
基于决策树算法的干扰信号识别*
2019-12-04 03:27:08李永贵牛英滔王昱陶
通信技术 2019年11期
方 芳,李永贵,牛英滔,王昱陶
(1.陆军工程大学,江苏 南京 210000;2.国防科技大学第六十三研究所,江苏 南京 210000)
0 引 言
信息化作战条件下,指控、情报、武器系统、导航测控等各种信息系统都高度依赖无线通信,无线通信系统和网络已成为敌方蓄意干扰的重要目标。通信蓄意干扰指削弱或破坏敌方电子系统对有用信号检测所采取的各种电子扰乱措施[1]。常见的具有代表性的干扰样式有:单音干扰、多音干扰、宽带噪声干扰、部分频带干扰、扫频干扰、脉冲干扰[1],这些典型干扰样式既可以独立运用,也可以根据具体通信信号灵活配置和组合运用,以达到更高效的干扰效果。因此,有效识别典型干扰样式,对无线通信系统或网络采取针对性抗干扰措施具有重要意义。
对于典型干扰样式的识别,国内外学者已做出大量研究。现有的文献大多采用模式识别的方法识别典型干扰样式。其识别流程一般分为三个阶段,首先采集干扰信号并对采集的干扰信号数据预处理,然后从众多数据中提取特征参数,最后根据识别算法分类识别,而识别重点在于特征提取和识别算法。目前,干扰特征通常采用关联维数、展宽特征、频谱相像系数和高阶累积量等方法表征。文献[2]提出了一种基于信号特征空间的支持向量机干扰分类算法,从文献可见该算法分类繁琐、运算量大且需要在高干噪比条件下才能达到较好的识别效果。文献[3]提出一种基于高阶累积量与神经网络的识别方法,该方法存在识别样式较少、窄带干扰识别性能差以及复杂度高的缺点。文献[4]从多维域上提取特征,并基于决策树和支持向量机的两种干扰识别器对多种典型干扰样式进行仿真识别,但该方法所需提取的特征参数多,计算复杂度高,识别干扰样式较少。
