
基于Rapideye数据的棉花特征光谱指数构建及类型识别
2019-12-11 08:41王利民姚保民高建孟季富华
中国农业信息 2019年5期
王利民,刘 佳,姚保民,高建孟,季富华
(中国农业科学院农业资源与农业区划研究所,北京100081)
0 引言
棉花是中国重要的经济作物之一,黄淮海流域、长江流域、新疆是我国三大产棉区[1-2],近年来棉花种植面积有下滑趋势[3],稳定棉花种植面积是我国农业生产的重要目标。快速、准确地监测中国棉花主产区的棉花种植情况,可为农业政策的制定提供可靠的依据,有利于维护农民的经济利益。遥感技术具有监测面积大、客观性强的特点,特别是近年来国内外中高分辨率卫星数据的不断增多,如Landsat-8[4]、Sentinel-2[5]、Worldview系列卫星[6]、Rapideye系列卫星[7-8],以及国内的资源系列卫星[9]、环境系列卫星[10]和高分系列卫星[11]等,利用遥感卫星技术正逐步成为农作物种植面积获取的重要途径[12-16]。
农作物种植面积遥感监测技术主要包括监督分类、非监督分类、决策树分类[17]、面向对象分类[18]等,其中监督分类方法又包括最大似然分类[19]、支持向量机[20]、随机森林[21]等,非监督分类又包括 ISOData[22]、Kmeans[23]方法等。这些技术方法在棉花遥感识别中都有不同程度的应用[24-28],并获得了较好的精度。如Jia等[24]利用HJ-1A/B CCD影像采用支持向量机的方法比较了单时相和多时相不同组合情况下提取小麦、棉花及其他几种地物的面积精度,在多时相组合情况下总体精度优于91%;Li等[29]利用CBERS01和HJ1B影像通过决策树分类模型提取山东省广饶县丁庄镇棉花信息,棉花面积的提取精度在90%以上。
为提高棉花识别精度,众多学者也开展了综合棉花遥感波段特征分类方法的研究。如曹卫彬等[30]对不同生育时期地物光谱曲线特征进行地面测量,并在TM影像光谱特征分析基础上,提出了棉花识别方法,棉花识别精度达到96.0%。为进一步简化识别步骤,便于监测业务的开展,加权指数的方法在农作物识别中也有应用。如王利民等[11]提出了一种冬小麦NDVI加权指数的分类方法,利用不同时期冬小麦与其他地物NDVI的差异,通过加权指数方式增强这一差异,从而实现河北安平冬小麦的快速识别,识别总体精度达94.4%;Song等[31]基于AMSR-E数据,提出了一种水稻种植指数,基于该指数对全国水稻的种植面积进行了提取,将提取结果与统计数据进行对比,两者相关系数达到0.94。
从已有研究报道来看,针对棉花遥感识别的光谱特征指数的研究尚不多见。而根据以往的研究,棉花波谱和同期播种的作物之间存在较大差异[30,32],因此可以考虑通过构建特征指数增强这种差异,进而实现棉花快速、准确识别和提取。已有研究的棉花波段主要集中在常见的红、绿、蓝、近红外波段,对红边棉花识别能力的研究相对较少,而红边波段已证明在部分作物(玉米、大豆、水稻等)分类中具有重要的作用[7,33]。针对以上问题,文章以包含红边波段的Rapideye卫星影像为数据源,以棉花为识别对象,通过地面样本数据的收集分析,结合红边波段构建相应的特征光谱植被指数,建立相应的处理技术流程,实现县级尺度棉花的高精度提取,为区域作物的监测提供了一个较为可靠的方法。
