
基于网络爬虫的大数据岗位职业技能的分析…
2019-11-11 13:14姚超
电脑知识与技术 2019年27期
姚超
摘要:为了更加客观且全面地了解当下各企业对大数据岗位的职业技能要求,他首先通过网络爬虫技术针对前程无忧网站上各个企业所发布与大数据相关的岗位进行信息提取并保存,然后通过分词技术对提取到的岗位信息进行分词,最后对分词后的数据进行统计分析。通过分析,他得到了相对客观的大数据岗位职业技能需求信息,这为后续地大数据人才培养方案制定提供了更加客观全面的数据支撑。
关键词:网络爬虫;大数据;职业技能;信息抽取;数据分析
中图分类号:TP319 文献标识码:A
文章编号:1009-3044(2019)27-0001-02
Abstract: In order to be more objective and comprehensive about the understanding of the various enterprises vocational skill requirements for big data posts, firstly, he extracted and saved the information of posts related to big data released by various enterprises` on 51job.com through web crawler technology, and then divided the extracted post information into words by word segmentation technology. Finally, he analyzed the data after word segmentation by statistics. Through the analysis, he obtained relatively objective information about the vocational skill demands of the big data posts, and provided more objective and comprehensive data support for the subsequent formulation of big data talent training plan .
Key words:web crawler; big data; vocational skills; Information Extraction; data analysis
2015年国务院印发的《促进大数据发展的行动纲要》[1]这一重要文件极大地加速了大数据行业及大数据职业教育的发展,同时也促使社会对大数据专业人才需求的激增。2016年,《普通高等学校高等职业教育专业(专科)目录》增补了“大数据技术与应用专业”[2],2017年高职院校正式以“大数据技术与应用”专业开始招生。截至目前,“大数据技术与应用”专业还没有毕业生,各高职院校的“大数据技术与应用”专业均处于探索研究阶段。为了能够更加客观且全面地了解当下各企业对大数据岗位的职业技能要求,从而实现对当前高职院校“大数据技术与应用”专业人才培养方案的修订与完善,本文将通过网络爬虫等技术从前程无忧招聘网站上获取有关大数据岗位相关信息并做分析。
1 整体设计
