
基于交叉验证网格寻优随机森林的黑产用户识别方法
2019-11-05 07:45章文俊韩晓龙
科技视界 2019年28期
关键词:随机森林
章文俊 韩晓龙
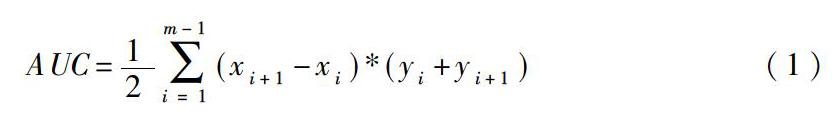
【摘 要】随着移动互联网的普及,黑色产业成为了一种新的违法途径。黑色产业的猖獗不仅损害了社会利益,同时也影响了正常用户的体验。本文提出了一种基于交叉验证网格寻优随机森林算法的区分黑色产业用户的方法。本文收集的黑产用户数据为某论坛的恶意刷违法消息的用户数据。利用随机森林机器学习数据特征,通过交叉验证以及网格搜索技术完成模型参数寻优,得到训练好的模型。并且比较了其他常见的几种分类算法在识别黑产用户的准确率。线上和线下实验表明,基于随机森林算法的模型在预测区分黑色产业用户上相比较于其他几种算法准确率更高,表现更为稳定。为打击黑色产业积累了宝贵的经验。
【关键词】随机森林;黑色产业;交叉验证;网格搜索
中图分类号: TP393.06 文献标识码: A 文章编号: 2095-2457(2019)28-0001-003
DOI:10.19694/j.cnki.issn2095-2457.2019.28.001
【Abstract】With the popularization of mobile Internet, the black industry has become a new illegal way. The prevalence of the black industry not only harmed the social interest, but also affected the experience of the normal users. This paper presents a method for distinguishing black industry users based on cross-validation grid-optimized random forest algorithm. The data collected in this paper is the user data of the maliciously brushed illegal messages of a certain forum. And using the random forest machine to study the data features, the model parameters are optimized through cross-verification and grid search technology, and the trained model is obtained. And the accuracy of the other common classification algorithms in identifying the black-producing user is compared. The online and offline experiments show that the model based on the stochastic forest algorithm is more accurate and more stable in the prediction of the black industrial users compared with other algorithms. Valuable experience has been accumulated in the fight against the black industry.
【Key words】Random forest; Black industry; Cross validation; Grid search
0 前言
移动化联网的发展让生活变得十分便利,但是同时也衍生出了一个黑色产业。黑色产业是利用不正当的违法手段在移动互联网上获取利益。黑色产业不仅对社会利益造成了极大地损失,对于正常用户的使用也产生了极大的困扰。对于黑色产业的研究不仅能减少利益的损失,也能通过打击黑色产业来保护正常用户的使用。
本文从黑色产业刷违法信息获取非法利益入手。通过收集某论坛的黑产用户数据。采用科学的数据处理工具对收集的数据进行清洗,保证数据的纯净。然后根据数据特征进行构建模型,采用了网格搜索寻找最佳参数。并且比较了几种常见的分类方法。根据实际的预测结果,以及线上模型表现,训练好的模型有着非常优秀的表现,能很好区分黑色产业用户和正常用户。对打击黑产有着较好的效果。
1 相关工作
1.1 随机森林算法
