
基于协整和误差修正的货车保有量测算模型
2019-12-02 04:58钱名军李引珍王亚浩
铁道学报 2019年11期
钱名军, 李引珍, 江 涌, 王亚浩
(1. 兰州交通大学 交通运输学院,甘肃 兰州 730070; 2. 青岛地铁集团运营分公司, 山东 青岛 266000)
货车是铁路系统实现货物位移的重要设备。1997—2018年铁路货车保有量与相关变量的波动变化趋势见图1。由图1可知,从近20年我国铁路货车保有量与路网货运营业里程、复线里程、货运量、货运周转量等变量的变化趋势看,尽管每年的变化方向、幅度不尽一致,但保有量与其他变量的长期趋势存在明显的相关性。对于这种复杂的关系,文献[1]指出,铁路网货车保有量与运营里程和货运量之间具有一定的相关性,但无法建立解析数学模型。因此,定性分析后作者直接采用二元线性回归方程来构建货车保有量与路网里程和货运量之间的测算模型。随着社会经济的持续发展,货运量逐年增加,铁路网建设、运营里程也在不断延长,货车保有量也应保持合理增长,这是铁路机辆部门制定货车购置计划和车流调度调整工作都非常关注的问题[2-3]。研究铁路网货车保有量与路网里程、货运量等多个变量间的量化匹配关系,有助于铁路系统进行货车资源的合理配置,提高铁路设备的整体利用率,充分释放铁路网的运输能力,实现资金的有效投入和决策的科学合理。

目前,针对类似铁路客货运量[4-5]、交通流量[6-8]、河川径流量[9]等复杂系统的预测研究大多是基于单变量时间序列,或者研究者凭借经验选取部分特征变量,缺乏较严密的变量筛选论证过程。实际上,复杂系统普遍具有多变量特性,每个变量都包含一定的表征信息,其重要性与侧重点彼此不同、又相互关联,某些变量的发展变化受与之相互作用的其它变量的影响。因此,需要将多变量序列作为一个整体进行研究,以便更好揭示复杂系统中众多变量间的相互作用关系,建立更准确的刻画模型。
本文从铁路运营历史数据时间序列本身所包含的特征信息出发,首先,对影响货车保有量的有关因素进行定性分析,根据时间序列计算出保有量与路网货运营业里程、货运量、货运周转量、周转时间等变量间的Pearson相关系数矩阵。其次,为避免模型输入变量过多,造成过拟合而影响测算结果,在不依赖先验信息的情况下,采用基于方差的膨胀因子法对各变量的相关关系进行共线性诊断,发现不经筛选直接将各变量作为模型输入变量,将产生严重的共线性。因此,采用逐步回归法筛选出包含信息量最多、解释能力最强的铁路网货运营业里程与货运量这2个变量作为模型输入变量,剔除了其他自相关的冗余变量,降低了模型维度。然后,基于协整理论[10]构建出含多元变量的货车保有量误差修正模型。最后,运用算例验证了模型的有效性,并对测算精度进行检验分析。
1 货车保有量测算模型自变量筛选
经分析,铁路货车保有量与路网货运营业里程、复线里程、货运量、周转量、货运密度、平均运距、周转时间和货车平均静载重等因素之间存在复杂联系,彼此间具有较明显的相关性。
1.1 影响货车保有量的相关变量定性分析
影响铁路网货车保有量的相关因素,主要有以下几方面。
(1) 铁路网的数量和质量因素
包括路网货运营业里程和复线里程。通常,铁路网货运营业里程越长或复线里程越长、复线率越高,路网的通行能力就越大,能开行的货物列车数量也相应增加,货车保有量也需适当增加,以保持车网的合理匹配,发挥路网的运输能力,二者呈正相关。
(2) 运量因素
包括货运量、货运周转量等。货运量的增大必然导致装卸车数的增加,对货车的需求量自然增加。而周转量为货运量与平均运距的乘积,该变量较全面地反映了货运能力的大小,承担的货运量越大,平均运距越长,货物周转量就越大,需要的货车数量就越多。
(3) 运营组织效率因素
包括货运密度、平均运距。货运密度是一定时期内相应区段周转量与其线路里程的比值,是衡量运能与运量适应程度的指标,货运密度越大,需要的货车数量也越多。平均运距是指一定时期内货物的平均运输距离,一般来说平均运距与周转时间成正比。
(4) 货车运用质量因素
涉及货车周转时间、货车平均静载重等。货车周转时间主要反映日常运营组织的质量。通常,周转时间越小,意味着机车车辆周转速度越快,运输组织效率越高,承担的货运量会越大,需要的货车数量就越多,它与货车保有量呈负相关。货车载重量利用率直接影响货车保有量,载重量利用率越高,货车平均静载重越大,需要的货车数量越少。
以上是对影响货车保有量的众多变量的定性分析,为准确揭示各变量对保有量的正负相关程度,利用Pearson相关系数进行量化表征。
1.2 基于Pearson系数的多变量相关性量化分析
Pearson相关系数常用于度量两个变量X与Y的线性相关关系强弱,相关系数ρ为
( 1 )
式中:Cov(X,Y)为X、Y的协方差;σX、E(X)和σY、E(Y)分别为X、Y的标准差和数学期望。
选取1997—2018年铁路行业的路网货运营业里程、货运量、周转量、平均运距等变量序列数据为研究样本,采用式( 1 )求得各变量间相关系数矩阵,见表1,表中“货运里程”为“路网货运营业里程”的简写,路网货运营业里程=路网运营总里程-高铁运营里程。

