
基于模糊评价的VDT系统搜索策略绩效形成机理研究*
2019-12-12 03:46罗俊浩王泰鑫段琼华
中国安全生产科学技术 2019年11期
罗俊浩,廖 斌,王泰鑫,魏 欣,段琼华
(四川师范大学 商学院,四川 成都 610101 )
0 引言
随着信息化的深入,信息系统(Information System,IS)在工业生产、公共事务管理,教育服务等领域被广泛应用。人与信息系统的交互主要通过视觉显示终端(Visual Display Terminal,VDT)完成。因此,VDT作业已经成为当前重要的劳动模式[1]。通过VDT界面对字符、图像等数据信息进行视觉搜索作业越来越普遍。如果视觉搜索区域内的目标按照一定的结构排列则称之为结构性搜索区域[2],比如名单表、菜单表等。作业者在结构性搜索区域内进行视觉搜索会严格采用系统搜索策略[3],使用系统搜索策略进行的搜索在本文中称之为系统搜索。系统搜索方式是搜索作业的一种重要形式,在化工、航空、核电站等控制室被广泛应用。如何提高VDT系统搜索作业绩效已经成为VDT作业管理者的重点工作内容。
目前学者们对视觉搜索过程中搜索策略与搜索绩效之间的关系研究较多:胡凤培等[4]发现采用导向式搜索策略能明显提高被试者的搜索速度;于瑞峰等[2]根据人眼的运动特征指出,为了提高作业绩效,作业者采用的搜索策略会随时间及环境的改变而发生变化;Tseng等[5]认为操作者为提高搜索绩效,其搜索策略在图片浏览任务下会根据刺激的密度和数量变化不断调整;Over等[6]研究表明,搜索策略的变化是一个伴随着扫视幅度逐渐变小而注视时间逐渐延长的过程。这些研究对持续搜索过程中的策略使用及变化进行了探讨,对具体搜索策略下的绩效形成机理并未作进一步的深入研究。只有明确了搜索绩效的形成机理,才能对搜索任务、界面布局等进行优化设计,进一步提高作业绩效。因此,非常有必要通过实验研究,运用模糊评价方法,分析被试者对搜索目标位置的主观偏好度和搜索绩效之间的关系,研究VDT系统搜索绩效的形成机理。为优化VDT系统搜索界面、提高搜索绩效提供理论依据。
1 方法
1.1 实验方法
1.1.1 任务设计
运用E-prime2.0设计实验模拟VDT系统搜索作业。目标刺激采用图片材料,均为bmp格式,像素为666 px×500 px。为了消除目标刺激材料的知名度和感情色彩差异对搜索作业绩效的干扰,刺激素材均选取最常见品牌的LOGO图标。所有刺激材料被整齐地铺陈于横纵比为4∶3的矩形界面上,并将此界面等分为九宫格,划分出“左下、下、右下、左、中、右、左上、上、右上”共9个目标位置方案,设为Ai(i=1,2,3,4,5,6,7,8,9)(方案序号见图1)。由此形成结构性搜索区域,研究系统搜索。任务过程采用“四阶段”模型,即要求被试者在呈现的搜索界面上扫视相关信息(搜索阶段),并找到指定的目标刺激(发现阶段),确认其真假后(判断阶段),通过输入设备做出反应(决策输出阶段)。

图1 刺激-反应设置Fig.1 Stimulus-response setting
实验设计了80个Trial,即:Stimulus,Interval,Probe反复交替呈现共80次,直至核心实验过程(Core Experimental Procedure,CEP)运行结束。实验程序运行方式如图2所示。

