
基于词频逆文档频统计的词汇时间分布层次
2019-11-18 02:43:58饶高琦李宇明
中文信息学报 2019年11期
饶高琦 ,李宇明
(1. 北京语言大学 汉语国际教育研究中心,北京 100083;2. 北京语言大学 语言资源高精尖创新中心,北京 100083)
1 时间分布层次
在现代汉语演变的历程中,词语的使用受时间影响的程度不一,表现为词语在时间维度上的分布不同。饶高琦等[1]称词语间的这一差异为词语的时间敏感性。以时间敏感性的高低对词汇系统进行分层,由内及外时间敏感性逐渐增强,可以构成词汇时间敏感性的层次系统。本文称该层次系统为“时间分布层次”。
词汇系统中很多词语十分稳定,受时间影响很小。它们构筑了现代汉语(词汇)的底层,也是时间分布层次的底层。由于受时间影响很小,这部分词汇更新和变异十分缓慢,对于一种语言起到基础和主干的作用。本文将这些词语组成的词汇称作历时词汇系统的“基干层”。与之相对,众多词语的使用情况与其所处的时代较为相关,新陈代谢很快,不构成语言生活的基础和主干。它们分布于时间分布层次中基干层以外的诸层次。
目前学界在词汇的历时研究中,将词汇一体处理,缺乏分层和分类。语言的每一个共时切面中观察到的词汇是多个历时层次混合的结果。对“新词新语”的众多研究和对文言成分的研究[2]看似是时间上的两极,但实质上都是对汉语词汇时间分布层次中较易变化的一层的研究。对稳态词[1,3-4]则是面对词汇时间分布层次中的最稳定底层的研究。但目前的研究中并未有意识地从时间维度上对词汇进行系统的分层或分类。
本文在饶高琦等人抽取基干层词汇的基础上,对基干层外的词汇进行时间分布层次的划分,并分析其诸特征。本文使用GPWS通用分词系统并辅之以人工修正对历时语料库进行分词。
2 时间分布层次的划分
饶高琦等[1]发现 TF-IDF方法较之其他统计方法较适合描述词语的时间分布情况。TF-IDF方法本质上是对纯粹词频的修正,其修正方式在于通过IDF值引入了词分布的广泛程度。显然频率相同或相近的两个词中,分布更广泛的词所包含的信息量少,反之亦然。而分布更窄的词对于了解其所在文档的特征具有更大价值。但IDF值的大小很大程度上取决于对整个语料库划分的粗细程度,亦即每份语料的规模。