
基于Hadoop的K-Means算法的设计与实现
2019-11-06 09:14王立友郑海鹏
绥化学院学报 2019年11期
王立友 郑海鹏
(淮南联合大学计算机系 安徽淮南 232001)
在现实生活中,人们经常会将类似的事物或事情划分为同一类。即所谓的“物以类聚、人以群分”。在计算机程序设计过程中,分类算法是一种监督学习方法。但是,在许多情况下,如果数据通过预处理满足分类算法的要求,则无法满足上述条件,特别是在处理大量数据时,成本非常大,您可以考虑使用K-Means聚类算法。K-Means算法属于无监督学习方法[1],作为较为经典的分类算法,在很多应用领域中都有其自身的优势,因为它与分类进行比较,所以聚类不依赖于预定义的类和类标签的训练实例。
一、K-Means算法简介
K-Means算法,也称为K-Means方法或K均值法,具有良好的可扩展性和快速收敛性[2],是最广泛使用的聚类算法。K均值算法是不断改变聚类中心点的过程(聚类过程如图1所示)。计算所有成员到每个质心的距离,然后重新划分其内部集群成员。将对应成员划分给到其距离最小的那个质心。K值表示簇的质心数(即聚类中心的数量);K-means可以自动将对应的成员分配给不同的类,但是不可能决定要分割哪些类。K必须是小于训练集中样本数的正整数。
假设输入成员样本集合为C=X1,X2,…,Xn-1,Xn(含有n个成员样本),K-means算法具体的过程如下:
1)选择初始化过程中中心点的个数(K值):A1,A2,…,Ak;
2)计算成员样本X1,X2,…,Xn-1,Xn到A1,A2,…,Ak的各自的距离;选取各个成员样本到各个中心点的最小距离,将样本成员划分到最小距离的中心点中(如式1);

1<=j<=k
3)重新为中心点Aj为隶属该类别的所有样本的均值;
4)重复2、3以上两个步骤,直到迭代终止(即上一次和本次聚类的中心点不再发生变化)。
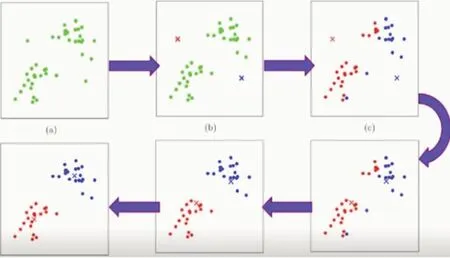
图1 K-Means聚类示意图
二、Hadoop平台简介
Hadoop是Apache Foundation开发的分布式系统基础架构[3]。其核心是MapReduce和HDFS(分布式文件系统)。在现代社会中,只要和海量数据有关的应用领域都会出现Hadoop 的身影[4]。随着Hadoop 版本的不断发展,其自身的功能正在变得越来越强大,并且已经形成了相对完整的系统。如图2所示。
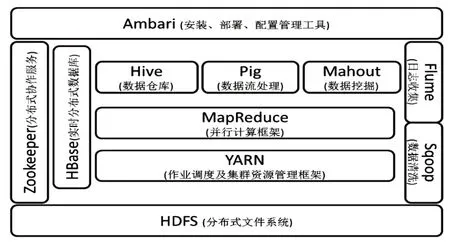
图2 hadoop平台架构
(一)HDFS 分布式文件存储系统。HDFS 代表Hadoop分布式文件系统,是一种具有高容错性,高吞吐量和高可扩展性的分布式文件存储系统。HDFS 在存储数据时使用块存储。它将节点分为两类:NameNode 和DataNode,其中NameNode是HDFS集群的主节点。DataNode是HDFS集群从节点,用来存储真正的数据。每个数据块可以在多个DataNode上存储多个副本,以提高数据安全性。
(二)MapReduce 框架。MapReduce 是一个开源并行计算框架,主要由两个函数组成:Map()和Reduce()。它可以将大型任务分解为相对相反的多个子任务,并且可以并行处理。Map()函数负责指定数据集上的相反元素,并生成一系列[key,value]作为中间结果[5]。而Reduce()函数则对中间结果中相同Key的所有“value”进行规约,并得到最终结果。
(三)HBase数据库。HBase是一个针对结构化数据的可伸缩、高性能的非关系型分布式动态模式数据库,与传统数据库相比,HBase采用BigTable数据模型。在Hadoop平台上运行时,HBase 中的表可用作MapReduce 任务的输入和输出,并可通过Java API检索。
(四)Hive数据仓库。Hive是数据仓库管理文件。它提供完整的SQL 查询功能,可将数据文件映射到单个数据表中。将其转化为MapReduce任务进行运行。
三、基于Hadoop的K-means算法的实现
(一)K-Means算法实现过程解析。
1.使用全局变量在最后一次迭代后存储质心。
2.使用Hadoop中的地图框架(map)来计算每个质心和样本之间的距离,并获得最接近样本的质心。
3.在Hadoop 中使用reduce 框架,输入键(Key)是质心,值(Value)是其他样本。
4.将先前质心和最新质心作比较,若发生了变化,就需要程序继续运行,进行下一次迭代,否则将停止迭代,终止当前程序,输出最终的聚类结果。
(二)算法实现过程需要解决的问题。本文的思路基本上是按照上面的步骤来做的,有以下几个问题急需解决:
1.Hadoop没有自定义全局变量,因此无法定义存储质心的全局变量,因此需要另一种想法,即质心存储在文件中。
2.存储质心的文件读取。我们选择在主main函数中读取质心,然后将质心设置保存到配置中。configuration 在map和reduce均可读
3.如何比较质心的变化,你可以在主要的主函数中进行比较,读取质心的文件和最新的质心并进行比较。这个方法是可以实现的,我们使用自定义计数器,计数器是一个全局变量,可在地图中读写并减少,在上面的想法中,我们看到reduce具有最后一次迭代的质心和计算的质心,因此完全可以直接在reduce中进行比较。如果发生变化,counter加1。
(三)基于手肘法的K-Means 算法中最佳K 值的确定。本文选取手肘法用来确定最佳K值[6]。手肘法的核心指标是平方误差的总和:SSE(如式2所示),其中,Ci是第i个聚类中心,p是聚类中心的元素,mi是Ci的质心(Ci中所有元素的平均值),SSE则可以表示聚类的质量。

SSE 方法的原理为:随着聚类中心数量的增加,聚类将更加细化,每个聚类中心的聚合度将逐渐增加,因此误差SSE将逐渐减小。当K小于实际簇数时,随着K值的增加,簇中心的聚集程度将大大加快。加速误差的平方和SSE减小的幅度。SSE 的下降趋势急剧减少,然后趋于平缓,即SSE和K之间的关系是肘形。而对应肘部的K值为最佳。