1 研究区概况
研究区包括河北省冀州市全部,以及周边的深州、辛集、宁晋等市辖区等部分区域。冀州市属河北省衡水市,地处华北平原腹地,位于 115°11′~115°41′E,37°19′~37°44′W,研究区总面积约为918 km2。
研究区位于华北平原北部,气候类型属于典型的温带大陆性季风气候,四季分明、雨热同期。全年平均气温12℃左右,最冷月份通常为1月,平均气温-4℃左右,最热月份通常为7月,平均气温27℃左右。全年降水量约为500 mm,且降水主要集中在夏季。研究区光热资源充足,年光照时数约为2 600 h,无霜期190 d,研究区地势平坦,土壤以壤土为主[34]。
研究区气候和土壤条件尤其适宜农作物生长,研究区内广泛种植冬小麦、玉米等粮食作物,以及棉花等经济作物,棉花的种植面积约占研究区耕地面积的一半,逐渐成为国家重点棉花生产区域。研究区区位如图1所示。
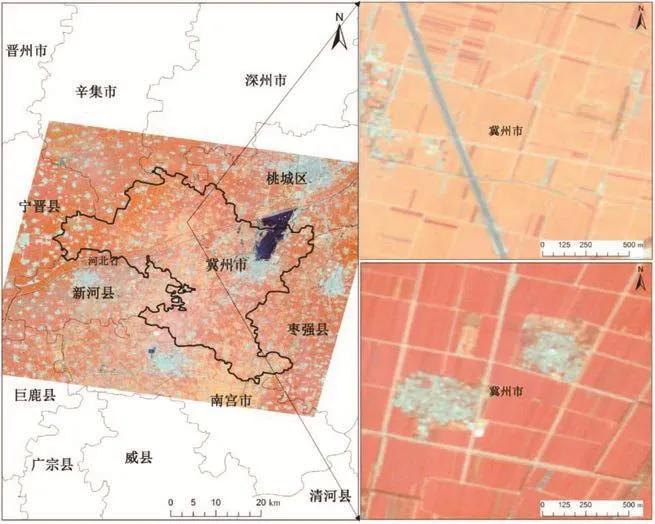
图1 研究区地理位置及Rapideye(B5/B4/B3)影像区域Fig.1 Location and Rapideye data of study area
2 试验数据获取与处理
2.1 遥感数据获取及预处理
研究数据采用2017年8月8日的Rapideye影像,该数据空间分辨率为5 m,包括蓝(440~510 nm)、绿(520~590 nm)、红(630~685 nm)、红边(690~730 nm)、近红外(760~850 nm)5个波段,影像数据如图1所示。对获取的Rapideye数据进行辐射定标、大气校正和几何精校正等预处理工作。
辐射定标采用的线性转换公式、定标斜率、定标截距都按照卫星方提供的公式与参数计算。大气校正采用ENVI/FLAASH大气校正模块进行,通过RESA网站[35]获取Rapideye卫星传感器的光谱响应函数,制作成波谱库文件,与卫星观测几何及气溶胶模式、光学厚度等参数,以及辐射定标后的影像一并输入FLAASH模型,模型输出结果就是消除大气影响的反射率影像。几何校正则在无控制点条件下采用影像自带的有理多项式系数(Rational polynomial coefficients,RPC)参数进行,同时与研究区的本底遥感影像数据进行几何精配准,使其定位精度达到亚像素级,满足遥感影像分类定位精度要求。经大气校正和几何校正后的研究区域影像如图2所示。
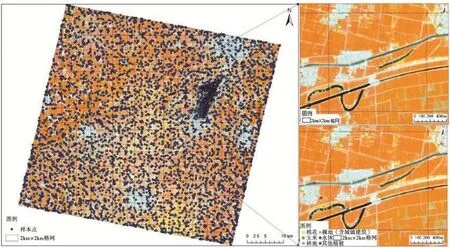
图2 研究区样本点分布Fig.2 The sample distribution
2.2 样本点数据获取
样本点数据的作用有2个,即作为训练样本及精度验证样本使用。为保证样本分布的代表性,采用随机方式获取样本点。同时将研究区划分为313个2 km×2 km格网,并将研究区地物类型划分为棉花、玉米、林地(含果园)、裸地(含城镇建筑)、水体和其他植被等6种,其中其他植被地物类型主要以植被为主,包括撂荒地以及其他作物等。采用目视解译方式逐个确定样本点地物类型。共选择了5 144个样本点,其中,棉花、玉米、林地(含果园)、裸地(含城镇建筑)、水体和其他植被6种地物的样本点数量分别为1 343、617、776、1 208、561、639个,占总样本数比例分别为26.11%、11.99%、15.09%、23.48%、10.91%、12.42%。样本点分布如图2所示。
