
基于BERT模型的舆情分类应用研究
2019-11-12 02:13:54胡春涛秦锦康陈静梅
网络安全技术与应用 2019年11期
◆胡春涛 秦锦康 陈静梅 张 亮
(1.江苏警官学院 江苏 210031;2.中国人民公安大学 北京 100038)
谷歌团队于2018年底发布了基于双向Transformer大规模预训练语言模型(Bidirectional Encoder Representation from Transformers,BERT),并凭借基于预训练的fine-turning模型刷新了11项 NLP任务的当前最优性能记录。随后,谷歌团队公开了该模型的官方代码和预训练模型。目前,笔者通过查阅大量资料发现国内对于BERT模型应用于中文自然语言处理的研究还处于初步阶段,而舆情数据的分类更是该领域的研究热点,引起了国内研究热潮。在研究早期,朱等[1]提出采用向量空间模型,王等[2]提出了基于词向量的文本字典分类模型,张等[3]提出使用计算文本相似度的方法进行文本分离。上述方法多基于统计规律,不能根据特定数据集进行个性化的调整,不能满足当前对舆情文本分类准确率的要求。随着神经网络的兴起,涌现出一批利用神经网络处理文本分类任务的研究。Kim等[4]将预训练的词向量作为输入,利用卷积神经网络(Convolutional Neural Network,CNN)实现了文本情感分类。Kalchbrenner等[5]提出一种动态卷积神经网络(Dynamic Convolution Neural Network,DCNN)模型用于句子特征学习,并取得了较好的效果。孙[6]在门限循环单元(Gated Recurrent Unit,GRU)的基础上连接Attention注意力层,设计了GRU-Attention分类模型,并证明了其分类性能相比支持向量机(Support Vector Machine,SVM)和单独的GRU网络有了一定提升。但此类神经网络结构简单、特征信息的提取和编码能力弱,在舆情信息这类语意复杂,包含上下文语境的文本分类任务中难以取得理想的效果。随着研究的加深,出现了更多更复杂的网络结构设计。刘月等[7]提出利用CNN提取短语序列的特征表示,利用N-LSTM(NestedLong Short-Term Memory)学习文本的特征表示,引入注意力机制,突出关键短语以优化特征提取,使模型不但能捕捉句子局部特征及上下文语义信息,还能突出输入文本各部分对文本类别的影响程度,在3个公开数据集上性能比基线模型有了明显提高。刘心惠[8]等提出使用多头注意力机制(Multi-head Attention),结合胶囊网络(CapsuleNet)与双向长短期记忆网络(BiLSTM)方法,在Reuters-21578和AAPD两个数据集上F1值分别达到了89.82%和67.48%。
纵观当前文本分类任务的研究,尚处于为某些特定的任务单独设计模型的阶段。笔者考虑,如果能使用出一种较为科学、完善的模型,当面临某项任务时能够对现有模型进行微调,在不影响模型性能的前提下,快速适应任务的需要,便可节省大量的研究资源,减少重复劳动。因此本文选择对BERT模型进行应用方向的研究,分析其设计原理,并通过对比实验探究其应用于舆情文本分类任务上的训练效率和分类性能。
