
基于Spark的大学生校园信用大数据评价系统构建研究
2019-12-16 02:57王启源谷瑞军王聪林聪李林鹏李伟
电脑知识与技术 2019年30期
关键词:信用评价
王启源 谷瑞军 王聪 林聪 李林鹏 李伟
摘要:校园内共享单车被破坏和挥霍助学金的情况屡见不鲜,既不利于大学生自身的健康成长,也给社会造成了负面影响。基于大数据技术构建大学生信用档案具有十分重要的意义。另外,随着高校中一卡通的广泛使用以及各业务系统的数据整合,形成了包括消费数据、宿舍进出数据、图书借阅数据、考试成绩的大数据环境,也为开发设计大数据信用评价系统创造了条件。通过整合大学生生活中的各方面的数据,基于HDFS和大数据计算框架spark,采用B/S架构,构建了信用评价系统。通过在真实环境下仿真测试,验证了评价模型的有效性,为有关部门提供了决策参考。
关键词:Spark框架;信用评价;Docker容器;大数据系统
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2019)30-0066-03
随着互联网的快速发展和电子支付的兴起,诚信已逐渐成为社会关注的焦点。发达国家自20世纪80年代就兴起了信用管理的研究,其中的绝大多数都已经建立起了比较完善的社会信用管理体系,出现了提供征信数据库服务的专业公司。国内的很多高校在很多年前也开展了相关的研究工作,利用信息化技术开发了相应的大学生信用管理系统和信用评价系统。
本项目主要研究基于校园一卡通的学生信用管理系统的设计与实现,系统包括信用数据采集与管理、学生信用综合评价等模块。在实现过程中以校园网为支撑,以校园一卡通数据库为核心,通过整合教务处、学工处、财务处、后勤处、图书馆5个系统中与信用有关的数据,设计评价模型和开发评价系统,将计算出的信用向量值存储在学生信用数据库中。系统中的信用评价模块调用学生信用数据库中的数据完成对学生信用的综合评价,从而得到学生最终的信用向量值,给出学生的信用等级。
1相关工作
1.1相关研究
在高校学生信用方面,国内很多高校在多年前就已经进行了一系列研究,也开发了相应的大学生信用评价系统。例如,通过智能校园应用程序与学生一卡通系统进行绑定,对学生的消费情况进行了探讨,并提出无人超市、无人监考考场、加强监控系统和对学生进行诚信教育的设想。他们还提出建立以大数据为核心,以智能感知为联系点,以智能应用为基础,构建智能校园信息平台。另外,还存在此种方式:基于大数据,根据学生身份证号码创建唯一编号进行信息采集。将这些庞大的数据导入到分布式数据库的同时进行分布式计算。建立统一的评定细则,最后录入信用平台。最后,要建立一个更具可操作性、更能反映大学生诚信状况的大学生诚信评价体系,从而建立一个面向政府和社会的诚信信息查询系统。又如松江大学城学生信用管理系统,通过JAVA语言和MySQL数据库实现了系统,其功能包括对信用进行增删改查,达成了系统的基本需求。但该系统较为简单,仍存在着一些不足的地方,比如系统无法定时收集数据并自动分析,难以做到实时生成高校生的信用情况。
1.2相关技术
大数据集是无法在规定时间内使用传统软件工具捕获、管理和处理的数据集,是需要新的处理模式才能获得价值的信息工具。大数据需要更高的决策能力、发现能力和过程优化能力。大型数据具有四个主要特征:数据量大、速度快、数据类型多样和低价值密度。大规模信息技术的战略重要性不在于知道、保有超大规模的数据量,而在于对这些相关数据进行专门处理。如果把大数据比作一个行业,该行业的获利方式就在于提高数据的处理能力。通过一系列专业化的处理最终发掘出有价值的信息。如果利用技术的角度来看,大数据和云计算是紧密联系、相互协作的。大数据必须采用分布式的方法来处理海量数据,他能够时时收集信息,但數据的计算处理则依靠云计算等。
Apache Spark是一个开源类Hadoop MapReduce的计算框架,特用于处理海量规模数据集,计算能力强且速度快。Spark具有MapReduce的优点,但与MapReduce的相异点在于,Spark的中间输出结果可以存储在存储器中,因此不需要重复读写HDFS,因此sDark在机器学习和数据挖掘方面的表现能力更加突出。Spark采用分布式数据集,除了可以优化迭代工作量外,它还可以提供交互式请求。通过在HDFS上保存收集到的数据,之后放入Spark中,进行数据分析。
