
融合字词模型的中文命名实体识别研究
2019-11-18 02:44:04殷章志李欣子黄德根李玖一
中文信息学报 2019年11期
殷章志,李欣子,黄德根,李玖一
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
命名实体识别在自然语言处理中扮演着非常重要的角色,是信息抽取、信息检索、机器翻译、问答系统等自然语言处理任务的基础,其主要任务是识别出文本中的人名、地名、机构名等专有名称并对其进行分类。
命名实体识别常用的机器学习方法包括隐马尔可夫模型(hidden markov models,HMM)、最大熵(maximum entropy,ME)、支持向量机(support vector machine,SVM)、条件随机场(conditional random field,CRF)等,这些方法需要人工提取特征,特征选择对识别的结果有很大的影响。文献[1]先采用底层隐马尔可夫模型识别出无嵌套的命名实体,然后采取高层隐马尔可夫模型识别出嵌套了人名、地名的复杂地名和机构名,该方法使用层叠隐马尔可夫模型,在大规模真实语料库的封闭测试中取得了良好效果;文献[2]提出了一种基于最大熵模型的命名实体识别方法,它使用来自整个文档的信息对每个词进行分类,证明了最大熵模型能够直接利用全局信息;文献[3]使用基于SVM和CRF的双层模型对中文机构名进行识别,第一层采用CRF识别简单机构名,第二层采用基于驱动的方法,将SVM和CRF结合进行复杂机构名的识别,最后合并两层的识别结果,取得了较高的精确率和召回率;文献[4]介绍中文命名实体识别的研究工作,通过研究汉字特征设计特征模板并对不同的特征集进行了讨论,在优化的特征条件下使用CRF进行中文命名实体识别。机器学习的方法对特征选取的要求较高,需要选择与命名实体识别任务相关联的各种特征,而特征的选取依赖于人们的专业领域知识,特征选取的质量好坏对识别结果有重要影响。
