
基于稀疏字典学习的立体图像质量评价
2019-12-21 09:03李素梅常永莉胡佳洁
天津大学学报(自然科学与工程技术版) 2019年1期
李素梅,常永莉,韩 旭,胡佳洁
基于稀疏字典学习的立体图像质量评价
李素梅,常永莉,韩 旭,胡佳洁
(天津大学电气自动化与信息工程学院,天津 300072)
本文提出了一种基于稀疏字典学习的双通道立体图像质量评价方法.其中,一个通道结合视觉注意机制得到初始立体显著图,用中央偏移和中心凹特性对其进行优化得到最终的显著图,然后,对其进行稀疏字典训练获得显著字典;另一个通道将参考立体图像对进行SIFT特征变换,然后,对其进行稀疏字典训练获得SIFT字典.在测试阶段,利用已训练字典对参考图像和失真图像进行稀疏编码获得稀疏系数,并定义稀疏系数相似度指标以衡量参考图像和失真图像之间的信息差异;最后将两个通道的质量分数进行加权得到立体图像质量的客观分数.实验在两个公开LIVE库上进行测试,实验结果表明,本文算法的评价结果与主观评分具有更好的一致性,更加符合人类视觉系统的感知.
立体图像质量评价;稀疏字典;视觉显著性;SIFT特征;中央偏移;中心凹
立体图像能够为观众带来身临其境的视觉体验,其产生、处理、传输、显示和质量评价已成为立体成像技术的热点研究问题.而立体成像技术的各个环节不可避免地会带来一定的噪声,致使观众产生视觉不舒适现象.设计一种系统且有效的立体图像质量客观评价方法用以说明立体成像技术各环节的正确性显得尤为重要.
截至目前,国内外学者已对立体图像质量的客观评价算法进行了较多研究,大致可以分为基于特征提取的传统方法[1]、基于稀疏字典学习的方法[2]和基于深度学习的方法[3-4]3个方面,本文主要研究基于稀疏字典学习的方法.稀疏编码来源于神经编码的感知信息是由少部分激活神经元的感知所得的思想[5-6],已成功应用于众多领域,目前也有部分文献利用稀疏字典学习的方法对立体图像质量进行评价,但是,该方面的研究还不够深入需要进一步探索.文献[7]提出了基于稀疏表示的立体图像质量客观评价方法,文中选取部分立体图像的左视点作为训练样本,得到不同频带的学习字典,利用获得的字典对测试图像进行稀疏表示获得立体图像质量分数.文献[8]分别将参考左图像和参考左视差图像作为训练数据,得到2个字典,分析图像稀疏性的结构和非结构特性得出失真立体图像的质量分数.文献[9]提出了一种全参考立体图像质量评价方法,模拟人眼多尺度特性学习多尺度字典,将图像的潜在结构表示为一组基本向量,根据相位和幅度差特征以及全局亮度特征得到立体图像的质量分数.以上基于稀疏字典学习的方法仅使用部分参考立体图像的左视点作为字典学习的训练数据,可能会导致字典学习的不完备(场景和信息特征的不完备).因此,考虑到场景的不完备以及考虑到立体图像是依据左右视图在大脑中融合所得,如果仅通过学习左视点图像信息可能会丢失一部分左视点所不具有的右视点图像信息,本文提出将所有场景的参考立体图像左右视图信息同时用于字典训练的方法.另外,文献[10-11]表明,人眼在观看图像时往往倾向于关注图像的某些重要区域,该区域称为显著性区域,图像显著性区域是人眼视觉的一个重要特性,已应用在很多方面,并取得了很好的结果.因此,结合视觉显著性本文提出了一种基于视觉显著性的字典训练方法.此外,考虑到目前所公开立体图像库中的左右视点图像,是经摄像机拍摄,然后对其进行校正所得,但是,现有的校正算法并不能达到百分之百的精确,会导致左右视点图像存在亮度、色度、视差(水平和垂直)以及相机拍摄基准不同等问题.因此,本文提出基于SIFT(scale-invariant feature transform)特征的字典训练方法.本文在训练阶段,首先将立体图像对分别进行显著性和SIFT特征提取2个通道的预处理,然后进行字典学习获得显著字典和SIFT字典.在测试阶段,一方面提取参考显著左右图像和失真显著左右图像,分成8×8不重叠的显著块作为输入数据,利用已训练的显著字典进行稀疏编码,分析计算稀疏系数相似度指标得到相应的失真立体图像的质量分数1.另一方面对参考立体图像对和失真立体图像对进行SIFT变换,利用已训练的SIFT字典进行稀疏编码,分析计算稀疏系数相似度指标得到相应的失真立体图像的质量分数2;最后将2个质量分数进行加权得到失真立体图像的客观质量分数.实验结果表明本文所提算法更加符合人眼视觉 特性.