因此,本文采用一种提取多维特征参数的基于ID3决策树算法的干扰识别方法。该算法提取幅度峰均比系数、归一化带宽、单频因子系数、归一化频谱平坦度数、分数阶傅里叶域能量聚集度五种特征参数,然后运用ID3决策树算法识别典型干扰样式,与文献[2-4]相比,该方法特征参数较少、算法简单、计算量较小。
1 特征参数和提取方法
干扰信号的特征参数是反映干扰信号多维域特征的参数,用于识别或区分不同的干扰样式。但特征参数的选取应遵循数量少、计算量小、区分度大的特点,即使用最少的、计算简便的特征参数能够较准确区分较多种类的蓄意干扰。因此,本节重点考察了幅度峰均比系数、归一化带宽、单频因子系数、归一化频谱平坦度数、分数阶傅里叶域能量聚集度五个特征参数,具体如下。
1.1 幅度峰均比
幅度峰均比系数是干扰在时域幅度最大值与幅度均值比。由于脉冲干扰具有较宽的带宽,在频域很难与宽带干扰区分开,但根据时域脉冲的冲激特征,幅度峰均比参数能够较好反映脉冲干扰的幅度特征,能够将脉冲干扰与其它干扰较好的区分开。其提取方法是:对干扰信号时域采样,记干扰信号的幅度A(i),i∈[1,N]为采样时刻,记Amax为幅度最大值,Amean为幅度平均值,峰均比系数表达式为式(1)所示。

1.2 归一化带宽
频域的归一化带宽是幅度谱归一化后计算超过0.5的幅度所占比,反映了干扰在频域的带宽大小,由于宽带和窄带干扰的频谱带宽存在明显差异,因此用归一化带宽区分宽带干扰与窄带干扰。信号进行离散傅里叶变换,得到频谱F(n),并计算得到幅度谱R(n),归一化处理后,得到Bw。
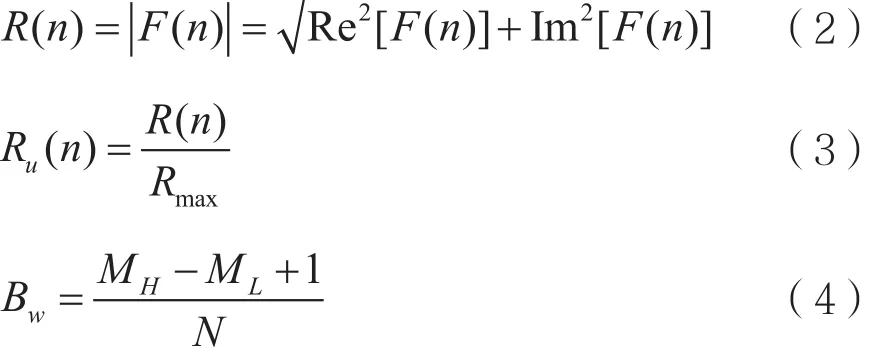
其中Rmax为幅度谱R(n)最大值,MH为归一化幅度谱大于0.5的下标最大值为归一化幅度谱大于0.5的下标最小值N为数据长。