每年语料的篇幅很大,词频波动范围很大。年颗粒度下的IDF取值(0~70),对中高频段的调节作用非常有限。其实验表明以月为颗粒度进行划分对IDF值发挥调节作用较为合适,并使用月颗粒度下的TF-IDF方法经小幅修正,在1946~2015年的70年时间跨度语料[5-6]的220万词汇上获得了规模约3 000词的基干层词集。基干层词集的主体基本上是TF-IDF值的倒序前3 011位,基础词汇和停用词等都在这一层中。本文基于其结果,使用月颗粒度下的TF-IDF值来描述整个词汇使用的稳定性,使用式(1)~式(3)计算取对数后的TF-IDF值。其强弱如图1所示,基本呈现为一个渐变的连续统(横轴为按照月颗粒度TF-IDF降序排列的词序号)。
不同尺度上的TF-IDF曲线变化呈现不同的形态。在3 011词到10 000词段,如果将曲线回归为二次系数大于零的多项式方程,可以获得较高的判定系数R2,即曲线类似于凹二次曲线,如图2(a)所示;在10 000词到5 0000词段,多项式回归中的二次项系数接近于0,其判定系数R2与线性回归方程一致,即曲线平直接近于直线,如图2(b)所示;在50 000词以上段,多项式回归的判定系数R2超过线性回归,但此时方程的二次项系数小于零,即曲线类似于一个凸二次曲线,如图2(c)所示。
根据曲线回归方程划分层次是对拐点观察法的量化和改进,以R2判定系数0值为不同区域的分界。根据TF-IDF曲线的变化,本文把3 011词到10 000词视作为一层,将10 000词到50 000词视作一层,将50 000词以上视作一层。在第3节中,本文将以历时文本分类的性能、词类分布、词长分布、覆盖率和词语生命力五个方面对以上分层进行考察,以对基干层/稳态词之外的诸时间分布层次进行佐证和分析。其中基干层的相关数据均引用自饶高琦等[1]的研究。

图1 语料库中所有词的月颗粒度TF-IDF值按递增排序

(a) 排序3 011~10 000词区域
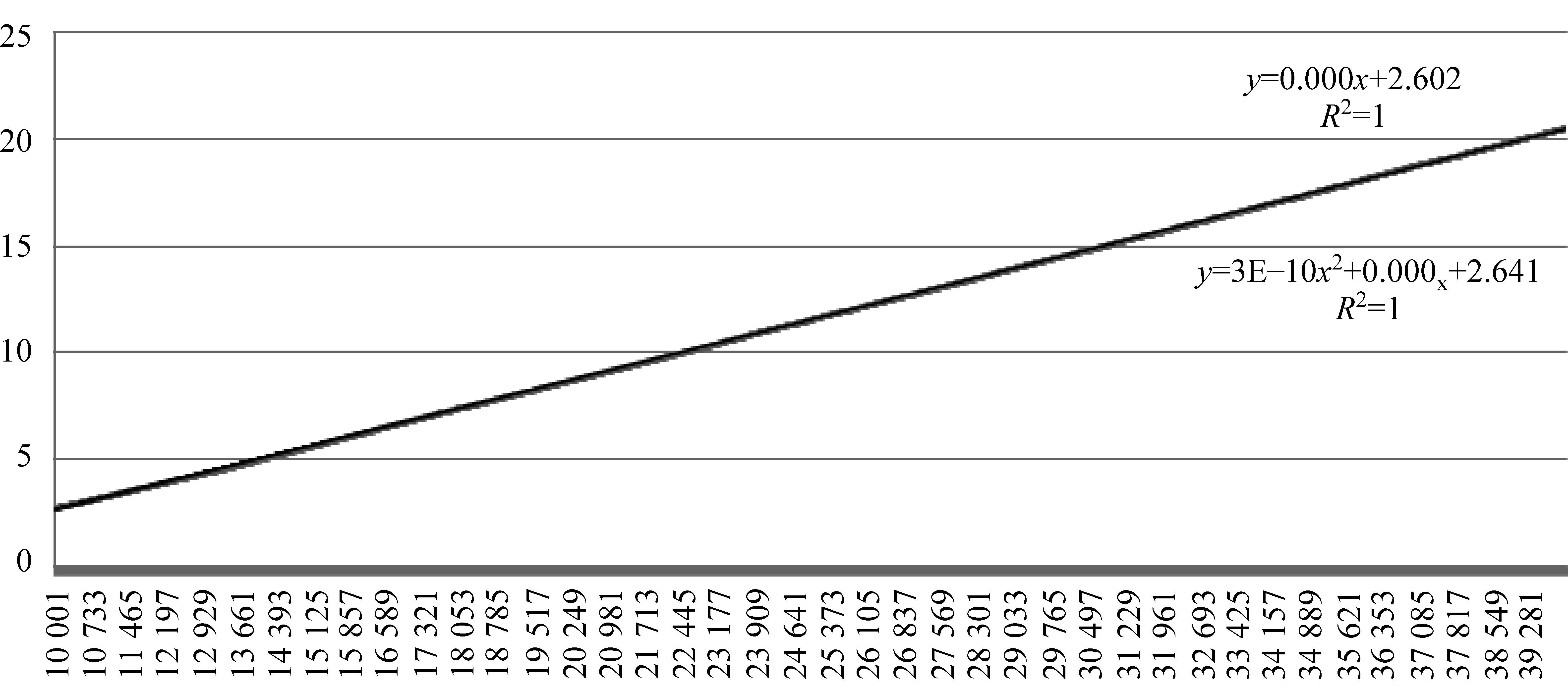
(b) 排序10 000~50 000词区域

(c) 排序50 000~400 000词区(局印)域图2 IF-IDF值排序
3 各词层的性质
3.1 时间敏感性