随机森林算法提出于1995年,由Leo Breiman和Adele Cutler共同提出。随机森林的提出是基于决策树。决策树一般为简单的分类操作,而随机森林是多棵决策树的集合。随机森林的输出取决于随机森林中的每一个决策树的类别。随机森林有着诸多优点,在机器学习中也是非常重要的一種算法。由于随机森林在处理大量数据以及平衡误差上的卓越性能,在实际应用中也被广泛使用。
随着随机森林算法在各个领域有着优良表现,该算法也被应用的领域也越来越多。陈标金[1]等通过筛选了技术指标和经济指标来作为特征数据来进行预测国债指数的预测变量。利用随机森林算法构建模型,通过模型进行预测。林栢全[2]等提出了一种基于随机森林与矩阵分解的推荐算法。相比较于传统的推荐算法,该算法在推荐性能上有更好的准确率和性能。Chong[3]等利用随机森林算法建立了热驯化和非热驯化模型。在预测室外高温的热风险有很高的准确率。这对室外工作者的健康有很大的保证。Jo[4]等通过K-means聚类算法添加类似数据。然后通过随机森林训练聚类得到的数据,根据模型的输出来识别用户的活动。最后个性化推荐优选的GUI。
1.2 机器学习
机器学习在深度学习尚未崛起时为深度学习奠定了基础。并且目前机器学习在各行各业也被广泛成功使用。机器学习是一门复杂的交叉学科,不仅涉及了高等数学等基础学科,还涉及算法等学科。机器学习的核心内容是让计算机模拟人类的学习行为,来获得新的知识和技能。机器学习的应用遍布人工智能的各个领域,极大地减少了人工的重复劳动。
机器学习一般分为有监督学习和无监督学习,两种不同的学习方式一般也会应用于不同的情景。蔡天鸿[5]等提出一种基于TF-IDF的人格分析方法。利用VSM、PCA、Wavelet技术提取出文本特征,利用KNN分类算法获得人格分类的候选项。Feng[6]等提出一种评估建筑环境绩效的定量方法。主要使用了参数化的设计技术以及机器学习算法来评估早期决策阶段的建筑环境绩效。Ariharan[7]等提出了一种机器学习框架,来管理传感器部署时相关的网络延迟和丢包。这种机器学习框架能结合学习模块的结果,进行集体决策。Czernechi[8]等提出将机器学习与遥感数据以及环境变量相结合的概念。并且通过建立模型来进行预测大型的冰雹事件。
1.3 网格搜索算法
网格搜索是机器学习中非常重要的一个概念。网格搜索是通过遍历给定的参数组合来优化所需要訓练的模型。通常为了防止模型过拟合或者欠拟合,会使用网格搜索算法寻找模型最佳参数。网格搜索也叫穷举搜索,即遍历整个训练数据集。
网格搜索算法在实际应用的过程中配合分类算法进行使用,主要是用于分类算法的参数寻优。张文雅[9]在预测汽车销量时,运用了交叉验证的网格搜索算法。主要是运用于优化SVM算法的惩罚系数以及核函数的参数。构建了汽车销售的预测模型。Wang[10]等提出了一种从脑电图传感器收集的非静止脑电图数据的综合方法。综合方法其中包括了网格搜索优化器,主要用于自动查找训练分类器的最佳参数。
2 理论基础
2.1 黑产用户行为分析
本文的研究主要针对是黑产用户在论坛恶意刷违法内容行为。黑产用户主要利用脚本文件进行无限制刷帖。为了针对黑产用户的恶意刷内容,需要对黑产用户的刷内容行为进行分析,然后构建预测模型。
通过对黑产用户行为进行分析可以发现,黑产用户会通过脚本文件直接访问发表内容的接口。并且在短时间内发送内容数量上会比正常用户多出很多。同时黑产用户在短时间内也会在回复内容数量上远远超过正常用户。同时基于黑产用户是通过作弊工具进行恶意刷内容。所以黑产用户等级不会很高。基于以上黑产用户等行为特征,可以对将黑产用户和正常用户进行很好地区分。
2.2 数据预处理
在机器学习中,数据是否足够以及数据的完整将直接决定模型的准确率,所以在数据处理的过程中对于数据的完整性的保留以及处理的灵活性都有着较高的要求。最为常见的也是使用最广泛的数据处理办法是通过MS的excel软件进行数据的处理。
因为本研究中设采集的数据集较为庞大且数据内容较为复杂。采用了python语言客休数据管理工具,numpy和pandas数据处理库。其中pandas通过读取数据将数据转换为DataFrame格式方便进行后续操作。在数据的预处理中,主要是对数据集中的缺失值进行填充,以及时间数据转换为时间戳。这样才能保证后续的模型训练能顺利进行。
2.3 分类方法设计
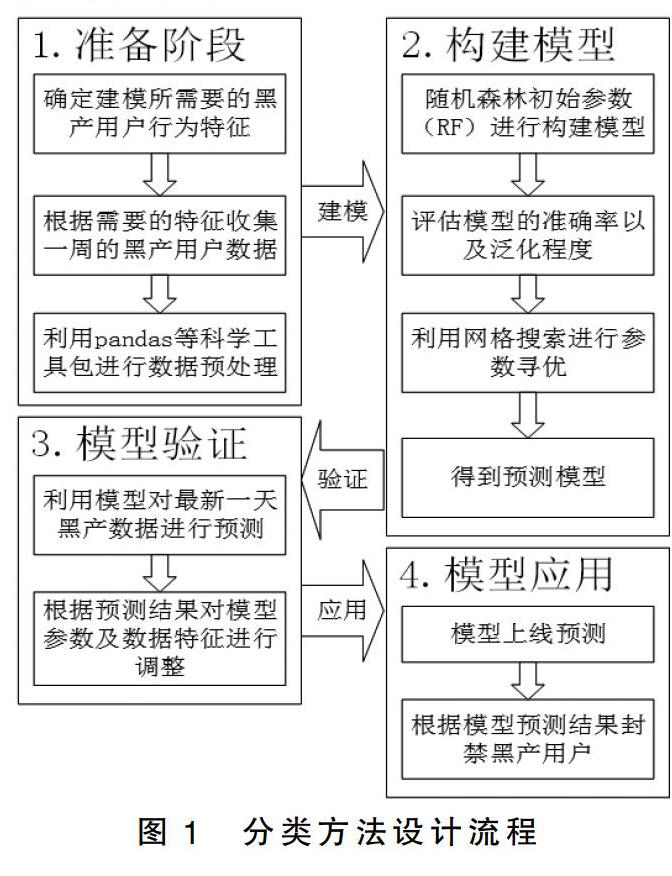
本文基于对黑色产业用户恶意刷内容的行为特征入手。利用随机森林算法进行训练模型,并通过网格搜索算法进行参数优化。得到最优的预测模型。具体的分类方法设计如图1所示。
