
空间多关键词Skyline查询算法
2019-11-11 02:22:14李星罗秦小麟周杨淏鲍斌国
小型微型计算机系统 2019年10期
李星罗,秦小麟,王 宁,周杨淏,鲍斌国
(南京航空航天大学 计算机技术与科学学院,南京 210016)E-mail:lxldblab@nuaa.edu.cn
1 引 言
随着信息技术的高速发展,数据已经成为了重要的战略资源.如何从海量数据之中挖掘用户最感兴趣的信息,做出满足用户偏好的决策,这使得越来越多的研究者开始关注Skyline查询.Borzoniy等人[1]在2001年提出了Skyline查询,查询结果为一组相对较优的多维数据集合,该集合中的数据点均不被其余数据点所支配.Skyline查询与现实生活紧密相关,近年来被广泛应用于多目标决策、分布式P2P网络以及用户偏好查询等领域[2].为了更好地满足用户查询偏好性需求,Choi等将Skyline查询与关键词匹配搜索相结合,以查询关键词作为用户语义型偏好,提出了关键词Skyline查询[3].例如,用户提出一个查询:希望找到一家服务质量高且价格低的海鲜餐厅,其中“海鲜”、“餐厅”即为查询关键词.
随着移动终端设备的普及和移动应用的快速发展,基于空间位置的服务获得了越来越多人的关注.人们在日常生活中往往会提出如下查询:
查询1.查询用户周围距离近、价格低、服务质量高的旅店,最好拥有地下车库.
查询2.查询学校周围距离近、口味好、价格低的餐厅且用户更偏爱于川菜.
查询3.查询城市周围距离近、环境好、交通便利的风景区,最好景点内部可以住宿.
上述查询可以概括地表述关键词空间Skyline查询问题.在查询的过程中,对象点与查询点间的距离为一个相对的动态空间属性,属性值随着发起查询的位置变化而变化.目前已有的算法仅仅关注于静态非空间属性,不能直接用于解决上述查询问题,需要重新考虑并建立一个基于空间文本对象的支配关系模型.
同时,现有的关键词Skyline算法无法很好地解决用户偏好性.INKS算法与KMS算法通过查询关键词与对象包含的关键词进行匹配,筛选出满足查询条件的候选对象集[3].而IPOT算法通过将关键词按照用户偏好进行偏序化,每个查询关键词作为一个新的维度进行Skyline计算[4],但是随着查询关键词数量的增加,维度的变化将直接影响Skyline查询的效率;查询关键词之间的权重关系,即用户查询语义,上述算法均没有进行定量计算.
此外,现有算法的剪枝优化策略仅仅关注于关键词信息,候选集中的对象还需根据查询空间要求进行二次过滤.所以造成了对象的重复遍历与判定,使得算法查询效率受到了一定影响.
基于上述问题,提出了一种基于加权距离的空间文本支配模型,并构建了一个针对空间文本对象的索引结构,能够有效处理空间多关键词Skyline查询.本文主要贡献如下:
1)针对用户多偏好需求问题,提出了一种基于加权距离的空间文本支配模型;提出了相应的枝剪策略,减少了支配判定计算开销,提高了算法的执行效率.
2)提出了一种基于R-Tree的空间文本索引结构.并利用位图结构,快速且准确地定位满足条件的空间文本对象,极大地提升了算法的查询效率.
3)采用模拟数据集对SKS算法进行了对比实验,并在真实数据集上进一步验证了算法的有效性,实验结果表明,SKS算法相较于现有算法更为高效.
本文结构如下:第二节介绍空间多关键词Skyline查询的基础知识和相关工作,并分析现有方法在解决多关键词匹配问题和Skyline支配计算时的不足;第三节提出了空间文本索引STR-Tree,并对其进行了详细的说明;第四节基于索引提出了空间多关键词Skyline查询算法SKS;第五节对SKS算法进行了实验评估,并与现有算法进行性能对比;最后对本文工作进行了总结与展望.
2 背景及相关工作
2.1 空间多关键词Skyline查询概述及定义
在本小节,我们针对欧式空间下关键词Skyline查询进行了形式化描述,并进一步讨论其相关性质.
假定空间文本对象点集O是一组含有n维属性的点集,对象点包含m维动态空间属性,例如查询点q至对象点o的距离值随查询点与对象点的位置变化而发生改变,属于动态空间属性.我们将查询点q至对象点o的空间距离d(o,q)作为唯一的动态空间属性考虑.其余n-m维属性为静态非空间属性,亦称文本属性.我们将文本属性进行扩展并划分为两类,如表1、表2所示:第一类为数值型文本属性,例如价格、好评度等;第二类为语义型文本属性,即对象描述性关键词.