表1 各变量相关系数矩阵
如果把货车保有量作为因变量(被解释变量),其余变量作为自变量(解释变量),由表1可知,路网货运营业里程、复线里程、货运量等多个变量与货车保有量的相关性均较显著。此时,仅从相关系数难以判断哪几个变量才是对货车保有量解释能力最强的关键变量。同时也发现,各解释变量间存在较强的相关性,如货运里程与复线里程、货运量与周转量之间。在对多元复杂系统进行建模时,若忽略自变量内部彼此间的自相关性,而将其简单处理全部直接作为输入变量,将导致模型过于复杂,且容易出现过拟合或多重共线性,这会使建模结果产生偏差甚至错误。基于方差膨胀因子的多重共线性诊断结果见表2。

表2 基于方差膨胀因子(θVIF)的多重共线性诊断结果
基于方差膨胀因子的多重共线性诊断规则为θVIF<5不存在共线性或共线性较弱;5≤θVIF≤10存在中等程度共线性;θVIF>10共线性严重,θVIF值越大说明线性依赖越严重。由表2可知,若直接将8个相关变量均作为模型输入变量,将产生较严重的共线性。因此,为降低模型复杂度同时提高建模精度,必须设法消除共线性,从相关变量中筛选出包含信息量最多、解释能力最强的变量组合作为模型的输入变量,剔除自相关的冗余变量。
1.3 基于逐步回归的模型变量筛选
本文结合铁路货车保有量问题的研究实际,综合考虑8个影响因素的关联性大小和回归计算的计算量,采用较稳妥的逐步回归法对模型的自变量进行筛选:根据自变量对因变量的影响大小,将其逐个引入回归方程,影响最显著的先引入方程,在引入一个变量的同时,对已引入变量逐个检查,将不显著的变量再从回归模型中剔除,最不显著的变量先被剔除,直到再也不能向回归方程引入新变量,同时也不能从回归模型中剔除任何一个变量为止。自变量引入和删除的显著性水平分别为0.05和0.1,即自变量引入的条件比删除的条件更为严格。经过6步回归后,得到拟合优度最好的解释变量是路网货运营业里程与货运量的组合,其余变量均被剔除。模型自变量筛选结果见表3。