Spark结构在分布式计算中使用Master-Slave模型。Master作为管理节点,为集群中那些包含Master进程的节点,负责任务调度,并保证工作的正常执行。如果节点中包含Worker进程,则为Slave节点。Slave节点对得到的任务进行计算,并实时向管理节点反馈自身工作状态。Driver和Worker是Spark应用程序执行时极其重要、不可或缺的角色。Driver不断将Task分配下去后,会创建Executor来执行任务。在执行时,Task及其所需要的依赖文件和序列化后的jar被发送给Worker进程,同时Executor处理相应数据分区的任务。
2平台架构和设计
2.1平台架构
基于Java EE技术,以抽象工厂设计模式和MVC设计模式为指导思想,采用SSM框架进行设计。基于HDFS和大数据计算框架spark对业务数据进行分析。客户机配置要求低,PC机或瘦客户机均可。因为采用的是B/S架构,在任何网络连通的条件下,都可通过客户机以浏览器的形式进行信用系统的访问。方便用户随时随地进行信用查询,了解自己的信用情况。其架构如图2所示。
2.2主要模块
基于Spark的大学生校园信用大数据评价系统主要包括数据采集模块、数据分析模块以及信用展示与可视化模块。
1)数据采集:将保存在数据库中的数据运用sqoop上传到docker容器中的HDFS集群上。
2)数据分析:容器中自动调用spark对采集到的数据进行分析。
3)信用展示与可视化:分析完的数据会被再度保存到数据库中,并在前端页面展示并生成折线图、柱状图、饼图等可视化信息。
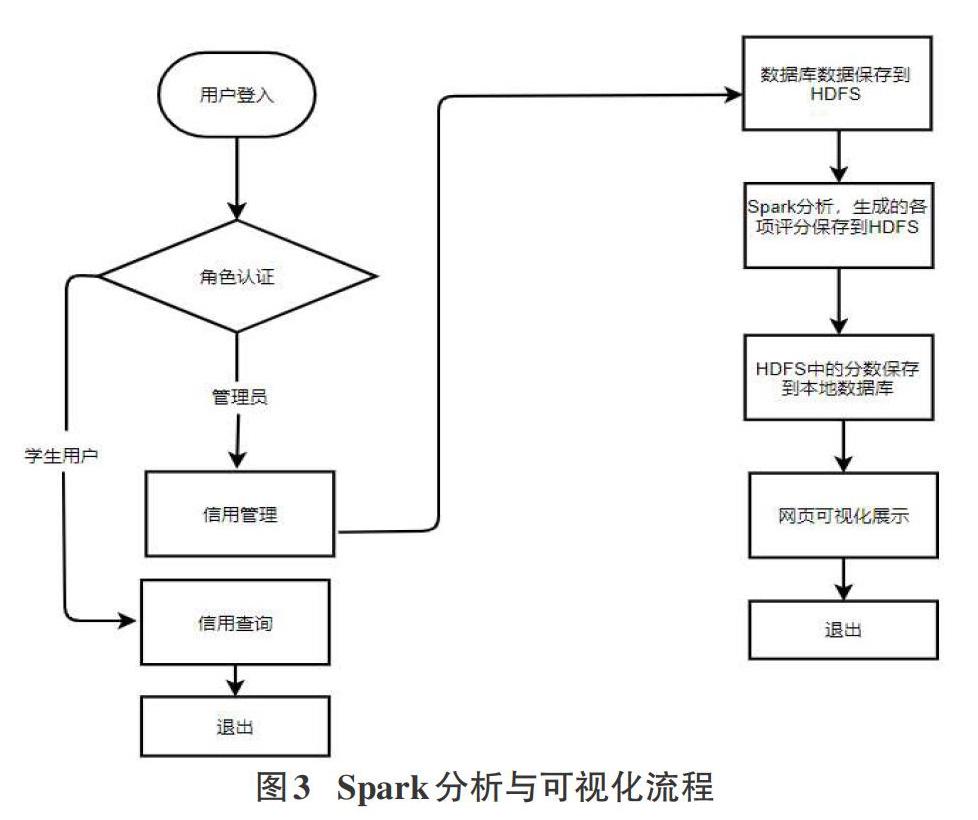
下面介绍spark分析与可视化流程的设计,如图3所示。
用户登录web应用后,对用户的角色信息进行验证,之后进人对应的功能界面。管理员用户可以查看详细数据,并且可以进行数据采集与分析。后台自动进行,等待运行完毕后可以查看最终评分结果,包括各个单项的分数与最后的总评。
3系统部署与运行
下面以一个学院、20个班的规模为例,选取相应的软硬件资源来搭建环境,并作了测试和最终评价。
3.1平台部署
3.1.1基础环境
首先选择两台19英寸2U机架服务器,一台为应用服务器,一台为支撑服务器。应用服务器配置为:12核心CPU、64G内存、2块2T硬盘;支撑服务器配置为:24核CPU、256G内存、4块4T硬盘,两台服务器间通过万兆网卡互联。然后分别安装cen-tos7系统。
3.1.2安装D0cker环境
1)安装Docker
sudo yum install docker
21开启Docker,并设置开机自启
sudo systemctl start docker
sudo systemctl enable docker
3)测试安装是否成功,如果打印出的Hello等字样时,表示Docker已正确安装。
docker rtln hello-world
3.1.3容器内应用部署
为保证数据采集与分析的自动运行,须在容器内安装Ha-doop,Sqoop以及Spark,并编写相应的脚本文件确保能够自动调用并执行。
3.1.4应用部署
分别安装mysq15.7数据库、JDK8、和tomcat7服务器,将ja_vaweb应用打成War包后部署到服务器上,并启动服务器,测试能否正常访问。
3.2平台测试
图4为平台管理员端主界面。
进人数据查看项,可查看学生具体数据,可对其进行修改,如图5所示。
进人信用查看菜单下,点击信用汇总中的采集分析,可自动对本地数据库中的数据进行采集,并利用Spark进行分析,一键汇总会将得到的分数保存到本地,如图6所示。
信用可视化菜单下可以根据需求生成饼图、柱状图或折线图查看学生的信用分布情况,如图7。
学生用戶进入系统界面,可查看自己的总信用评价,以及入学以来各个时期的折线图,如图8所示。
4结束语
在当今社会,信用信息对个人的生活、工作都有着重大影响,需要加强对学生的信用管理,建立完备的信用监督体系,从而提高学生的诚信意识。通过在Linux系统上安装Docker软件,并在容器内部署Hadoop、Spark,可以快速、省时地将传统关系型数据库数据上传其中并快速分析,最终将结果保存至本地以供查询。另外,采用Javaweb技术使最终结果呈现在浏览器页面上,方便了高校学生随时随地查阅自己的信用情况。
猜你喜欢
现代管理科学(2017年4期)2017-04-06
商场现代化(2016年26期)2016-11-21
商场现代化(2016年24期)2016-11-02
中国经贸导刊(2015年5期)2015-03-31