为了便于描述及后续支配计算,若存在某数值型属性,其值越大表现越优,则对其进行相应的预处理操作:p(oi)=maxValuei-p(oi).其中,p(oi)表示对象点o在第i维的属性值,maxValuei表示该维度上属性值的最大取值.因此,对于下文中对象点所有数值型属性,假设其值越小表现越优.
定义1.(非空间支配[1])对于任意两个对象点oi,oj∈O,其中i≠j,且在所有非空间属性上,oi均不弱于oj,且至少有一维,oi优于oj.以上情形,我们称之为oi在非空间属性上支配oj,形式化地表述,oinsoj.而所有在非空间属性上支配oj的兴趣点集合我们称之为oi的非空间属性支配域,用符号Domns(oj)表示.
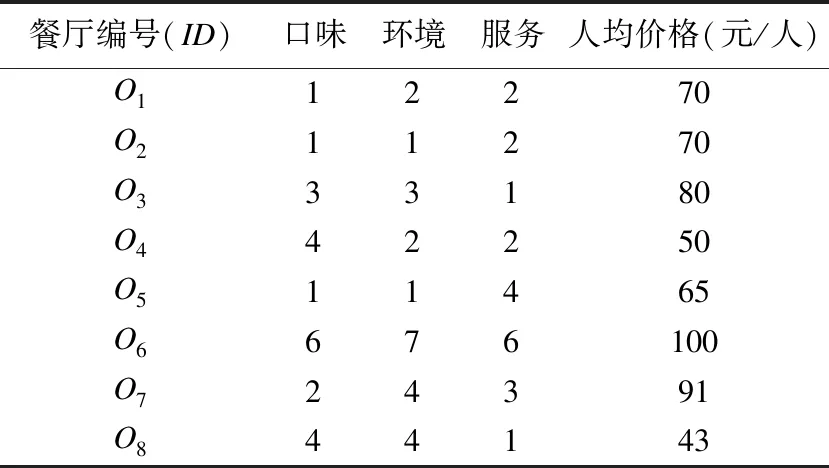
表1 餐厅数值型属性信息Table 1 Restaurant numeric attribute informationt
定义2.(基于多关键词匹配的加权距离)对于给定的查询点q以及其对应的查询关键词q.w,与空间上任意一个对象点oi,若关键词相似度W(oi.w,q.w)=0,其加权距离为一个极大值;若W(oi.w,q.w)>0,其加权距离为欧式空间距离d(oi,q)除以两点间的关键词相似度W(oi.w,q.w),结果记为dt(oi,q),公式化抽象表示为:
dt(oi,q)=d(oi,q)/W(oi·w,q.w)
(1)

表2 餐厅语义型属性信息Table 2 Restaurant semantic attribute informationn
其中,关键词相似度W(oi.w,q.w)用来表示查询关键词与对象所包含的关键词之间的相似程度.对于用户给定的一组查询关键词,每个查询关键词都有与之相对应的用户偏好权重,该偏好权重可以由用户直接给出或者为系统默认值.假定查询用户q的查询关键词q.w={Seafood,Resturant},偏好权重分别为0.6、0.4.对于对象o4.w={Nightlife,Golf},由于无关键词能与查询关键词匹配,因此其关键词相似度W(o4.w,q.w)=0*0.6+0*0.4=0,根据加权距离定义,由于关键词相似度为0,通过计算可得其加权距离为一个极大值;对于对象o1,o1.w={Seafood,Resturant},因而其关键词相似度为W(o1.w,q.w)=1*0.6+1*0.4=1.因此,与查询关键词完全不匹配的无关对象点,可以先行剪枝,减少相应支配计算开销,提高查询效率.结合关键词的加权距离,以下提出一种新的空间文本支配关系.