表3 逐步回归自变量筛选结果
表3给出的是引入路网货运营业里程、货运量这2个解释变量的模型拟合优度R为0.993 5,非常接近1,调整后R2值(排除了自变量的影响)为0.984 6,也是6步回归过程中最大的,表明该自变量组合可以解释因变量98.46%的变化。同时,模型方差F检验值最大,显著性0.000 2远小于0.01,达到显著性标准。2个变量的回归系数显著性检验值均小于0.01,说明自变量对因变量具有显著影响,印证模型是有意义的。
2 基于协整理论的预测建模方法
2.1 协整原理
协整关系[11]是指系统变量间的长期均衡关系。可用于描述两个或多个非平稳时间序列的均衡关系。
定义1 对于m维向量时间序列
Xt={X1t,X2t,…,Xmt}
如果:
(1)Xt的各分量序列{X1t,X2t,…,Xmt}为具有相同阶数d的单整序列。
(2) 存在一个α≠0,使得αTXt~I(d-b),b>0。
则称Xt={X1t,X2t,…,Xmt}中各分量序列存在(d,b)阶协整关系,记为Xt~CI(d,b),α为协整向量。
2.2 多变量序列误差修正模型
误差修正模型[10,12](Error Correction Model,ECM)是一种将长期协整关系与短期误差修正方法相结合的时间序列预测模型,克服了伪回归问题,能有效描述变量序列间的长期稳定表现和短期波动特征。根据Granger定理[13]:若变量间存在协整关系,即表明这些变量间存在长期稳定的均衡关系,而这种长期均衡关系是在短期波动过程中不断调整(误差修正)才得以实现的。任何一组相互协整的变量序列都存在误差修正机制,通过变量间这种调节机制,保持其长期均衡关系。
设m+1维向量时间序列{Yt,X1,t,X2,t,…,Xm,t}各分量均1阶单整,变量间的长期均衡模型一般表达式为
Yt=a0+a1X1,t+a2X2,t+…+amXm,t+εt
t=1,2,…,T
( 2 )
式中:[a0,a1,a2,…,am]为协整向量,ai(i=0,1,2,…,m)为协整参数;εt为平稳非均衡误差项,满足εt~iidN(0,δ2)。式( 2 )对应的一阶滞后分布模型(ADLM)[8]为
Yt=β0+β1X1,t+γ1X1,t-1+
β2X2,t+γ2X2,t-1+…+
βmXm,t+γmXm,t-1+μYt-1+εt
( 3 )
式中:βi、γi和μ为对应回归参数,i=0,1,2,…,m。该模型显示出Yt值不仅与Xt的变化有关,而且与Xt-1与Yt-1有关。对式( 3 )左右两边同时减去Yt-1,右边同时加减βkXk,t-1,k=1,2,…,m,即得对应的一阶误差修正模型
ΔYt=Yt-Yt-1=β1X1,t+γ1X1,t-1+β2X2,t+
γ2X2,t-1+…+βmXm,t+γmXm,t-1+(μ-1)Yt-1+
β0+εt-β1X1,t-1+β1X1,t-1-β2X2,t-1+β2X2,t-1-
…-βmXm,t-1+βmXm,t-1=β1ΔX1,t+β2ΔX2,t+
…+βmΔXm,t-(1-μ)(Yt-1-
β2ΔX2,t+…+βmΔXm,t-λ(Yt-1-ρ0-ρ1X1,t-1-
ρ2X2,t-1-…-ρmXm,t-1)+εt
( 4 )
式中:
i=1,2,…,m

