
基于GIS技术的水文地质及突水预警信息管理系统设计
2019-11-19 06:40包选贵李成林
微型电脑应用 2019年11期
包选贵, 李成林
(青海省柴达木综合地质矿产勘查院, 格尔木 816000)
0 引言
针对煤矿运行过程开展系统研发可以更加高效、准确地对其数据进行分析,为了提高该系统的可靠性与运行速度,应对其数据库进行全面的优化设计[1-3]。由于煤矿产生的数据量非常多,并且各类数据的格式也存在较大差异,因此必须设计更加灵活的数据采集模式才能构建合理的数据库,以此促进煤矿工作效率的提升[4-7]。考虑到数据都是以独立方式在数据库内运行,因此从系统研发的层面分析,应在数据库跟前台操作界面之间构建有效的连接,通过设置专门煤矿信息处理系统来实现各项信息数据的可操作性,同时也可以通过客户端浏览器B/S架构对信息实现远程传输,以此有效管理矿井的各项信息内容,并完成信息的高效分析与共享[8-10]。
构建本系统的目标是为了对数据进行更加高效的管理与分析,因此需设置合适的系统平台[11]。运行系统之前应先全面收集并分类整理各项煤矿信息。在长期的煤矿采掘过程中,大量的水文与地质数据信息将被不断积累,这些都可以作为数据库的数据来源[12]。随着煤矿数据信息量的不断增长,如果依然选择人工管理的方式将会耗费大量的时间与人力管理成本,并且实际数据查询、分类与管理的效率也很低,较易出现错误。同时在开采工作中,所有巷道与工作区域无法实现统一的数据更新过程,即使采取数据的日更新处理也无法满足实时共享的要求。一些早期构建的煤矿,一些通过纸质记录的水害资料以及特定的防治水方案与工艺都未获得充分继承[13-15]。