为测试数据选择最佳簇编号K值,具体实施过程为K=1-6,针对对每一个K值记下对应的SSE,制作K和SSE关系图,并选择与肘相对应的K 值作为最佳簇数。如3 所示:即K=4聚类结果最优。
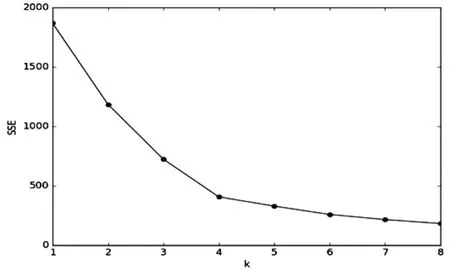
图3 K与SSE关系图
(四)Hadoop实现K-Means算法的主要代码。
1.定义Center类、初始化质心.首先定义一个Center类,它主要存储质心数量K值,以及两个从HDFS读取质心文件的方法。一个用于读取初始质心,一个用于在每次迭代后读取质心文件夹。这个是在文件夹中的,代码如下:
public class Center{
protected static int k=4;//质心的个数(由手肘法确定K=4为最佳)
/**
从初始质心文件加载质心并返回字符串,由质心之间的制表符分隔
*/
public String loadInitCenter(Path path) throws IOException {
StringBuffer sb = new StringBuffer();
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(conf);
FSDataInputStream dis = hdfs.open(path);
LineReader in = new LineReader(dis,conf);
Text line = new Text();
while(in.readLine(line) >0) {
sb.append(line.toString().trim());
sb.append(" "); }
return sb.toString().trim();}
2.每次迭代从质心文件中读取质心并返回字符串代码
public String loadCenter(Path path) throws IOException{
StringBuffer sb = new StringBuffer();
Configuration conf = new Configuration();
FileSystem hdfs = FileSystem.get(conf);
FileStatus[]files = hdfs.listStatus(path);
for(int i = 0; i < files.length; i++) {
Path filePath = files[i].getPath();
if(!filePath.getName().contains("part")) continue;
FSDataInputStream dis = hdfs.open(filePath);
LineReader in = new LineReader(dis,conf);
Text line = new Text();
while(in.readLine(line) >0) {
sb.append(line.toString().trim());
sb.append(" ");}}
return sb.toString().trim();}}
public class KmeansMR {
private static String FLAG = "KCLUSTER";
public static class TokenizerMapper extends Mapper { double[][]centers = new double[Center.k][]; String[]centerstrArray = null; @Override public void setup(Context context) { //将放在context中的聚类中心转换为数组的形式,方便使用 String kmeansS = context.getConfiguration().get(FLAG); centerstrArray = kmeansS.split(" "); for(int i = 0; i < centerstrArray.length; i++) { String[]segs = centerstrArray[i].split(","); centers[i]= new double[segs.length]; for(int j = 0; j < segs.length; j++) { centers[i][j]= Double.parseDouble(segs[j]);}}} public void map(Object key,Text value,Context context) throws IOException,InterruptedException { String line = value.toString(); String[]segs = line.split(","); double[]sample = new double[segs.length]; for(int i = 0; i < segs.length; i++) { sample[i]= Float.parseFloat(segs[i]);} 3.