1 模型介绍
本文模型在预训练的BERT模型基础上进行了结构的微调,使其能更好应用于文本分类任务。因此首先要对BERT的结构和特点有一个较为全面的了解。从技术发展的角度来看,该模型并未使用某种全新的深度网络或提出某种全新的算法,而是将近年来各种深度学习、自然语言处理技术进行完善和集成。下面将对BERT的整体结构及各个模块分别进行介绍。
图1显示,Devlin J等[9]设计的BERT模型主要分为两大部分,主要分为输入层和双向Transformer编码层。下面首先介绍模型主要部分——Transformer编码器。
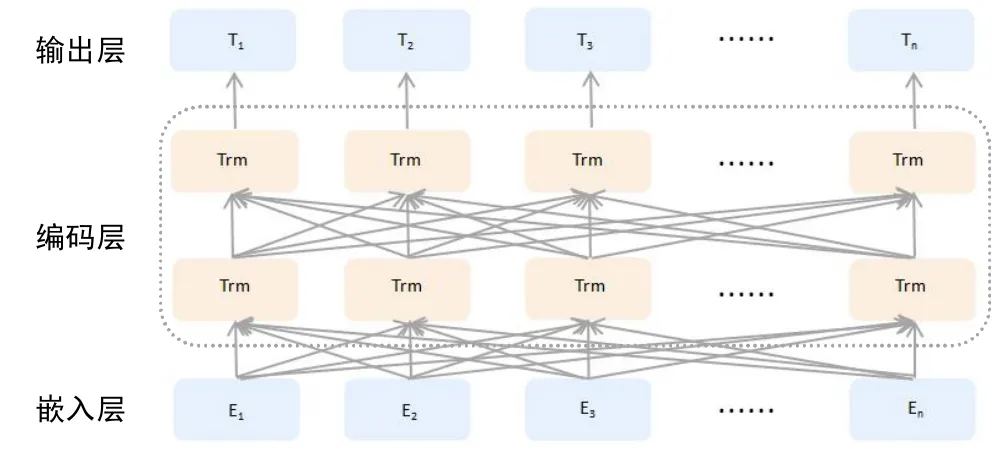
图1 BERT模型基本结构示意图
1.1 Transformer编码器
在自然语言处理中,词嵌入几乎是所有研究的基础。以2013年 Tomáš Mikolov 等[10]提出的 Word2vec(Word to Vector)为例,主要通过连续词袋模型(Continuous Bag-Of-Words Model,CBOW)和连续Skip-gram模型(Continuous Skip-gram Model,Skip-gram)进行训练。以CBOW算法为例,核心思想是从一个句子里把一个词掩盖,训练神经网络去预测被掩盖的词。当神经网络训练达到设定的轮数或能够在大量语料的训练后成功预测,就能通过神经网络计算出该词的词向量表征。原理类似于人们阅读文本时发现文章某个词不认识,但可以通过上下文的语境含义推测出该词的大致意思。随着自然语言处理任务的复杂,研究者发现,Word2vec不能区别不同语境中同一个词语的不同语义。例如多义字“还”,它既有“归还”、“回报”的意思,也有表示“仍旧”等等多个意思,而Word2vec只能返回它混合了多种语义的一个词向量。因此研究者提出了新的表示词嵌入方法——来自语言模型的词嵌入(Embedding from Language Models,ELMO)[11]。如图2所示,该模型的创新在于,在利用预训练的词嵌入模型的基础上,利用双向长短期记忆网络(Long Short-Term Memory,LSTM)编码单词的上下文,调整后单词的Embedding表示动态的具备了上下文的语义。
图2中,句子中每个单词经过三层编码:嵌入层为单词原始的词向量表示,之后是第一层正向LSTM中对应的词汇编码,这层主要蕴含句法信息;最后是第二层反向LSTM中对应词汇编码,这层主要蕴含语义信息。之后给予这三层各一个权重,将编码结果乘以各自权重累加求和,便得到ELMO的输出。
BERT紧随ELMO推出,图1显示,该模型在总体结构上和ELMO并无二致。根本的改变在于BERT使用Transformer编码器代替了原先的LSTM。如图3所示为Ashish Vaswani等[12]设计的Transformer外部结构。它由6个编码器(Encoder)和6个解码器(Decoder)堆叠而成。它接收序列数据,同样输出处理后的序列数据。经过6个编码器处理后的数据会分别输入6个解码器进行解码。