2.3 训练及精度验证样本
将5 144个点划分为棉花及非棉花2类,分别有1 343和3 801个点,各抽取1/3作为训练样本,其他2/3作为验证样本,则共有1 454个训练样本,3 690个验证样本。精度验证数据空间分布如图3所示。
3 研究方法
3.1 技术思路
地物特征都会占有特定的光谱空间,构建主要光谱特征的综合特征,利用形式较为简单的指数形式,可以实现地物特征识别的目的。基于这一思想,针对研究区的6种地物类型,分析其光谱可分性,构建棉花识别指数,实现棉花类型的识别。
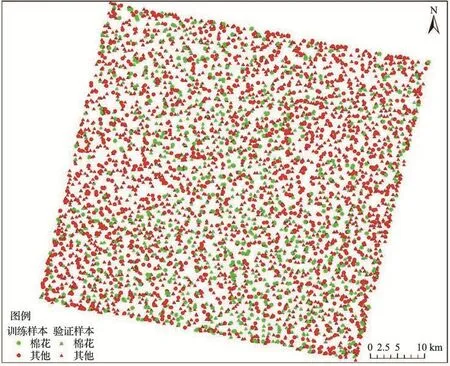
图3 研究区训练样本集验证样本分布Fig.3 Training sample and validation sample distribution
主要技术方案是,根据6种地物的光谱特征,对6种地物类型的分离程度定性排序,去除水体、裸地(含城镇建筑)2种与棉花不易混淆的地物类型,对剩余的林地、玉米、其他植被和棉花4种地物类型构建棉花提取指数(Cotton Extraction Index,CEI),要求棉花识别指数的阈值范围要占据4种地物范围的高值区域。
将棉花识别指数由低到高排序,生成均匀分布于棉花指数范围内的系列阈值,并获得每个阈值下分类结果的混淆矩阵,取总体精度最高值作为识别阈值,利用该阈值对全部影像分类,并采用目视解译获得的本底数据进行精度验证。
为验证该算法的可靠性,将该算法的结果与最大似然、随机森林等2种方法的识别结果进行比较评价。
3.2 地物光谱特征分析
基于5 144个样本点,计算6种地物不同波段反射率(为了便于说明和计算,反射率值统一扩大1万倍,下同)均值,不同地物影像反射率值变化规律如图4所示。可以看出,研究区主要地物光谱反射特征可以归纳为水体、植被、裸地(含城镇建筑)等3类低、中、高反射率地物。植被(棉花、玉米、林地及其他植被)的光谱特征显著,其可见光波段的蓝光(B1)、绿光(B2)、红光(B3)波段的反射率均较低,而红边(B4)和近红外(B5)则急速升高,表明B4+B5可以作为反映植被特征的指数;水体的各波段反射率则普遍较低;裸地(含城镇建筑)的各波段反射率普遍较高。

图4 Rapideye影像不同地物的光谱反射特征Fig.4 Rapideye spectrum reflectance character of different ground objects
根据裸地(含城镇建筑)B1、B2和B3等3个波段反射率值均较大,而植被和水体在B1、B2和B3波段反射率较小的特点,利用B1+B2+B3值大小可以对裸地(含城镇建筑)进行有效剔除。裸地(含城镇建筑)B1+B2+B3值大于3 000,而植被和水体B1+B2+B3值不足2 000,因此使用B1+B2+B3大于2 500作为判别阈值剔除裸地(含城镇建筑)。
根据水体5个波段反射率值均较小的特点,利用B1+B2+B3+B4+B5值大小可以对水体像元进行有效剔除。由于仅有水体像元B1+B2+B3+B4+B5反射率值一般都在3 000以下,因此使用B1+B2+B3+B4+B5小于3 000作为判别阈值剔除水体。