近年来,随着神经网络在图像和语音领域的成功应用,深度学习也被越来越多地应用到自然语言处理任务中。深度学习可以自动学习句子特征,不需要人工干预,因此基于深度学习的命名实体识别方法受到广泛关注。文献[5]提出一个统一的深度神经网络(deep neural network,DNN)结构,在不需要人工提取特征的情况下,该结构在序列标注等任务上取得了良好效果。命名实体识别是典型的序列标注问题,而循环神经网络(recurrent neural network,RNN)可以有效地利用序列信息。文献[6]提出BiLSTM-CRF来进行命名实体识别,通过双向长短时记忆网络(bidirectional long short-term memory,BiLSTM)可以有效地学习句子的上下文信息,CRF层可以考虑到标签的依赖信息,使得标注过程不再是对每个词单独分类;文献[7]提出基于字的BiLSTM-CRF并用于中文命名实体识别,在第三届SIGHAN Bakeoff[8]评测任务的语料上取得了良好效果。
使用BiLSTM-CRF进行中文命名实体识别有基于字和基于词两种方法。基于字的命名实体识别方法不需要对文本进行分词,减少了未登录词的数量,一般通过改进输入层的向量特征或者加入词性及字形等信息来改善识别效果,但字所包含的语义信息没有词丰富,存在语义信息不足的问题。在基于词的命名实体识别方法中,要先对句子进行分词,分词结果会对识别性能造成影响。现有的方法多是使用单一模型进行命名实体识别,在对字词信息进行结合时,一般将字送入神经网络训练得到隐层向量拼接在对应的词向量后面,从而对基于词的命名实体识别方法进行改善。为了将基于字和基于词的方法进行有效结合,改进单一模型的识别效果,该文提出了一种融合字词BiLSTM模型的命名实体识别方法,该方法将字模型(Char-NER)和词模型(Word-NER)作为基模型,训练得到Char-NER和Word-NER中投影层的分值向量,将它们运算后拼接送入最终模型,进行训练得到标注结果。我们分别在1998年《人民日报》和MSRA语料上进行了实验,在不需要人工特征的条件下,实验结果表明该方法较基线系统有较大提高。