不同分层中词的时间敏感性不同,即反映时间特征的程度不一。本节使用历时文本分类这一任务来考察不同层次词汇的时间敏感性。时间敏感性较强、反映时间特征较好的词语作为特征,对历时文本分类应有较好的贡献。如对年颗粒度的时间变化较敏感的词语对年颗粒度的历时文本分类应有较好贡献。
在历时语料库中均匀选取五分之一的年份(共14年),每年选取2 000词的文本20篇,共280篇,56万词作为文本分类任务的测试数据集。实验中去除频次为1的超低频词。按照月颗粒度下TF-IDF值的排序,将前70万词按照序号分为6组: 3 011~10 000词、10 000~20 000词、20 000~50 000词、50 000~100 000词、100 000~300 000词和300 000~700 000词。总体而言,排序较为靠后的词词频较低,出现在测试集中的可能性显著减小,因而越靠后的分组词量越大,以平衡越发严重的数据稀疏现象。
在针对每组词语进行的实验中,本节以测试集里出现的该组词语为特征(各组词作为特征独立进行分类实验,并不叠加),其在测试集出现的频率为特征值,使用朴素贝叶斯分类器(1)使用数据挖掘平台weka构建。对测试集中属于14个不同年份的280个文档(56万词)进行分类。为控制计算成本,将频次为1的超低频词去除。实验采用10%交叉验证。各组词作为特征的分类精确率如图3所示。

图3 各分组的文本分类精确率(横坐标为该分组中排序最后词的序号)
随着词序增加,第一、二、三组的精确率小幅上升。从第四组开始,在排序 50 000词以后的分组精确率出现大幅下降。对此可以做如下解释: 基干层之外,TF-IDF值在一定范围之内的词频率较高,时间特征较为明显。序号 50 000之外的词则由于频率较低,分布范围很窄而不容易出现在测试集中。偶有一些出现某一年份的某文档中,也难以在该年份的其他文档中复现,无法形成统计上的显著性,从而导致分类精度大幅下滑。
3.2 词类分布的差异
本部分统计了各组词中的词类分布。这里对兼类词的词类使用各词类频次所占比例为加权进行了修正。结果见表1和图4。本节将人名、地名、组织机构名等也归入了广义的名词。随着序号的增加,名词和数词的比例逐步提升,而形容词、动词与其他(主要是虚词)大幅下降。序号10 000与50 000以后名词和数词的比例大幅增长,而其他词类大幅下降。这也可以成为支持本文将序号50 000作为层边界的理据之一。