1 基于稀疏表示的立体图像质量评价模型
图1为本文算法结构,算法主要包括基于视觉显著性和SIFT特征预处理的2个通道,两通道信息可以对测试立体图像的特征进行相互补偿.以下将从立体显著图的提取、SIFT特征的提取、稀疏编码以及质量评估4个方面展开分析.
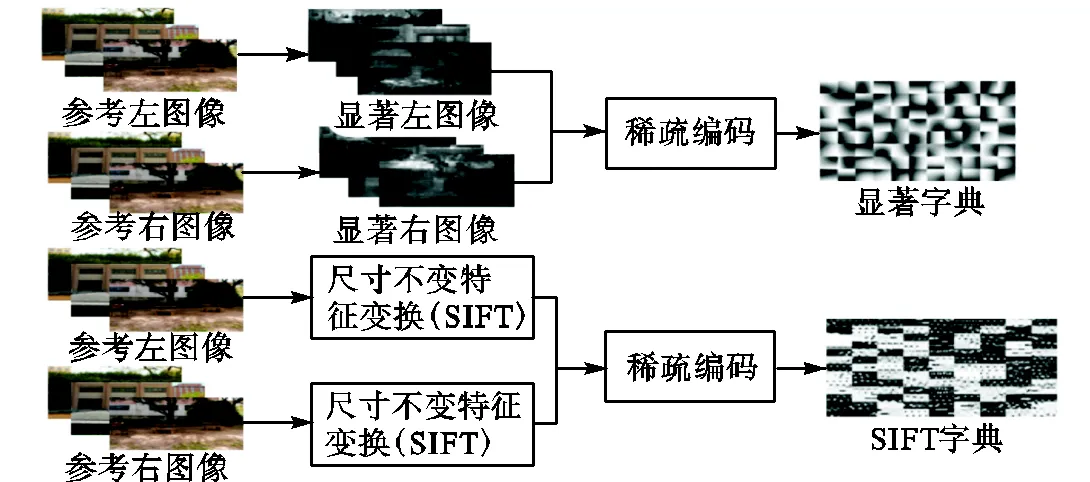
(a)训练阶段结构
(b)测试阶段结构
图1 本文算法结构
Fig.1 Structure chart of the proposed algorithm
1.1 立体显著图的提取
立体图像比平面图像具有更多的信息量,人眼不可能在短时间内匹配所有的特征边缘,大多数人只关注那些“重要区域”,然后提取这些区域中对象的边界,并最终匹配这些边界形成立体视觉[12].因此,本文模拟人眼视觉注意特性,提取立体图像显著特征来评估立体图像的质量.
立体显著图的提取过程如图2所示.文中采用绝对差值图来表示深度信息.首先,分别提取左右图像的亮度、色度和纹理对比度特征,结合绝对差值图获得初始显著图.然后,利用中央偏移和中心凹等特性对其进行优化分别获得显著左图像和显著右图像.