1.3 单频因子系数
频域的单频因子系数是干扰幅度谱最大值与幅度值之和的比,由于单音干扰的能量聚集在一个频率上,因而此频率点的幅度值R(n)远大于其它点,可以用单频因子系数区分单音干扰与其它干扰。将幅度谱R(n)按从大到小排序,得到最大幅度Rmax,单频因子系数表达式为式(5)所示。

1.4 归一化频谱平坦度数
归一化频谱平坦度数反应了干扰信号在频域的起伏情况,根据该参数的大小可以判断干扰在频域有无脉冲。归一化频谱平坦系数主要反映了干扰在功率谱中是否含有明显的冲激部分:信号冲激部分波动越大,平坦度越低,平坦系数越大,窄带瞄准式干扰和梳状多音干扰的归一化频谱平坦度数明显[4]。为了获得归一化频谱中的陡峭部分,用归一化频谱减去滑动窗函数的平均频谱。
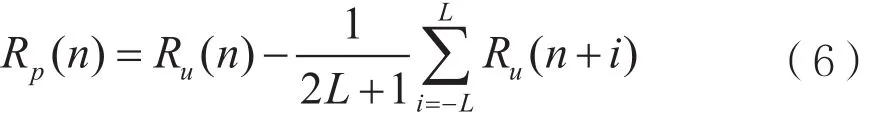
其中滑动窗口的宽度L一般为0.01N向下取整,根据Rp(n)标准差得归一化频谱平坦度数。
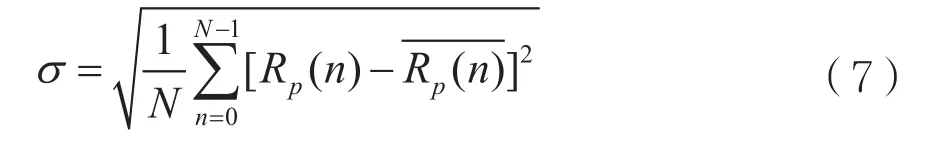
其中均值。在其它参数无法较好 地区分多音干扰与其它干扰的情况下,通过比较归一化频谱平坦度数,可将其与其它宽带干扰区分开。
1.5 分数阶傅里叶域能量聚集度
与时域、频域特征比较,变换域的分数阶傅里叶域能量聚集度往往能够更直观地反映干扰信号的能量聚集差异,并且在干噪比较低的条件下该参数也能够充分、明显地区分干扰。如果仅仅根据线性扫频干扰和宽带干扰的时域、频域特征参数,则很难将两者区分。但在分数阶傅里叶变换域,宽带噪声干扰具有平坦的频谱;而线性扫频干扰具有比较高的能量聚集度。因此,利用分数阶傅里叶域能量聚集度可以区分线性扫频和宽带干扰。
