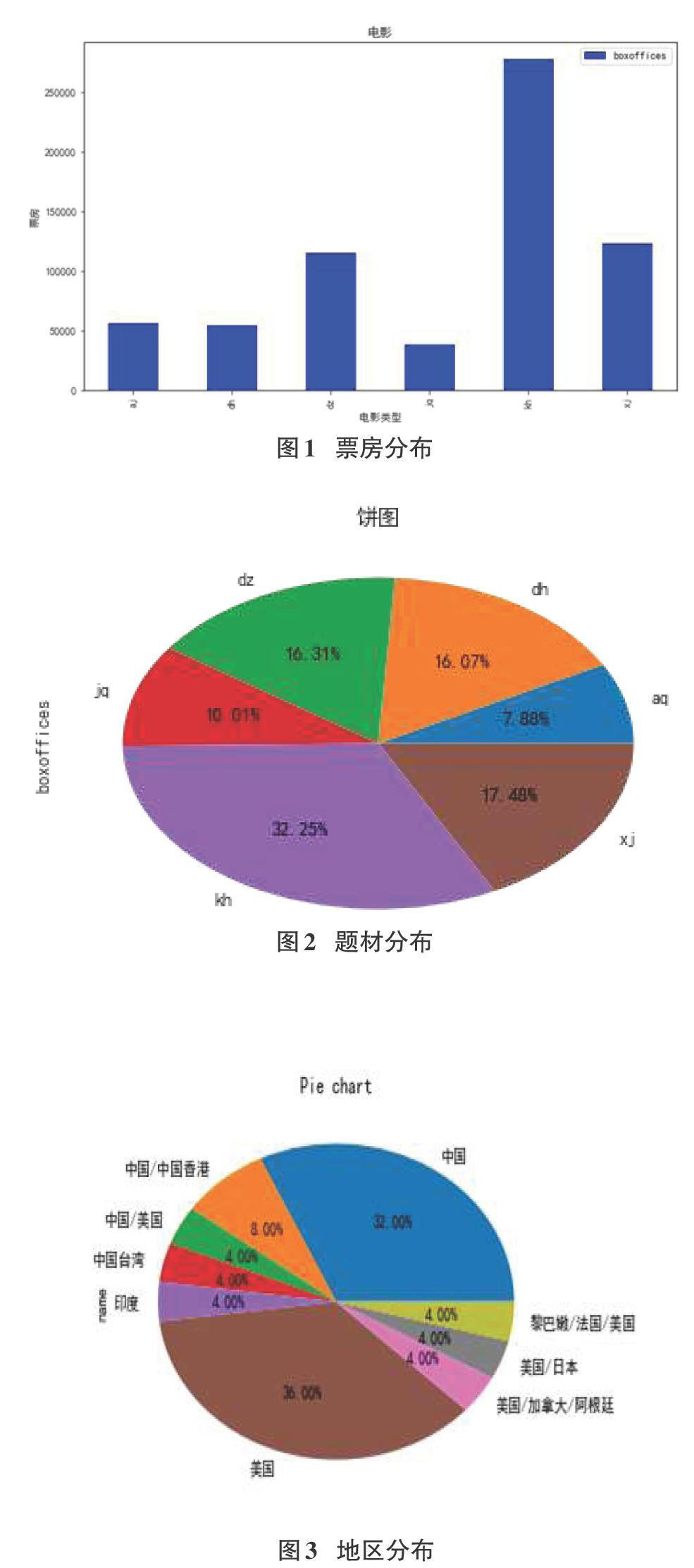
通过groupby方法按照类型分组,统计相应类型电影的总个数以及各个类型的电影票房的平均数和总数,并使用mat-plotlib.pyplot库作条形图和饼图,结果一目了然,见图3和图4。
如图1所示:横轴为电影类型,从左到右依次为爱情、动画、动作、剧情、科幻、喜剧,竖轴为票房。从图中我们不难看出,科幻类型的电影更受人们的青睐,喜剧和动作电影大众喜欢程度相差不大。
从图2中我们也可以清楚的看到某种类型的平均电影票数占总平均票数的比例。我们不难得出结论,科幻类型的电影的平均票房占了绝大部分,具体数值为32.25%。
3.2.2各地区在中国电影市场上映电影数量
图3可以分析出每个地区在中国电影市场的活跃度,从图3中可以看出美国在中国电影市场活跃度最高,中国紧迫其后。
3.2.3各个上映地区在中国电影市场上的平均电影票房数
同样,我们通过groupby按照地区分组,统计在中国各地区上映的电影平均票房。如图4所示:横轴为地区,竖轴为平均电影票房数量,从图4中我们可以分析出人们对各地区在中国电影市场的认可度。从圖4中我们可以直观地看到中国上映的电影的平均票房数量最多,这也与国人对国产电影的支持和国产电影类型和数量在这些年不断陕速发展有关。
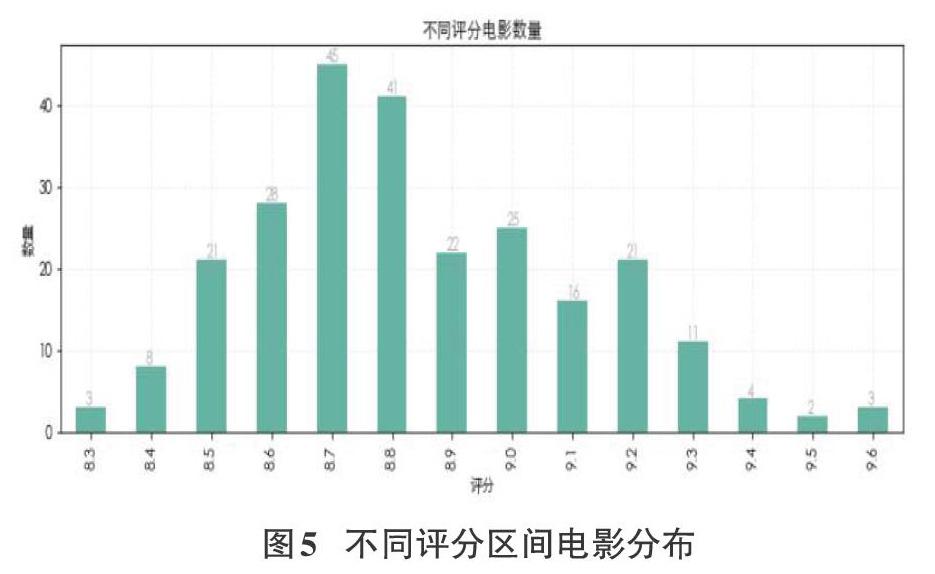
3.2.4不同评分电影的数量