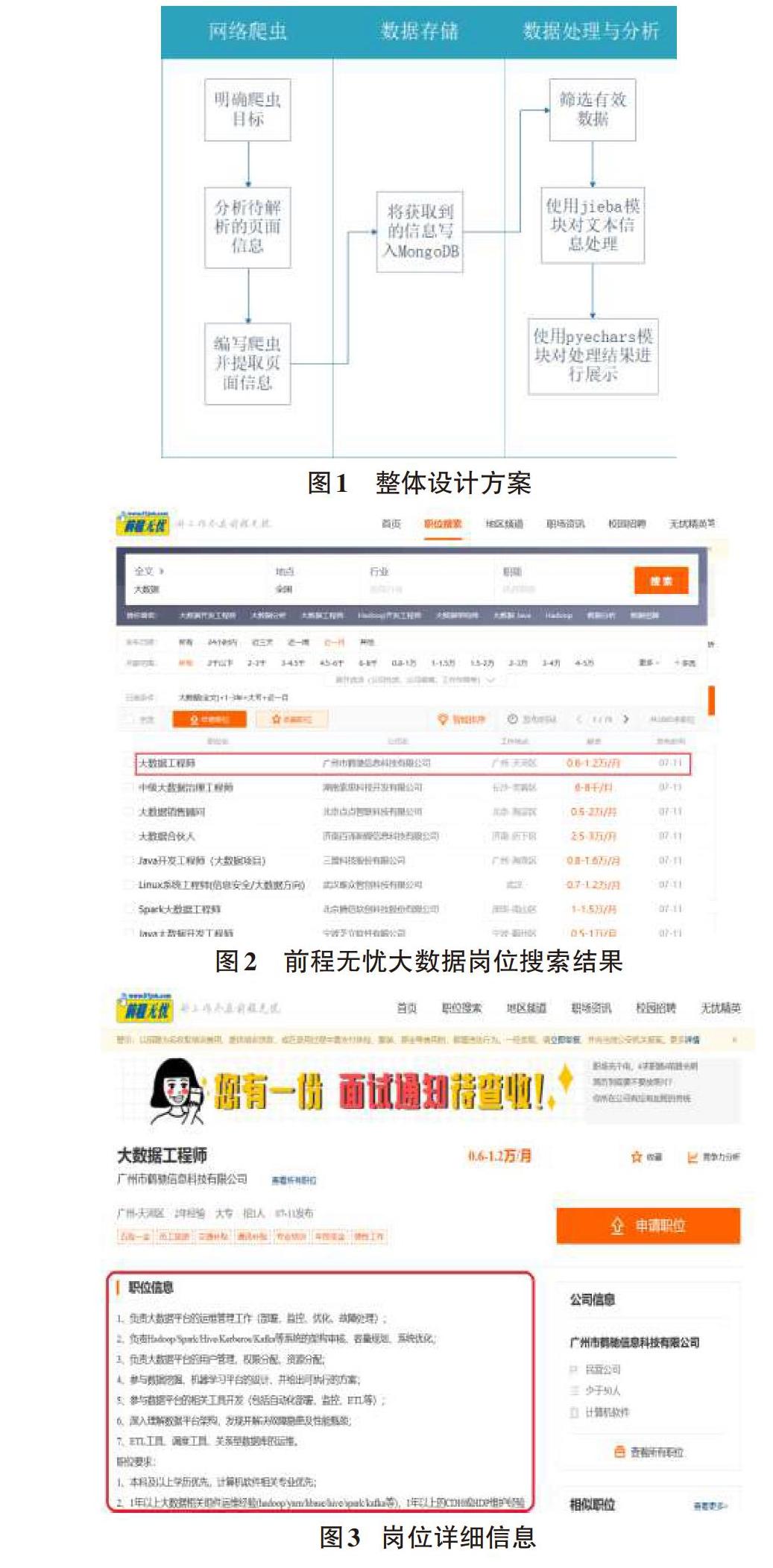
为了实现获取大数据岗位信息并进行分析,本文的功能涉及三个模块:网络爬虫、数据储存和数据处理与分析。其中网络爬虫的实现方案有很多,因为Scrapy框架具体高效和功能强大等特点[3],本文采用Scrapy框架实现网络爬虫以获取的大数据岗位相关信息。由于MongoDB具有高性能、易部署、易使用、存储数据非常方便等特点[4],本文的数据存储模块采用MongoDB来保存获取到的大数据岗位信息。因为通过爬虫获取到的岗位信息数据均是中文文本信息,本文需要对中文文本信息进行分词处理然后再分析,jieba模块是目前最好的Python中文分词组件[5],因此本文采用jieba模块来对岗位描述的文本信息进行处理并使用pyecharts模块来对分析的结果进行展示。具体的设计方案如图1所示。
2 大数据岗位信息获取与存储
2.1 网络爬虫的设计与实现
1) 明确爬虫目标。
根据需求,本文将关注的焦点放在前程无忧招聘网站上有关专科学历的大数据岗位信息。如果只搜索以上信息,将会出现大量与大数据岗位不符合的信息,如:销售员、电话客服等。为避免此种情况出现,本文将搜索范围限定在有1-3年工作经历的招聘岗位上,此時得到的信息将更加符合大数据专业。具体的搜索结果如图2所示,其中被矩形框标记的内容则是本文所需要的部分信息。在图2中可以发现其中仍然包含有极少量无效信息,因此本文将在后面的数据处理过程中对这些数据进行更深入地筛选过滤。此外,以上页面的内容并不能满足本文用于职业技能分析的要求,还需要将每个岗位的详细信息提取出来,详细页面如图3所示,其中矩形框标记的内容则是本文所需要的核心信息。
2) 分析待解析的页面信息。
通过第1步得到两个待解析的页面:大数据岗位搜索结果页面、岗位详情页面。这里可以通过浏览器所提供的“查看元素”功能来分析整个页面的文档结果及要爬取信息在页面中的位置。通过分析可以得到每个页面上所要爬取信息如下:搜索结果页面的职位名、公司名、工作地点、薪资、岗位详情链接、下一页链接等;岗位详情页面的职位信息。
2.2 大数据岗位信息储存
当scrapy获取到数据后,这些数据将会被传递到pipeline中进行下一步处理。本文通过编写实现pipeline中的process_item(self, item, spider)方法,将传递过来的数据通过MongoDB的insert()方法直接写入MongoDB数据库中。为了能够让数据可以被传递到pipeline中,这里需要提前设置好setting.py中的“ITEM_PIPELINES”信息,要确保该参数存在且未被注释。
3 大数据岗位信息处理与分析
3.1 数据筛选
在2.1节中已经发现爬取到的数据中还有少量岗位信息为客服和销售岗,因此在进行数据处理与分析前,要把这些信息从有效数据中过滤掉。这里最直接的思路是在查询数据库是将这些数据过滤掉,但是MongoDB数据库在查询过滤功能与其他数据库不同,它所采用的是正则表达式。本文所需要的数据中其岗位名称不包含“销售”和“客服”等字符,结合正则表达式相关语法规则设计出符合该功能的正则表达式为“^((?!销售|客服).)*$”[6]。
3.2 数据处理与分析
常见的数据处理包含:数据错误处理、缺失值处理、离群值处理、中文jieba分词、去停用词处理等[7]。本文主要采用中文jieba分词和去停用词处理两种数据处理方法。如果不采用去停用词处理,这里将得到大量与最终要求无关的统计信息,如:优先、熟悉、掌握等。去停用词处理可以节省存储空间和提高搜索效率,停用词专指在处理自然语言数据或文本时自动过滤掉的字或词[8]。