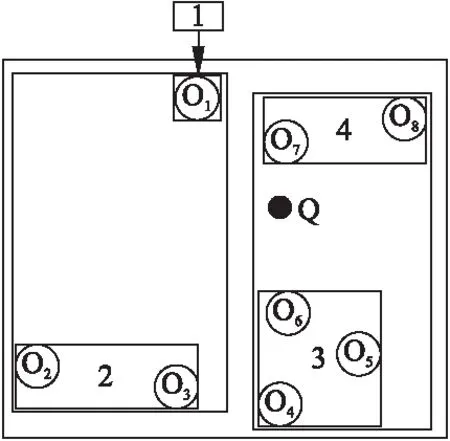
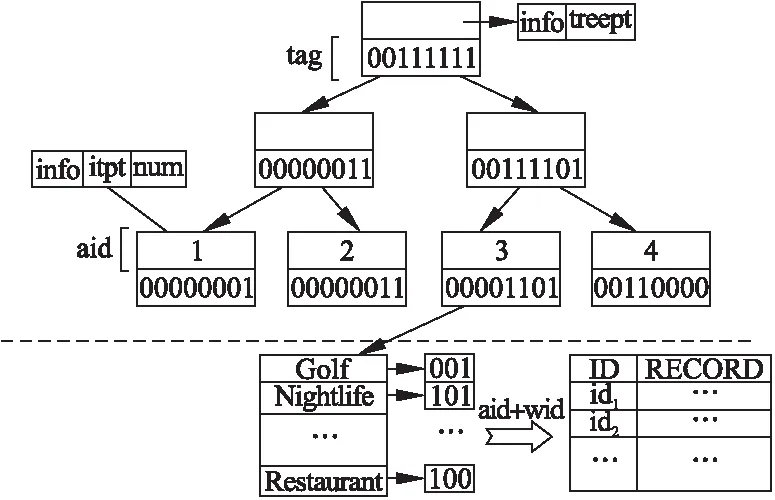
定义3.(空间文本支配)对于给定的查询点q以及空间上任意两个对象点oi,oj∈O,其中i≠j,若存在以下情况:若oinsoj,且dt(oi,q) 相比与传统文本支配,空间文本支配相当于在其基础上人为地新增了一个维度.该维度对应的属性值随查询关键词以及查询点的空间位置的改变而改变,支配关系无法在查询发起前先行计算,这样查询效率将受到很大的影响. 定义4.(空间多关键词Skyline查询(SKSQ))对于给定的查询点q、查询关键词q.w、查询空间范围R以及空间对象点集O,该查询过程分为以下两步: 1)遍历对象点集O,筛选出满足以下条件的所有对象点构成候选集C,如果∃oi∈O,d(oi,q)≤R且oi所包含的关键词oi.w与查询关键词q.w部分匹配,则oi∈C,即对象oi属于候选对象集C,该过程记为:SKQ(O.w,q.w,R)={C|C⊆O∧oi∈C,oi.w∩q.w≠Ø,d(oi,q)≤R}. 2)对候选集进行空间Skyline计算,所得到的结果集记为SKSP(Spatial Keywords Skyline Point),其中SSQ为空间Skyline查询结果集,结果集记为SP.而对于空间多关键词Skyline查询过程,可以抽象表示为: SSQ(Q,q)={SP|SP∈O∧o∈SP,Domst(o)=} (2) SKSP=SKSQ(Q,q,R)=SSQ(SKQ(O.w,q.w,R),q) (3) 图1 用户与对象点空间位置分布Fig.1 Spatial distribution of objects and user points 以表1中的对象为例,查询点与对象空间位置关系如图1所示.若查询关键词为“Seafood”、“Restaurant”,且用户偏好权重默认相等,即均为0.5,则满足查询关键词的对象候选集为{o1,o2,o6},根据定义4,空间多关键词Skyline查询结果为{o1,o2}. Borzsonyi[1]提出了两个著名的Skyline算法:BNL与D&C并应用于传统的关系数据库系统之中.虽然有很好的普适性,但是算法执行效率较差.后续有学者陆续提出了基于R-Tree索引的Skyline查询算法:NN[5]和BBS[6]算法,NN算法通过递归的方法搜索文本区域最近邻点,并通过相应的剪枝策略删除被该对象支配的所有对象;BBS算法与NN算法类似,同样是采用了基于R-Tree索引的最近邻搜索策略,该算法通过维护一个堆结构来存储必须被访问的对象,并利用分支界限法筛选出符合条件的Skyline对象. 随着Skyline应用场景越来越多,语义型文本属性开始进入学者们的考虑范围.Wong[4]将数值型属性按照传统的偏序关系进行计算,而语义型属性因为用户偏好不同,偏序关系亦各不相同.因此该算法针对于语义型属性通过用户自我拟定的偏序关系进行Skyline计算;Choi等[3]提出了关键词Skyline查询,并提出相应的查询算法:INKS与KMS算法.INKS算法通过使用倒排表的方法获取满足查询关键词的候选集,在其之上利用BNL算法计算得出最终结果集,该方法拥有良好的普适性但在多关键词查询过程中效率较低.而KMS有效地解决了这一问题,利用IR2-Tree树,通过签名文件之间高效的位运算从而快速过滤与查询不相关的文本对象,但由于IR2-Tree是一种基于空间R-Tree的信息检索树,在维度较低时效果较好,随着查询维度的增加,其效率将显著下降.Shi[7]提出了一种面向多用户的空间文本关系模型STD,并利用IR-Tree索引结构,给出了一种可以高效地解决多用户查询问题的空间文本Skyline查询算法ASTD. 近年随着基于位置服务的应用高速发展,学者开始将Skyline查询引入空间数据库、时空数据库等相关应用的研究之中.Sharifzadeh等学者[8]提出了空间Skyline查询:SSQ算法,其针对于多用户环境,以各用户距对象点的空间距离构建各个标准维度,旨在选择一组距离相对所有用户最优的对象.由于SSQ算法在实际生活中普适性较差,因此Son等学者[8]在SSQ算法的基础上提出了基于曼哈顿距离空间Skyline的算法,Fu等学者[10]提出了一种基于道路网空间的连续范围Skyline算法. 