首先离散分数阶傅里叶变换:

其中uk是离散值,P为离散傅里叶阶数,P∈[0,2],r(n)位干扰时域表达式,然后计算分数阶傅里叶变换域幅度谱的最大值和平均值的比值,得到Rfr(p)。
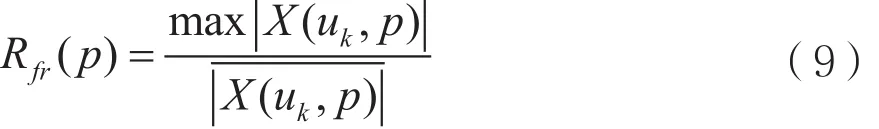

上述五种特征参数其值域变化范围受干噪比的影响,为准确估测上述特征参数的取值范围、研究干噪比对算法识别的影响,本文在-20 dB到20 dB干噪比范围内每种干扰样式随机产生1 000个样本,根据式(1)~(10)仿真出参数变化范围,如表1所示。
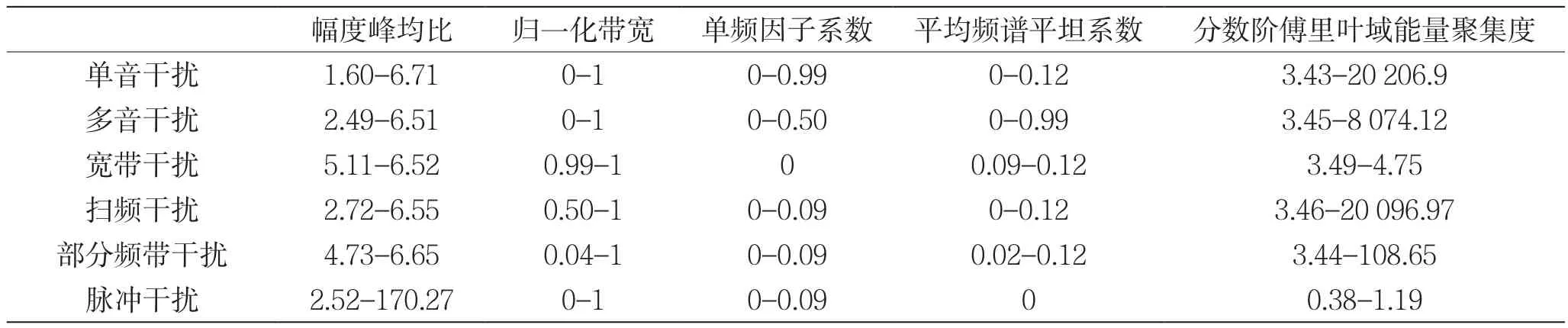
表1 6种干扰样式特征参数比较
2 干扰识别
2.1 干扰样式的模式识别
本文的干扰识别系统主要由干扰信号采集、预处理及特征提取、分类识别三个部分组成。干扰信号采集模块是采集干扰信号;预处理及特征提取模块是从数据中提取出区分度最大的特征参数,一般提取数据的时域、频域、变换域特征,形成训练样本集和测试样本集;分类识别模块是根据决策树算法识别训练样本的结果调整算法的参数,再通过误差检验的结果优化算法参数,最后输入测试样本进行识别,过程如图1所示。
2.2 决策树原理
不同的识别算法,识别的效率和准确率也不尽相同。本章提出基于经典的ID3决策树算法[6]的快速识别方法。ID3[7]的关键是选择信息增益作为属性测试的标准,每次都选择信息增益最大的那个属性,使分类的效率和质量大大提高。
设样本集X的样本种类为n,每种样本的概率为pi,那么属性A的信息增量为:

其中H(X)称为平均信息量[8]:
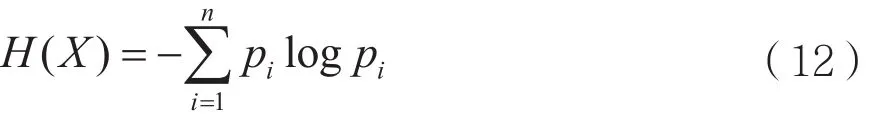
H(X,A)为已知属性A后,样本集X的信息量,它的数学表达式为:
