
归一化植被指数研究
2019-11-26 11:54张姗
绿色科技 2019年20期
关键词:研究方法
张姗


摘要:针对归一化植被指数(NDVI)在国际和国内研究中的应用及与其他数据的结合情况,对NDVI在不同研究领域中的深化应用及研究的最新进展进行了简要介绍。同时通过一些案例的分析,得到了NDVI数据与其他数据结合研究的基本思路和方法论,在研究现状方面,基于当前较为普遍的相关性分析,做深入的研究与探讨,在值检验方法方面。对NDVI在不同的研究方向中的值检验方法进行了简要分析,主要涉及到的就是显著性检验,最后结合研究现状和NDVI的局限,对当前研究进行了总结,以对后续研究提供想法。
关键词:归一化植被指数;值检验;研究方法;数据结合及相关性分析
中图分类号:Q948 文献标识码:A 文章编号:1674-9944(2019)20-0025-04
1引言
归一化植被指数(NDVI),是反映植被覆盖与植被分布的重要数据,通过对NDVI在时间序列上的变化进行分析,能够较为准确地获取植被覆盖度、植被物候、植被分布区域的变化规律,对深入研究全球气候闭环和陆地生态系统具有十分重要的意义。
目前,已有一些研究,利用NDVI指数对全球或者区域的植被变化进行研究,Tingxiang Liu等利用NDVI数据,研究了1982~2015年中国东北地区植被物候变化,殷刚等通过研究长时间序列下中亚地区的NDVI数据,得到全球变化下中亚地区植被覆盖度的变化和影响因子的相关度,梁守真等利用2000~2009的ND-VI数据,研究了时间序列下环渤海地区植被的变化情况。对于当前NDVI的数据结合,现有研究多用气候数据,主要分析植被变化与气候因子的关系。
在值检验和拟合公式方面,主要涉及到P值检验和拟合公式,同时也会涉及部分适用于NDVI数据的数学模型(主要是植被物候模型),拟合公式方面主要会涉及到SLOPE公式和线性偏相关公式。从而多角度地分析NDVI的应用与研究现状,为后续研究提供借鉴。
2NDVI的研究方法
2.1SLOPE公式与植被覆盖度
当前NDVI的研究方向,主要在于3个方面,研究植被覆盖度变化及影响因素,研究植被物候变化及变化规律,研究植被变化(覆盖度,物候,垂直地带性,区域分布)与影响因子的相关性。
关于植被覆盖度变化的研究,其主要的研究方向在于基于长时间序列的研究区研究,或是基于大尺度研究区的研究,同时也存在两者相结合的情况,其主要落脚点在动态监测和原因分析。当前的研究方法是基于SLOPE公式反映的NDVI数据的变化情况,对植被覆盖度的变化进行分析:
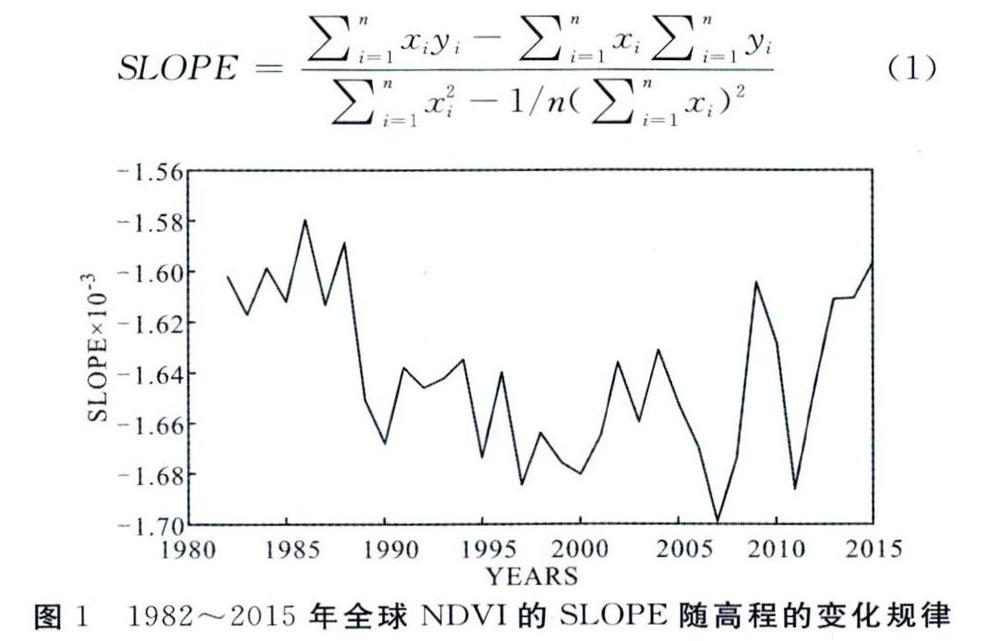
式(1)中:SLOPEE为回归方程斜率;z,y分别为年份和年均NDVI)i为计算期间年份序号;n为计算的总年份。如果SLOPE
SLOPE的变化强度实际上就是指SLOPE的SLOPFE,1982~2015年全球NDVI的SLOPE随高程变化的规律图(图1)总体上反映的是NDVI的垂直分异规律,即海拔上升,植被覆盖度总体呈下降趋势,但这种垂直分异的明显程度在不同时间段存在不同,就折线图数据而言,SLOPE值呈现1982~2000年减小,2005~2015年增加的情况,说明了垂直分异存在“相对不明显一相对明显一相对不明显”的趋势,基于此趋势可以进一步探究影响垂直分异明显性变化的原因。
2.2物候拟合函数与植被物候变化