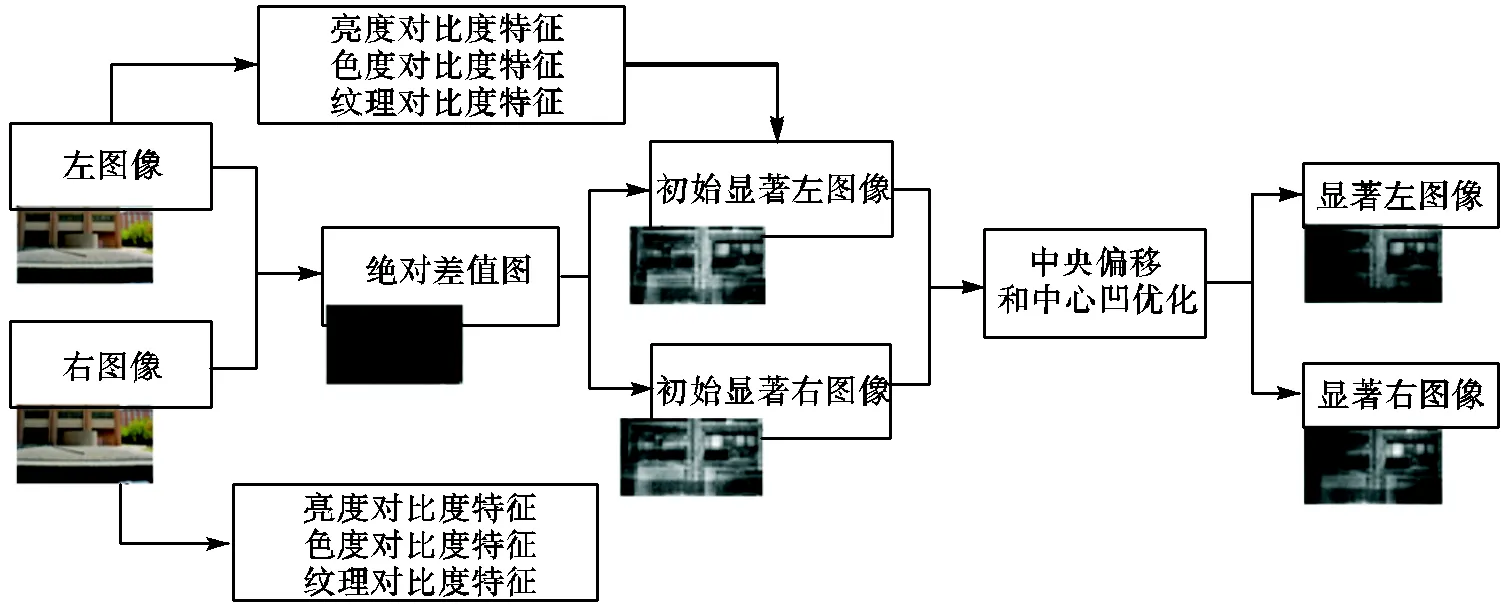
图2 立体显著图的提取过程
(1) 中央偏移.所谓中央偏移(center bias,CB)特性,是指人眼在观看图像时总是倾向于从图像的中心开始寻找视觉注视点,然后其注意力由中央向四周递减[13].本文中采用各向异性的高斯核函数来模拟注意力由中央向四周扩散的中央偏移(CB)因子.
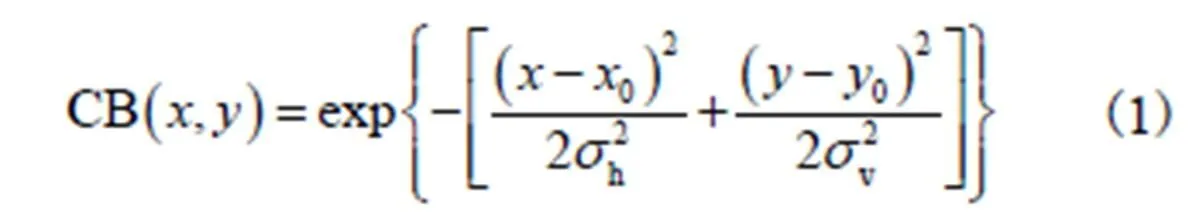
1.2 SIFT特征的提取
SIFT是一种检测局部特征的算法,该算法通过求解图中的特征点及其有关尺度和方向的描述子获得特征,并进行图像特征点匹配.以下将就尺度空间的构建、极值点的检测定位与方向参数的指定以及关键点描述子的生成等3部分内容对SIFT算法进行 分析.
(1)尺度空间的构建. 尺度空间理论的目的是模拟图像数据的多尺度特征,高斯核是实现尺度变换的线性核,根据式(4)构建图像尺度空间.
(2)极值点的检测定位与方向参数的指定. 为了寻找尺度空间的极值点,每一个采样点都要和它所有的相邻点进行比较,以确保在尺度空间和二维图像空间都检测到极值点(即关键点).得到检测尺度空间关键点后,需要精确定位关键点的位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点,以增强匹配稳定性.并且,利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备旋转不变性.
(3)关键点描述子的生成. 本文初始选择以特征点为中心取16×16的邻域作为采样窗口.为了测试该邻域大小是否适合本文所用立体图像数据库,本文还对邻域的大小进行了缩小和放大,分别对8×8和20×20的邻域大小进行了对比实验,实验结果表明,选择16×16的邻域作为采样窗口更适合于本文所用的立体图像数据库,因此,本文选择以特征点为中心取16×16的邻域作为采样窗口,将采样点与特征点的相对方向通过高斯加权后归入包含8个bin的方向直方图.每4×4的小块上计算8个方向的梯度直方图,形成一个种子点,对每个关键点使用4×4共16个种子点来描述,这样一个关键点就会获得4×4×8的128维的SIFT特征向量.