对于空间关键词查询,许多学者也做了许多相应的研究工作.最初为了解决空间最近邻问题,学者提出了R-Tree索引结构[11],该索引是一种高度平衡树且利用MBR对空间进行有效的分割,保证了50%以上的空间利用率.学者们在R-Tree基础上添加了位图结构以及倒排索引,通过将空间信息与文本信息相结合的方式,可以有效地解决空间关键词查询问题.上述索引结构可以统称为空间文本索引结构,按照空间与文本优先关系,空间文本索引可以分为三类,基于空间优先:R*-IF[12]、IR-Tree[13]、IR2-Tree[14]索引等;基于文本优先:I3[15]、S2I[16]、IL-Quadtree[17]索引;松散组合:R-Tree+倒排索引[18,19]、SFC-QUAD[20]. 综上所述,现有算法在解决空间多关键词Skyline查询上无法有效地解决用户偏好问题,导致结果集质量下降.部分算法在解决多关键词匹配的问题上效率底下,对应的索引结构易产生过多的数据冗余.为解决上述问题,本文提出了一种空间文本索引STR-Tree,基于该索引结构,提出了一种高效的空间多关键词Skyline查询算法SKS. 基于上述概念,为解决空间多关键词高效匹配问题,我们提出了一种混合索引结构——空间文本索引STR-Tree. 该索引结构从逻辑上分为两层:上层索引对R-Tree索引结构进行了扩展,在节点中增加了表示对象关键词信息的签名文件,用于描述对象所处区域的空间与关键词信息间关系;下层索引为倒排表结构,用于描述关键词信息与对象本体间对应关系. 图2展示了基于R-Tree索引的对象划分情况,对最小且不可再分的MBR按照空间从上至下,从左至右的规则进行顺序编号.根据编号,我们对于空间文本对象id进行了重新编码:id=aid+wid.其中aid表示该区域的编号,wid表示对象在该区域的内部编号,例如对象o2在区域的内部编号为1.若假定区域容纳空间文本对象的数量上限值为3,只需个位即能表示区域内部所有对象,且对象所在区域的编号为2,编码后对象o2的id为21.结合上述空间划分及对象编码情况,我们建立了如图3所示的空间文本索引结构——STR-Tree. 图2 基于R-Tree空间对象划分Fig.2 Partitioning spatial objects based on R-Tree 对于上层索引,中间节点存储如下信息 图3 STR-Tree索引结构示意图Fig.3 STR-Tree index structure diagram 其中签名文件为一串定长的二进制码(此例中假定二进制码的长度为8),我们通过一个既定的hash函数将关键词映射至二进制码中对应的bit位,即将该位的0修改至1.但是对于定长的二进制码,若关键词的数量过多,必定会出现不同的关键词通过hash函数映射至相同的bit位,即位冲突,还需进行后续准确地关键词比较操作,这样大大影响了查询效率.对此,我们将关键词分为两类:第一类关键词为描述对象本身性质的关键词,如:Golf、Restaurant、Bars等;第二类为描述对象特征的关键词,如Seafood、Nightlife等.前者类型的关键词数量远远小于后者,且查询关键词中必定包含第一类关键词.我们对此类关键词构建签名文件,一方面降低位冲突发生的概率;另一方面,通过签名文件,在查询过程中可以先行过滤与查询关键词无关的空间区域,并剪枝大量的无关对象点. 例如,编号为2的叶子节点,对应空间区域包含的第一类关键词为:Restaurant、Bars,其中,Restaurant通过hash函数生成的结果为0000001,同理,Bars对应为00000010.我们通过对上述两段二进制码进行OR操作,生成签名为00000110,通过该签名即可同时表示Restaurant、Bars两种不同的一级关键词信息.查询关键词依旧可以遵循上述过程生成一个新的签名S,将该签名S与查询区域所对应的签名Si执行AND操作,若SAndSi=S则表示该区域内的关键词包含查询关键词,反之,则不包含.因此通过该操作可以避免继续访问不包含查询关键词的下级节点,有效地提高了搜索效率. n.tag=c1.tag∨…∨ci.tag (4) 其中n.tag为父节点的签名信息,c1.tag至ci.tag为父节点n对应的所有子节点的签名信息. 