3.3 棉花识别指数的构建
基于目视解译的研究区本底数据,绘制6种地物不同波段反射率组合下像元个数分布图,如图5所示。图5a为B1+B2+B3+B4+B5波段反射率组合下不同地物像元个数分布图,水体像元集中在B1+B2+B3+B4+B5波段组合的低反射率区,根据样本点确定的3 000阈值可以对水体进行有效剔除且不影响其他地物像元。图5b为B1+B2+B3波段反射率组合下不同地物像元个数分布图,仅有裸地(含城镇建筑)像元集中在B1+B2+B3波段组合的高反射率区,根据样本点确定的2 500阈值可以对多数裸地(含城镇建筑)像元进行剔除且不影响其他地物像元。由图5c可以看出B4+B5波段可以较好地反映植被特征,棉花、玉米、林地及其他植被均处于较大反射率值区域,预期可以用于棉花的识别。
剔除水体和裸地(含城镇建筑)像元后B4+B5波段组合下4种地物类型的像元个数分布如图5d所示。从上述分析结果可知,棉花的红边及近红外波段显著高于其他植被,在传统的考虑近红外波段基础上,叠加红边波段,可以进一步提高B4+B5数值,从而使得棉花与其他植被的区分更加显著,基于B4+B5值即可对棉花进行识别和提取。因此,将B4+B5定义即为棉花提取指数CEI值,即:

式(1)中,RefRE表示红边波段反射率,RefNIR表示近红外波段反射率。

图5 不同波段反射率组合下像元个数分布:(a) b1+b2+b3+b4+b5 ;(b) b1+b2+b3;(c)b4+b5;(d) b4+b5(去除水体及裸地/城镇建筑)Fig.5 Pixel number distribution under different band reflectance combination
3.4 最大似然分类方法
最大似然法也称为最大概似估计或极大似然估计,是一种具有理论性的点估计法。最大似然分类假定每个波段每一类地物反射率统计呈正态分布,并计算给定像元属于特定类别的可能性。除非选择一个可能性阈值,所有像元都将参与分类。每一个像元被归到可能性最大的那一类里。该方法是作物遥感识别分类经常使用的分类算法,具有分类结果稳定可靠、精度较高的优点。具体算法可参考相关文献[36]。
3.5 随机森林分类方法
随机森林分类(Random Forest Classification,RFC)是Breiman于2001年提出来的一种较新的多决策树分类方法[21],该方法通过在数据上及特征变量上的随机重采样,构建多个CART类型决策树(不剪枝),通过多决策树投票的方式确定数据的类别归属。随机森林方法对于遥感影像分类具有很好的抗噪声性能,分类精度较高。该法利用样方数据自动构建分类决策树,属于监督分类的一种。相关定义及详细表述可参照相关文献[37]。
3.6 精度验证
精度验证方法采用混淆矩阵的方法进行,包括总体精度、制图精度、用户精度、Kappa系数等4个精度衡量指标,相关定义及详细表述可参照相关文献[38-40]。
4 结果与分析
4.1 基于样本点数据的分类阈值确定