首先为了得到数据,需要对黑产用户行为进行分析。主要寻找可以非常准确区分黑产用户和正常用户的行为特征。找到合适的黑产用户特征,收集黑产用户一周的特征数据。在收集完黑产用户数据之后为了能顺利进行机器学习,需要将数据进行清洗,即数据的预处理。
然后是用随机森林分类器(RondomForest)进行训练模型,现在默认参数下进行数据的训练。为了更快地找到模型的最佳参数。本文才用了网格搜索(Grid search)算法,保证模型在训练过程中不会因为参数设置而导致过拟合或者欠拟合。
通过训练好的预测模型对最新的黑产用户数据进行预测,并且比较准确率。通过观察误判和漏判用户特征进行调整模型。最后将训练好的预测模型上线进行预测,为后续的处理提供判断依据。
2.4 模型评估
本文研究内容是通过机器学习训练模型来进行预测,为了保证模型的准确率。需要在模型进行预测的过程中,对模型完成评估。在评估过程中主要可以参考一下几个数据的准确率。其中随机森林算法所特有的袋外得分率(oob_score)。该参数表示为,在训练集中每次训练的过程会自动将训练集的1/3的数据集划分成测试集。这样在训练模型的同时也能进行测试。袋外得分率的返回值也是模型的准确率判断条件之一。
训练好的模型在预测最新的黑产用户数据时,因为已知黑产用户标签,可以通过随机森林的分类器的predict函数得出预测标签,将两者标签进行对比,同样也能统计得到模型的准确率。
模型的优劣不仅取决于模型预测的准确率,因为准确率可以通过参数进行调整。所以在判断完模型准确率的基础上,还需要对模型的泛化能力进行评估。通常为了评估模型的泛化能力会采用AUC函数。AUC分数越高,代表模型的泛化程度越强。AUC计算公式如下:
3 实验结果与分析
本文以黑产用户特征为数据特征,对某论坛的黑产用户恶意刷内容行为数据进行收集。共收集一周数据作为模型的训练参数。经过数据预处理之后,最后得到的数据有13万条。在训练模型过程中将整个数据集分成4:1的训练集和测试集。用于评估模型的准确率。
3.1 数据预处理
本文主要是利用python程序语言进行数据处理。为了保证训练数据的完整性以及数据的可读性。在数据处理过程中主要涉及pandas和numpy两个科学数据处理包。通过将数据集转换成DataFrame特殊的格式,对缺失值进行填充。对于机器学习无法识别的数据类型进行转换,保证训练数据集的纯净。
3.2 预测模型训练与参数寻优
通过数据的预处理得到纯净的黑产用户数据之后。利用随机森林算法训练模型。初始的模型训练采用默认参数,得到在默认参数下的模型准确率。为了体现模型对数据集的依赖性,对不同的数据集大小下模型的准确率进行对比。训练结果如表1所示。
从表1的预测结果来看,数据集的大小对模型的预测有着很大的影响。表1中的AUC得分是数据集切分出来的,所以在计算泛化能力时得分很高。实际在预测过程中需要先考虑模型的准确度,在看中模型的泛化程度。从预测结果来看,短时间内的特征数据,并不能进行很好的预测。七天的数据集比单独一天的数据集提高了将近40%的准确率。所以为了保持模型预测的准确率,至少保证一周以上的数据集大小。
确定完数据集的大小对模型产生的影响,接着需要进行参数调优,保证在准确率和泛化能力都很好的前提下产生过拟合或者欠拟合。本文中才用了网格搜索算法,虽然耗时较长,但为了保证模型预测的准确率还是采用网格搜索。
对于随机森林算法,其分类器主要需要调整的参数为以下五个参数:决策树个数(n_estimators),决策树的最大深度(max_depth),内部划分节点需要的最小样本树(min_samples_split),叶子节点最少的样本数(min_samples_leaf),以及单棵决策树使用特征的最大数量(max_features)。因为本文中数据特征数量较少,并且选取的特征数量都具有较高的关联性和区分度,所以会将所有的特征加入训练。即需要调整的参数为四个参数。
图2为调整参数后模型准确率和AUC分数的对比,这里调优用到的数据集为七天数据集。从图2可以很清楚的看到在默认参数下,模型准确率和泛化程度都比较高。经过参数的调整,模型预测的准确率由初始的97.35%提高到了99.25%。并且模型的AUC得分也从95.67%提高到了99.57%。在网格搜索算法计算得到最佳参数,并且四次调整参数之后,模型预测的准确率以及泛化能力都到了预期的程度。
3.3 模型上线预测
训练好的预测模型,在线下经过几天的验证和校准。能保证良好的准确率,在确认无误的情况下接入线上进行拦截。通过几天的拦截数据观察和统计,模型有着预期的表现。具体的上线拦截准确率如图3所示。
从图3可以看出模型在上线拦击用户准确率达到了当初预期的效果。基本能保证在准确率在98%以上。通过模型能过滤掉绝大多数的黑产用户,保证正常用户的使用体验。同时线上的拦截数据(下转第7页)(上接第3页)也能非常直观的表明模型的有效性和实用性。模型的准确判断不仅极大地减少了人工判断的时间,同时也能不断地根据黑产用户的行为来提升模型和完善模型。