根据以上分析可知,应结合煤矿的历史资料与信息实时更新的要求,构建煤矿的水文、地质、属性方面的数据库,并与水害空间信息以各项参数建立全面的关联性,更好地实现对突发状况的预防能力,使煤矿的信息管理能力与整体工作效率获得显著提升。
1 设计流程
可以将系统平台的信息内容主要分成如下两种:第一种属于数据信息类型,包含观测与预测共两种数据,如水害状况、煤矿地质、工作面、矿井涌水量等信息;第二种属于图形分布信息,包括巷道的横截面、煤层结构、电阻率断面分布等。
可以把煤矿资料分成空间、时态、属性与文档共4种信息类型。按照煤矿信息的具体特征设计得到数据库流程,如图1所示。
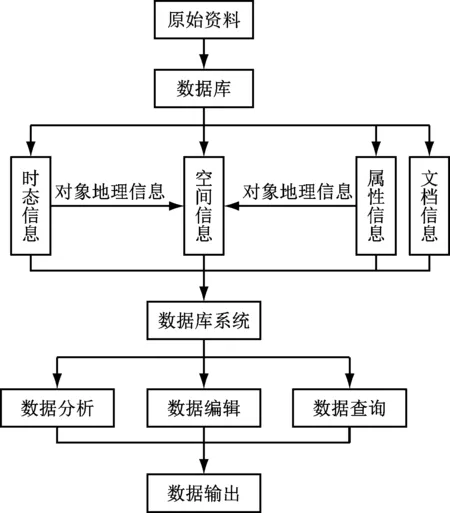
图1 流程设计
其中,空间信息包含了点、线、面各维度对应的地理位置;时态信息中包含了有采掘过程进行实时反馈的数据内容以及各项日常更新内容;在属性信息中含有对不同要素进行描述的信息内容;在文档信息中包含了煤矿的所有文件信息。根据煤矿设计图先完成原始资料的预处理,同时将煤矿设计图的CAD格式转换成mxd格式,再从中提取获得有用信息,将提取得到的信息存入数据库。通过数据库平台可以很方便地调用上述信息内容,之后再对其开展数据分析、管理或查询的操作,并把得到的数据处理结果反馈至平台界面。