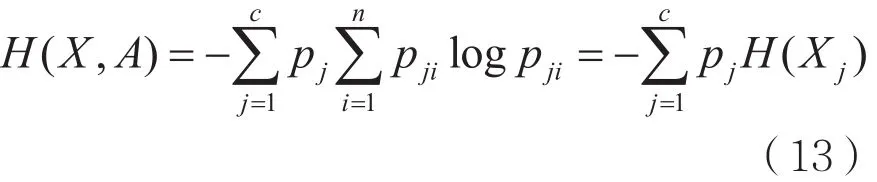
其中c为属性A的取值个数。
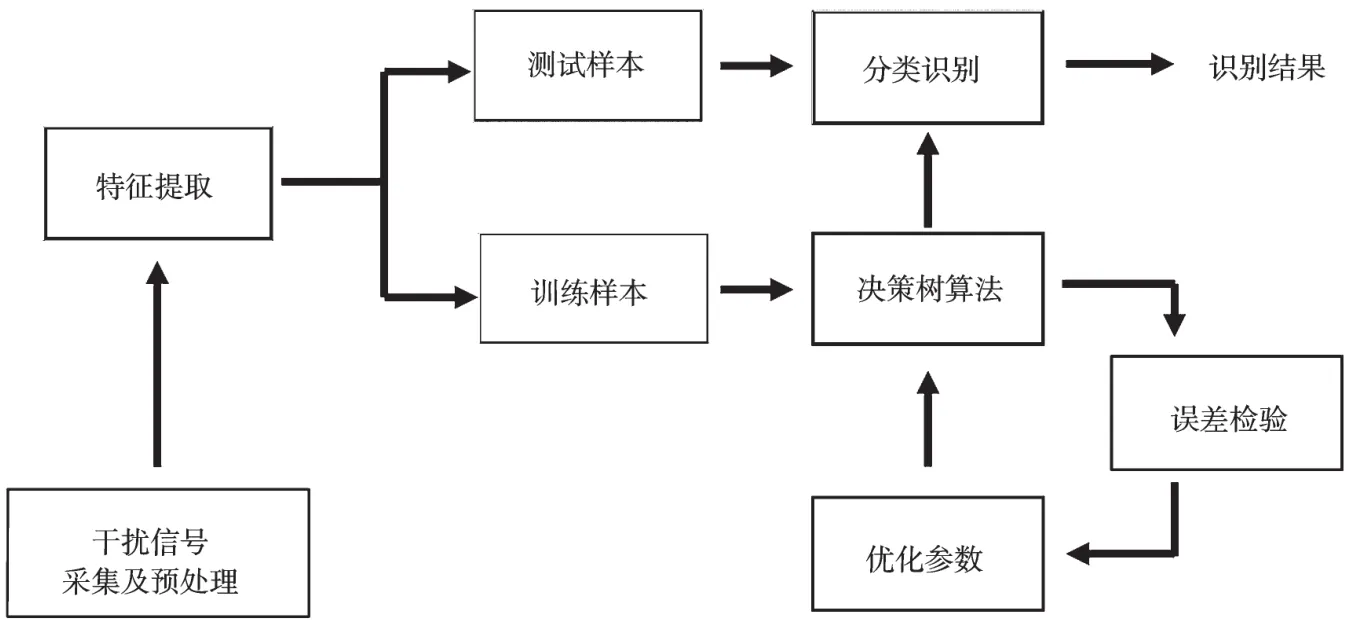
图1 干扰样式的模式识别图
本章提出的基本干扰识别算法的过程如下:
设S是6种干扰信号的训练样本集合,H是干扰信号的5种特征参数集。首先将训练样本集S和特征参数集H并成新的集合Q(S,H)。由于每种干扰有1 000个样本,那么Q为6 000x6的二维数据。它的前5列为幅度峰均比、归一化带宽、单频因子系数、归一化频谱平坦度数、分数阶傅里叶域能量聚集度特征参量,第6列为干扰样式标签,单音干扰为1、宽带噪声干扰为2、多音干扰为3、部分频带干扰为4、扫频干扰为5、脉冲干扰为6。
然后从每个干扰的1000个样本中随机选取300个训练样本,形成训练集Train(1800,H)和测试集Test(4200,H)接着从训练集Train(1800,H)中任意选取其中一个特征A,计算它的信息增量,根据6种干扰数值的不同将分类出新的节点,依次选取其它属性,重复上述过程,得到训练好的决策树。
最后利用测试集Test测试决策树的识别性能。当识别基本干扰信号的决策树构造完成时,可能会出现过拟合现象,需要剪枝去掉一些不合理的节点,剪枝时利用测试数据集Test测试叶子剪掉后识别率是否降低,若没有降低,则减去该叶子,若降低,则保留该叶子,从而得到一棵精简的树。[8,6]
2.3 基于决策树的干扰识别算法
基于ID3决策树算法的干扰信号识别:
1.数据初始化,干扰信号样本以及预处理后的特征参数样本
2.随机选取干扰样本形成训练集Train和测试集Test。