1.3 稀疏编码
1.3.1 字典学习
稀疏表示是用少量“基原子”的加权线性组合来近似表示一个输入的信号向量.在字典训练的过程中,很难同时求解字典和稀疏系数两个参数,但如果每次求解其中一个则是凸优化问题,如式(6)为固定字典求解稀疏系数的过程,式(7)为固定稀疏系数求解字典的过程.因此,字典训练时通常是固定其中一个来求解另一个,然后进行迭代求出合适的字典和稀疏系数.
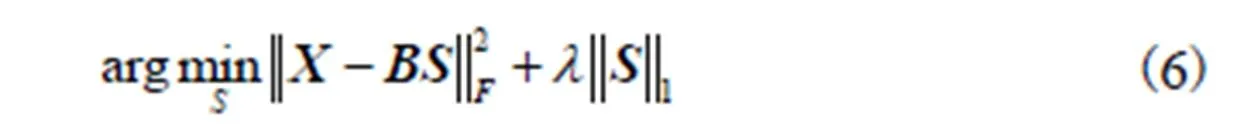
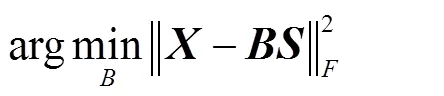
1.3.2 显著字典和SIFT字典
显著字典和SIFT字典的获得过程如图1(a)所示.在显著性通道,首先,提取参考左右视图的显著图,利用8×8重叠的窗口对立体显著图进行处理得到8×8的显著图像块.然后根据方差信息的大小选取每幅显著图像的前3,000个显著块,将其矢量化组成矩阵作为字典训练数据进行字典学习得到显著字典.本文显著字典的大小选择64×128.在SIFT特征提取通道,首先,对参考左右视图进行SIFT特征提取并将其矢量化组成矩阵作为字典训练数据进行字典学习得到SIFT字典.本文SIFT字典的大小选择128×1,024.
1.3.3 稀疏系数
图像的稀疏性会随着图像失真类型以及失真程度的不同而改变,因此将图像的稀疏性作为立体图像质量评价的基础,如图1(b)所示测试阶段结构.将参考立体图像对和失真立体图像对分别送入显著性和SIFT特征提取两个通道进行预处理,然后利用已得到的相应字典进行稀疏编码获得参考立体图像对和失真立体图像对的稀疏系数矩阵.
1.4 立体图像质量评估
通过对显著性通道和SIFT特征提取两个通道的质量分数进行加权获得测试立体图像的客观质量分数,其具体求解步骤如下.
步骤2显著性通道的测试左视图质量由式(8)求得

其中
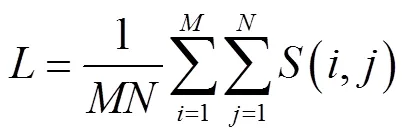
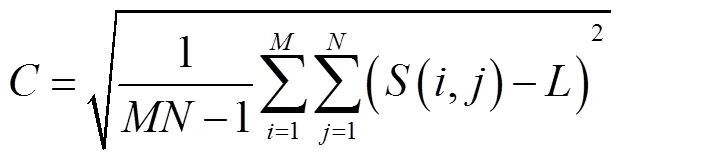
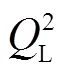
步骤4人眼视觉处理系统中左右图像对所融合立体图像的贡献有一定差别,因此本文利用式(12)对左右视图质量占比进行加权.
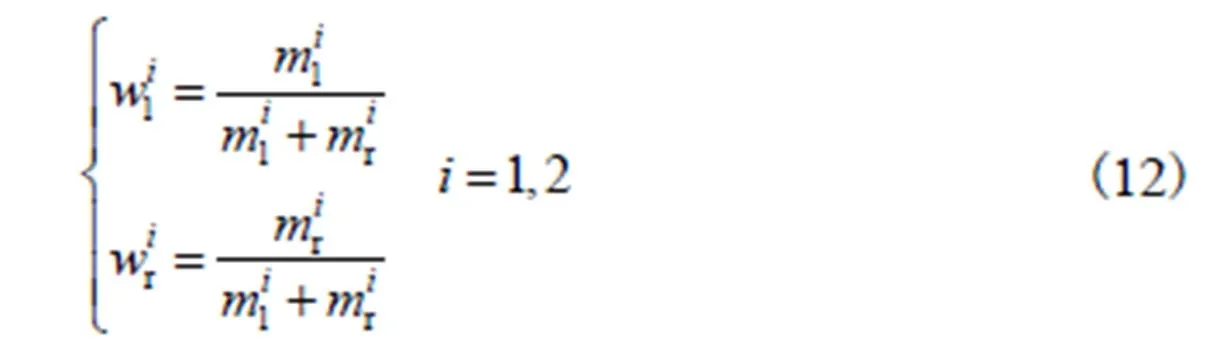


2.1 实验数据和性能指标
文中实验数据采用2个公开的LIVE数据库.LIVEⅠ数据库包含365幅对称失真立体图像对和20幅原始立体图像对,有5种失真类型,分别为JPEG、JP2K、Gblur、WN和FF.LIVEⅡ数据库包含对称和非对称失真立体图像对共360幅,LIVEⅡ数据库中包含原始立体图像对8幅,失真类型包括JPEG、JP2K、Gblur、WN和FF 5种.实验使用PLCC (pearson linear correlation coefficient)和SROCC (spearman rank order correlation coeffcient)2个指标来评价所提出模型的性能.PLCC和SROCC的值越接近1,说明客观评价方法与主观评价方法的相关性越好.同时,本文中也给出了本文算法的时间效率.