下载并用正则表达式解析豆瓣TOP250网页,如图5所示:横轴为评分,竖轴为数量,该图可表示出豆瓣网前250名电影评分主要分布的范围,从图中可以看出,8.7评分的电影数量最多。评分主要分布中8.5到9.2之间。由此可见,大众对电影类型喜好虽然不同,但是有一定包容性。
4结束语
大数据时代下,人类社会的数据正以前所未有的速度增长。编写爬虫程序获取到的海量数据更为真实、全面,在信息繁荣的互联网时代更为行之有效。因此编写爬虫程序成为大数据时代信息收集的必备技能。
Python作为一门脚本语言,它灵活、易用、易学、适用场景多,实现程序快捷便利。课题主要采用Python,结合正则表达式、BeautifulSoup等丰富且强大的库,探讨构建模块化的web数据采集、Html解析及抓取链接数据的方法,深入研究爬虫的基本原理与数据挖掘的算法。通过爬虫获取的海量信息,我们可以对其进行进一步的分析:市场预测、文本分析、机器学习方法等。
对于卫生信息化方向的信息管理与信息系统的专业学生而言,掌握Python数据抓取的方法、熟悉搜索引擎和网络爬虫相关技术以及检索算法,为将来从事数据收集与处理的医疗信息化相关工作打下良好基础。
猜你喜欢
北京测绘(2022年6期)2022-08-01
云南化工(2021年8期)2021-12-21
北京测绘(2021年7期)2021-07-28
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