3.利用训练集Train创建决策树分类器,计算时幅度均比系数、归一化带宽、单频因子系数、归一化频谱平坦度数、分数阶傅里叶域能量聚集度的信息增益,将特征参数的信息增益按大小排序作为识别干扰信号的顺序。
4.使用测试集Test对决策树进行仿真测试,得到6种干扰样式的识别率。
5.通过训练集Train和测试集Test交叉验证误差值,找到最小错误的最大修剪级别bestlevel。
6.根据最大修剪级别bestlevel剪枝。
7.计算剪枝后决策树的交叉验证误差,保证剪枝后决策树的正确识别率。
具体识别流程如图2所示。
3 特征参数和提取方法
为验证决策树算法的有效性,分别对6类干扰信号数据集进行实验,并与传统的K最近邻算法识别器进行对比。K最近邻算法的思路是在特征空间中的K个最近邻的样本中的大多数属于一个类别,则该样本识别为这个类别。其中K的取值是算法的核心要素之一,本文K取300。该算法简单易于实现,但需要计算待测样本和训练样本所有样本数据的距离,所以非常耗时。
在仿真中单音干扰的中心频率在100 kHz~300 kHz之间随机变化,多音干扰以200 kHz为中心频率,频点数在2~5之间随机取值。宽带噪声采用高斯白噪声。部分频带干扰采用高斯白噪声通过窄带滤波器产生[9],中心频率为200 kHz,频带宽度在10~60 kHz之间随机取值。扫频干扰的中心频率为200 kHz,扫频带宽在280 kHz、240 kHz、215 kHz、200 kHz、180 kHz、150 kHz、125 kHz、100 kHz中随机选择。脉冲干扰的占空比在0.1%~1%之间随机取值。干扰信号采样点数为100 000,随机产生1 000个干噪比在-20~20 dB的干扰样本,取其中300个样本作为仿真的训练样本,700个样本作为仿真的测试样本。