因此,式( 4 )也可写为
( 5 )
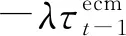

ECM模型是在向量自回归模型(VARM)的基础上发展起来的,是具有协整约束的向量自回归模型,与无约束的VARM相比,ECM将变量序列中的长期均衡关系与短期非均衡波动结合起来,能提高预测模型的稳定性。
3 货车保有量测算模型构建
3.1 数据来源及处理
本文从国家统计局官网、历年《中国铁道年鉴》和《铁道统计公报》中提取到1997—2018年的国家铁路货车保有量、路网营业里程、货运量等统计数据作为研究样本。
为消除各数据序列的量纲影响,同时不改变数据间的协整关系,本文对各变量序列均进行了自然对数标准化处理,文中均以此数据为研究基础。根据前文的变量筛选,将自变量记为X1(货运营业里程)、X2(货运量),因变量记为Y(保有量)。
3.2 时间序列平稳性检验
根据变量序列协整建模理论,首先需要对各变量序列进行平稳性检验,以防止出现伪回归现象[14]。本文采用ADF单位根检验(Augmented Dickey-Fuller Unit Root Test)[15]来判定相关变量的时间序列是否平稳。若不平稳,则对初始序列先后进行一阶、二阶差分再行判断。若平稳,则可在此基础上进行下一步的Johansen协整分析。
本文对Y、X1和X2三个变量序列进行ADF检验的结果见表4。

表4 变量序列ADF检验结果
检验结果分析:(1)3个变量的初始序列ADF检验统计量均大于1%、5%和10%的水平临界值,即在1%、5%和10%显著水平下分别以0.999 7、1.000 0和0.987 9的概率接受存在单位根的原假设。所以,原序列都是非平稳序列。(2)3个变量的一阶差分序列对应的ADF检验统计量都小于5%的显著水平临界值,且接受存在单位根的原假设的概率分别为0.000 4、0.015 0和0.009 3,均小于0.05,表现出平稳性。综上,变量序列均为一阶单整,记为(*)~I(1),Δ(*)~I(0),满足进行Johansen协整分析的条件。
3.3 Johansen协整检验
协整检验是构建向量误差修正模型的基础,主要判断模型内部各变量是否存在长期均衡关系。因涉及3个变量间的均衡关系分析,故采用Johansen协整检验法。依据最小AIC(Akaike Information Criteria)准则,选取最佳滞后阶数为2。它包含了迹检验(Trace Test)和最大特征值检验(Maximum Eigen-value Test)两种方法,使结论更具稳健性,检验结果见表5。

表5 Johansen协整检验结果
由表5可知,协整检验中迹检验和最大特征值检验均表明,对应原假设的检验统计量都分别大于其5%显著水平下的临界值,且接受原假设的概率均远小于0.05,协整方程个数最多有3个。这表明货车保有量、路网货运营业里程和货运量这3个变量间彼此存在长期的协整关系,这也为本文的研究提供了有力支撑。
3.4 测算模型构建
(1) 长期均衡模型
根据上述协整结果可知,3个变量间存在显著的协整关系,根据式( 2 )可以建立长期均衡模型(协整回归方程)
Yt=α0+α1X1,t+α2X2,t+εt
( 6 )
以1997—2016年的数据为建模样本运用最小二乘法(OLS)对模型参数进行回归估计并检验,结果见表6。

表6 均衡模型参数回归结果及检验数
可决系数R2很接近1,各变量系数的标准差很小,对应P值均小于0.01,D.W检验值接近2,表明残差序列不相关,均说明拟合效果显著。对应协整方程为
Yt=8.888 8+1.019 2X1,t+0.179 4X2,t+εt
( 7 )
同时对模型的残差序列εt进行ADF检验,结果见表7。

表7 均衡模型残差序列ADF检验
残差序列εt的ADF检验统计量均小于1%、5%和10%的显著水平临界值,接受存在单位根的原假设概率为0.000 0,表现出平稳性。再次证明模型所选变量是有意义的。
(2) 短期误差修正模型
按最小AIC准则,选取模型的最佳滞后阶数为1,按照式( 5 )将协整回归方程( 7 )的残差序列作为误差修正项,即可建立对应一阶误差修正模型
( 8 )
式中:
(8.888 8+1.019 2X1,t-1+0.179 4X2,t-1)
再运用OLS法对模型参数进行回归估计并检验,结果见表8。