1 命名实体识别算法模型
模型融合的思想是将多个基分类器C1,C2,…,Cm预测的结果进行组合,通过一些算法来生成最终性能更好的分类器C。有许多不同的方法可以将基分类器进行有效组合。最简单的方法就是投票,对于每个分类器都有输出的预测类别,投票就是把基分类器预测最多数量的类别作为最终类别。投票可以扩展为加权投票,给每个基分类器分配一个权重,最终返回具有最高总预测权值的类别。其他的融合方法还有Bagging[9],通过每次从样本中选取不同的训练集来训练得到不同的模型,最后再将这些模型进行融合。
融合字词模型的命名实体识别标注框架如图1所示,该框架主要由三部分组成: 基于字的BiLSTM-CRF模型(记为Char-NER)、基于词的BiLSTM-CRF模型(记为Word-NER)、融合Char-NER和Word-NER两个模型的最终分类器。
1.1 单一模型框架
该文使用的模型融合方法将基于字的BiLSTM-CRF和基于词的BiLSTM-CRF作为基模型。为防止过拟合,训练集分为两部分T1和T2,T1用于训练基模型,把T2送入训练好的基模型中得到字模型和词模型各自投影层的分值向量,对分值向量进行运算后拼接作为特征送入最终模型进行训练。
为验证模型融合方法的有效性,本文将词模型与字模型的模型架构设为一致,以字模型为例,如图2所示。该模型一共有4层,向量映射层、BiLSTM层、投影层和CRF层。
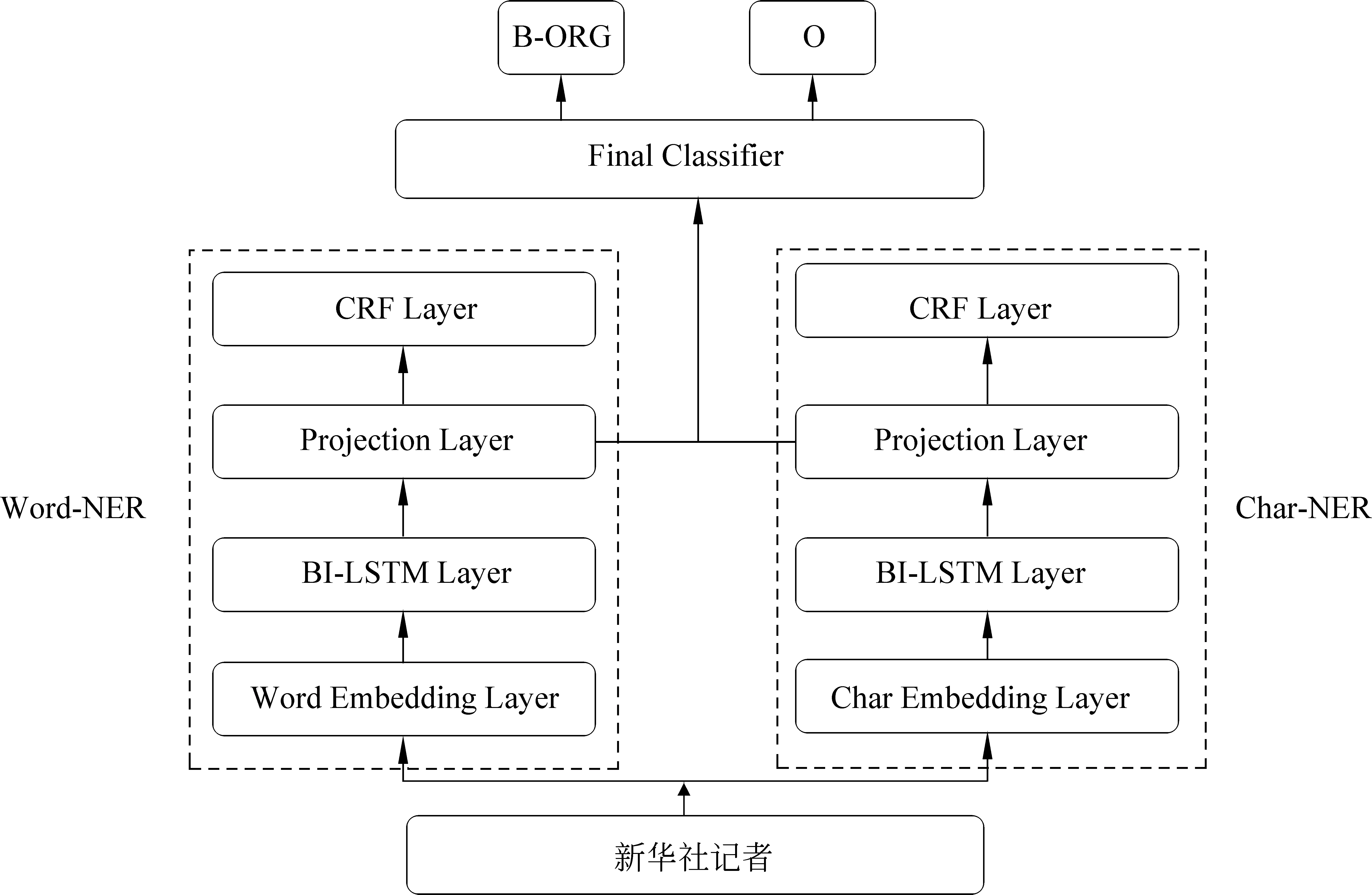
图1 融合字词模型的NER标注框架
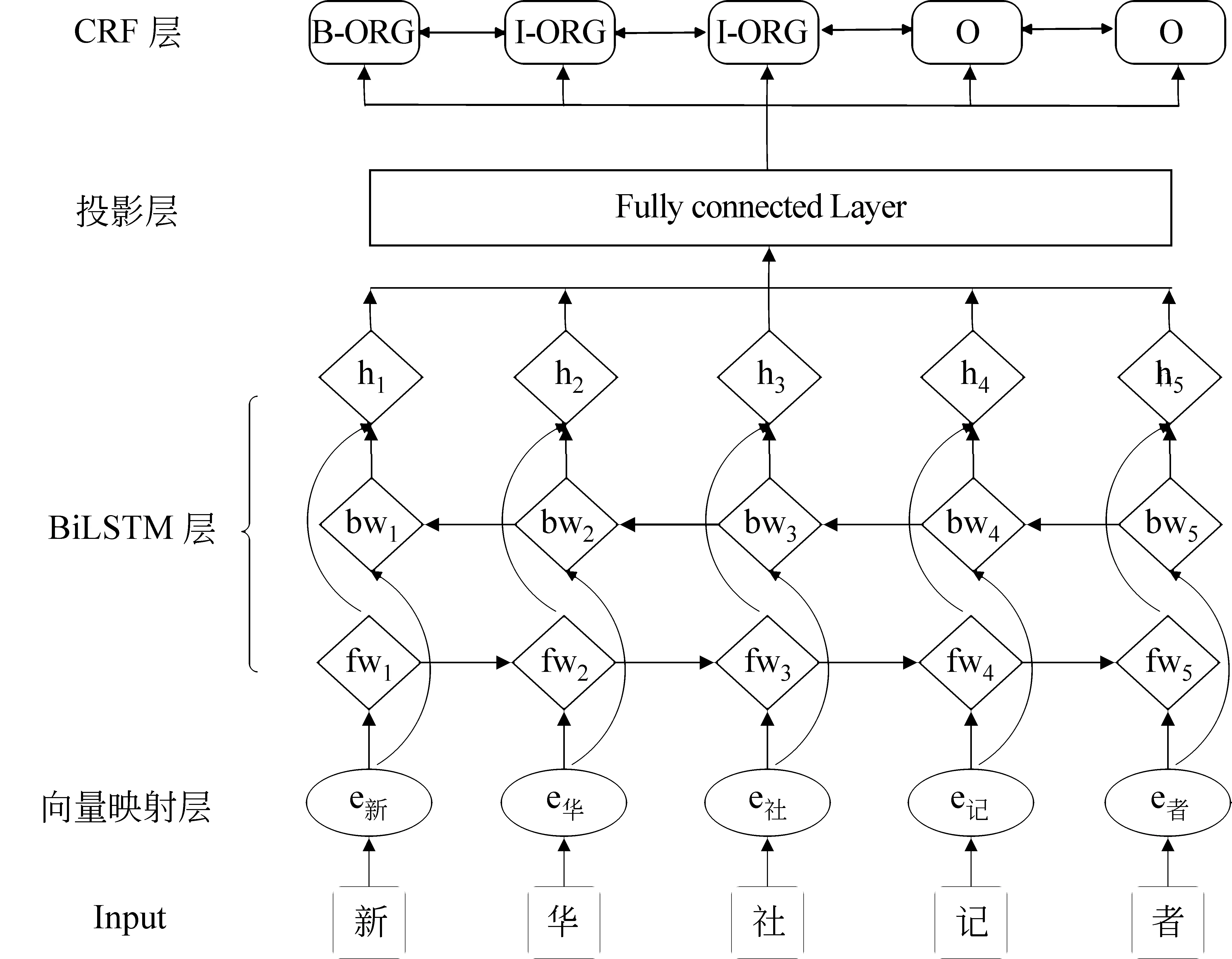
图2 基于字的BiLSTM-CRF识别模型
向量映射层将词表中的字映射为低维稠密向量,输入一个字的序列c1,c2,…,cn,对于字cj可以表示如式(1)所示。
(1)
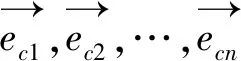
(2)