对于下层倒排索引,如图3所示,索引中每个节点存储如下信息 基于上述索引结构,在本小节我们提出了SKS算法来解决空间多关键词Skyline查询问题.算法SKS在遍历STR-Tree索引的过程中,在将上层索引节点对应的区域位置信息与查询区域信息进行相交区域判定的同时,通过节点对应一级关键词的位图信息与查询关键词间的比较,算法从空间与文本两方面对空间文本对象集过滤.而当算法遍历至叶子节点时,则通过下层倒排索引,利用bit间的快速位运算,获取满足所有查询关键词的对象,即该子区域内的候选集.基于STR-Tree索引的空间多关键词Skyline查询算法如下所示: 算法1.空间多关键词Skyline查询算法 SKS 输入:查询点q,查询关键词q.w,查询范围R,空间文本对象点集O,STR-Tree索引 输出:空间多关键词Skyline结果集 SKSP 1.SP← {};C←{}; 2.While!nodeStack.isEmpty()do //以深度优先搜索的方式遍历索引 3.N←nodeStack.pop(); 4.IfN.isInRange(q.w,R)then //若当前区域满足查询关键词q.w与查询范围R 5.IfN.isLeaf()then 6.C←getCandidate(q.w); //遍历当前区域对应的下层倒排索引 //计算当前区域内满足查询关键词的候选集C 7.ForeachcinCdo 8.SP←calculateSkyline(SP,c,q.w,R); 9.Else 10.nodeStack.push(N.getChildNode()); //若不为叶子节点,则将孩子节点进栈 对于算法1,第2至3行,以栈的方式维护尚未访问的STR-Tree上层索引节点;第4至6行对访问区域进行判断,若为叶子节点则通过下层倒排索引计算出满足查询条件的候选集C;第7至9行,循环调用calculateSkyline方法,进行空间文本支配判定并生成新的中间结果集SP. 由于候选对象与中间结果集间复杂的空间文本支配计算,导致算法1中calculateSkyline方法是该算法中最耗时且最频繁的操作.为此,需要通过优化空间文本支配计算过程来提高查询效率. 定理1.若存在某个空间文本对象oi∈C,其加权距离小于中间结果集中距查询点最近的对象点,则该对象oi一定属于中间结果集SP. 证明:假设对象oi不属于中间结果集SP,则SP中必定存在一个对象点sp∈SP,使得sp空间文本支配oi.根据定义3,则spnsoi,且dt(sp,q) 定理2.对任意的空间文本对象o1,o2∈O,若o1,o2之间不构成文本支配,则o1,o2必定不构成空间文本支配. 证明:由于对象o1,o2之间不构成非空间支配,因此对查询点q而言,q位于空间任意位置,o1,o2之间必定不能在文本属性以及空间属性上同时构成支配,因此根据定义3,o1,o2必定不构成空间文本支配. 基于上述定理1和定理2,我们采用了如下过滤策略: 1)最小值过滤法:通过一个小顶堆结构对中间结果集SP进行维护,其中堆顶对象sp即为SP中距查询点p加权距离最近的点.若存在候选对象c的加权距离小于sp,根据定理1,对象c一定属于中间结果集SP.因为SP中对象均在空间属性上弱于c,所以后续只需要进行文本支配判定,并直接删除SP中所有被c文本支配的点. 2)求和过滤法:考虑对象在数值型文本属性上所有属性,我们将其值的和作为该过滤策略判定的依据.对于任意一个对象点o,其在属性维度NS的过滤公式设计如下: (5) 上述公式表示对象点o在属性维度NS上的过滤值S(o),而该过滤值即为点o的非空间属性值之和.由于该过滤方法时间复杂度为O(1),相比于时间复杂度为O(d)(其中d为数值型文本属性的维度值)的文本支配判定,可以简单地先行判定两个对象点之间的支配关系.对于任意两个对象点o1和o2,若S(o1)S(o2),即表明对象o2在属性维度NS上不可能文本支配对象o1,因为至少有一个维度上o2的值大于o1.因此,通过补充判定对象o1是否文本支配o2,若双方无文本支配关系,结合定理2,可以发现o1和o2间不存在空间文本支配关系,则不必继续计算,直接进行剪枝,从而提高了算法的执行效率. 算法2.