现阶段已经获得广泛应用的数据模型主要包括层次、关系、网络与面向对象共四类,本研究重点分析关系型的数据处理过程。煤矿数据通常不属于独立数据,各项属性数据基本都是由空间数据组成,时态数据既可能与属性数据存在关联也可能与空间数据存在联系,在文档信息中则包含了发布时间与文档类型的内容,更有助于实现系统开发的过程。本文选择关系型数据库的方式来构建得到属性表数据库。处理软件为SQL Server2010,通过空间数据引擎 ArcSDE构建得到空间数据和属性数据之间的关系,由此设计得到本文的系统数据库。
2 数据库设计
设计系统数据库时主要包括二个模块,分别是对水文地质的设计以及对避灾与突水预警数据库的设计。 设计水文地质数据库的过程包括整理与归纳煤矿的各类资料,具体设计内容如图2所示。
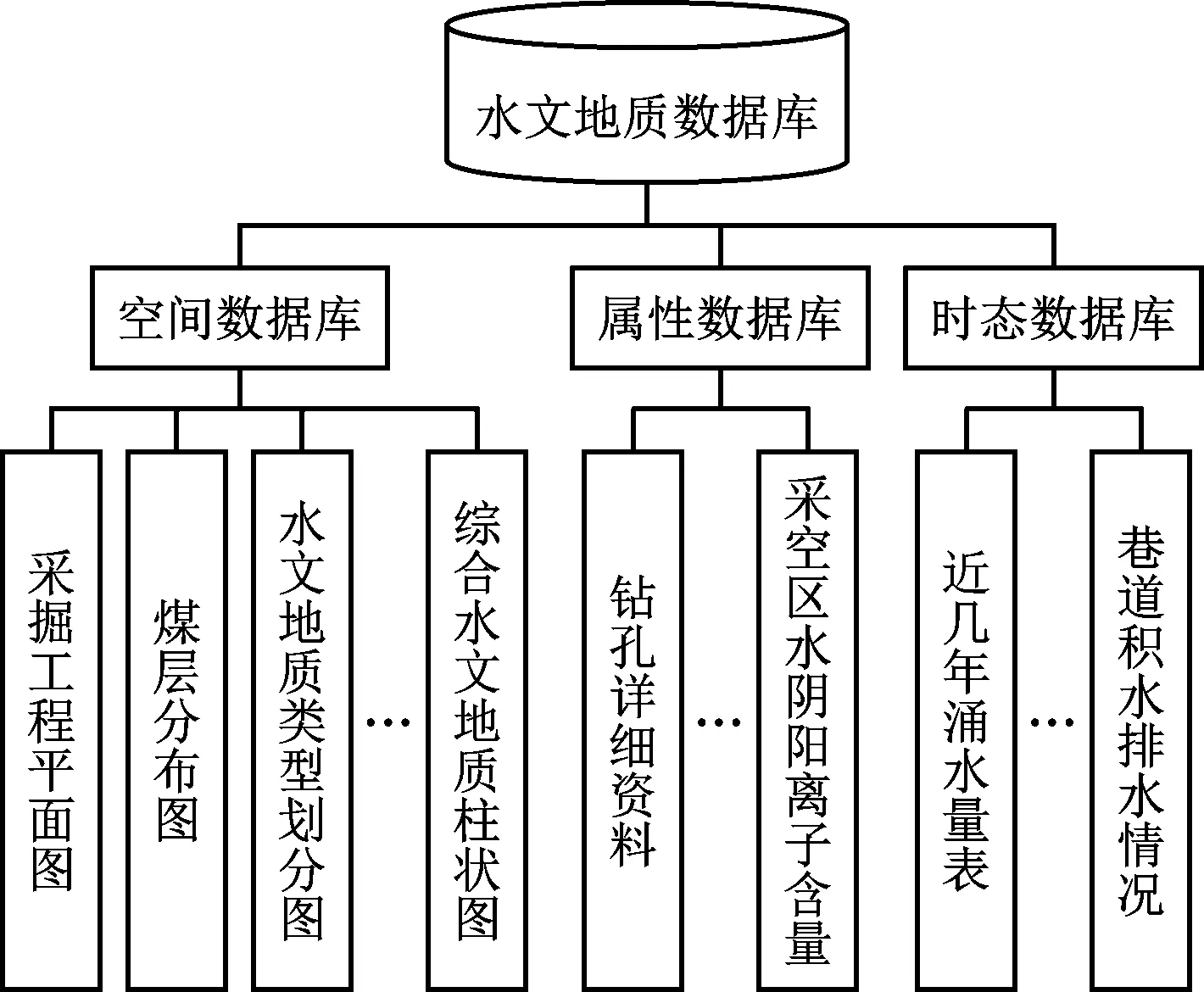
图2 地质基础数据库
2.1 空间数据库设计
(1)数据采集
通过定义各要素空间位置可以得到空间数据。大多数煤矿设计图纸都是属于 AutoCAD 格式,无法建立规范的原始数据,因此在采集空间数据前,必须先转化 CAD 格式的图纸,使其变为GIS数据类型,以此完成对空间数据的提取与存储过程。在系统中进行空间数据存储时,应确保 CAD数据的各项属性与标注保持完好,使系统平台可以高效完成数据处理以及对空间进行分析,从而构建合理的防治水模型。