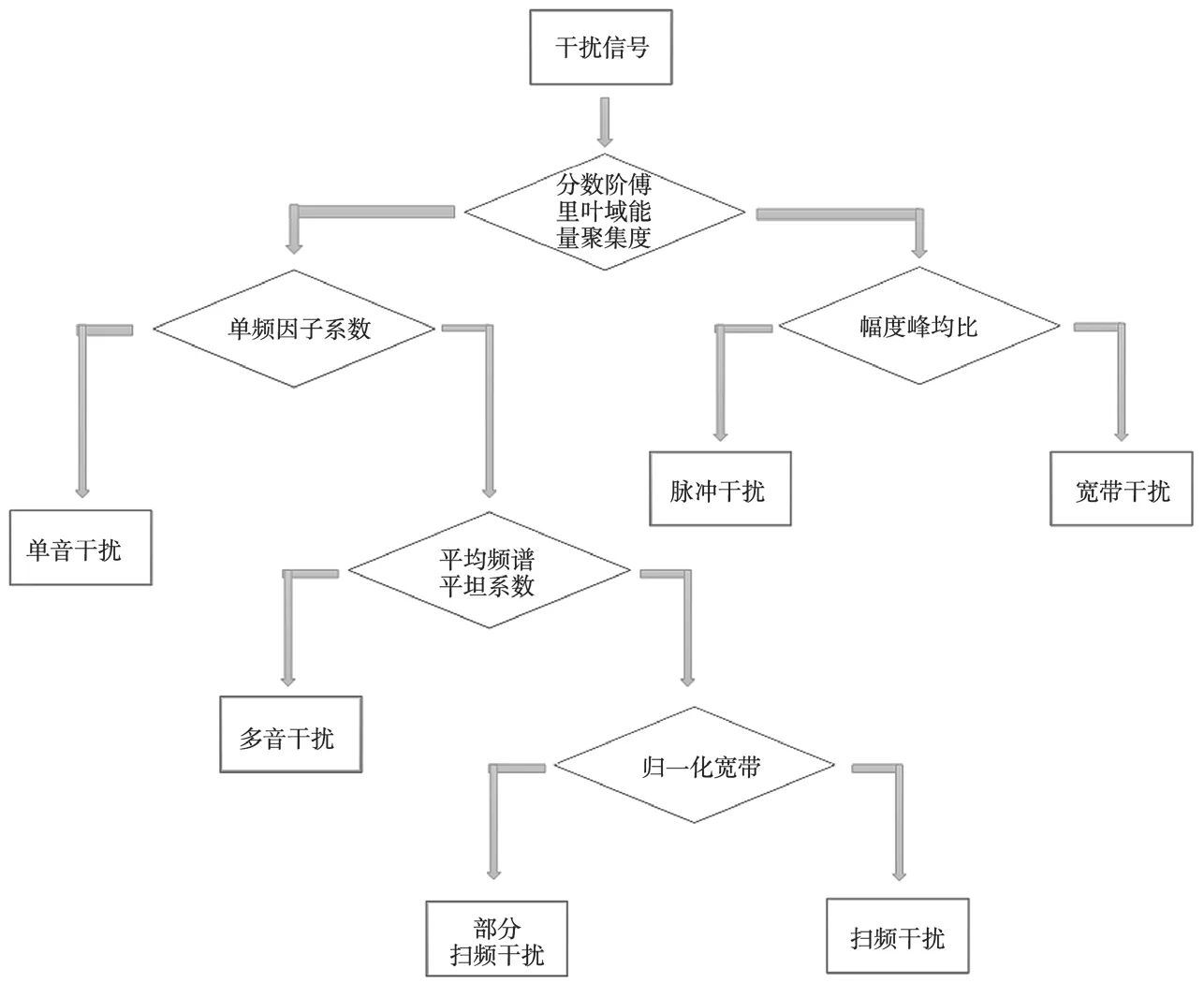
图2 基于决策树的干扰信号识别图
从图3中可以看出,决策树算法在JNR等于-5 dB时,识别率已达到80%,对单音干扰具有良好的识别能力。相比之下,K最近邻算法性能较为稳定,但JNR小于10 dB时,识别率提高的很慢。从图4中可以看出,决策树算法对多音干扰识别性能较好,JNR大于-5 dB时,识别率接近100%。这是由于多音干扰特征参数与其他干扰样式具有较大差异,故具有较好的识别性能。从图5中可以看出,JNR低于-5 dB时,K最近邻算法的识别率较好,JNR大于-5 dB时,决策树算法的识别率较好。从图6中可以看出,两种算法对部分频带干扰的识别性能都很好。图7、8可以看出,JNR大于-10 dB时,决策树算法的识别率始终高于K最近邻算法的识别率,决策树算法对扫频干扰、脉冲干扰识别性能好于K最近邻算法。从图9可以看出,JNR低于-5 dB时,决策树算法的识别率较低,JNR大于-5 dB时,决策树算法的识别率会提高的非常明显。因为在低干噪比的情况下,无法准确提取各种干扰的特征参数。随着干噪比变大,干扰样式特征参数的差异变化明显,因此识别率明显提高。通过仿真可以得出:在低干噪比条件下(一般在-10 dB下),K最近邻方法的识别性能优于本文方法,但现实环境中为保证较好的干扰效果干扰功率必须达到一定要求,因此在高干噪比条件下(一般0 dB以上),本文方法计算简单、运行较快且识别率能达到99%。
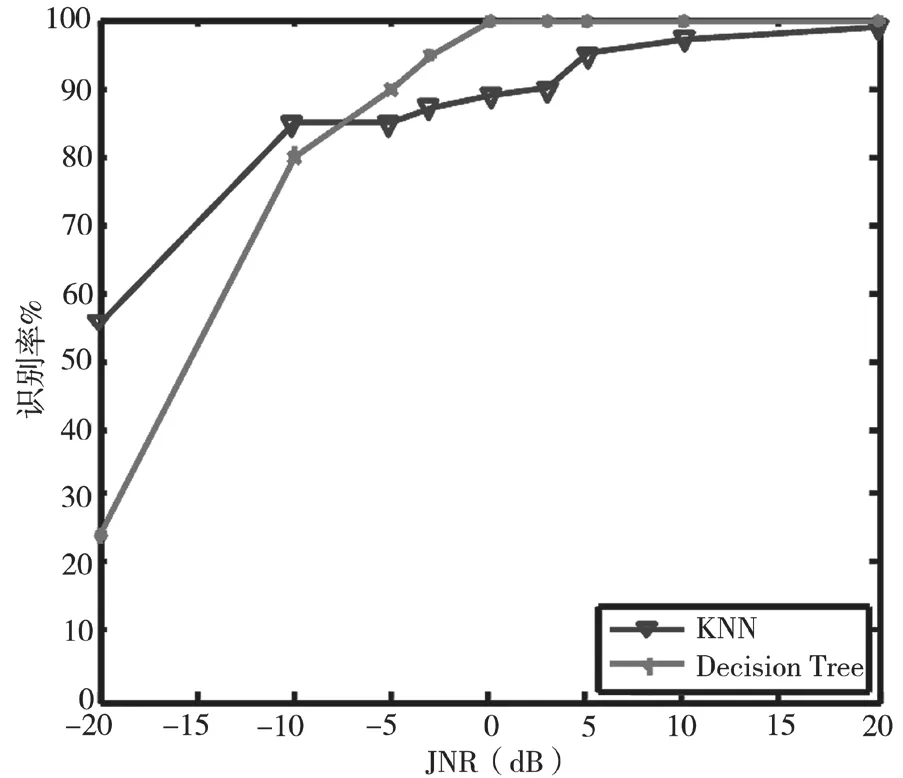
图3 单音干扰识别率
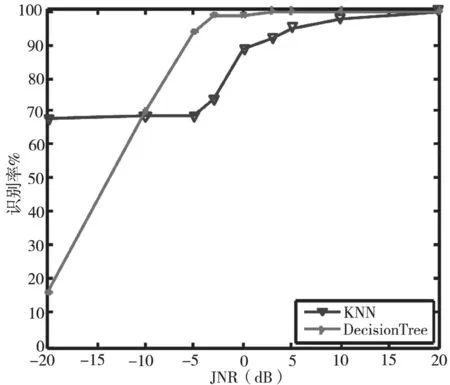
图4 多音干扰识别率