图2 ELMO模型基本结构示意图

图3 Transformer的总体结构
每个Encoder的内部构造完全相同,但参数不会共享。主要由两部分组成:自注意力层(Self-attention)和前馈神经网络层(Feed Forward Neural Network)。
同样,每个Decoder也具有类似的内部结构,比Encoder多一个“编码—解码注意力层”,目的是帮助Decoder重点关注句子中某个关键词语,而忽略其他相关程度较低的词。它们的内部结构如图4所示。

图4 Encoder-Decoder内部结构
下面介绍Transformer的运行流程。输入句为“这家餐厅我们经常来,它的牛肉面、小笼包和肥牛都特别好吃”。原句经过前期的处理,输入的是句子中的单个字符,但如何让模型知道句中的“它”是指代的“店”而不是句中的其他字符呢?
当模型在处理词语时,Self-attention层会逐一计算该词与句中其他词的关照程度,再将结果通过softmax函数进行归一化,得到相关性的概率分布。为了清楚解释该过程,需引入相关公式加以说明。假设模型的输入为X:
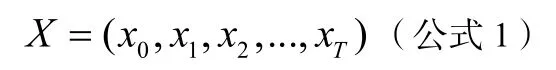
模型的输出为:
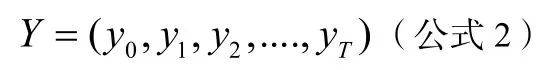
对每一个输入x做线性映射,乘以WQ权重矩阵得到每个输入x的Query向量,同样分别乘以WK,WV得到每个输入x的Key向量和Value向量,这些向量用于之后计算句中词语之间的相互关联程度。
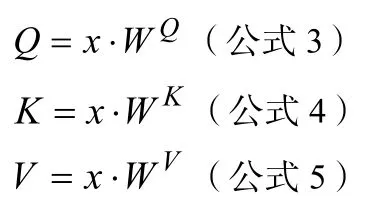
例句中字符“它”、“的”经过词嵌入得到向量x1,x2,将输入X乘以对应的权重矩阵WQ、WK、WV得到Q、K、V向量。将其中q1和k1、k2、……、kT对应相乘得到字符关照程度的得分Score,将Score除以8(即Key向量维度的开方,目的是保证训练过程中具有更稳定的梯度)得到新的关照度表示,再对结果使用softmax进行归一化运算,目的是保证对重要字符关照度不变的情况下降低对不重要字符的关注。再将softmax产生的计算结果乘以Value向量,将关照度和语义信息结合,得出“它”和句中其他字符关照程度向量z1。计算过程如图5所示。

图5 Self-Attention机制运行流程
上述过程可以用公式6统一表示:
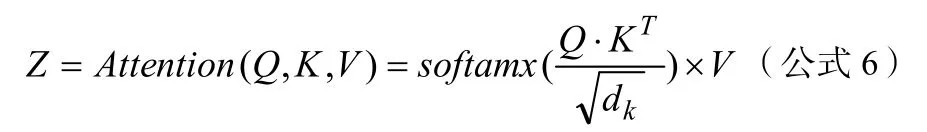
其中,dk表示Key向量维度。根据例句得到的“它”字符在全句中的注意力关注程度如图6所示。
而BERT模型采用了多头注意力机制(Multi-headed Attention),相较于Self-attention,它为attention层提供了多个表示子空间(Representation Subspaces),拓展了模型关注不同位置的能力。每个注意力头(header)都分配一个Query、Key和Value权重矩阵(Transformer使用8个注意力头)。这些权重矩阵在训练开始时随机生成,通过训练将来自较低层的Encoder/Decoder的矢量投影到不同的表示子空间。
对于每个注意力头,通过公式6,计算得到相应的关照程度向量z0,z1……z7,将8个向量拼接之后乘以矩阵W0得到最终的注意力矩阵Z。对于字符“它”,图7显示了完整的计算过程。
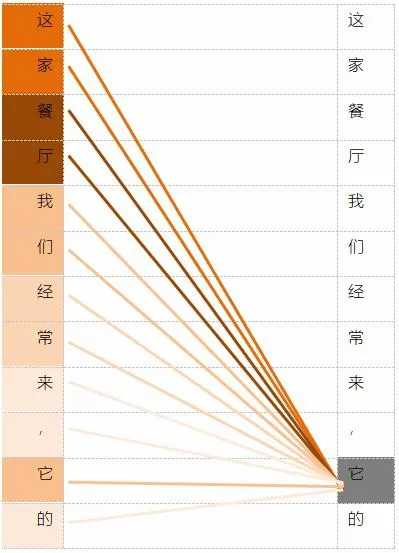
图6 字符“它”在句中的注意力关注度
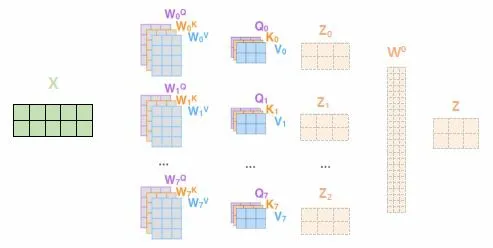
图7 Multi-headedAttention计算过程示意图
该计算过程可以用公式7表示:

BERT所用的Transformer基于传统模型进行了改进,即添加了残差连接。它将每个Encoder/Decoder的输入同多头注意力结果或前馈神经网络运算结果进行拼接,目的是为了解决随着网络的加深而产生的梯度消散问题。之后,对拼接结果使用归一化函数,对Z进行更新,目的是将注意力层的输出结果限制在一定范围内。该计算过程可用公式8表示:

之后将归一化结果输入前馈神经网络,使用修正线性单元(Rectified linear unit,ReLU)作为激活函数。运算过程如公式9所示:
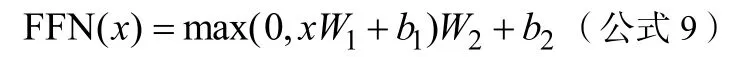
其中x表示网络的输入,W1,b1,W2,b2均为网络待训练参数。图8为BERT的Encoder内部结构图。
1.2 词嵌入层
在Transformer之前,每个字符需经词嵌入层的处理,编码成提供给Encoder的词向量。Encoder中只用了多头注意力机制和前馈神经网络,不同于循环神经网络能够学习到字符的位置信息。因此,除了传统通过词向量编码之外,还需编码字符的位置信息。图9中,Encoder的输入为字符的原始词向量和位置编码向量信息(Positional Encoding)的拼接结果。
Positional Encoding使用正弦函数和余弦函数来构造每个位置的值,计算方法如下所示:
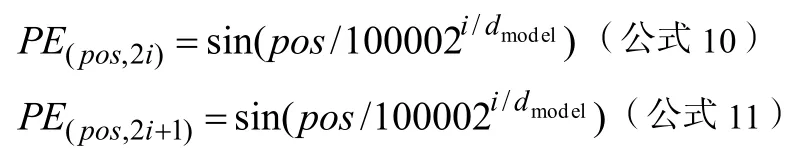