由于煤矿包含了多种不同的要素信息,数据的存储结构也存在显著差异,这就要求各项素信息按照分层模式进行保存。将钻孔的各项地理信息数据进行抽象化处理形成 Point,再把巷道以及等高线等抽象成 Line,对于工作面则被抽象成 Polygon。上述各类地理信息都按照分层方式进行存储。
(2)数据库建立
对所有图形信息进行收集并按照不同的分层结构进行检查,并根据实际建库标准,把各项信息内容导入Geodatabase中。构建数据库的具体流程,如图3所示。
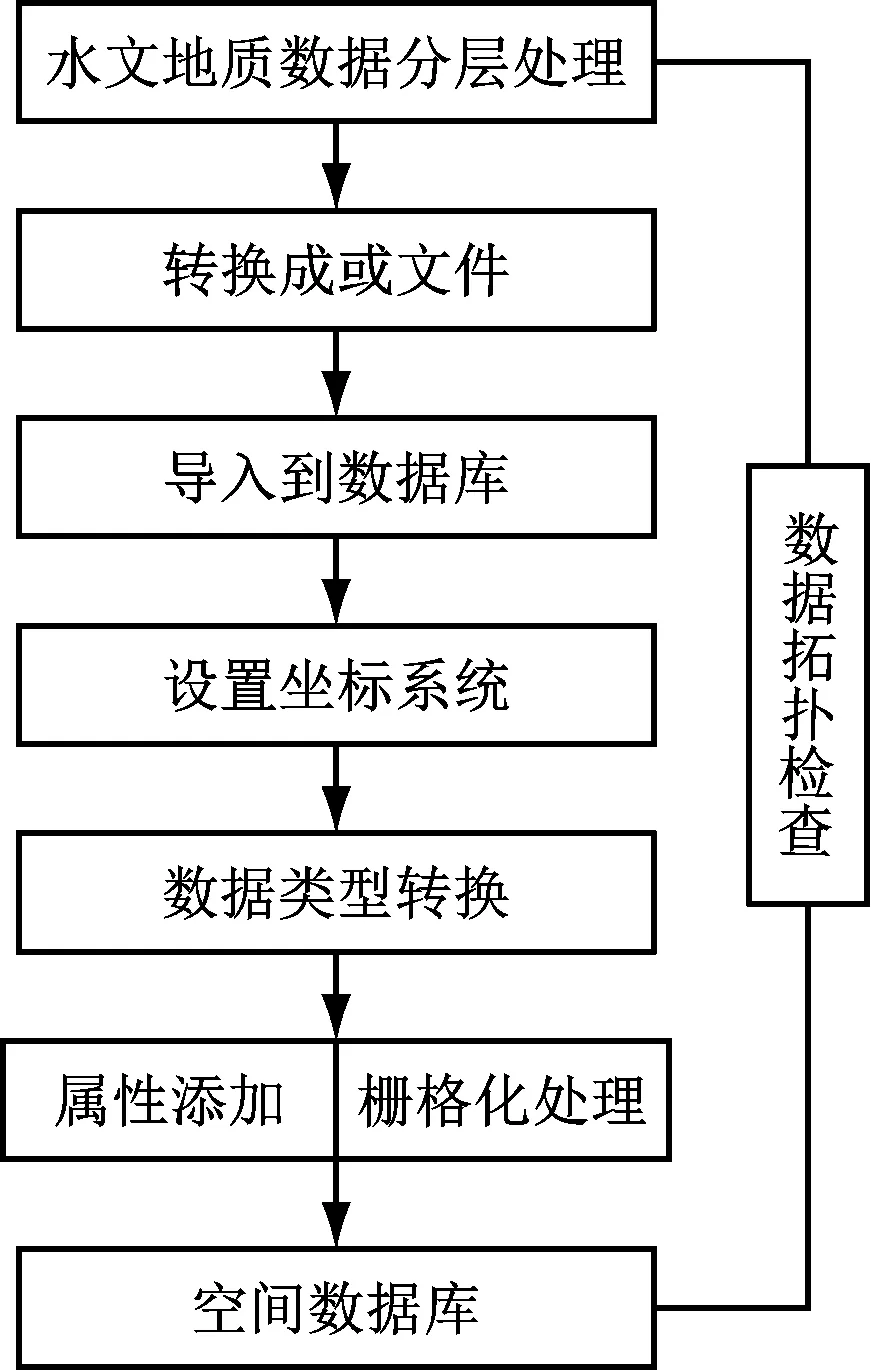
图3 空间数据库建立流程图
2.2 属性数据库设计
根据空间数据得到的空间内容与特性都是属性数据,并以关系表方式进行存储,各项数据记录与图元信息一一对应。利用SQL Server 2010对各项属性信息进行制表后再实施数据存储。其中,属性数据按照如下方式完成存储过程:在数据库制表中直接进行数据存储,使不同数据间形成相互关联;跟空间信息进行对应关系,将数据存储至栅格与矢量文件里,以FID和空间图形信息形成关联,并将其存储至空间数据库内。当定量数据获得确定的数值后,可将其输入到数据库平台中;如果一个数据未获得确定的数值,只有定性分析结果,则可以利用平台来寻找得到合适的数值,之后再将其存储至数据库。
考虑到数据类型存在明显差异,因此对空间与属性数据分别采取单独存放的模式,在属性数据库内含有包含关系表内容的各项记录,并与空间图像形成对应关系。