关于植被物候及物候变化规律的研究,研究方向主要是关于长时间序列的植被物候变化的研究,其主要研究数据为GIMMS NDVI数据,简要研究流程:首先是基于GIMMS NDVI数据提取每一年年内NDVI变化情况,然后根据时间序列提取多年的NDVI变化曲线,再利用拟合函数模型对原始的NDVI变化曲线进行拟合,主要的拟合函数模型有Savitzky-Golay滤波模型,不对称高斯函数模型和双logistic函数模型,可以根据最优拟合模型进行选择,也可以将3种函数值进行线性变换(求平均,权重求和),最后选择适当的分析法进行分析,得出结论。关于函数拟合方面,由于当前的技术层面无法达到年内不间断连续监测NDVI值,同时由于云量等问题,部分NDVI值会存在空缺或者错误,所以需要用拟合模型对原始数据进行拟合,针对3种常用的函数拟合模型,本文主要介绍双logistic函数模型,其函数模型结构如下:
f(t)=c1+c2g(t;x) (2)
式(2)可以看成是f(t)=b+ax的初等线性函数式,在研究性论文描述“C1和C2决定了函数的基线和振幅”,其实质也可以从初等函数中反应出来,C1=6,表示函数向上或向下平移的距离,C2=a,表示函数的增减性质,g(t;x)是一个高斯型函数,近似于正态分布的图像,整个函数的线性与非线性取决于g(t;x),由于其近似正态分布的函数曲线,导致c1决定其下限值高度,即所谓基准高度,C2决定其振幅大小,即增加时增加的幅度,和减少时减少的幅度,这两个幅度决定了函数的一个极值到基准线的垂直距离,即振幅;g(t;x)在双logistic函数模型中其函数结构为:
2.3偏相关系数与相关性分析
关于植被变化及影响因子相关性的研究,在当前的研究中,主要涉及到的是气候因子对于植被覆盖度变化的研究,其研究一般思路是,利用NDVI与其他数据进行偏相关系数计算,从而得到各个因子在植被变化过程中的偏相关系数,从而判定影响植被变化的多种因素中,每个因素所占的地位。相关性分析的一般流程是:提取需要计算偏相关系数的因子在研究区和研究时间内的数据,然后计算各数据与其他数据的相关系数,再利用相关系数计算一阶偏相关系数,用一阶偏相关系数计算二阶偏相关系数,递归计算直至k阶偏相关系数计算完成,最后根据影响研究参数的各因子,k阶偏相关值的大小,说明影响该参数的因子在影响过程中所占的地位。相关系数计算公式如下:
表2显示的是林冠层截留量与各影响因素的偏相关系数,由表中数据可以看出,林外降雨量與林冠层截留量有较大关系,其次是风速与相对湿度,与其他因素的关系较小。
2.4偏相关系数变化分析
通过偏相关系数在长时间序列上的研究,可以发现,偏相关系数在长时间序列上并不是固定不变的,而且诸多研究中都能找到这种实例,如图2t61。
图2中可以明显看出NDVIGS(GS is Growing sea-sons)和GT(GT is Growing temperature RNDVI-GT)的部分相关系数。在前15年和后15年有明显的不同,同时从5个方面定义GS,发现偏相关系数都有明显的降低,但是就研究而言,对于这种变化的原因研究的比较少,不仅仅需要从阶段上来研究前后阶段的变化,更应该从年际变化和年际变化反映的长时间序列的变化趋势来研究,研究的简要技术路线如图3所示。
3显著性检验与尺度转换
3.1显著性检验
显著性检验,主要指利用拟合函数对不连续或者空缺值进行拟合假设时,需要检验拟合值与实际测量值的差异是否显著,即拟合值与实际样本的测量值间的差异,是拟合值的总体特征与实际测量值特征在根本上就不一致,还是拟合值与实测值之间的差异纯属机会变异。也就说,显著性检验是检验数据反映真实情况程度的方法,常用的显著性检验的方法是P值检验。