2.2 性能分析
表1给出了本文方法与文献[1,8-9]算法之间的结果比较,加粗数据为所有数据中最好的结果.从表1中可以看出本文算法在LIVEⅠ数据库上SROCC为0.938,3,PLCC为0.942,9;在LIVEⅡ数据库上SROCC为0.903,6,PLCC为0.911,6.在LIVEⅠ和LIVEⅡ数据库上,两个指标数值均高于文献[1]、文献[8]和[9]的结果.本文采用基于稀疏字典学习的方法而文献[1]采用基于特征提取的传统方法,由于传统方法需人为选取特征,其有效性不定,而稀疏字典自动提取重要特征,所以本文算法较好.文献[8]利用了参考左图像的视差图进行字典训练,目前没有很好的立体匹配算法来提取视差图,导致其算法总体效果并不理想.本文选择数据库中所有立体图像对进行字典学习,保证训练字典的完备性;而文献[9]选取数据库中部分场景的参考左图像作为字典训练的数据,导致训练字典的不完备性,其算法在LIVEⅡ数据库的效果更差.基于以上分析可知,本文基于视觉显著性的字典训练方法更加符合人眼视觉特性;基于SIFT特征的字典训练方法可以很好地解决左右视图之间亮度、色度及相机基准不同的问题;所采用的双通道方案实现了信息特征的相互补偿.
表1 不同评价方法的总体性能比较
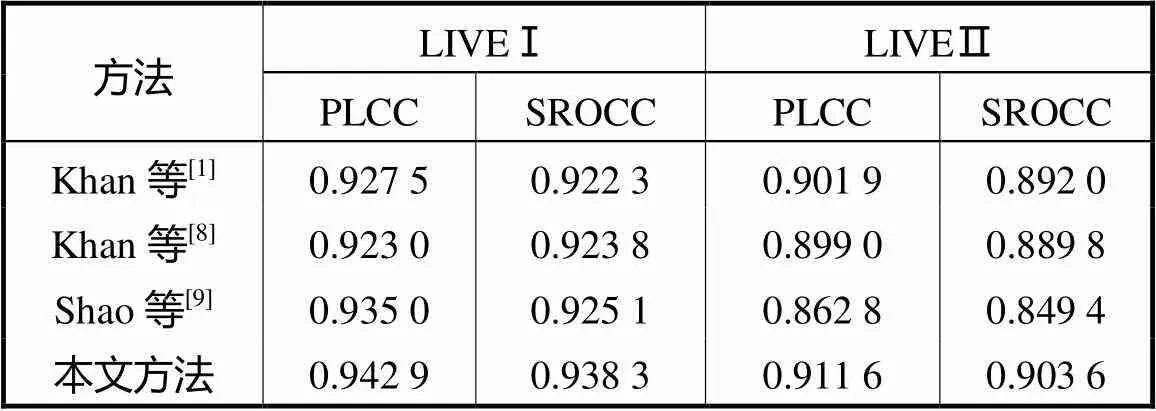
Tab.1 The overall performance comparison of different evaluation methods
表2和表3是本文算法和文献[8]针对不同失真类型所得不同指标的数据结果.根据表2和表3中的数据可以看出,LIVEⅠ数据库中,对于JP2K、JPEG两种失真类型,本文算法对JP2K失真类型的PLCC和SROCC分别为0.939,9和0.903,5;文献[8]对JP2K失真类型的PLCC和SROCC分别为0.941,5和0.906,7.本文算法对JPEG失真类型的PLCC和SROCC分别为0.732,5和0.663,1;文献[8]对JPEG失真类型的PLCC和SROCC分别为0.744,4和0.696,3;针对JP2K和JPEG这两种失真类型的立体图像,本文算法略差于文献[8].