2.3 时态数据库设计
1)采集数据
按照巷道采掘的具体过程对时态数据进行实时更新,由此获得多种不同类型的图纸与数据。采集时态数据的具体内容包括矿井涌水资料数据、矿井突水资料数据以及历年降水量资料数据,如图4所示。
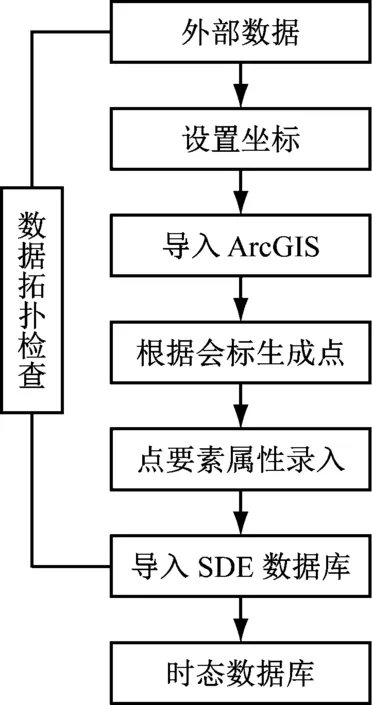
图4 时态数据库流程设计
通过在时态数据和关联空间数据之间建立关联性,使采集获得的时态数据能够对含义进行更全面、明确的表达,构建得到图4所示的时态数据库流程。按照时态信息表构建得到GIS 数据,同时把表格类型与采集得到的煤矿数据换换成图层格式,将结果显示于系统平台界面上以及各类数字图形中,从而更加形象直观的了解空间和属性之间的关系。先从Excel表中选出二列数据作为构建横向与纵向坐标的数据来源,再进行界面设置,确定结果输出路径,再把时态信息表转换成GIS图。
2.4 突水预警及避灾数据库设计
设计突水预警数据库的过程包括了煤矿历史信息以及各项实时信息的防治水、突水预测、最短避灾路径等内容的分析,含有参数、模型、仿真结果、数据类型、文本结构等。设计得到如下二个数据库,如图5所示。
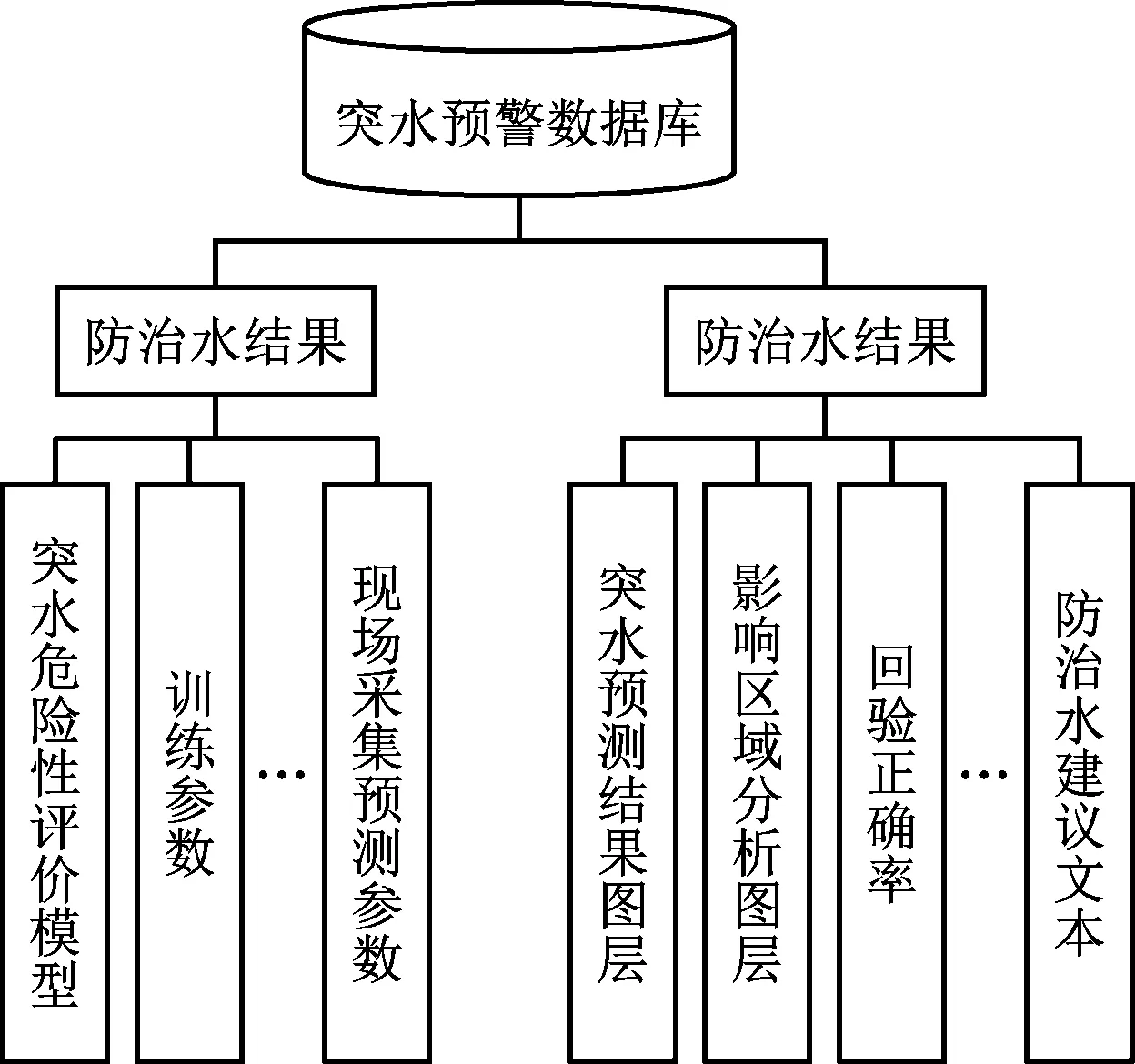
图5 突水预警及避灾数据库
(1)突水预测模型库