空间文本支配判定算法 calculateSkyline 输入:查询中间结果集SP,候选对象c,查询关键词q.w,查询范围R 输出:查询中间结果集SP 1.sp← getHeapTop(SP); 2.Ifdt(c,q)< dt(sp,q)then 3. textualDetele(SP,c);//删除SP中所有被c文本支配的点 4. insertcintoSP; 5.Else 6. For eachspinSPfrom the Heapdo//遍历堆中所有对象 7. IfS(c)≤S(sp)then 8. Ifc∉Domns(sp) then//不构成文本支配 9. continue; 10.Elseifdt(c,q) 11. deletespfromSP;//删除SP中被c支配的点sp 12.Else 13. Ifsp∉Domns(c)then//不构成文本支配 14. continue; 15.Elseifdt(sp,q) //若c被SP中的某一点支配 16. break; 17.Ifsppoints to NULLthen //指向堆末,表明遍历完所有对象,即当前堆中对象c 不存在控制关系 18. insertcintoSP; 对于算法2,其中第1至4行通过最小值过滤法对于候选集进行枝剪;第6至9行通过求和过滤法进行先行支配判定;第10至11行,删除SP中被支配的对象;第15至16行,若候选对象被支配,则跳出循环. 为验证SKS算法的性能及其有效性,我们设计了多组实验对SKS算法进行测试.由于现有的工作中没有用于专门解决空间多关键词Skyline查询的方法,因此将SKS算法与可以解决该问题的INKS算法和ASTD算法进行比较.INKS算法基于倒排索引,快速检索出满足查询条件的空间文本对象,并计算出Skyline结果集;ASTD则利用IR-Tree对无关对象点进行过滤. 我们从两方面验证了SKS算法的有效性:首先,在小规模数据集上,算法计算结果与理论计算结果相同;其次,与INKS算法和ASTD算法的执行结果进行对比,结果均保持一致,进一步证明算法的有效性.另外,为了更好地避免随机性,算法查询性能最终指标以相同环境下10次测试,并除去最大最小值后剩余8次测试值的平均值作为依据. 实验环境为:Windows10操作系统,Intel Core i7处理器,主频3.30GHz,内存4GB.上述算法均用Java语言实现,编译器为IntelliJ IDEA. 实验采用模拟数据集进行测试,并在真实数据集上对SKS算法进一步验证.其中,模拟数据集分为独立数据集、相关数据集、反相关数据集三种,数据集中所有空间文本对象点均随机生成,对象点对应的空间横纵坐标均在[0,100]的数值范围内随机取值.对于数值型文本属性由文献[1]提及的数据生成器产生,各维度数值为区间[0,100]上的随机值,且规定数值越小即表示该维度上的属性表现越优,同时与之对应的语义型文本属性从既定的词典中随机选择生成.真实数据集采用yelp商业点评网站的开源数据集,数据集中包含美国菲尼克斯等城市的85,883个商铺的详细信息,我们将数据集中的经纬度作为空间位置信息,商铺的分类信息作为语义型文本属性,其余星级、浏览量等指标作为数值型文本属性. 为了便于与模拟数据集之间进行比较,我们对真实数据集上数值型属性进行了处理,使全体数据能够映射到区间[0,100],数值转换函数如下: (6) 其中p(oi)表示空间文本对象o在维度i上的取值,minValuei与maxValuei表示所有对象在维度i上的最小取值与最大取值. 为了分析与验证不同数据量下对于算法的影响,我们采用了独立数据集,相关数据集,非相关数据集三种模拟器数据集进行实验.其中空间文本对象个数n由100K到500K变化,数据集中数值型数据维度为5维.查询点q的空间位置坐标为随机产生,其包含的查询关键词数量为3,查询半径为30单位长度.本次实验以查询开始至查询结束的CPU时间作为查询算法性能的评价指标. 图4 数据量对算法性能的影响Fig.4 Performances with scalability of dataset 图4为不同数据量下对应三种不同数据分布情况的三个算法性能测试结果.通过对比分析可以得出,随着数据量的上升,三种算法的执行计算时间均有所提高.同时可以明显得出,在数据量为100K时,三种数据分布下INKS算法查询计算所用的时间约为SKS算法的2倍以上.且随着数据规模的逐渐增大,SKS算法相较于其他两个算法优势越发凸显.