4 结论
本文从对黑色产业用户利用作弊手段传播违法消息,并且恶意刷内容的行为入手。通过分析黑产用户行为特征,针对特征进行收集数据。利用python的开源工具完成数据清洗。利用机器学习中的随机森林算法的分类器构建预测模型。并且通过网格搜索算法完成对模型的参数寻优过程。最后通过线下的验证完成对模型的评估,通过观察线上拦截情况对模型进行调整。从线上数据来看模型不仅有着良好的表现,同时也为后续打击黑产用户提供了宝贵经验。下一步研究会基于深度神经网络来增加模型的学习能力,适应更多的场景。
【参考文献】
[1]陈标金,王锋.宏观经济指标、技术指标与国债期货价格预测——基于随机森林机器学习的实证检验[J/OL].统计与信息论坛:1-7[2019-05-31].
[2]林栢全,肖菁.基于矩阵分解与随机森林的多准则推荐算法[J/OL].华南师范大学学报(自然科学版),2019(02)[2019-05-31].
[3]Daokun Chong,Neng Zhu,Wei Luo,Xiaodi Pan. Human thermal risk prediction in indoor hyperthermal environments based on random forest[J].Sustainable Cities and Society,2019,49.
[4]Sang-Muk Jo,Sung-Bae Cho. A personalized context-aware soft keyboard adapted by random forest trained with additional data of same cluster[J]. Neurocomputing,2019,353.
[5]蔡天鴻,邓金,史国阳,朱晋,怀丽波.基于TF-IDF方法的文本人物群体人格分析方法[J].计算机应用与软件,2019,36(05):35-38.
[6]Kailun Feng,Weizhuo Lu,Yaowu Wang. Assessing environmental performance in early building design stage: an integrated parametric design and machine learning method[J]. Sustainable Cities and Society,2019.
[7]V Ariharan,Subha P. Eswaran,Srinivasarao Vempati,Naveed Anjum. Machine Learning Quorum Decider (MLQD) for Large Scale IoT Deployments[J]. Procedia Computer Science,2019,151.
[8]Bartosz Czernecki,Mateusz Taszarek,Micha?覥 Marosz,Marek Pó?覥rolniczak,Leszek Kolendowicz,Andrzej Wyszogrodzki,Jan Szturc. Application of machine learning to large hail prediction - The importance of radar reflectivity, lightning occurrence and convective parameters derived from ERA5[J]. Atmospheric Research,2019,227.
[9]张文雅,范雨强,韩华,张斌,崔晓钰.基于交叉验证网格寻优支持向量机的产品销售预测[J].计算机系统应用,2019,28(05):1-9.
[10]Wang Xiashuang,Gong Guanghong,Li Ni. Automated Recognition of Epileptic EEG States Using a Combination of Symlet Wavelet Processing, Gradient Boosting Machine, and Grid Search Optimizer[J]. Sensors (Basel, Switzerland),2019,19(2).
猜你喜欢
南水北调与水利科技(2016年6期)2017-01-06
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
绿色科技(2014年3期)2014-07-11