但是,对于WN、Gblur和FF这3种失真类型立体图像的质量评价,本文算法比文献[8]好.LIVEⅡ数据库中,对于WN、JPEG 2种失真类型,本文算法WN失真类型的PLCC和SROCC分别为0.922,5和0.925,7,文献[8]WN失真类型的PLCC和SROCC分别为0.927,7和0.922,8;比较而言,本文算法PLCC指标略低于文献[8],但SROCC指标比文献[8]高,说明本文算法对于WN失真类型的立体图像评价性能并不低于文献[8].本文算法JPEG失真类型的PLCC和SROCC分别为0.778,8和0.732,9,文献[8]JPEG失真类型的PLCC和SROCC分别为0.797,8和0.773,5.针对JPEG失真类型,本文算法性能较文献[8]略差,但差异不大.分析可知,在LIVEⅠ数据库上,文献[8]更适合于评价JP2K、JPEG两种失真类型,本文算法比较适合于评价WN、Gblur和FF这3种失真的立体图像质量;而评价JP2K、JPEG 2种失真类型的立体图像效果略差一点.在LIVEⅡ数据库上,文献[8]更适合于评价JPEG失真类型.本文算法比较适合于评价WN、Gblur、JP2K和FF这4种失真的立体图像质量;而评价JPEG失真类型的立体图像效果略差一点.但从全部数据分析,本文算法的PLCC和SROCC均好于文献[8],实验结果表明本文所提方法具有更好的普适性,更符合人眼的主观视觉感受.
表2 LIVEⅠ数据库2种不同方法的性能比较
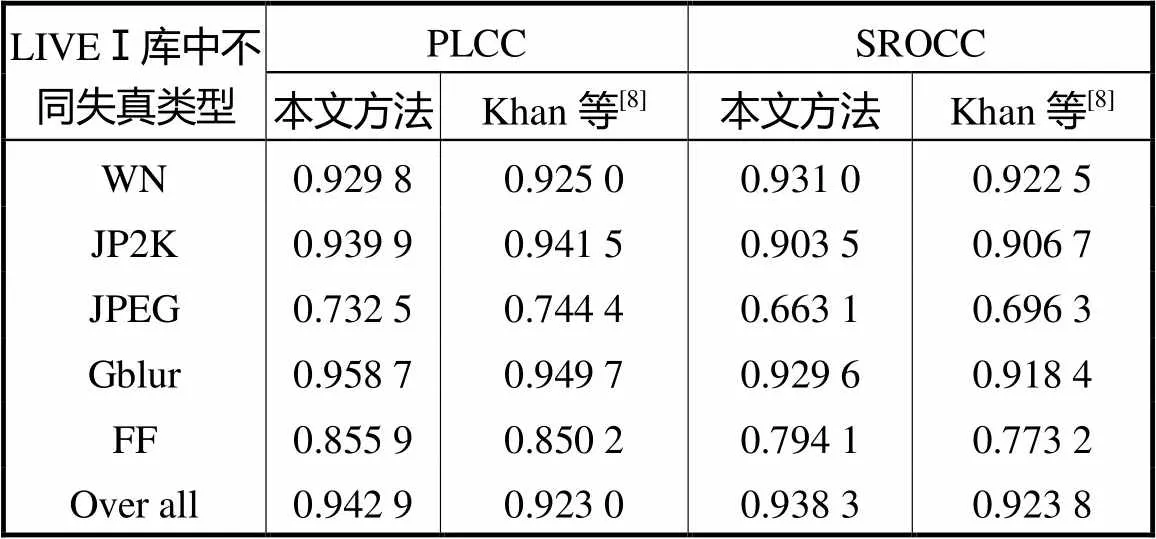
Tab.2 Performance comparison of two different methods in LIVEⅠ database
表3 LIVEⅡ数据库2种不同方法的性能比较
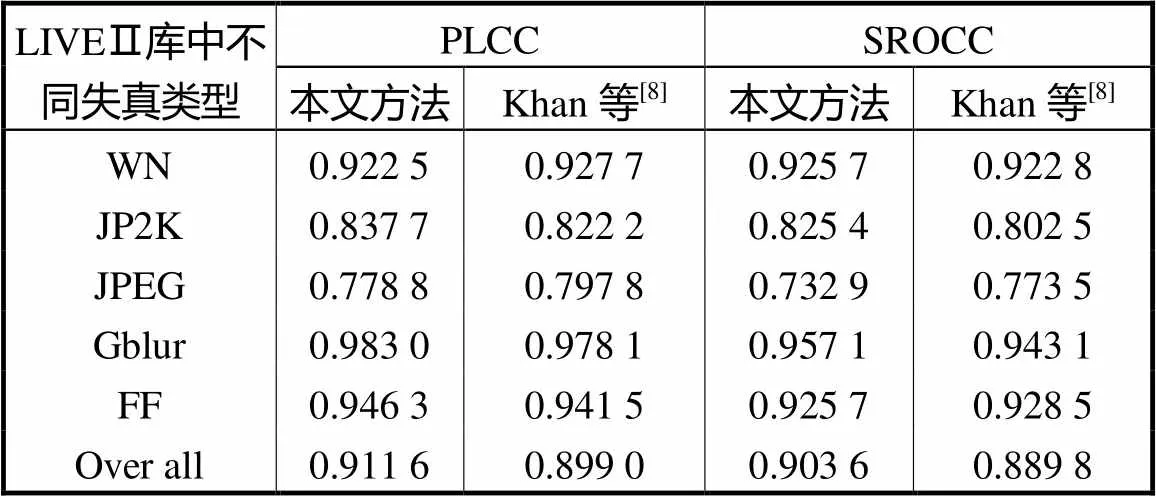
Tab.3 Performance comparison of two different methods in LIVEⅡ database
表4列出了本文算法测试所用时间复杂度,表中时间为一幅立体图像的测试时间.测试时间的长短与仿真时使用的硬件设备有关,本文使用的是Windows10 64位操作系统,3.10,GHz处理器,使用MATLABR2014b进行算法实验.从表4中可以看出,在已训练好的模型上进行测试所用时间较短,说明本文算法具有很好的实时性.
表4 本文算法的时间复杂度