主要是因为SKS算法在计算过程中,利用STR-Tree快速检索出满足查询条件的有笑点,并利用剪枝策略对支配判定过程进行优化,从而大大减少了访问无效对象点的次数和支配计算开销. 另外,从数据分布的角度来看,由于相关数据集、独立数据集与反相关数据集的Skyline结果数依次递增,因此对象间支配判定计算的次数也依次递增.INKS算法与ASTD算法对于数据分布的敏感度不高,尤其是在反相关分布的情况下,上述两种算法的效率有了明显的下降.但SKS算法在支配计算的过程中,基于空间文本支配关系提出了两种相应的过滤策略,使得在数据分布发生变化时,查询效率没有受到过多的影响. 实验旨在验证查询关键词数量的变化对于算法性能的影响程度.因此,考虑在数据分布为独立分布的情况下,测试数据集中空间文本对象为200K个,数值型属性维度为5.在查询点q空间坐标保持不变的情况下,查询关键词数量由1到10进行变化,查询半径为30单位长度. 图5 查询关键词数量对算法性能的影响Fig.5 Performances with the number of query keywords 如图5所示,为不同数量的查询关键词在独立数据集下对于三种查询算法性能测试结果.在查询关键词数量较低的情况下,INKS算法效率较好,由于该算法利用倒排索引结构,可以直接检索出满足查询条件的有效对象点.随着关键词数量的增加,因为倒排索引无法高效地解决冗余数据的判重问题,因此INKS算法效率逐渐降低.而SKS算法针对多关键词匹配问题利用签名文件,将对象id映射至对应的bit位上,并利用基于位图匹配的倒排索引结构,实现了快速的有效对象点检索.在关键词数量较高时,SKS算法的优势越发明显,关键词数量为7时,相比于ASTD算法查询性能提高了近90%. Skyline查询计算过程中,空间文本支配关系的计算次数随着数值型文本属性的维数增加而增加,并且直接影响到查询效率的高低.因此,以下讨论数值型属性维度的变化对于算法性能的影响.实验采用独立数据集,其中空间文本对象个数为200K个,数值型属性维度为2至8维进行变化.查询点q的空间位置坐标随机产生,查询关键词数量为3,查询半径为30单位长度. 图6为不同维度下三种算法的查询性能测试结果.由上图可以得出,ASTD算法在数据维度较小时表现较优,但是随着维度的升高,算法的性能逐渐降低,尤其到了维数为6的时候,性能下降程度明显.而SKS算法在低维度的时候算法性能与ITS算法不相上下,主要是此时遍历索引的时间耗费成为了制约因素;而随着数据维度的升高,SKS算法通过采用了相应的剪枝机制,有效地减少了无关对象点间数值型属性间支配关系计算开销,维度为8时,ASTD算法计算所用时间约为SKS算法的3倍. 图6 数值型属性维度对算法性能的影响Fig.6 Performances with numeric attribute dimension 实验采用了yelp点评网站上的开源数据集对于算法性能进行了进一步验证,数据集中包含来自美国菲尼克斯等11个城市85883个商铺信息,每个商铺对应的数值型文本属性维度为3,查询点q随机产生,查询关键词数量为3,查询半径由10度到50度(经纬度)之间变化. 图7 真实数据集下的算法性能Fig.7 Performances with real-life dataset 图7展示了在真实数据集下查询范围变化与算法执行效率的关系.由图可以分析得出,随着查询经纬度的范围扩大,被查询点数量也随之增加,查询算法的效率均有所降低.在真实数据集下,SKS算法相较于其余两种算法具有较高的查询效率,与模拟数据集下的实验测试结果保持一致,进一步证明了SKS算法的高效性. 本文从用户提出多角度偏好的需求出发,针对空间位置动态变化问题进行深入研究,提出了一种空间多关键词Skyline查询解决方案.为了快速处理空间多关键词匹配并有效地剪枝无关空间区域,提出了一种空间文本索引结构STR-Tree;在该索引结构基础上,提出了一种高效的空间多关键词Skyline查询的算法SKS.最后,在模拟数据集与真实数据集上进行实验,结果表明本文提出的方法能够有效地解决空间多关键词Skyline查询问题,且拥有更为优良的查询性能. 上述工作可以很容易地扩展至道路网环境.另外,未来研究工作将重点关注如何解决多用户环境下的空间关键词Skyline查询,引入交互式查询思想,以解决用户偏好不一致问题.