其中,⊕表示向量拼接。投影层是一个全连接神经网络,目的是为了将BiLSTM得到的d维向量转换成维度与定义好的标签数量相等的k维向量。模型的最后一层是CRF层,通过维特比算法解出最优序列,为整个句子打出标签。本文使用的是BIO标注方法,B代表实体的开始部分,I代表实体除开始之外的后续部分,O代表的是非实体。B-PER、I-PER对应人名开始和后续部分,3种实体有6个标签,加上非实体标签O共7种标签。CRF层可以利用上文已经预测的标签,避免了出现B-PER后面紧跟着I-LOC这种不合理的情况。
1.2 字词模型融合
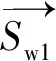
2 实验与分析
2.1 数据集
本实验所用的数据集为1998年《人民日报》1月份的标注语料和2006年SIGHAN中文命名实体识别评测的MSRA语料。语料规模如表1所示。

表1 语料介绍
2.2 实验设置
实验中的字向量随机初始化生成,词向量使用skip-gram模型在1.42 GB的搜狗新闻语料上训练生成。实验中基于字的识别模型和基于词的识别模型的超参数设定为同样的值,具体的超参数设定值如表2所示。
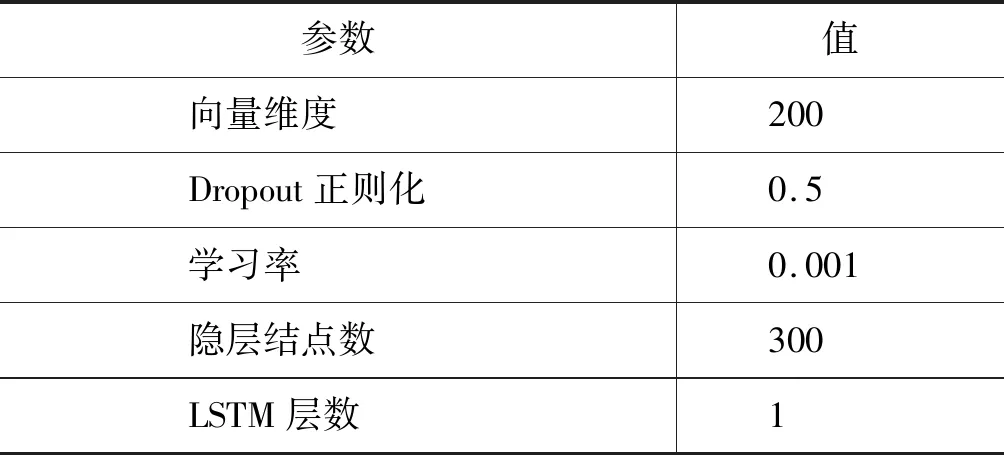
表2 超参数设置
2.3 实验结果及分析
为了验证融合字词模型标注框架的有效性,分别在《人民日报》和MSRA两个数据集上进行实验,基于字的命名实体识别模型记为Char-NER,基于词的命名实体识别模型记为Word-NER。基于分类的融合方法包括支持向量机、贝叶斯推断、Dempster-Shafer理论(DS)、动态贝叶斯网络、神经网络等[10],本文尝试选取朴素贝叶斯、深度神经网络、支持向量机作为融合模型的最终分类器进行对比实验,分别记为Ensemble-NB、Ensemble-DNN、Ensemble-SVM,实验结果如表3所示。