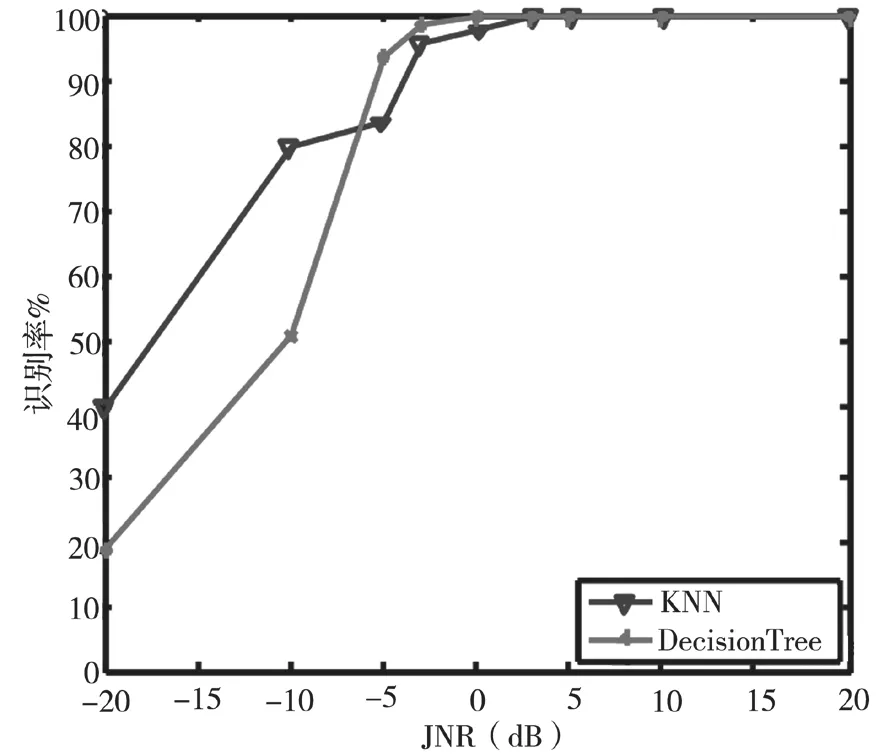
图5 宽带干扰识别率
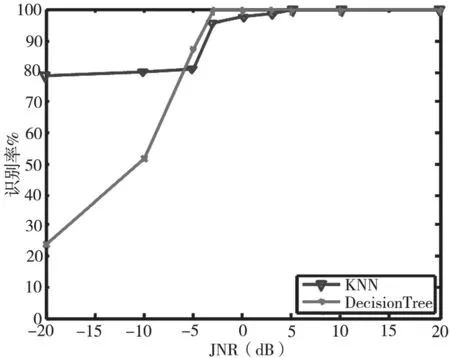
图6 部分频带干扰识别率
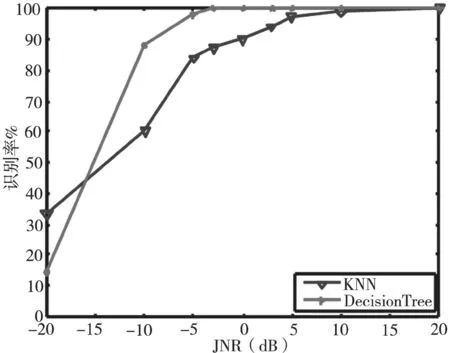
图7 扫频干扰识别率
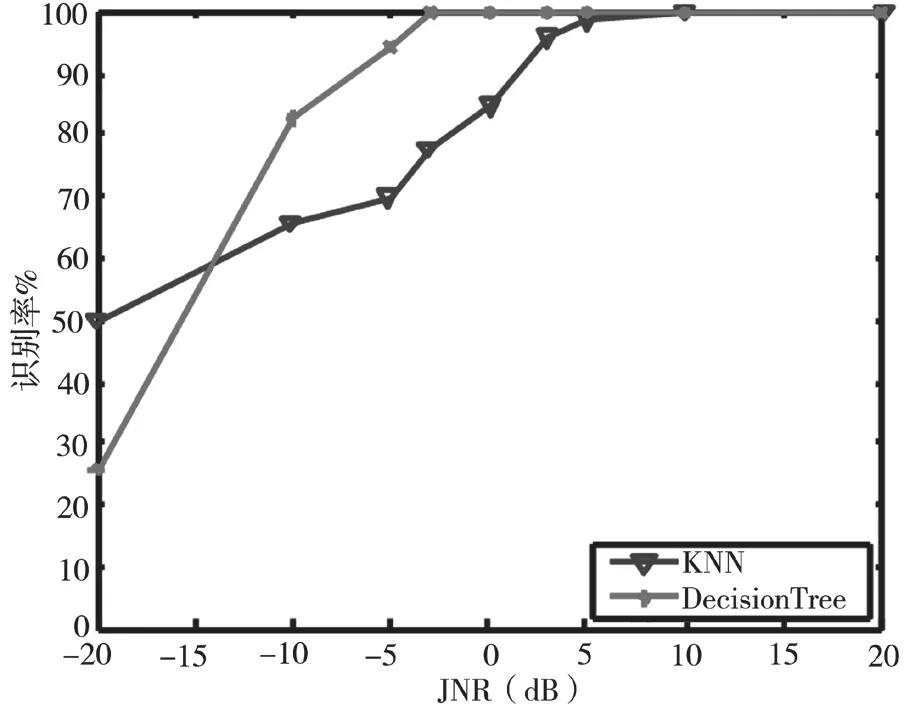
图8 脉冲干扰识别率
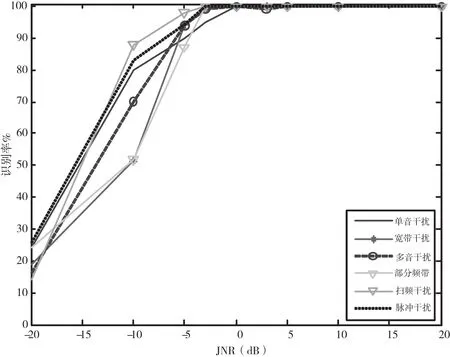
图9 决策树算法对6种干扰的识别率
4 结 语
为了在复杂电磁环境中简单、快速地识别典型的干扰样式,提供有效的对抗决策,本文深入分析干扰信号多维域的特征参数,提取了一组计算简单且个数较少的特征参数,给出了基于决策树算法的干扰识别方法,并进行了干扰识别性能对比分析。仿真结果表明,对于典型干扰样式,本文所提干扰识别算法比传统的K最近邻算法具有更好的识别性能。
猜你喜欢
天然气与石油(2022年4期)2022-09-21 07:02:38
天然气与石油(2021年5期)2021-11-06 09:39:42
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
电气技术(2021年3期)2021-03-26 02:46:08
天然气与石油(2021年1期)2021-03-08 09:07:32
通信电源技术(2020年22期)2020-03-27 06:48:02
制造技术与机床(2017年11期)2017-12-18 06:46:39
工业设计(2016年6期)2016-04-17 06:42:54
课堂内外(初中版)(2015年9期)2015-09-10 07:22:44