该数据库中包含了关于突水的各项数据,具体包括突水历史信息、最短避灾规划模型、巷道线状资料、巷道尺寸、预测模型参数、障碍物分布、矿井位置数据等。并且,此数据库可以完成对各项数据的实时更新,从而实现对采掘工作面情况的精确、快速反映,极大提升预测准确性。
(2)防治水数据库
从防治水数据库中可以获得水害影响区域分布图、突水预测点、回验准确率、避灾通道长度、路线信息等内容。
3 管理系统实现
本文设计得到了以 B/S模式为基础的信息管理系统,如图6所示。
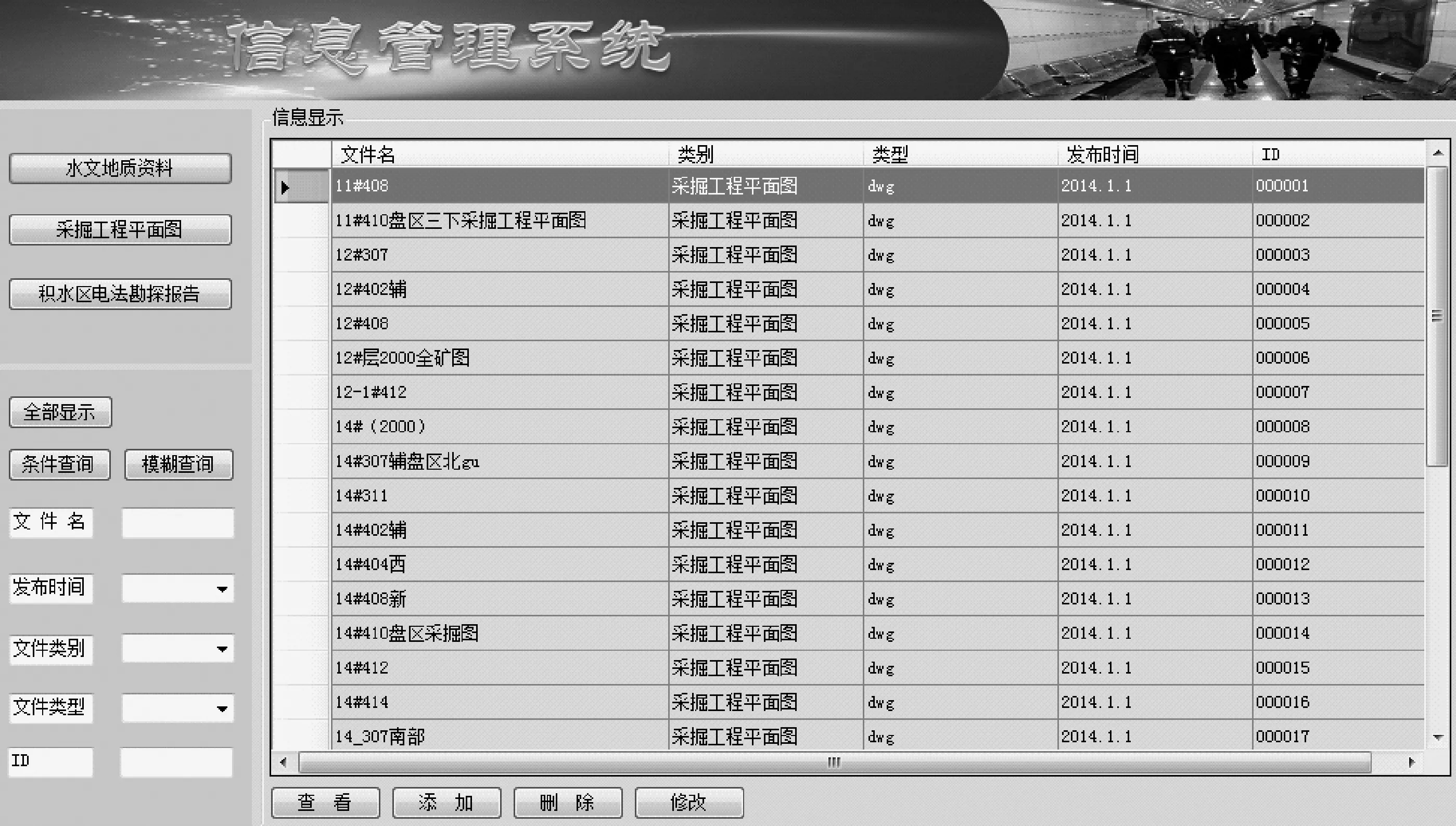
图6 信息管理系统
通过ASP.NET建立UI,对程序进行自定义获得平台的特定功能。在控件中可以通过设置自定义的组件来构建Web Form,从而简化代码,极大减小系统的开发时间。具体步骤为:
(1)先按照前文方法在SQL Server2010中构建时态、属性、突水预警数据库。之后,采用web.confi构建得到SQLServer2010连接方式,并通过测试确定连接是否正常。
(2)利用ADO.NET来完成数据库信息的交互过程。通过SqlConnection 与 SQL Server建立连接,选择 Command 来执行SQL代码,完成数据的新增、编辑、删除等操作,构建高效的通信。利用ExecuteReader方法快速查询满足程序运行要求的数据,再将其填充到 DataReader中。DataSet可以暂时存储DataAdapter通过查询数据库获得的结果,之后关闭 Connection,因此不必跟数据库之间构建实时连接。