图2 实验程序Fig.2 Experimental procedure
首先,被试者在每个Trial中都会先接受到一个标准刺激(搜索目标提示);然后,根据该目标提示在随后呈现的搜索界面上找到该搜索目标;最后,使用柯蒂键盘上的数字小键盘中的“数字1~9”按键选择目标刺激所在的对应位置。“刺激-反应键”对应关系见图1,该设置保证了“刺激-反应”位置相容性原则。
每名被试者完成搜索实验后,还要求对目标位置方案Ai(i=1,2,3,4,5,6,7,8,9)的偏好进行主观评价。目标位置偏好指标设为Cj(j=1,2,3,4),分别为“C1快捷性”“C2准确性”“C3适应性”“C4习惯性”。被试者需要在4个主观偏好指标视角下,分别对9个位置的主观偏好进行评价。
1.1.2 被试者
为避免被试者认知水平差异等因素对实验结果的干扰,采用简单随机不重复抽样的方法,从本校经济管理类专业大一到大四的在读本科生范围内甄选被试者28人,其中男生14人,女生14人,平均年龄20.8岁。所有被试者均无生理和心理方面的既往病史,裸眼视力或矫正视力达1.0以上,色觉正常,均为右利手。
1.1.3 实验设备及主观评价量表
实验测试过程采用联想商用台式电脑,配备19英寸高清宽屏LED显示器,并将屏幕分辨率调至最高像素(1 440 px×900 px),输入设备均采用带数字小键盘的标准柯蒂键盘。
量表1:VDT(电脑、手机等)日常搜索行为频率主观评价量表,采用9标度,1~9表示平时搜索频率的逐步提高;量表2:目标位置偏好指标Cj重要度的主观评价量表,9标度,1~9表示重要度的逐步增加。量表3:目标位置偏好主观评价量表,按指标Cj分类,共4种。如果某位置符合某偏好指标,则在九宫格评价表的对应位置填“√”;反之,则填“×”;评价不确定时,填“?”。
1.1.4 实验程序
提前1 d告知被试者实验前需进行充分休息,保证实验过程精神饱满。正式实验前,被试者填写个人信息后进行练习实验。练习实验由正式实验程序中随机抽取的20个Trial构成。练习实验结束后,被试者需填写量表1和量表2。随后进入正式实验,每名被试者均须完成80个Trial的搜索测试。最后,被试者填写量表3,实验结束。E-prime软件自动记录每个Trial的正确率和反应时间。
1.1.5 数据采集与整理
搜索绩效指标为正确反应时,由E-prime软件自动采集获得;被试者主观评价数据由被试者手动填写获取。剔除异常数据后分类汇总。
1.2 模糊评价方法
1.2.1 Pythagorean模糊集
论域X中2个区间为[0,1]的隶属函数μp与vp,在0(μp(x))2+(vp(x))21下,若∀x∈X,μp(x)∈[0,1],vp(x)∈[0,1],则记P={[x,P(μp(x),(vp(x))]|x∈X}为Pythagorean模糊集,其中μp(x)和vp(x)分别为X的隶属度与非隶属度[7]。引入X的犹豫度令P=[μp(x),(vp(x),πp(x)]。
某组Pythagorean模糊数a=P(μa,va)的得分函数s(a)与精确函数h(a)分别为:
s(a)=(μa)2-(va)2
(1)
h(a)=(μa)2+(va)2
(2)
设a1=p(μa1,va1,πa1)和a2=p(μa2,va2,πa2)为2组Pythagorean模糊数,则a1与a2之间的欧氏距离为:
(3)
1.2.2 交互式多准则决策(TODIM)方法
TODIM方法是由GOMES等人基于前景理论提出的1种多属性决策方法,其主要思想是在前景理论价值函数的基础上,构建某个方案相对其余方案的优势度函数,并据此确定各方案的优劣排序[8]。TODIM方法相比前景理论具有明显的优势,无需事先确定决策参照点的信息,只对方案进行两两“优势-劣势”的感知优势度比较,即可解决具有清晰性属性值的多维度决策问题[9],而且还重点考虑了损失规避行为特征和决策者的参照依赖[10]。该方法原理如下:
1)方案Ai相对于方案At的优势度
(4)
其中:
(5)
式中:lij和ltj为实数;wjr为属性Cj相对于参考属性Cr的相对权重;wjr=wj/wr;wr=max{wj|j=1,2,…,n};θ为面对损失的衰减系数,且θ>0。
2)通过标准化最终的优势度矩阵,计算方案Ai的全局价值ξ(Ai),即:

(6)
根据ξ(Ai)的大小对方案进行排序,ξ(Ai)越大,方案Ai越优。
2 目标位置偏好主观评价
2.1 目标位置偏好指标权重
根据量表1,共采集到28名被试者的日常VDT搜索行为频率自评数据。频率均值为5.7,方差分析结果显示:28名被试者日常搜索频率无显著差异。表明本次实验被试者的日常VDT搜索均较为频繁。
根据量表2,共采集28名被试者对目标位置偏好指标Cj的评价数据。分别对C1,C2,C3,C4的主观评价值求和,归一化处理后得其权重。经计算,目标位置偏好指标Cj的权重W=(0.246,0.276,0.238,0.240)T。
2.2 基于模糊评价的目标位置偏好排序
根据量表3,28名被试者对目标位置Ai(i=1,2,3,4,5,6,7,8,9)在偏好指标Cj(j=1,2,3,4)下进行主观评判。根据评判结果,计算指标Cj(j=1,2,3,4)下Ai(i=1,2,3,4,5,6,7,8,9)的隶属度与非隶属度,最终由Pythagorean模糊集rij=P(μij,vij)(i=1,2,3,4,5,6,7,8,9;j=1,2,3,4)构成决策矩阵,见表1。

表1 Pythagorean模糊集决策矩阵Table 1 Pythagorean fuzzy set decision making matrix
根据决策矩阵,利用公式(1)~(5)计算单偏好指标下Ai的优势度对比矩阵φ1~φ4(分别对应C1~C4)。
A1A2A3A4A5A6A7A8A9

