
基于Hadoop 平台的聚类协同过滤推荐方法研究∗
2019-11-12 06:38:42赵恩毅王瑞刚
计算机与数字工程 2019年10期
赵恩毅 王瑞刚
(西安邮电大学物联网与两化融合研究院 西安 710061)
1 引言
随着互联网技术的飞速发展,它为人们提供越来越多的信息和服务的同时,也使得人们从信息缺乏的时代逐步踏进信息过载的时代。智能推荐系统的到来,使用户能够更加便捷地在网络中获取到自己所感兴趣的话题。推荐系统通过对无用信息进行筛选过滤来为用户推送有用信息,从而提升了用户获取信息的效率[1]。其中推荐算法则是推荐系统中的关键所在,它能够决定一个推荐系统性能的优劣,而协同过滤推荐是推荐算法中性能效果比较好的策略之一[2]。
然而大数据时代的到来让海量数据的存储与计算效率面临巨大挑战。传统单机上的协同过滤在运算效率和计算复杂度上都不能满足超大量信息处理的需要。因此分布式推荐成为推荐算法研究中一个新的研究方向[3],本文将设计一种基于Hadoop 平台的分布式聚类协同过滤推荐算法。首先对K-means 聚类算法进行改进,然后在MapReduce 计算框架下对其实现分布式聚类[4]。改进聚类算法利用最大-最小值思想得出聚类中心,能够有效降低算法并行计算时的迭代次数。同时在MapReduce 框架下将Map 端所产生的同簇数据传输到Combiner 类中,避免了Reduce 端所接收数据量过大而影响传输效率。然后在传统协同过滤算法的基础上,通过大数据平台实现一种基于改进K-means聚类的协同过滤推荐算法,进而改善了推荐系统在大数据环境中存在的稀疏性和可扩展性问题,同时算法的运行速率以及推荐精度也得以提升。
2 分布式聚类协同过滤推荐算法
针对传统协同过滤推荐算法在数据稀疏性和准确度等方面存有缺陷,提出在利用Hadoop 分布式计算平台所具备的计算大规模数据等优势的同时,通过聚类模型来构建高精度的推荐算法[5]。其中Hadoop 是开源的分布式计算框架,它有分布式文件系统HDFS 和支持一个MapReduce 范式的实现。该分布式聚类协同过滤推荐算法不但使推荐精度提升,并且在数据的稀疏性和可扩展性方面也得以解决[6]。针对分布式环境下的高维复杂数据,首先对其做降维处理,数据预处理之后经过改进的K-means 聚类模型计算出恰当的聚类簇,最后在Hadoop 分布式计算框架下通过协同过滤结合聚类的方法构成推荐列表[7]。图1为推荐算法流程。

图1 基于大数据平台下分布式聚类协同过滤推荐算法流程
2.1 对数据做预处理
复杂的初始数据只有经过预处理之后,在后期运用中才能够被高效利用[8]。在这里可以将数据定义作属性集合,其中属性则是特征信息。通常在推荐系统中的数据较为复杂,不但存有高维空间特征,并且在空间中表现较为稀疏[9]。通过对数据降维,可以高效地将复杂高维空间转为简单低维空间[10]。其中,在奇异值分解方法中,集合中的任何特征信息的概念强度都通过计算得来。另外,针对协同过滤推荐算法,矩阵分解技术能够有效解决其数据稀疏性以及可扩展性问题[11]。本文在Hadoop分布式计算框架下采用交替最小二乘迭代(ALS)矩阵分解技术对初始矩阵做处理,其中 ||u × ||τ user-item 评价打分矩阵R(秩为n)可以粗略定义为矩阵=PQT。

最小误差等同于对R 值做奇异值分解处理:

其中U 表示 ||u ×n 矩阵,V 表示 ||τ ×n 矩阵,∑是n×n 对角化矩阵。下面提取前k 个最大奇异值所对应的向量矩阵,Uk,Vk,能够得出用户-矩阵和物品-矩阵可定义为
该模型相应的评分预测rui可定义为