在合并了同一层中各分组之后,得到图5。其中50 000词到700 000词的分组代表50 000词以外的部分。随着词序号的增加,词层从内到外名词的比例迅速增大,在第三层中达到最高,数词的变化趋势相仿。而动词、形容词和虚词从内到外比例急剧下降。注意到图5最内层次为3k~10k区间,不包含最稳定、最基础的前3 000词。大部分形容词集中于前3 000词层次,所以这里出现了和动词相比较大的落差。就各层次而言,形容词的占比从内向外快速下降。动词相仿,但下降稍慢。
可以发现和语言结构的组成和变化关系密切的词类时间敏感性都较差: 多数动词是句子组织框架的中心,形容词在汉语中可以充当谓语,虚词则承载有丰富的语法信息。同时动词、形容词和虚词是封闭性的词类,而名词是开放性的词类,其主要功能是表达社会信息,因而在高时间敏感性的层内比重较大。数词本身是封闭性的。但是数词的组合成为了开放性词类,并与名词共同承担社会信息,也体现出了较高的时间敏感性。
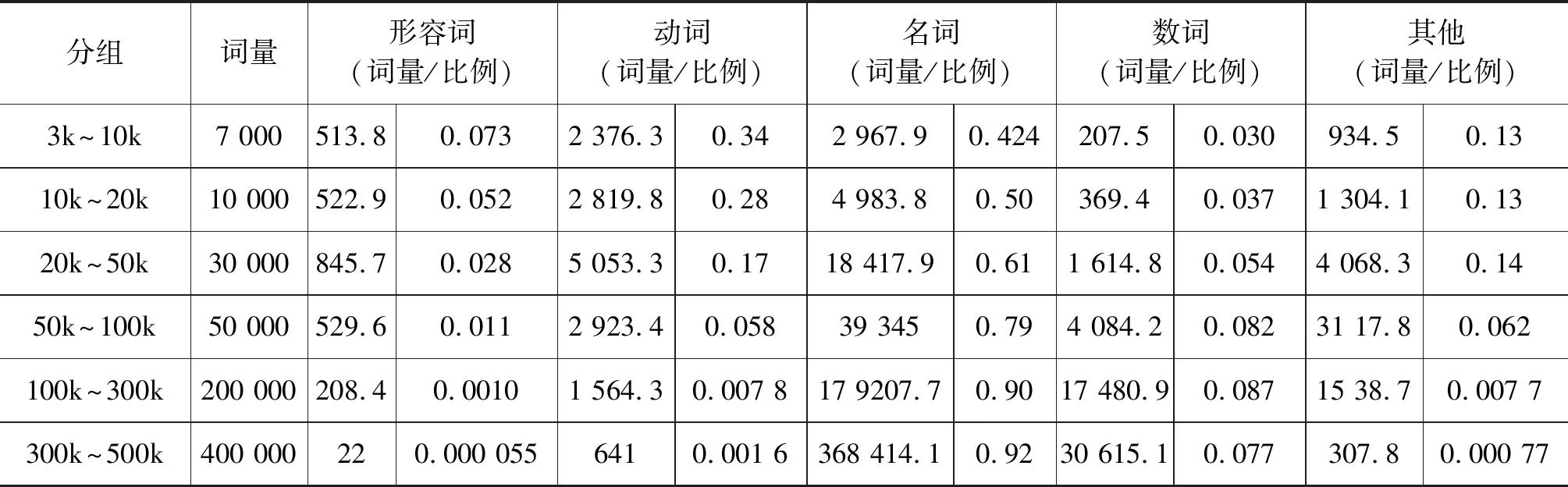
表1 各组词类分布(分组一栏为该组中排序最后的词的序号)

图4 各组词类分布变化(横坐标为该组排序最后词的序号)

图5 各层词类分布变化
3.3 词长分析
对三个不同层次的词进行词长对词次取平均进行计算。如表2、图6所示,针对词种计算的词长分布可以发现,随着词序增长,平均词长逐步增加。三个分层边界上都出现了大幅度的词长变化。序号3 000到7 000这一段,与饶高琦等[1]的基干层词集的平均词长(1.52字)相比也出现了明显增长。序号10 000以后比之前平均多出约半个字。序号50 000以后的平均词长是基干层的两倍多。其原因主要是名词比例的大幅上升,归入名词部分的命名实体较长,如组织机构名。在这一层中增加的数词对词均长的增加也有较大贡献。
随着词序的增加,双音节词比例下降,主体被三音节词取代,四音节和五音节词的比例也出现可观的增长,单音节词几乎消失。如果结合基干层词的词长数据进行分析,由内到外双音节词的占比经历了先增后降的变化。