图8 BERT所用Encoder内部结构图

图9 BERT编码层示意图
2 模型的训练
本文在BERT输出结果上添加了全连接网络并使用softmax作为分类器。训练数据为微博舆情数据,数据集总共分为14大类,包括民生、文化、娱乐、体育、财经、房产、汽车、教育、科技、军事、旅游、国际、农业、电竞。各类别的数据分布如表1所示。
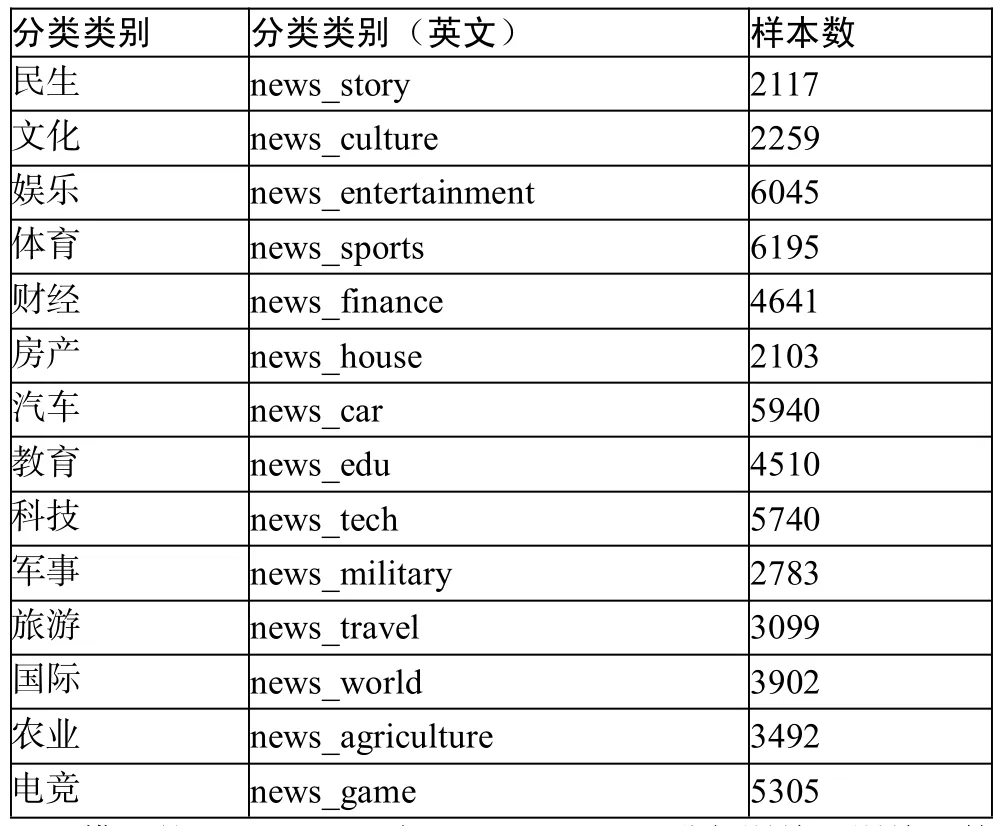
表1 各类别样本数据统计情况
模型的Fine-turning在Tesla K80 GPU进行训练,训练一轮时间约为7分钟。表2为模型训练记录。

表2 BERT的Fine-turning训练记录
同时,笔者还将该BERT与杨等[13]提出的文本分类模型做对比,使用双向LSTM连接CNN,设置CNN的一维卷积核长度为3,卷积核个数为64,用最大值池化层连接softmax归一化函数作为分类器。模型训练记录如表3所示。

表3 双向LSTM 连接CNN的模型训练记录
对比显示,使用BERT的模型在精确率和召回率两方面均优于使用双向LSTM连接CNN的模型,笔者分析有以下两点主要原因。
(1)由于Transformer引入了多头注意力机制,对于某一个词,能从不同角度关注到句中相对应的词,因此它对于句子长距离特征捕获能力要略微优于循环神经网络。
(2)在LSTM连接CNN模型中,RNN主要用于编码字词和上下文关系,CNN主要用于语言特征的抽取,受CNN卷积核长度及卷积核个数的限制,对语意特征的提取能力不如Transformer的多头注意力机制丰富和完整。另外,由于CNN最初用于图像特征的提取,图像是像素点的排列,CNN只需检测出多个像素点具有的某种整体结构特征,池化操作并不会根本改变对图像内容的理解。而对于文本,一个细节的差别可能导致整个句意的改变。因此Transformer的Encoder-Decoder结构捕捉到语言特征会相对完整和多样。
3 总结与展望
本文通过介绍词嵌入技术的发展历史,从而较为全面地介绍了BERT模型的整体结构和运行流程。最后将其与传统模型做对比,进而分析它在性能上优于传统分类模型的原因。同时,笔者发现,在舆情文本分类任务上,由于本文使用中文语料,BERT只接受以字作为embedding的输入,相较于以词语作为embedding丢失了较多语义信息。因此后续将尝试借鉴BERT的Transformer构造思想,训练出能够对词语进行动态编码的模型,以求获得更好的语义表达和特征抽取能力。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
开放教育研究(2020年2期)2020-03-31 01:54:14
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
