
基于时空双流融合网络与AM-Softmax的动作识别
2019-11-12 02:13:56马翠红毛志强
网络安全技术与应用 2019年11期
◆马翠红 王 毅 毛志强
(华北理工大学电气工程学院 河北 063210)
传统的人体动作识别主要是基于手工特征[1-2]的方法,然而由于传统方法进行特征提取的步骤烦琐且难以提取到深层特征,因此使得行为识别准确率难以提升。近年来,随着深度学习被广泛应用于图片分类、人脸识别和目标检测等识别领域,其在人体动作特征提取上也表现出了很好的效果。2014年,Karpathy等[3]第一次利用深度卷积网络以连续的RGB视频帧为输入,进行人体行为识别,然而并没有很好地利用时间域特征;Simonyan等人[4]提出了双流卷积网络结构,分别提取视频序列中的时间域特征和空间域特征,识别效果虽然有了明显提升,然而由于该网络结构使用的是传统Softmax和SVM进行人体识别,使得识别准确率并不高。
在L-Softmax[5]和A-Softmax[6]的基础上,Wang F等人[7]提出了一种加性余量 Softmax(Additive Margin Softmax,AM-Softmax)方法用于人脸识别,对传统的Softmax loss函数进行改进,使得人脸特征具有更大的类间距和更小的类内距。受文献[7]的启发,本文将AM-Softmax思想用于人体动作识别中,取得很好地识别效果。
在文献[4]的基础上,本文对其网络结构进行改进,将双流网络结构进行时间流到空间流的单向连接,再将全连接层的输出特征进行融合,然后采用AM-Softmax对时空融合特征进行深层验证,从而最大化类间距离、最小化类内距离;最后采用线性SVM对特征进行分类,从而实现人体动作识别。
1 模型架构设计