3.4 语料覆盖率
本节对各层次所包含的词汇进行了语料库覆盖程度的分析,如图7所示。基干层词虽然只有3 011个,但是对语料库的覆盖超过了四分之三。3 000词到10 000词一层则覆盖了剩余部分的一半。序号50 000以后的词量虽有200余万,但只能覆盖整个语料库的2.26%。

表2 各层平均词长及词长分布(词次计算)

图6 各层的平均词长分布和各长度词汇的分布(词次计算)

图7 各层词汇对全部语料库的覆盖率(%)
3.5 词语的历时生命力曲线考察
张普[3]曾经指出“依据词语的曲线特点可以构成不同类型的曲线特征,依据不同特征的曲线类型,对词汇进行分类研究,也许我们会形成一门新的‘词汇曲线类型学’”。刘长征[7-9]根据跨度29年的《深圳特区报》语料,将词汇的历时生命曲线按照出现零值点的情况分为“孤点型”“断续型”和“连续型”三类。在考察范围内,只在一个监测时点上出现的词语为“孤点型”,在某几个监测时点上出现零值点的为“断续型”,在监测的时间范围内无零值点的则为“连续型”。本节借用该分类系统,以词汇在诸年度的频次对其“生命值”进行估计,对词汇分层系统中各层词汇进行生命力曲线分析。
由表3可知,诸类型的生命曲线在各分层中的分布差异明显。“孤点型”词语只在最外层出现,并占有七成比重;“断续型”词语在基干层极少出现,仅有两例,随着TF-IDF排序增加而迅速增长,在第三层出现高峰(占比91.8%),在第四层回落到占比三成;“连续型”词语则从基干层中占比99.9%,迅速下降到第三层的8.2%,在第四层完全消失。在三种类型词语的分布变化中,第二层起到了基干层和第三层间的过渡作用。在各类型词语的分布中,四个层次差异明显,这从一方面印证了分层的合理性。虽然通过TF-IDF值无法反映刘长征研究中所划分的“成长型”“衰减型”“凸起型”和“凹陷型”等具体走势,但TF-IDF值揭示了词语在历时语料中的分布的平均情况,是对词语在历时生命曲线进行的再次抽象,即以数值表征其生命力曲线的类型。因而本文的工作是对张普[3]所构想的“词汇曲线类型学”在词汇层面上进行的整体研究。
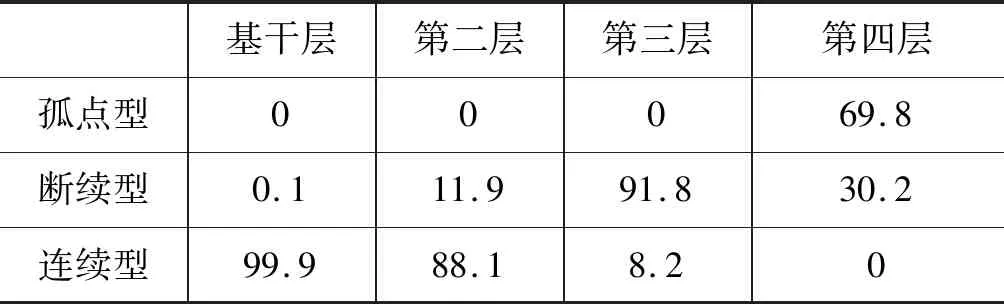
表3 各层词汇中诸历时生命曲线类型占比(%)