实验结果显示: 在《人民日报》语料上,Word-NER的效果比Char-NER稍好;在MSRA语料上,Word-NER人名和地名识别的效果较Char-NER略差,其主要原因是MSRA语料中没有将每个词标注出来,其词信息是通过自动分词工具获得的。而通过字词模型融合之后,融合模型的方法在人名和地名上的识别效果均获得明显提高。
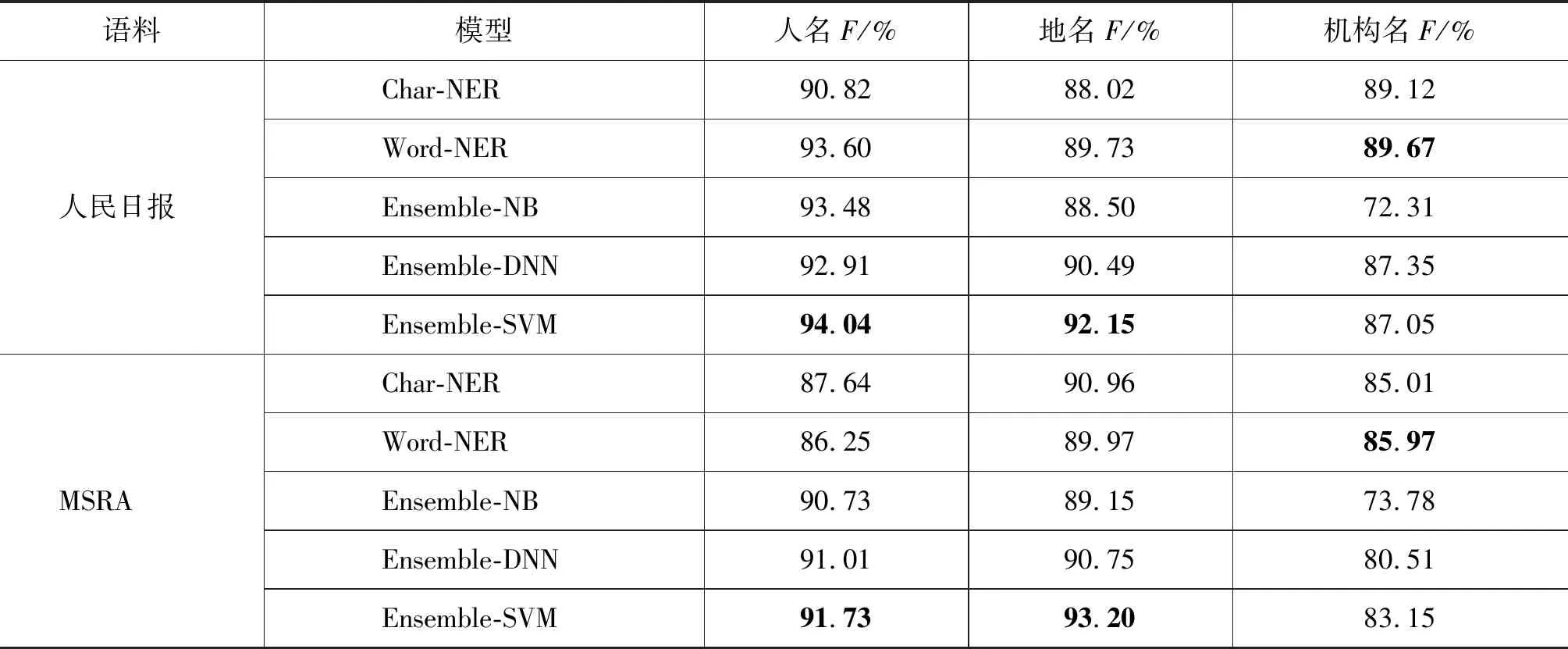
表3 《人民日报》和MSRA实验结果
通过实验可以看到,在融合模型的方法中,人名和地名识别效果最好的是Ensemble-SVM,Ensemble-SVM不论是在《人民日报》语料还是在MSRA语料上对之前结果都有所提高,尤其在MSRA语料上的提高幅度更大。
对实验结果进行分析发现,在词模型和字模型中都正确识别的命名实体,在字词融合模型中也可以被正确识别,在字模型和词模型中有一个识别正确,另一个识别错误的情况下,字词融合模型通过对字词信息的有效结合可以对错误的结果进行修正。在单一模型中,字或词在投影层的输出是一个维度等于标签数的向量,该字或词属于哪个类别由向量中最大的值所在的维度决定,在这种情况下,字或词的分类结果仅由向量中的某一维度决定。在字词融合模型中,利用式(3)、式(4)对它们进行运算拼接后,在词模型的投影层向量中加入了字模型的得分信息,拼接之后得到的是一个维度等于标签数乘2的向量,词的分类结果由向量中更多的维度所决定,此时该向量中的类别特征信息更加丰富,将该向量作为新的特征输入最终模型中进行训练,会使得整体模型的泛化能力更强,获得更好的识别效果。
实验结果还表明,Ensemble-SVM对人名和地名F值的提高效果比较明显,但是对于机构名的识别效果有所下降。这是因为Ensemble-SVM的最终模型使用的是分类算法,对各个标签进行标注时是相对独立的,没有利用序列中标签之间的依赖信息。而Char-NER和Word-NER的解码层使用CRF模型的转移概率矩阵对标签进行约束,从而降低非法标签序列出现的概率。本文将由3个或3个以上词组成的机构名作为长机构名,其他作为短机构名。对《人民日报》的测试结果进行统计分析,其中长机构名335个,预测出273个,正确的有248个,短机构名590个,预测出601个,正确的有535个。实验结果如表4所示。