A1A2A3A4A5A6A7A8A9

A1A2A3A4A5A6A7A8A9
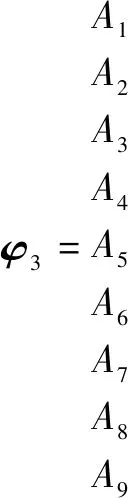
A1A2A3A4A5A6A7A8A9
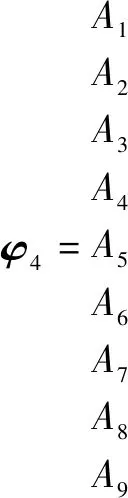
根据公式(7)将方案优势度对比矩阵φ1~φ4进行加总,得到总优势度对比矩阵δ。
(7)
A1A2A3A4A5A6A7A8A9

基于矩阵δ,利用公式(6)计算出9个目标位置偏好的最终评价得分,并按从高到低的顺序排序,见表2。

表2 目标位置偏好排序Table 2 Target location preference ranking
3 系统搜索策略绩效形成机理分析
统计28名被试者在目标位置Ai(i=1,2,3,4,5,6,7,8,9)的搜索正确反应时,对均值进行方差分析,结果见表3。

表3 方差分析Table 3 Variance analysis
由结果可知,在系统搜索策略下,9个搜索目标位置之间正确反应时绩效差异性极其显著。
对Ai(i=1,2,3,4,5,6,7,8,9)的位置偏好度和搜索绩效进行对比分析,结果见表4。

表4 目标位置偏好与绩效对比Table 4 Comparison of target location preference and performance
由表4可知:
1)搜索目标位置A5在位置偏好排序和绩效排序之间的差异非常大,位置偏好度很高(第2位),但是搜索绩效非常差(第8位);其他8个目标位置的偏好度排序和绩效排序比较接近。结合“注意返回抑制理论”和“周边多注视理论”分析可知:在本文实验中,当刺激间隔“Interval”自动消失后会立即呈现搜索界面;而被试者对中心区域具有较高的偏好,他们会首先注视中心区域,确认无目标刺激后转而扫视界面的周围区域;由于注意返回到刚才已注视过的中心区域会变慢或受到抑制,当目标刺激在中心区域而被试者作出错误判断时,中心区域的搜索绩效就会大幅度下降。因此,出现了中心区域位置偏好度高而搜索绩效却较低的现象,这与现有研究所提出的结论和观点极为相似[11-14]。
2)由于目标位置A5的情况比较特殊,因此,清除表4中A5的偏好度和绩效排序数据(假设不考虑目标位置A5的情况),对其他8个目标位置Ai的偏好度和搜索绩效进行重新排序,结果见表5。

表5 重新排序后的目标位置偏好与绩效对比Table 5 Reordering of the comparison of target location preference and performance
由表5可知,在不考虑中心区域A5的情况下,搜索目标位置偏好度排序与绩效排序之间的一致性高。说明在结构性搜索区域内采用系统搜索策略进行作业时,中心区域除外的其他区域的搜索绩效与作业者对搜索区域的主观偏好是高度一致的。但在实际的系统搜索作业中,目标位置A5一般是存在的。所以,在实际应用中应将结构性搜索区域划分为中心区域和周围区域分别进行分析。
3)从“C1快捷性”“C2准确性”“C3适应性”“C4习惯性”4个指标对目标位置的主观偏好进行模糊评价,对于解释系统搜索策略绩效的形成机理是有效的。
4)相关研究成果认为搜索绩效较优区域有左上方、正左方、左下方、正上方,较差区域则是右下方、正右方、右上方[15-16]。这与本研究结论相似,但导致这种搜索绩效差异性的根本原因不是搜索目标的位置属性,而是作业者对搜索目标位置主观偏好的差异。大多数人对目标位置的主观偏好趋于一致,但还存在偏好不一样的少部分人,前面提到的“左上方、正左方、左下方、正上方为较优区域;右下方、正右方、右上方为较差区域[15-16]”对于这少部分人是不适用的。
4 结论
1)基于系统搜索策略的VDT搜索作业绩效形成的根本原因是作业者对目标位置的主观偏好度,而不是搜索目标的位置属性。
2)在系统搜索策略下的VDT作业中,中心区域除外的其他区域的绩效与作业者的位置偏好具有高相关性,偏好度高的区域搜索绩效要显著优于偏好度低的区域;中心区域的偏好度高但绩效差。
3)在实际应用中,宜将结构性搜索区域划分为中心区域和周围区域分别研究。
猜你喜欢
中共云南省委党校学报(2022年1期)2022-04-26
名家名作(2021年4期)2021-05-12
小学生优秀作文(低年级)(2020年4期)2020-07-24
科普童话·学霸日记(2020年1期)2020-05-08
共产党员(辽宁)(2019年7期)2019-11-18
共产党员·上(2019年4期)2019-04-26
小天使·一年级语数英综合(2019年2期)2019-01-10
环球时报(2017-08-18)2017-08-18
北极光(2016年6期)2016-08-17
奥秘(2016年3期)2016-03-23