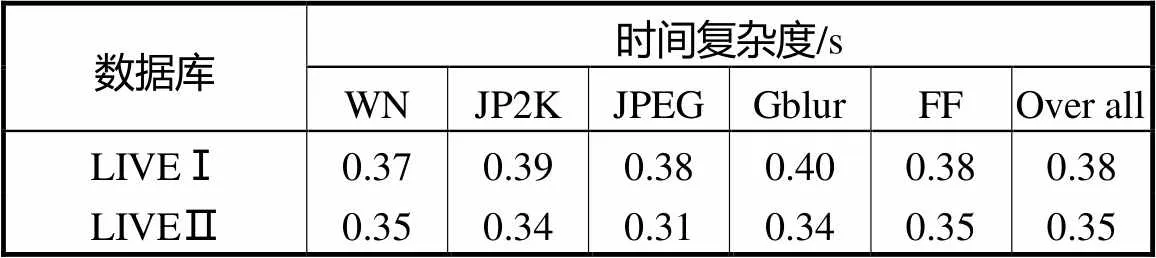
Tab.4 Time complexity of the algorithm in this paper
3 结 语
本文提出了一种基于稀疏字典学习的立体图像质量评价方法,包括基于视觉显著性的字典训练和基于SIFT特征的字典训练两个通道相结合的立体图像质量评价方法,最后将两个通道的质量进行加权得到最终的立体图像质量分数.为了保证字典训练数据的完备性,提出将原始参考立体图像对作为字典的训练数据,经过显著性和SIFT预处理训练得到显著字典和SIFT字典.将视觉显著性加入到立体图像质量评价中,更加符合人眼视觉特征.实验结果表明了本文算法的性能较好,与主观评价值相比较,模型预测结果较准确.
[1] Khan M S,Appina B,Channappayya S S,et al. Full-reference stereo image quality assessment using natural stereo scene statistics[J]. IEEE Signal Processing Letters,2015,22(11):1985-1989.
[2] Karimi M,Nejati M,Soroushmehr S M R,et al. Blind stereo quality assessment based on learned features from binocular combined images[J]. IEEE Transactions on Multimedia,2017,19(11):2475-2489.
[3] 王光华,李素梅,朱 丹,等. 极端学习机在立体图像质量客观评价中的应用[J]. 光电子·激光,2014,25(9):1837-1842.Wang Guanghua,Li Sumei,Zhu Dan,et al. Application of extreme learning machine in objective stereoscopic image quality assessment[J]. Journal of Optoelectronics·Laser,2014,25(9):1837-1842(in Chinese).