按照3.2中所述方法去除水体和裸地(含城镇建筑)后,获得CEI指数影像。记录5 144个样本点对应的地物类型,分为“棉花”和“其他”两类,非棉花像元全部记为“其他”类别。经统计样本点的CEI值域范围为0~6 800。按照下式得到一系列阈值。

式(2)中,Ti为第i个阈值,i取值为1~136的自然数,为该范围内等间距分段的段数。
以系列阈值中的每一项作为分类阈值依次对CEI影像进行分类,高于阈值的判断为棉花,低于阈值的判断为其他,采用5 144个样本点中的1 454个样本点作为训练样本,3 690个样本点作为验证样本,分别计算各阈值下棉花提取精度,从总体精度、Kappa系数、棉花用户精度和棉花制图精度4个指标进行评价,精度评价指标随CEI指数的变化曲线如图6所示。
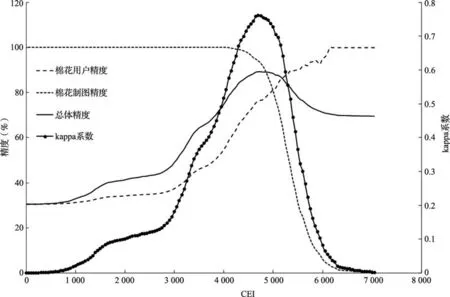
图6 基于样本点数据的CEI指数法提取精度Fig.6 Extraction accuracy of CEI method based on sample data
分类阈值较低时,棉花“错分”严重,无“漏分”现象,因此在CEI值较低时,棉花用户精度很低而制图精度很高。随着CEI值的增大,棉花“错分”现象减轻,逐渐出现“漏分”现象,因此,随着CEI值的增大,棉花用户精度逐渐增加而棉花制图精度逐渐降低。受棉花用户精度和制图精度变化规律差异的影响,总体精度和Kappa系数总体呈现先增加后降低的趋势,且在CEI为4 650时,总体精度和Kappa系数同时达到了最大值,分别91.3%和0.821 5。因此,基于样本点数据,确定4 650为棉花提取的最佳CEI阈值。
4.2 基于CEI指数的棉花类型识别
在去除水体、裸地(含城镇建筑)地物类型后,以4 650为分类阈值对整个研究区CEI的分布影像进行分类,高于阈值的判定为棉花,获得研究区的棉花分布结果,如图7所示,可以看出冀州市的棉花主要分布在中西部和南部等区域。
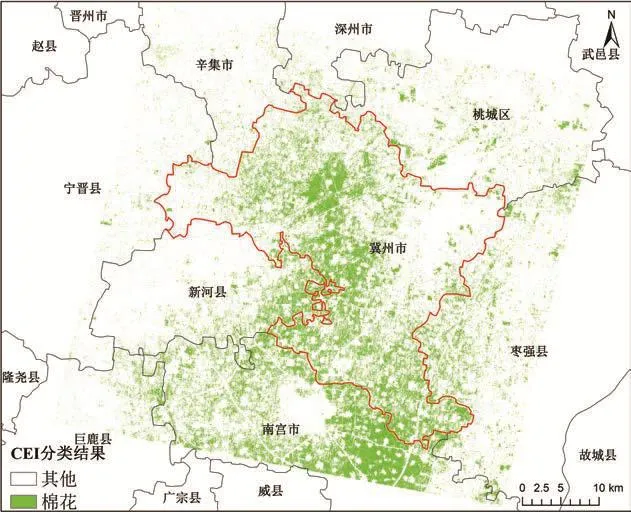
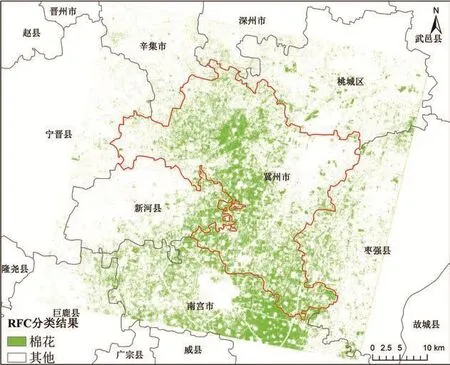

图7 基于CEI、RFC和MLC 3种方法的棉花识别结果Fig.7 Cotton extraction result based on CEI, RFC and MLC classification
利用目视解译判读5 144个样本点的地物类型对分类结果进行评价,结果表明,在阈值为4 650时,总体精度达到88.80%,kappa系数达到0.751 7。
4.3 与监督分类算法的比较
为了评价基于CEI指数方法的相对精度,采用同样样本点作为训练和精度验证样本,利用最大似然分类算法和随机森林分类算法对研究区域进行监督分类,并利用目视解译获得的本底数据对提取结果进行精度评价,从总体精度、Kappa系数、棉花用户精度和棉花制图精度4个指标进行评价,基于CEI指数法、最大似然分类法和随机森林分类方法提取精度对比情况如表1所示。

表1 基于CEI方法、最大似然分类方法和随机森林方法的棉花提取精度Table 1 Cotton extraction accuracies of CEI,MLC and RFC methods