当学习P 和Q 时,可利用已知评分:
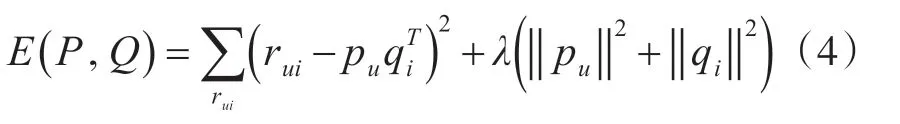
其中λ 被定义为控制正则化参数。
2.2 改进聚类算法MapReduce并行化实现
K-means算法在传统聚类方法中相对简单高效,但传统K-means 算法的聚类结果却不够稳定[12]。原因是传统K-means 算法在初始聚类中心点和K值的选取上通常是根据用户自身经验来设定,在这个过程中往往需要用户重复试验来提升设定值的准确度[13]。那么在没有用户的经验情况下,如何通过准确计算来确定K-means 算法的初始聚类中心和K值,本文对传统K-means聚类算法做出改进。
对于如何来高效设定初始聚类中心点,可以在Hadoop 分布式计算框架下采用最大值-最小值方法来计算获取[14]。用该方法不但可以降低计算过程中迭代次数,并且能够避免聚类中心在选取时发生点与点过于邻近的情况。该方法利用欧式距离来确保聚类中心点之间的距离值足够大。假定对象集合为{ x1,x2,⋅⋅⋅,xm} ,算法的实现步骤如下:
1)假设θ( 0 <θ <1) ,选取距离原点最远的点x1和距离原点最近的点x2作为初始聚类中心点c1和c2,记x1,x2两点之间的距离为D。
2)计算出剩余点与c1,c2点的距离,找出与c1点和c2点距离值最小的点d1和d2得出max( d1,d2),其中max( d1,d2)>θ·D,再将相应数据点设为第3个聚类中心点c3。
3)假若c3存在,那么继续计算剩余点各自与c1,c2,c3点的距离得出max( d1,d2,d3) 并确定第4 个聚类中心点。 依次类推,当剩余点与max( d1,d2⋅⋅⋅dn)的距离不大于θ·D 时,终止选取聚类中心点的计算。
该改进的K-means 算法避免了所选取的聚类中心点间距离相邻近的情况,也降低了运算迭代次数。同时,本文结合MapReduce分布式计算模型的特性,将Map端所产生的同一簇数据利用Combiner类对其做归并处理,这样能够使得从Map 端到Reduce端传输过程中的数据量减少,从而缩减传输开销。具体步骤如下:
假设对象集合X={x1,x2,⋅⋅⋅,xn},聚类簇数k个,聚类中心点为{C1,C2,⋅⋅⋅,Ck} 。
输入:对象集合X,初始中心点x1,x2
输出:k个聚类中心点
步骤1.计算初始聚类中心
1)Map 端读取本地数据,计算每个点与初始中心点的距离。
2)将该距离记作Value值传送到Reduce函数。
3)Reduce端计算出与初始中心点距离最近的点。
4)将MapReduce 计算结果中距离值最大的点添入中心点文件。
5)将所有中心点写进cluster 中并将其加到分布式缓存里,以便为下一次迭代传输信息。具体流程如图2所示。

图2 聚类中心点计算流程
步骤2.聚类算法的MapReduce实现
1)Map 端读取分布式缓存中上一轮迭代而来的簇中心点。
2)Map 函数计算中心点到每个点的距离并得出最近的簇中心点,然后将其作为key 值,对应点的数据内容作为value值。
3)Combiner 类归并Map 端同一簇的<key,value>。
4)Reduce 端对Combiner 类所输出内容做合并计算。
5)当中心点变化值小于给定值时结束本流程,否则跳向第1)步。
2.3 聚类中的相似度/距离度量方法
聚类算法往往会根据距离度量的方法来计算对象之间的相似度,对象通常会被分入相同簇或者不同簇中。不同簇对象之间的距离较远而相似度低,同一簇对象之间的距离较进而相似度高[15]。距离度量方法作为衡量对象间相似度的指标,当采用不同的计算方法将会产生不同的效果。所以会将不同的度量方法进行比较,从而选取出一种准确度较高的方法。其中较常见的是欧几里得距离:

除了距离,用来计算两向量之间夹角的余弦相似度能够准确衡量两个样本之间的差异,夹角范围为[-1,1],余弦相似度如下:

另外皮尔逊相关性系数也是较常用的一种度量方法[16]。Pearson 相关系数重点用来确定两向量是否在同一条直线上,它类似于余弦相似度是用来计算两向量之间的夹角。当Pearson 相关系数值越大,说明两对象之间的相关性越强。而当Pearson相关系数值趋近0 时,说明两对象之间的相关性越弱。我们通常可以参考表1 数据来判断两个向量的相关强度。

表1 相关系数值域等级
Pearson相关系数:
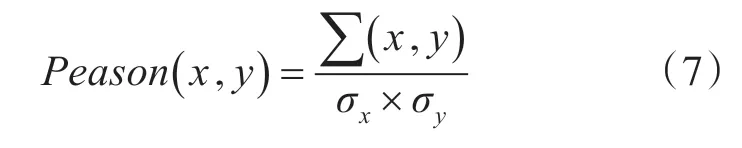
其中Pearson 相关系数值介于-1 到1 之间,它能够衡量两个数列之间的线性相关程度。
2.4 基于改进聚类的协同过滤推荐算法
协同过滤算法当前在推荐系统研究领域被广泛应用,它不同于传统搜索引擎需要用户提供关键字等信息内容,而是通过用户的日志行为来挖掘出用户喜好[17]。协同过滤通常使用近邻方法为用户寻找相似偏好用户的信息,从而针对性比较强。协同过滤推荐算法不同于基于内容的推荐算法,它是根据邻近用户物品评价或者打分结果来判断目标用户的偏好,在这个过程中协同过滤推荐算法并不需要获取用户和物品的特征内容。另外,协同过滤推荐通常可以分为两大类,一种是基于用户的协同过滤,另一种是基于物品的协同过滤。总而言之,协同过滤关键之处是挖掘出用户的偏好,通过广大用户给各个物品做出的评价以及打分结果向相关用户进行合理的推荐。本文将在协同过滤推荐算法的基础上结合改进聚类算法来构建推荐列表。其中,基于改进聚类的协同过滤算法具体描述如下。
输入:目标物品的评分测试集R1、聚类数据集合R2、聚类中心和初始点集合R3、给定相似性阈值C。
输出:最终推荐列表
1)对评分测试集中的目标值与集合中各聚类中心点做相似度计算处理并统计;
2)将上述统计值与所给定的相似性阈值进行详细对比,选取不小于阈值的统计值所对应项目列表,并将其添加到候选项目集中;
3)对候选集进行基于项目的分布式协同过滤来生成用户向量、项目共现向量以及项目组织完成的预测向量等等,实现对向量的预测,最终完成对目标项目的相关推荐。
3 实验结果与分析
通过上述研究,选取1 台机器作为Master,4 台机器作为Slave去负责相关运算任务。在数据集的选取上,这里在MovieLens 官方网站www.Crouplens.org 下载电影数据中的100KB,1MB 和10MB三种对应数据,接下来选用该三类不同大小的电影数据来进行实验,实现本文中不同算法在各个性能上的比较。
为了检验在分布式大数据环境下该算法的相关性能,本文根据加速比S=T1/Tn来做相关处理和验证,通过Hadoop 的分布式平台环境的可扩展性能,可使该三种数据规模不同的电影数据在算法上的执行效率大大提升。其中对该加速比的定义如下:

其中T1表示的是每个节点所执行的时间,Tn则表示的是n 个节点同时工作的时候程序所执行的总时长。在实验过程中,根据计算节点的数量我们依次对集群中的节点进行启动,总共5 个计算节点。接着分别将我们所选取的三类不同规模的数据集在所搭建好的集群上进行处理。最后得出实际执行的时间T1~T5,根据上述步骤所绘制出来的加速比曲线如图3所示。