[4] Lü Y,Yu M,Jiang G,et al. No-reference stereoscopic image quality assessment using binocular self-similarity and deep neural network[J]. Signal Processing Image Communication,2016,47:346-357.
[5] Olshausen B A,Field D J. Sparse coding of sensory inputs[J]. Current Opinion in Neurobiology,2004,14(4):481-487.
[6] Reinagel P. How do visual neurons respond in the real world[J]. Current Opinion in Neurobiology,2001,11(4):437-442.
[7] 李柯蒙,邵 枫,蒋刚毅,等. 基于稀疏表示的立体图像客观质量评价方法[J]. 光电子·激光,2014,25(11):2227-2233. Li Kemeng,Shao Feng,Jiang Gangyi,et al. The method of evaluating the objective quality of stereoscopic images based on sparse representation[J]. Journal of Optoelectronics·Laser,2014,25(11):2227-2233(in Chinese).
[8] Khan M S,Channappayya S S. Sparsity based stereoscopic image quality assessment[C]//2016,Asilomar Conference on Signals,Systems and Computers. Pacific Grove,USA,2016:1858-1862.
[9] Shao F,Li K,Lin W,et al. Full-reference quality assessment of stereoscopic images by learning binocular receptive field properties[J]. IEEE Transactions on Image Processing,2015,24(10):2971-2983.
[10] Peng Q,Cheung Y M,You X,et al. A hybrid of local and global saliencies for detecting image salient region and appearance[J]. IEEE Transactions on Systems Man & Cybernetics Systems,2017,47(1):86-97.
[11] Cheng M M,Mitra N J,Huang X,et al. Global contrast based salient region detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(3):569-582.
[12] 王 飞. 基于上下文和背景的视觉显著性检测[D]. 大连:大连理工大学,2013.Wang Fei. Visual Saliency Detection Based on Context and Background[D]. Dalian:Dalian University of Technology,2013(in Chinese).
[13] Tseng P H,Carmi R,Cameron I G,et al. Quantifying center bias of observers in free viewing of dynamic natu-ral scenes[J]. Journal of Vision,2009,9(7):1-16.
[14] Efron B,Hastie T,Johnstone I,et al. Least angle regression[J]. The Annals of Statistics,2004,32(2):407-451.
[15] Schölkopf B,Platt J,Hofmann T. Efficient sparse coding algorithms[J]. Proc of Nips,2007,19:801-808.
[16] Censor Y A,Zenios S A. Parallel Optimization:Theory,Algorithms and Applications[M]. Oxford:Oxford University Press,1998.
Evaluation of Stereoscopic Image Quality Based on Sparse Dictionary Learning
Li Sumei,ChangYongli,Han Xu,Hu Jiajie
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
In this paper,a dual-channel quality assessment method of stereoscopic images using sparse representation was proposed. For one channel,the initial 3D salient map was obtained with visual attention mechanism,and the final salient map was generated through optimization by centre bias and the fovea property,then is used to train a salient dictionary. For another channel,a scale-invariant feature transform(SIFT) dictionary was trained by SIFT features extracted from reference images. At the testing stage,the trained dictionaries were used to get the sparse coefficient matrices for reference images and distorted images,and a sparse coefficient similarity index was defined to measure the information difference between them. Finally,the quality scores of the two channels were pooled to achieve the object score of the stereoscopic image. The performance of the proposed stereoscopic image quality evaluation metric was verified on two publicly available LIVE databases,and experimental results show that the proposed algorithm achieves high consistent alignment with subjective assessment,which satisfies the HVS better.
stereoscopic image quality evaluation;sparse dictionary;visual saliency;SIFT feature;center bias(CB);fovea
TN911.73
A
0493-2137(2019)01-0105-07
2018-02-07;
2018-04-09.
李素梅(1975— ),女,副教授,博士生导师,tjnklsm@163.com.
常永莉,cyl920611@163.com.
国家自然科学基金资助项目(61002028).
the National Natural Science Foundation of China(No.61002028).
10.11784/tdxbz201802017
(责任编辑:王晓燕)
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
黑龙江大学自然科学学报(2022年1期)2022-03-29
小哥白尼(趣味科学)(2020年3期)2020-07-27
小学阅读指南·低年级版(2019年11期)2019-07-01
小型微型计算机系统(2019年4期)2019-05-05
电子制作(2019年24期)2019-02-23
军营文化天地(2018年2期)2018-04-20
小天使·一年级语数英综合(2017年11期)2017-12-05
小学生时代·大嘴英语(2017年1期)2017-03-20
读者(2016年14期)2016-06-29