在NDVI的研究中很多涉及到P值检验的拟合计算,同时显著性检验并不只是说明的是,数据值的大小,数据的变化趋势,而是说明数据的可靠性,在对NDVI数据的研究中,往往涉及到植被的增长速率,植被的下降速率,植被的变化趋势等问题,在大多数研究中,关于NDVI的这些结论,都利用了显著性检验来检验拟合数据的可靠性,常用的P值界限有(0.01,0.05,0.1),当P>0.05或0.1时说明由数据得到的结论(如相关性,数据趋势,数据增速)不显著,当P<0.05或0.1时,说明由数据得到的结论显著,但是并不是说没有通过P值较小的显著性检验的结论就不能使用或者说毫无价值:Gang Fu,Zhen xi Shen在研究修剪与气温变暖对青藏高原北部三大高寒草甸区植物生产力的影响时,得到了C区由于修剪造成的GPP下降14.4%的结论,该结论的P检验值只有0.082,远大于0.001和0.005,但是在试探性研究中如果把P定为0.1,则在较高的P值下,该结论仍可以说明是显著的。在NDVI与其他数据的相关性研究中,对于相关性的P检验则是说明两组数据是否是显著相关的,白建军等在研究区域气候因子与植被时空变化关系时,得到了植被月平均NDVI值和月降水量相关系数是0.808(n=132)P<0.001的结论,反映的是植被月平均NDVI值和月降水量相关系数的可靠性。由相关系数0.808显著,可以得到植被月平均NDVI值和月降水量相关性较大的结论。
3.2尺度转换
在研究NDVI数据与其他数据相关性时,常遇到数据尺度不一致的情况,在尺度由低分辨率向高分辨率转化时,可以办的方法是进行重采样,再进行尺度转换,在尺度上推时,选择方法有很多:线性的方法可以选择相邻像元和求平均的方式,也可以选择加权求和方式,进行尺度转换,非线性的方式可以通过设立中间尺度,建立中间尺度与高低分辨率间的函数关系,由低分辨率向中间尺度转换,再由中间尺度转换到高分辨率,尺度转换实例。
在研究中1982~2015年全球植被覆盖的时空变化及其驱动因子时,NDVI数据分辨率为0.083度,气象数据为0.25度,不能直接进行叠加运算。于是需要进行尺度转换。此研究采用加权求和的方法将NDVI数据转换至与气象数据相同的尺度。转换公式为:
4结论与讨论
本文对NDVI的主要应用方向及研究方法进行了总结概括,深入探究了主要的NDVI研究方法及研究函数,研究结论实际上是一个NDVI数据的研究方法和研究思路,主要就有,植被覆盖度对应的SLOPE函数研究,植被物候对应的双logic函数模型研究,植被变化与其影响因子的相关性研究,偏相关系数的深入探讨,显著性检验和尺度转换。关于NDVI数据其实也存在较大的局限性,NDVI公式为:
根据函数结构可以看出,NDVI是近红外和红波段的观测数据进行非线性变换得到的,这种非线性变换对NDVI的低值部分数据来说是一种突出,对于高值部分来说是一种抑制,导致NDVI数据,在高值部分反应不灵敏,从而在对植被覆盖度较高区域例如亚马逊和刚果雨林的变化研究中,NDVI數据很少被采用。
如在研究热带雨林退化和碳储量之间的关系时,Mohammed Alamgir等则使用的统计实测,在雨林中抽样进行测量的方式进行研究,而非利用NDVI数据。同时在研究中非树木覆盖度的决定因素及敏感性时,Julie C.Aleman等使用分类型计算的方式,计算不同影响因子在模型中的相对重要性以及它们与植被覆盖偏相关系数来量化每个预测因子的影响,在分析当前植被覆盖分布及变化的同时,该研究基于数据,增加了对未来植被覆盖度变化的预测,但该研究是从植被覆盖度影响模型和MODIS three cover数据角度出发的。对于基于NDVI数据的植被覆盖度及分布预测的深度研究还较少。最后基于大尺度长时间序列的NDVI变化及影响因子研究多考虑的是NDVI与其影响因子的线性相关性,但实际情况并不是所有影响因子与NDVI的关系都是简单线性相关的,因此在非线性相关性方面还需要深入探究。
猜你喜欢
戏剧之家(2016年21期)2016-11-23
中国集体经济(2016年27期)2016-11-19
大经贸(2016年9期)2016-11-16
化学教与学(2016年10期)2016-11-16
人间(2016年28期)2016-11-10
人间(2016年28期)2016-11-10