(3)显示结果集。通过数据表来显示记录与查询数据。其中,列对应fields,行对应records。GridView 可以实现分页的功能,从而简化代码。
(4)以程序自定义操作方式获得目的结果集。根据结果集来处理记录信息,同时完成各类格式资料的归类、新增、编辑、删除,可以利用不同方式查询记录,达到灵活管理煤矿水文资料的效果。
(5)连接中断。通过close使数据库断开,通过自定义程序操作ADO资源,并将其分配至别的平台。
(6)开发得到网站后再对Web 应用程序进行编译,从而提升程序运行安全并优化效率。待正确编译后再发布,便于用户访问。
4 总结
结合煤矿的历史资料与信息实时更新的要求,构建煤矿的水文、地质、属性方面的数据库,与水害空间信息以各项参数建立全面的关联性,并展开管理系统实现实际应用。该系统更好地实现对突发状况的预防能力,使煤矿的信息管理能力与整体工作效率获得显著提升。
猜你喜欢
矿业安全与环保(2022年1期)2022-03-25
煤矿安全(2021年11期)2021-11-23
家庭影院技术(2021年2期)2021-03-29
航天标准化(2020年4期)2020-03-03
炎黄地理(2019年1期)2019-09-10
海外英语(2013年4期)2013-08-27
新高考·高三英语(2013年5期)2013-08-20
中学英语之友·中(2008年2期)2008-04-01