大数据岗位信息处理完成后,本文采用TF-IDF(term frequency-inverse document frequency)[9]统计方法来对其进行分析,以确定各种计算机专业相关的职业技能在大数据岗位中的重要程度。
3.3 结果展示
通过3.2节中对大数据岗位信息的处理,并使用TF-IDF统计方法进行分析后,为了更加清晰明了地展现分析后的结果,本文采用pyecharts模块中的柱状图Bar来呈现结果,具体如图4所示。通过该分析结果可以非常明显看出:对于大数据岗位来说,数据库、数据分析、Java、MySQL、Linux、Python、Hadoop等是非常重要的职业技能;此外可视化等相关技术、数据结构、网络爬虫等职业技能也是较多企业对大数据人才的要求。
4 结束语
以前,我们要想知道指定岗位所需要的职业技能都是通过调查部分企业来实现的。通过这种方式,我们所得到的结果不全面,有时还会因为企业给出的信息较随意使得结果不客观,甚至会出现偏差。本文通过网络爬虫技术爬取前程无忧网站上各个企业所发布与大数据相关的岗位进行信息并保存到MongoDB中,同时使用中文jieba分词、去停用词处理等对数据进行处理并使用TF-IDF统计方法对处理后的数据进行分析,最后得到了一组相对客观的大数据岗位职业技能需求信息,这为后续地大数据人才培养方案制定提供了更加客观全面的数据支撑。
参考文献:
[1] 中华人民共和国国务院.促进大数据发展行动纲要[Z].北京:中华人民共和国国务院,2015.
[2] 中华人民共和国教育部.《普通高等学校高等职业教育(专科)专业目录》2016年增补专业[Z].北京:中华人民共和国教育部,2016.
[3] 黑马程序员.解析Python网络爬虫:核心技术、Scrap框架、分布式爬虫[M].北京:中国铁道出版社,2018:175-178.
[4] 百度百科.mongodb[DB/OL].[2019-07-10].https://baike.baidu.com/item/mongodb.
[5] Gaius_Yao.簡明jieba中文分词教程[M/OL].[2019-07-10].https://www.jianshu.com/p/883c2171cdb5.
[6] (美)Goyvaerts Jan, Levithan Steven.正则表达式经典实例[M].郭耀译.北京:人民邮电出版社,2010:273-304.
[7] 李光明,潘以锋,周宗萍.基于自然语言处理技术的学生管理论坛文本挖掘与分析[J].智库时代,2019(29):122+127.
[8] 百度百科.停用词[DB/OL].[2019-07-10].https://baike.baidu.com/item/停用词.
[9] 冯勇,屈渤浩,徐红艳,等.融合TF-IDF和LDA的中文FastText短文本分类方法[J].应用科学学报,2019,37(03):378-388.
【通联编辑:朱宝贵】
猜你喜欢
四川劳动保障(2021年5期)2021-07-19
工会信息(2020年21期)2020-02-28
中国新通信(2016年21期)2017-01-06
商场现代化(2016年22期)2016-10-18
学习月刊(2016年14期)2016-07-11
出版与印刷(2013年4期)2013-12-15