图1 总体架构设计
利用卷积神经网络(CNN)提取视频中的时间信息一直是人体动作识别的难点。卷积神经网络比较适用于提取单一静态图片特征,对于视频的时间信息不是很敏感。文献[4]提出了时空双流深度学习策略,用来分别提取视频的空间信息和时间信息,最后进行双流信息融合。与传统的视频人体动作识别方法相比,该方法有效的融合了视频中的时间信息。但是仍存在以下问题:双流结构提取的时空特征仅在最后的Softmax层进行融合,没有考虑到时空特征在卷积层和全连接层之间的关联性;该模型采用的是传统的Softmax-loss函数,对类内距离小、类间距离大的相似动作识别效果并不好。
本文提出的Two-stream Fusion&AM-Softmax网络模型如图1所示。该网络模型主要包含四个部分:时空双流融合网络、时空特征融合、AM-Softmax深度验证、线性SVM实现动作分类识别。
1.1 时空双流融合网络
为了充分利用视频序列中的表观信息和运动信息,建立起时空特征之间的关联性,提出了一种时空双流融合卷积神经网络结构,其具体网络结构参数设置如图2所示。本文构建的双流基础网络模型采用的是牛津大学视觉几何组(Visual Geometry Group,VGG)开发的VGG-M-2048模型。
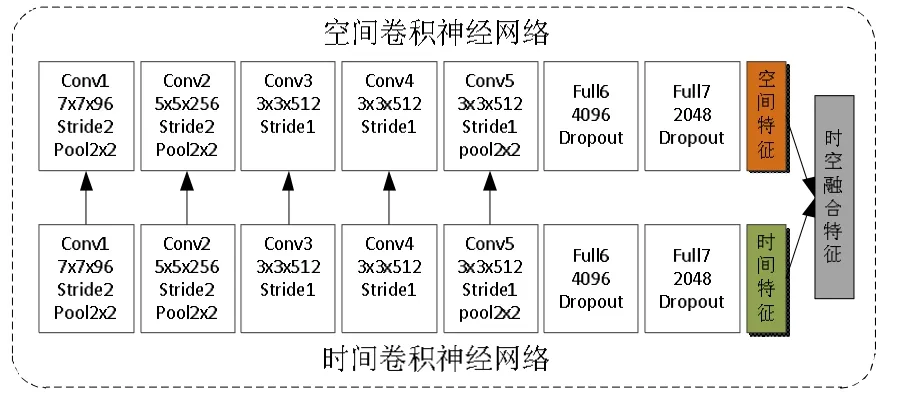
图2 双流融合卷积网络结构
空间流卷积神经网络实际上是一种图片分类结构,以连续的单个多尺度RGB视频帧为输入,提取静态图片中的人体表观特征。时间流卷积神经网络是以连续的光流图为输入,提取光流图中的人体运动信息。光流图可以理解为空间运动物体在连续视频帧之间的像素点运动的“瞬时速度”,能够更加直观的表征人体动作。本文采用OpenCV视觉库中的稠密光流帧提取方法,分别获取视频中水平方向和垂直方向的光流帧,然后以20个光流图构成一个光流组(flow_x和flow_y)作为时间流卷积神经网络的输入。
时空融合双流网络指的是利用空间流提取到表观信息与时间流提取的运动信息的关联性判断人体动作。例如挥拳和散步,空间流卷积神经网络识别出静态图像中手和脚的位置,然后时间流可以识别出手和脚的周期性动作,从而根据时空双流提取到的深度特征识别出人体动作。在时空双流卷积网络内部,采用一种时间流到空间流的单向连接,将时间流提取到的运动特征输入到空间流,将之与表观信息进行关联性,从而提取到更深层次的动作特征。
最后,将双流网络结构提取到的时空特征进行融合,作为后续AM-Softmax算法的输入。虽然在双流卷积网络内部各层进行了单向连接,时间流提取到的运动特征在空间流各层也进行了关联性学习,但是由于运动特征是重要的人体动作信息,仍会从时间流的全连接层输出出来再与空间流的输出特征进行融合,从而视频序列中的运动特征会作为网络模型的主导特征进行人体动作识别。
1.2 AM-Softmax算法
之前提出的L-Softmax、A-Softmax引入了角间距概念,用于改进传统的softmax loss函数,能够使得类别特征之间具有更大的类间距和更小的类内距。
Softmax loss函数经常会被用到卷积神经网络中,虽然简单实用,但是它在人体动作识别中并不能引导网络学习区分性较高的特征。传统的Softmaxloss函数如下式所示:

式中,fj表示最终全连接层的类别输出向量f的第j个元素,N为训练样本的个数。
由于f是全连接层的激活函数W的输出,所以fyi可以表示为,则最终的损失函数可以表示为:
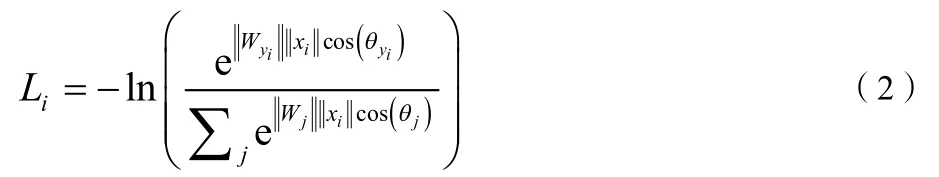
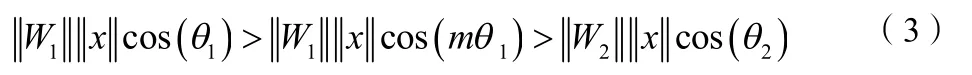
因此,L-Softmax loss函数可写为:

接下来,文献[6]提出了一种A-Softmax loss函数,以二分类作为例。为了将1特征x正确分类,修改后的softmax loss函数要求,即。在此基础上增加一个参数,此时要正确分类,需要使,即。这样就增加了判决的约束,使得学习的特征更具区分性,因此可以得到A-Softmax loss函数如下式所示:
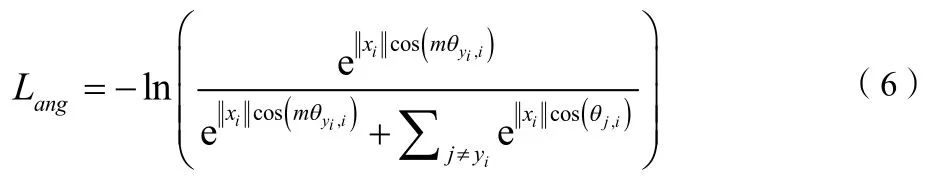
为了能够保证上式可以在CNN中进行前后向反馈,上式可改写为:
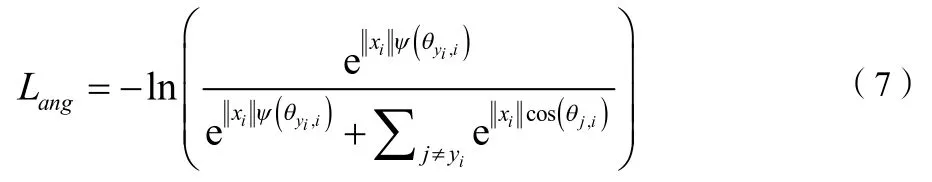
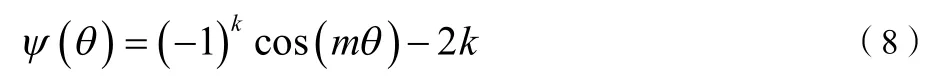
文献[7]在L-Softmaxloss、A-Softmaxloss函数基础上提出了一种更加直观、更易解释的AdditiveMarginSoftmax(AM-Softmax)算法用于人脸识别,并取得了很不错的效果。
L-Softmax和A-Softmax都是引入了一个参数因子m将权重W和输出向量f的余弦距离变为,通过m来调节特征间的距离。AM-Softmax将式(5)、(8)改写为:

因此,最后的AM-Softmax loss函数写为:
在215名参加城乡居民合作医疗保险的高血压患者中,CHE的发生率为13%,其中,农村户口患者CHE发生率为74%; 发生CHE的logistic回归模型,以患者的社会人口经济学特征、疾病严重程度、医疗费用支出等作为解释变量。结果如表4,其中,患者家庭CHE发生的概率随着收入水平的增加而逐渐降低,门诊自付费用每增加一元,其CHE发生的概率将增加0.12%。另外,丧偶状况下的患者发生CHE的概率大于对照组。
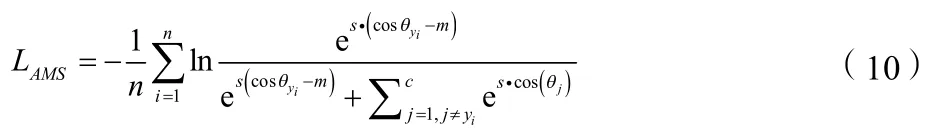
式中,s是一个缩放因子。
本文受其启发,将AM-Softmax loss函数应用到了人体动作识别,对动作深度特征进行处理,使其能够将各类动作特征的类间距更大,类内距更小。如图3所示。
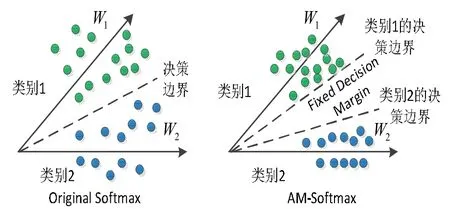
图3 原始Softmax和AM-Softmax比较
2 实验结果与分析
2.1 实验环境搭建
本文实验环境选择在深度学习框架Tensorflow上进行,采用小批量随机梯度下降法进行网络训练。时空双流融合卷积神经网络采用VGG-M-2048模型提取时空特征,以16帧为一组的连续RGB视频帧为空间输入,尺寸大小为224*224,时间流卷积神经网络输入大小为224*224*2L,在原光流图上随机位置裁剪连续光流帧。
本次实验数据集采用KTH数据集,该数据集包括了4种场景下25个不同行人的6种行为视频:正常行走(Walk)、慢跑(Jog)、跑(Run)、挥拳(Box)、双手挥手(Wave)、鼓掌(Clap)。如图(4)所示。实验过程中,为了增加识别准确率可信度,本文将KTH数据集随机划分成3组,取其3组测试平均准确率作为评估模型效果的指标。
2.2 实验结果与分析
实验过程中,为了得到更加可靠的识别准确率,本文将KTH数据集随机划分成3组,并取其3组测试平均准确率作为评估模型效果的指标。
通过时空双流融合VGG-M-2048模型提取连续RGB视频帧与连续光流图的时空特征,在双流VGG-M-2048模型内部卷积层之间采用时间流到空间流的单向连接方式,进行运动特征与表观特征的关联性学习。实验过程中,在双流结构全连接层的不同位置进行时空特征融合,其识别准确率如表1所示。