2.2 相关工作
3 空间文本索引STR-Tree
4 空间多关键词Skyline查询算法
5 实验及分析
5.1 数据集设置
5.2 数据量对算法性能的影响
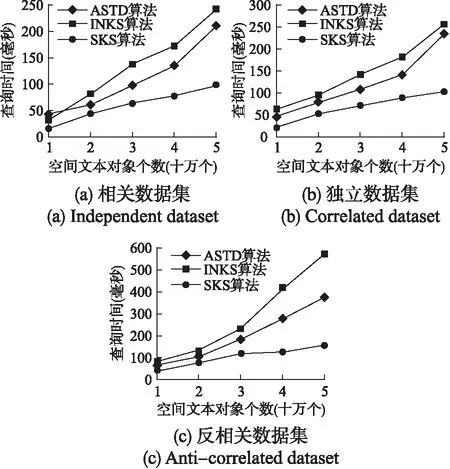
5.3 查询关键词数量对算法性能的影响
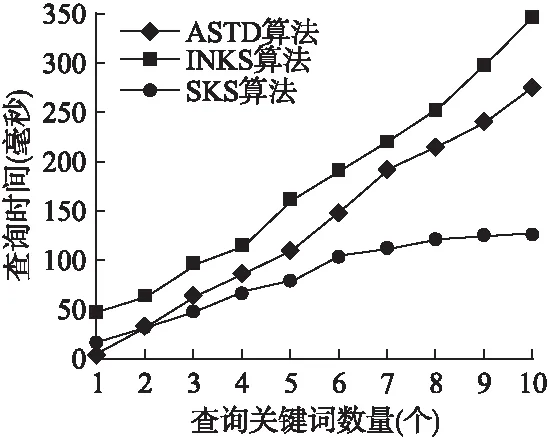
5.4 数值型属性维度对算法性能的影响
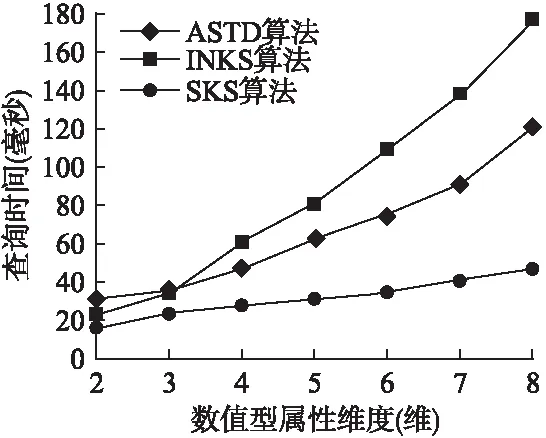
5.5 真实数据集下的算法性能
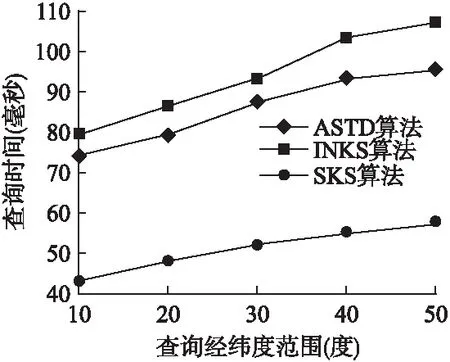
6 结束语
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09意林(2021年9期)2021-05-28 20:26:14中华诗词(2019年7期)2019-11-25 01:43:00时代英语·高一(2019年1期)2019-03-13 10:29:48意林(2018年3期)2018-03-02 15:17:24自动化学报(2017年2期)2017-04-04 05:14:34厦门理工学院学报(2016年1期)2016-12-01 04:50:48Coco薇(2016年8期)2016-10-09 00:02:56灯与照明(2016年4期)2016-06-05 09:01:45中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24
