
基于消息中间件的调用链跟踪设计与实现
2019-12-16 02:57唐文
电脑知识与技术 2019年30期
唐文


摘要:分布式系统对高性能、高可用性、可伸缩要求越来越高,消息中间件是重要的技术之一,解决应用解耦、异步消息、流量削峰等问题。消息中间件松耦合交互方式在系统整体实现层面会呈现出复杂度,多应用间业务流无法跟踪、无法定位问题,需要耗费大量的时间来查找定位问题。该文实现一种基于消息中间件的调用链跟踪方法,可视化业务流完整的调用链,同时统计分析各阶段耗时,而且方法对应用程序实现“零侵入”。
关键词:分布式系统;消息中间件;调用链跟踪;服务跟踪
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)30-0054-02
1概述
分布式系统中应用部署在不同节点中,不同的应用之间通过传递消息来激活对方的事件触发相应的操作,发送者将消息发布到主题中,消费者通过订阅主题来获取关注的消息,消息中间件能在不同平台之间通信,屏蔽掉各种平台及协议之间的特性,实现应用程序之间的协同。发布/订阅者不相互感知,由此带来一些问题:消息在应用程序之间传递丢失,无法快速定位出丢失消息的应用嘲;业务流过程中如果出现性能问题,无法快速确定哪个应用耗时长。以上问题往往需要将各个应用日志打开,耗费大量人力才能找出问题。
分布式消息跟踪业界已有成熟的实现方案,代表是GoogleDapper,其实现原理是:对于每次用户发起的请求,使用一個TRACE ID作为标识,每个服务组件使用SPAN ID作为标识,服务组件对于到达的请求记录跟踪日志,跟踪日志中包含TRACE,ID、SPAN ID和PARENT,ID(消息发送上游组件的SPAN加),组件通过PARENT ID找到上游组件,用户发起的请求涉及的所有组件调用关系可视出来。Dapper已有实现主要在远程过程调用(RPC)场景,对应用开发者未完全实现“零侵入”嘲。
2设计实现
2.1方案
消息中间件(MOM)采用发布/订阅模式,生产者将消息发送到主题中,中间件将主题中消息发送给订阅者,将Dapper的TRACE,ID、SPAN,ID和PARENT ID在发布订阅消息中传递,应用将ID持久化到日志中,通过日志则可分析出调用链。
如图1所示,业务流由APPl发起消息,消息APP2和APP3订阅处理,APP2处理之后发布新消息,新消息APP4订阅处理,一次完整的业务流经过APP1、APP2、APP3、APP4和中间件5个组件,参照Dapper原理过程如下:
1)APP1业务流发起来,生成一个Traceid假若为1,Parentid等于自身Moduleid为1,两个id携带在发布的消息中,同时id持久化到日志中;
2)APP2订阅到消息,首先将接收到消息的Traceid=1、Parentid=1持久化到日志中,消息处理完成后生成新消息,新消息Traceid继承已处理消息的Traceid为1,Parentid等于自身Moduleid为2;
3)APP4订阅到消息,将接收到消息的Traceid=1、Parentid=2持久化到日志中;
41 APP3订阅到消息,将接收到消息的Traceid=1、Parentid=2持久化到日志中。
步骤2中APP2发布新消息继承Traceid对应用程序“零侵人”原理在消息处理进程/线程上下文未改变。日志文件命名与Moduleid一致,通过日志文件中的Traceid、Parentid则可以将业务流调用链识别出来。APP发送/接收端记录日志信息,同样中间件接收,发送端也记录日志信息,日志信息加上时间戳,不仅是调用链,业务流完整耗时、分段耗时、应用耗时占比、热点应用都可识别出来,帮助运维者管理和决策。
方案实现存在以下几个问题需要考虑:
1)Traceid和Moduleid确保系统全局唯一,需要有一个ID生成策略;
2)调用链跟踪影响系统正常运行,涉及组件众多,如何动态开关功能;
3)调用链生成大量的日志需要机器分析,日志规格化便于机器分析。
2.2ID生成策略
Traceid代表一次业务流,不能出现两个一样的Traceid,使用时间戳是一个很好的办法,Linux时间戳精确到微妙/纳秒,如果在APP端生成Traceid,同一个时间精度点上可能小概率出现两个APP生成相同的Traceid。中间件为单线程处理,单次处理耗时小于一个时间戳精度不会发生,因此在中间件中生成更合理,Traceid规则如下:
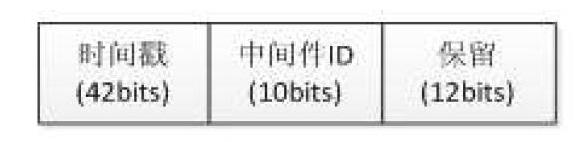
考虑到中间件是多实例多进程,Traceid中加人中间件ID。由于0号Traceid在系统中中约定为不存在ID号,需要保证生成的Traceid不为0,因此将最后12bit最后一位设置为1。
Moduleid需要考虑应用进程在多实例的情况下也能够识别,Moduleid组成格式-。Moduleid采用字符串构成,使用Pid来区分业务进程多实例的情况。考虑到服务链跟踪需要做到应用“零侵入”,新增功能不需要修改代码,Moduleid不能够由业务来进行设置,应用使用中间件时注册了Moduleid,因此可由中间件直接将Moduleid加入到消息通告中,应用无需感知。
2.3功能开关
服务链跟踪功能默认开启,一个是影响正常业务性能,一个是产生大量log,两个都浪费系统资源,因此需要支持动态开关。一次业务流涉及的所有应用很难提前知晓,发起应用则很容易知道,在业务流发起应用打开功能更合理的,同时能支持指定消息主题打开。
业务流发起应用打开功能后,中间件以及所有的下游应用如何识别。发起应用可通过特定命令告诉中间件该次消息需要使用调用链跟踪,中间件识别到则生成一个新的Traceid,并在消息通告中携带上Traceid和Parentid,下流应用接收到携带ID的消息则认为功能开启,这样链式传递将所有涉及的应用功能开启。实现上将Traceid=O作为功能开启,这也是上小节为什么将0号视为不存在的Traceid。业务流执行完成功能同时关闭,因此功能关闭不需要额外处理。
2.4日志分析
为支持机器分析日志,日志首先需要支持规格化,XML/JSON是常用的规格化方式,嵌入式系统中资源受限使用最简单的规格化方式,在日志将增加标签。单条日志包含的信息如下:其中:
Traceid标识本条日志属于哪条跟踪链;CMod标识本条日志属于哪个应用;
LMod标识本条日志Parentid是哪个应用;
Key标识触发本次消息的主题;
Act标识触发本次消息的增/删/改行为。
跟踪日志具有固定的格式,因此可以使用正则表达式从中分析出所有信息,通过CMod和LMod找出调用父子关系,构造出调用链树形图。另外,耗时可以是日志生成的时间戳中分析获取。
3测试
下图2展示了系统中一次业务流调用链图,上下流应用调用关系、消息传递的主题Key、业务流完整耗时、各阶段耗时及占比全部可显示出来,达到了系统设计预期。
4结论
本文基于Google Dapper原理实现了基于消息中间的调用链跟踪,解决了分布式系统中应用之间调用关系难于跟踪定位问题,对于业务流时延性能分析能够显著的帮助,优化只需要关注各个应用,完整视图由机器来自动化生产,节省人力资源投入。本文实现还存在下一步优化点:1)应用消息处理更改上下文,如采用异步处理方式;2)分布式节点中时间戳存在不一致,耗时分析增加这部分考虑。