求得成员距离最近的质心 double min = Double.MAX_VALUE; int index = 0; for(int i = 0; i < centers.length; i++) { double dis = distance(centers[i],sample); if(dis < min) { min = dis;index = i; } } context.write(new Text(centerstrArray[index]),new Text(line)); } } public static class IntSumReducer extends Reducer Counter counter = null; public void reduce(Text key,Iterable double[]sum = new double[Center.k]; int size = 0; //计算相应维度上的值之和,存放在sum数组中 for(Text text : values) { String[]segs = text.toString().split(","); for( int i = 0; i < segs.length; i++) {sum[i]+= Double.parseDouble(segs[i]);} size ++;}//求新的质心 StringBuffer sb = new StringBuffer(); for(int i = 0; i < sum.length; i++) { sum[i]/= size; sb.append(sum[i]); sb.append(","); } 4.判断新的质心跟前一次迭代的质心是否一致 job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); FileInputFormat.addInputPath(job,samplePath); FileOutputFormat.setOutputPath(job,kMeansPath); job.waitForCompletion(true); /**获取自定义计数器的大小,如果它等于质心的大小,表示质心没有改变,程序停止迭代*/ long counter = job.getCounters().getGroup("myCounter").findCounter("kmenasCounter").getValue(); if(counter == Center.k) System.exit(0); boolean flag = true; String[]centerStrArray = key.toString().split(","); for(int i = 0; i < centerStrArray.length; i++) { if(Math.abs(Double.parseDouble(centerStrArray[i]) - sum[i]) >0.00000000001) { flag = false; break; }}//如质心不一致,计数器加1 if(flag) {counter = context.getCounter("myCounter","kmenasCounter"); counter.increment(1l); } context.write(null,new Text(sb.toString()));}} public static void main(String[]args) throws Exception { Path kMeansPath = new Path("/mid-data/k-means/k-Means");//初始质心文件 Path samplePath = new Path("/mid-data/k-means/sample");//样本文件 Center center = new Center();//加载聚类中心文件 String centerString = center.loadInitCenter(kMeansPath); Int index = 0;//初始化迭代次数 while(index < 100) { Configuration conf = new Configuration(); conf.set(FLAG,centerString);////将集群中心字符串放入配置中 kMeansPath = new Path("mid-data/k-means/k-Means" +index);//此迭代的输出路径也是下一个质心的读取路径 /**确定输出路径是否存在*/ FileSystem hdfs = FileSystem.get(conf); if(hdfs.exists(kMeansPath)) hdfs.delete(kMeansPath); Job job = new Job(conf,"kmeans" + index); job.setJarByClass(KmeansMR.class); job.setMapperClass(TokenizerMapper.class); 5.重新加载质心 center = new Center();centerString = center.loadCenter(kMeansPath); index ++;} System.exit(0);} public static double distance(double[]a,double[]b) { if(a == null || b == null || a.length != b.length) return Double.MAX_VALUE; double dis = 0; for(int i = 0; i < a.length; i++) { dis += Math.pow(a[i]-b[i],2);} return Math.sqrt(dis);}} 经在Hadoop 框架上进行测试,上述程序实现了简单的K-Means 算法,并得出了较为理想的聚类效果。有关KMeans聚类算法在实际中的具体应用,笔者将在后续的实践中继续进行探究。四、结语
猜你喜欢
汽车实用技术(2022年14期)2022-07-30北京航空航天大学学报(2021年4期)2021-11-24计算机技术与发展(2020年8期)2020-08-12电脑报(2020年12期)2020-06-30铁道通信信号(2019年6期)2019-10-08电脑报(2019年4期)2019-09-10雷达学报(2017年6期)2017-03-26互联网天地(2016年1期)2016-05-04智能系统学报(2015年4期)2015-12-27应用科技(2015年5期)2015-12-09