图3 加速比曲线
图3 纵轴表示执行算法所得出的加速比S 值,横轴表示运算过程中计算节点的数量从1 台递增到5 台。由图3 所示曲线我们可以得出,随着集群中计算节点数量从1台机器逐渐增加到5台机器过程中,执行以上三种不同数据规模的电影数据所绘制出的曲线加速比值也在大幅单调增长。通过观察图3 中三条曲线走势,显然可得出随着计算节点数量的逐渐增多,10MB 的大数据量电影数据所执行效率增长较快,而100KB的小数据量电影数据所执行效率增长较为缓慢。另外,当计算节点的数目越来越多的时候,折线图中的曲线加速比值增大的速率会由非线性增长变为线性增长。所以基于Hadoop 平台下的分布式聚类协同过滤算法在数据规模庞大的环境下所执行出来的推荐效率相对较高,同时也可以得出该算法在大数据环境下具有比较好的可扩展性。
在协同过滤推荐中同样也涉及到了相似度计算的问题,可将余弦相似度、皮尔逊相关性系数以及修正余弦相似度三种度量方法应用到Hadoop 大数据平台上进行实验,计算比较绝对平均误差MAE 值,根据结果选择最佳相似性度量方法应用到本文提出的协同过滤推荐算法中,便于查找目标用户的最近邻居。实验结果如图4所示。

图4 相似度计算方法比较
由图4 可得出,在相同实验条件下,三种方法都随着邻域数的增多而降低直到趋于稳定,皮尔逊相关性系数的值在三种方法当中较小,那么采用皮尔逊相关性系数来计算用户簇中项目之间的相似性会提高推荐精度。
另外,对测评算法性能方面,可采用平均绝对误差(MAE)来测评推荐质量,公式如下:

由式(9)可推,当计算出来的平均绝对误差值越小,就表明算法的推荐精度或者质量越高,反之,当计算结果越大,那么算法的推荐准确度就会下降。我们从100 KB 的电影数据集中选取不同数量规模的用户数进行试验,用户数量逐次增加,分别选择50、100、200、500、800 五组数据。并且每组数据按照8∶2的比例,随机抽选划分训练集R1和测试集R2。通过这五组实验数据计算MAE 值,对不同的推荐算法进行试验比较。实验结果如图5所示。

图5 各个数据量的算法效果比较
图5 中横轴指的是试验数据所划分得到的组数,纵轴是我们计算出来的平均绝对误差值的大小。由图5 曲线走势我们可以得出,基于聚类的协同过滤算法MAE 值较小,该算法在性能上明显要比其它两种方法效果好。另外,当电影实验数据量越大,MAE值也会随之变小,推荐质量不断提高,从而可以总结出在较大数据量的条件下推荐准确度更高。同时在实验数据上,第一组数据最为稀疏,到第五组数据相对密集,从图5 中结果我们能够总结出本文算法在对数据稀疏性问题上明显比其他两种算法效果好,它在克服数据稀疏性方面取得了较好效果。
4 结语
本文是在Hadoop 平台下结合改进聚类算法提升了传统协同过滤推荐方法的性能。通过最大值-最小值算法对K-means 做出改进,实现了对改进K-means 算法的MapReduce 并行化设计,并在Hadoop平台下对聚类协同过滤算法实现分布式处理,这种利用MapReduce 计算框架所实现的改进推荐算法大大提高了算法的推荐质量和运算效率。同时本文也探讨了并行化协同推荐算法的评估指标,验证了基于Hadoop 平台的分布式聚类协同过滤推荐算法能够有效地解决数据的稀疏性和算法的可扩展性问题。然而在推荐质量上仍有很多有待完善的地方,同时以后的工作重点可以在算法的推荐性能上再进一步对其优化。
猜你喜欢
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
能源(2017年10期)2017-12-20 05:54:07
电子测试(2017年15期)2017-12-18 07:19:27
能源(2017年5期)2017-07-06 09:25:54
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
智能系统学报(2015年4期)2015-12-27 09:38:39
雷达与对抗(2015年3期)2015-12-09 02:38:50
大众摄影(2015年9期)2015-09-06 17:05:41
电子设计工程(2015年6期)2015-02-27 12:04:53