图4 KTH样本数据集

表1 不同全连接层输出特征识别准确率的比较(%)
从表1中可以发现,随着时空特征融合位置层次的加深,其动作识别准确率也在不断提高,但在空间流的fc6层与时间流的fc7层进行融合时,识别效果最好。文献[4]和文献[8]提出的双流CNN模型在UCF-101数据集上均证明了这一结论。
为了验证本文算法提出的AM-Softmax Loss函数对动作识别效果提升的作用,在KTH数据集上对比了不同的Softmax Loss设计方案对网络的影响,如表2所示。实验结果表明,传统的Softmax Loss函数在动作识别上并未取得很好的识别效果,然而本文采用的在L-Softmax、A-Softmax基础上进行改进的AM-Softmax取得了很好的识别效果,识别准确率可达97.5%。

表2 不同Softmax Loss方案对网络的影响
最后,将本文方法与其他主流的动作识别算法在KTH数据集上进行比较,如表3所示。
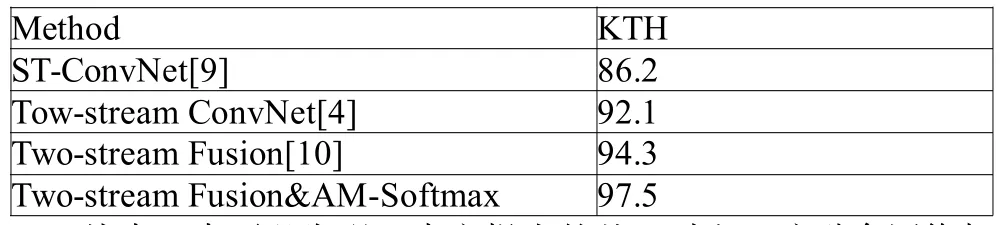
表3 不同算法在KTH上的比较结果(%)
从表3中可以发现,本文提出的基于时空双流融合网络与AM-Softmax的动作识别效果明显优于其他算法,说明在卷积层进行时空特征融合,使表观特征与运动特征进行关联性学习,能够提高动作识别准确率。
3 结束语
本文从人体动作类内类间距离差异的角度出发,提出了一种基于时空双流融合网络与AM-Softmax的动作识别方法。通过时空双流卷积神经网络分别提取视频序列中的表观特征和运动特征,且在卷积层内部采用时空单向连接将时空特征进行关联性学习;然后将双流结构的S-fc6层与T-fc7层特征进行融合;最后采用AM-Softmax Loss函数对时空融合特征进行优化,利用线性SVM实现人体动作识别。在KTH数据集上的实验结果表明:在卷积层采用单向时空连接进行时空特征关联性学习有利于人体动作表征能力的提升;将空间流的fc6层与时间流的fc7层进行特征融合,会有更高的识别准确率;采用AM-Softmax Loss函数优化时空融合特征,能够最大化类间距离、最小化类内距离,有利于人体动作分类。
猜你喜欢
中小学校长(2022年7期)2022-08-19 01:36:36
四川党的建设(2022年8期)2022-04-28 21:29:35
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
冶金设备(2020年2期)2020-12-28 00:15:22
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
高原山地气象研究(2020年3期)2020-07-16 07:53:58
中小学校长(2019年10期)2019-11-07 04:56:38
作文大王·低年级(2018年10期)2018-12-06 06:22:44