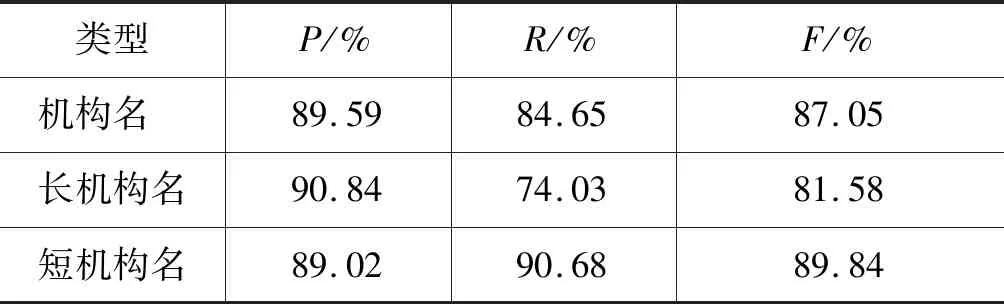
表4 长、短机构名的实验结果对比
从表4可以看出,模型对长机构名的召回率比较低,导致了整体机构名F值下降,而对短机构名的识别效果在精确率和召回率上都可以保持比较稳定的效果。长机构名一般由多个词组成,对该类实体进行标注时,有一处标签预测错误会导致整个实体识别产生错误。此外,长机构名往往嵌套地名,由于分类模型对每个词进行单独预测,只根据该词对应的标签分数进行标注,没有考虑该词是否与上下文中的词构成嵌套关系。因此,字词融合模型对机构名的识别效果没有单一模型的识别效果好。
2.4 与现有其他方法的对比
2.4.1 1998年《人民日报》语料
表5给出了在《人民日报》语料上与其他文献中实验方法的结果对比。我们和现阶段比较好的方法进行对比,在使用人工特征的方法中,文献[11]通过制作特征模板用CRF进行训练,通过手工提取丰富特征,如词性、语义、实体标记等,在人名、地名、机构名上分别达到了93.97%、91.49%、84.67%的F值。在不依赖人工特征的方法中,文献[12]使用深度信念网络进行实体识别,在训练语料上无监督地学习出词和词性特征的分布式表示,然后输入到构建的6层深度神经网络中,最后人名、地名、机构名的F值分别是90.48%、89.66%、88.61%。本文所提方法在未使用任何人工特征的情况下,在《人民日报》语料上取得了较好的效果。
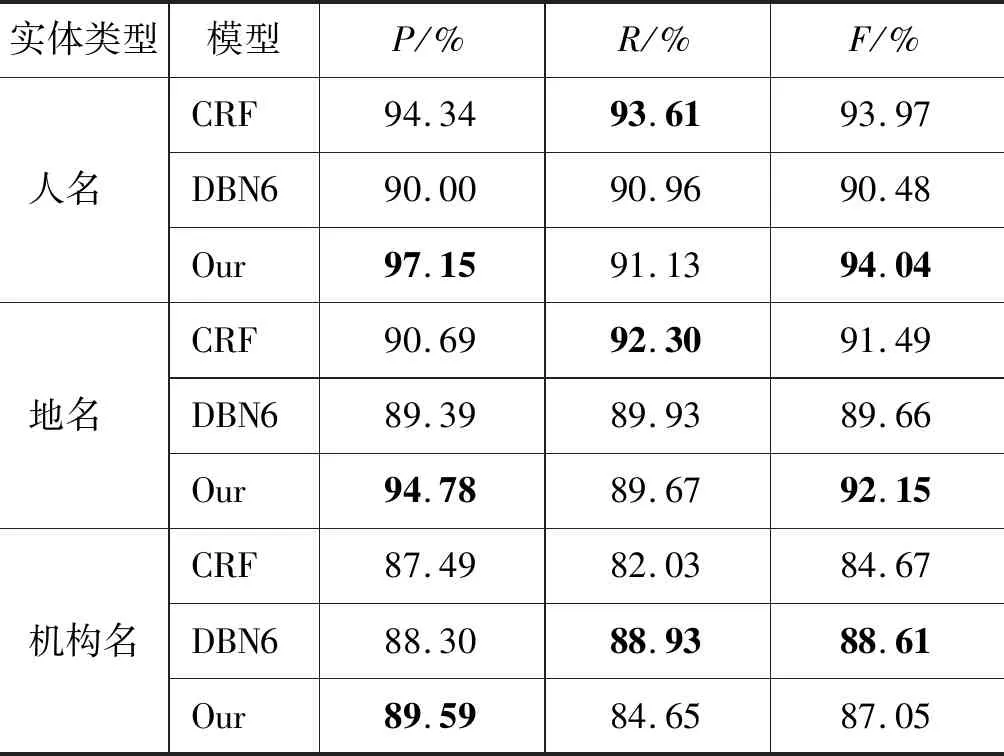
表5 在《人民日报》语料上的实验对比
2.4.2 MSRA语料