4 词汇时间分布的四分层体系
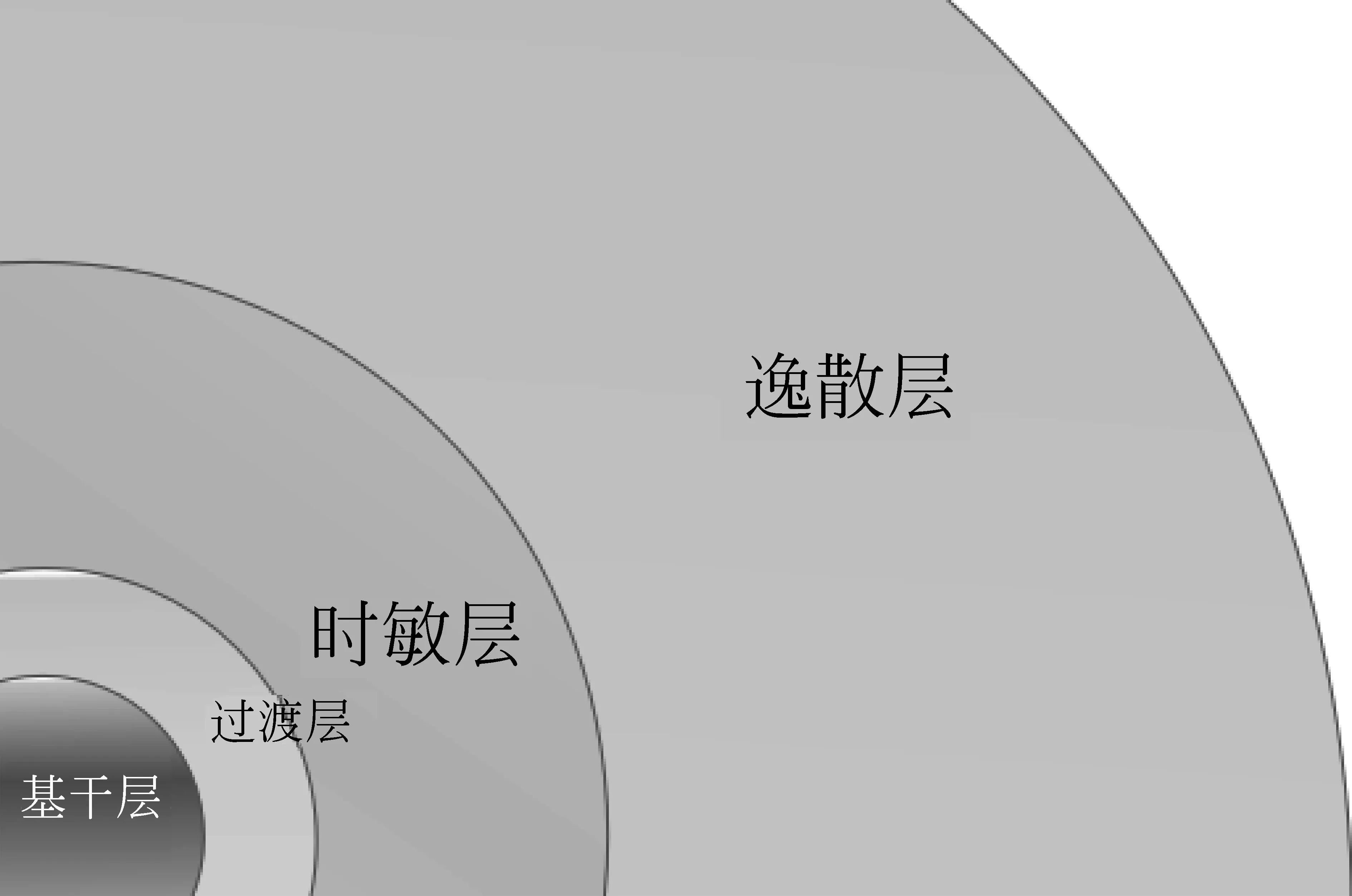
图8 词汇分层体系的简要示意
按照词在月颗粒度下TF-IDF值增序,将序号3 011到10 000这一层称作过渡层,序号 10 000到50 000的部分称作时敏层,序号50 000之外的部分称作逸散层,示意如图8所示。相较于基干层,过渡层体现出一定的时间敏感性,但弱于时敏层,因此得名。它是无时间敏感性的基干层与较高时间敏感性的时敏层之间的过渡区域。这一点也在文本分类实验的结果中得以体现,即属于该区域的分组对不同时间点文本的分类精确率小于等于时敏层。词语历时生命力曲线的考察支持其过渡属性。该层中,词的平均长度较基干层有大幅增长(1.52字到2.08字)。这两层中,双音节词占比基本一致。词长增长的主要原因在于,单音节词占比降低了近一倍,这一份额由三、四音节和更长的词瓜分,如表4所示。

表4 基干层与过渡层词长分布对比(%)
过渡层的词类分布与基干层没有很大的差别。这也说明了过渡层的过渡性质。但名词部分中命名实体开始大量出现,由于命名实体长度通常较长,因而造成了词长增加。时敏层词汇的时间敏感性较强,这一区域词语的使用和分布会随着时间发生较大变化,因此得名。这一区域的词兼顾较高的词频和较窄的时间分布区域,因而在文本分类实验中能够取得最好的结果。同时在词语历时生命力曲线的考察中,该层大部分词语为“断续型”,即具有明显的时期特征。因而“时间敏感”是该层最大的特点,许多时间敏感的社会语言现象多由这一层中的词语构成,流行语和年度词亦多出自此层。词长方面,平均词长较之过渡层有明显增长。在表1所展示的词类分布差异中,名词、数词的占比有可观增长,形容词、动词和其他类大幅下降,因而复杂的语法现象在这一层出现的可能性较小。序号50 000之后的逸散层,虽然有更高的时间敏感性,但词频普遍很低,出现的时间段过窄。大部分词语的历时生命曲线为“单点型”,没有“连续型”词语,这直接影响了该层词汇在文本分类实验中的表现。“逸散层”这一命名借用自大气科学中对地球大气最外层的命名(dissipation layer或mesosphere)。