表8 VECM参数回归结果及检验数
可得误差修正模型为
ΔYt=0.896 1ΔX1,t+0.129 1ΔX2,t-
误差修正系数λ=0.676 8,表明上一年度货车保有量增速与长期均衡值偏离量的67.68%将在本年度得到修正,修正力度较大。
(3) 测算模型
将上述模型进行整合,即可得到年度货车保有量测算模型为
Yt=Yt-1+ΔYt
( 9 )
利用式( 9 )即可实现对相应年度货车保有量的计算或预测。
4 模型测算性能评价及结果验证
为验证所建误差修正模型的有效性,对其进行保有量预测验证及精度分析。
4.1 性能评价指标
本文采用平均相对误差δMPE、Theil不等系数U、偏差比例σBP、方差比例σVP和协方差比例σCP等指标从多方面进行预测精度检验。
(1) 平均相对误差δMPE为
(10)
式中:h为样本期数。
(2) Theil不等系数U为
(11)
(3) 偏差比例σBP为
(12)
(4) 方差比例σVP为
(13)

(5) 协方差比例σCP为
(14)

4.2 货车保有量测算结果验证分析
以2017、2018年度国家铁路货车保有量实际数据为测试样本,对所建模型进行验证,2017、2018年国家铁路货车保有量实际值来自于对应年度的《中国铁路总公司统计公报》。有关测算精度指标计算结果见表9。

表9 保有量测算结果及精度对比
根据所建模型结合货运营业里程和货运量预测值可测算出2019—2022年国家铁路货车需求量分别为80.14、82.33、85.43和87.77万辆。综合表9和图2来看,所建误差修正模型测算的货车数与历年实际值接近程度较高、偏差较小。相对误差稳定在0.018附近;不等系数U是不受量纲影响的相对指标,度量的是相对均方误差,其值远小于0.01。偏差比例σBP较小不到2%,它度量了预测值与序列实际值均值的偏离程度,表示的是系统误差;方差比例σVP较小近乎为0,它度量了预测值方差与实际序列方差的偏离程度;协方差比例σCP则高于98%,它衡量了剩余的非系统预测误差。三个比例值之和为1,表明预测效果良好。可见,测算值基本围绕实际值上下小幅波动调整,这也验证了修正系数在模型中所起的作用。

5 结论
铁路系统全网或局部路网的货车保有量应该有一个合理数值,长期以来对该数值的计算方法研究较少且缺乏有力论证。本文在不依赖先验信息的情况下,从铁路运营历史数据时间序列本身所包含的特征信息出发,筛选出对因变量解释能力最强、包含信息量最多的铁路网货运营业里程与货运量这2个变量作为模型自变量。在对自变量和所选因变量序列进行ADF检验和Johansen协整检验的基础上,给出了多变量序列误差修正模型(ECM)的构建方法,并以历史数据为基础,采用OLS回归方法确定出合理的误差修正模型参数。研究结果表明:
(1) 影响货车保有量的因素确实较多,但对其解释能力最强、包含信息量最多的是路网货运营业里程和货运量两个参量。
(2) 货车保有量及其解释变量序列本身都是不平稳的,带有趋势项的,而其一阶差分序列才是平稳序列,可用于做进一步的长期均衡性研究分析。
(3) 运用基于协整理论的误差修正模型来测算铁路货车保有量是可行的,且精度验证效果较好。
基于协整理论和误差修正的测算模型丰富了铁路系统有关参量的测算方法体系,其测算结果可为铁路机辆部门制定货车购置计划或日常车流调度调整措施提供科学的决策依据和参考指标。
猜你喜欢
润滑油(2022年3期)2022-11-15
新能源汽车报(2019年25期)2019-08-13
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
大陆桥视野(2017年13期)2017-12-23
智富时代(2017年1期)2017-03-10