为了验证本文方法的泛化能力,我们选择与Zhou等的实验结果进行对比。表6给出了在MSRA语料上与其他模型的对比实验结果。文献[13]首次提出基于词的CRF模型和使用大量精心制作的特征,在MSRA语料上达到了86.51的F值。文献[14]的方法针对片段级中文命名实体识别进行研究,联合使用多种不同的特征模板,在MSRA语料上获得了较好的性能。这两种方法都基于传统的统计学习模型,依赖人工特征设计和专业知识。文献[15]为了减弱系统对人工特征设计的依赖,采用深度学习片段神经网络结构,实现特征的自动学习,在MSRA语料上对人名、地名和机构名识别的总体F值达到了90.27%。实验结果显示,与以上方法相比,本文提出的融合字词模型的命名实体识别方法获得较好的系统性能,在人名和地名识别结果上比最好的系统分别提升了1.04%、0.35%。

表6 在MSRA语料上的实验结果对比
3 结论与展望
中文命名实体识别是中文自然语言处理领域中的重要基础任务之一。针对这一任务,本文在BiLSTM-CRF神经网络模型的基础上,提出了一种融合了字词BiLSTM模型的命名实体识别框架,该框架将模型融合方法用于序列标注任务中,并对不同粒度的标注模型进行融合,将基于字的标注模型和基于词的标注模型融合在一起,有效结合了文本中的字信息和词信息。在此基础上,使用SVM作为融合方法的最终模型,在不需要任何人工特征的条件下,有效改善了单一模型的识别效果。
从实验结果还得出: 本文方法对人名、地名的识别效果均有较大提高,而由于机构名一般由多个词构成或嵌套有地名,融合字词的模型没有考虑相邻标签之间的关系,导致融合字词BiLSTM模型的方法在机构名的识别上没有基于字的BiLSTM-CRF模型效果好。
在下一步的工作中,我们将继续研究对字词融合模型的改进,探究更有效的最终分类器使得融合模型的泛化能力更好。可以通过改进最终模型或者融入篇章信息,提高对长机构名的识别效果,从而获得更好的识别性能。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
中国外汇(2019年18期)2019-11-25 01:41:54
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