基于最大似然分类方法的棉花提取总体精度和Kappa分别为86.53%和0.698 3。比较CEI方法和最大似然分类方法可以看出,基于CEI指数方法获得的棉花提取总体精度和kappa系数上均优于最大似然分类方法,总体精度提高了2.27个百分点,Kappa系数提高了7.65%。另外,CEI指数方法提取的结果中,棉花的制图精度与用户精度差异相较最大似然分类方法更小,可以使得漏分和错分像元数量更为一致,减少遥感分类面积与实际面积值的差异。
基于随机森林分类方法的棉花提取总体精度和Kappa分别为90.12%和0.766 7。比较CEI方法和随机森林分类方法可以看出,基于CEI指数方法获得的棉花提取总体精度与随机森林分类方法的提取精度相当,但Kappa系数较随机森林分类方法降低了1.96%。随机森林方法提取的结果中,棉花的制图精度与用户精度均优于CEI指数方法,表明随机森林分类方法综合分类效果优于CEI指数分类方法和最大似然分类方法。
5 讨论与结论
该文利用棉花在红边波段与近红外波段反射率高的特点,构建棉花提取指数(CEI)。水体和裸地(含城镇建筑)掩膜后,棉花集中于CEI指数的高值区域。通过构建系列CEI阈值,并以样本点分类精度最大作为依据确定4 650为最佳阈值,实现了棉花像元的快速精确提取,对棉花提取结果进行精度验证,结果表明分类结果的总体精度达到88.80%,Kappa系数达到0.751 7。通过与最大似然分类方法和随机森林分类方法分类精度的对比发现,作为业务运行快速提取方案,该精度是可以接受的,表明基于CEI阈值方式进行棉花面积提取是可行的。
基于CEI指数的分类方法,分类结果优于最大似然分类方法,稍差于随机森林分类方法。随机森林分类方法分类精度虽然更高,但本质上是一个“黑箱”系统,用户输入训练样本并获得分类结果,分类过程中不同波段或指数信息对分类结果的权重信息不可知,不利于用户理解。在分类结果不理想时,用户很难有针对性地对样本进行筛选和优化。CEI指数方法的最大优点在于物理意义明确、计算方便。CEI指数即为提取棉花的特异性指数,用户易于理解。此外,用户可以根据实际情况适当调整阈值,获得棉花不同的“漏分”和“错分”效果。
CEI指数原理简单,意义明确,计算方便,在区域棉花遥感识别中具有较好的应用潜力。该文仅仅通过单时相CEI指数,即可实现较高精度的棉花识别。在后期的研究中,可以进一步使用多时相的CEI指数,或结合其他类型的植被指数特征,从而实现更高精度的棉花识别甚至识别棉花的不同品种。同时,CEI指数使用了红边波段,可以进一步推广应用到Worldview、Sentinel-2A/B、GF-6等具备红边波段的卫星影像中,有利于使用多源数据构建时序CEI指数,对于区域棉花的高精度识别具有较强的推广应用价值。
猜你喜欢
冶金能源(2022年5期)2022-10-14
——缺陷度的算法研究
条码与信息系统(2022年3期)2022-07-05
汽车电器(2022年6期)2022-07-02
航天返回与遥感(2022年2期)2022-05-12
建材发展导向(2021年19期)2021-12-06
临床骨科杂志(2020年1期)2020-12-12
汽车文摘(2018年2期)2018-11-27
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
电子制作(2017年8期)2017-06-05