它隐喻了这一区域的词的特性: 生命周期很短,十分活跃,但稍纵即逝,与地球大气最外层的处于高度电离状态的原子相似,十分活跃,很容易逃逸到外太空中。在这一层中形容词、动词和其他词类几乎绝迹,仅剩余名词和数词,因而典型的语法现象通常不由这一层的词构成。在这一层出现了大量的命名实体,它们与其所在的时间段有关,是因为频次太少而不具有统计差异性。但这一层词量巨大且开放,是构成具体语言生活所不可缺少的,是基干层、过渡层和时敏层构筑的语言“骨架”上具体的“血肉”。我们将以上三层和基干层的特点总结在表5中。

表5 各层次词语特征对比
5 结论
本文工作在基干层词语的基础上,根据 TF-IDF图线的趋势对历时语料库词汇进行了时间分布层次的划分,并进行了时间区分度、词类分布、覆盖度等指标的考察和分析。TF-IDF升序3 000到10 000词为语法现象明显的过渡层,10 000到50 000词为时间敏感性较强的时敏层,50 000词以外是词频很低,使用寿命极短的逸散层。从内到外诸层,名词比例逐层提高,平均词长逐层增长,词量猛增,时间敏感性增强,但对语料的覆盖率迅速下降。从基干层到散逸层,本文尝试基于历时语料库建立汉语词汇的时间分布层次的分层体系。时间分布层次从内到外诸层的特点符合语言生活的直观认识和语素与词汇组合的基本规律。本文认为在其他类型,甚至其他语言的历时语料上也存在近似的分层体系。虽然在词量和覆盖率上可能有所差别,但层次之间的相对关系与特征应大体一致。
猜你喜欢
汉字汉语研究(2021年1期)2021-06-11 01:14:58
汉字汉语研究(2021年1期)2021-06-11 01:14:56
花卉(2020年4期)2020-03-16 08:17:50
新世纪智能(英语备考)(2019年10期)2019-12-16 09:07:54
绿色科技(2019年13期)2019-08-31 02:44:12
广东蚕业(2019年3期)2019-05-14 05:37:40
红楼梦学刊(2019年5期)2019-04-13 00:42:36
新世纪智能(语文备考)(2019年3期)2019-01-12 09:08:10
汉字汉语研究(2018年3期)2018-11-06 07:03:08
东南法学(2016年2期)2016-07-01 16:42:34
