
基于TRIZ发明原理的专利自动分类方案设计与实现
2019-11-03 14:07王保越及歆荣
电脑知识与技术 2019年23期
王保越 及歆荣
摘要:为深入挖掘和充分利用已有专利文献中的创新思路和关键技术,基于TRIZ理论中的发明原理,对中文专利文献自动分类实现方案进行了设计和实现。该方案中基于TRIZ发明原理的经典描述和已标注发明原理的专利文献构建TRIZ发明原理字典,基于构建的发明原理字典对专利文本进行分词和特征选择,利用机器学习方法对专利特征向量样本进行分类模型训练和预测。为加快方案验证,TRIZ发明原理字典的构建、基于构建的发明原理字典的专利文本分词、特征选择以及特征向量化都使用软件实现,利用支持向量机实现分类模型的训练和预测。实验结果表明,该方案可以达到较高的分类准确性。因此,该方案的实施可为基于TRIZ发明原理的专利自动分类提供一条可借鉴的思路。
关键词:TRIZ理论;TRIZ发明原理;中文专利文献;文本分类
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2019)23-0215-03
开放科学(资源服务)标识码(OSID):
Design of Patent Automatic Classification Scheme Based on TRIZ Invention Principle
WANG Bao-yue, JI Xin-rong
(Hebei University of Engineering, Handan 056038, China)
Abstract: In order to dig deeply and make full use of the innovative ideas and key technologies in existing patent documents, based on the invention principle of TRIZ theory, the implementation scheme of automatic classification of Chinese patent documents is designed. In this scheme, a TRIZ Dictionary of Invention Principles is constructed,which is based on the classical description of TRIZ Invention Principles and the patent documents labeled with TRIZ Invention Principles. Based on the dictionary of Invention Principles, the patent text is segmented and selected. The classification model of patent eigenvector samples is trained and predicted by machine learning methods. In order to speed up the scheme verification, the construction of TRIZ Dictionary of Invention Principles, the word segmentation of patent text based on TRIZ Dictionary of Invention Principles, feature selection and feature vectorization are all realized by software, and the training and prediction of classification model are realized by using support vector machine. The experimental results show that the scheme can achieve high classification accuracy. Therefore, the implementation of this scheme can provide a reference for automatic patent classification based on TRIZ invention principle.
Key words: TRIZ theory; TRIZ invention principle; Chinese patent documents; text classification
1 引言
专利文献是世界上最大最新的技术信息源,是创新的源泉[1]。当前对于专利分类检索大多采用国际专利分类法(International Patent Classification, IPC),该分类方法采用功能与应用相结合,以功能为主的分类原则,将专利按技术主题进行多层次分类[2]。因此,人们按照IPC分类方法对专利信息进行检索,只能检索到专利所属的技术领域、应用领域以及其实现的功能,并不能从专利中挖掘出潜在的更有价值的内容,如发明创造和解决技术难题的创新思路等[3]。对于想要进行发明创造的研发人员,IPC分类方法不能满足他们从专利中获取创新资源和创新思路的需求。因此,需要一套能够指导人们进行发明创造和解决复杂工程问题的方法学理论[4]。TRIZ理论是由苏联发明家、教育家根里奇·阿奇舒勒(G.S.Altshuller)在1946年开始创立,旨在研究人类进行发明创造、解决技术难题过程中所遵循的科学原理和法则[4]。该理论是阿奇舒勒及其研究团队通过梳理、分析数以百万计的已有技术创新成果和相关自然科学知识,归纳总结出的一套能指导人们进行发明创新、解决工程问题的系统化的方法学体系[5]。经过几十年的发展,TRIZ理论已经成为当今世界上著名的发明问题解决理论,已在世界各国诸多知名企业中推广应用,加快了人们创造发明的进程和高质量创新产品的产出[5]。TRIZ理论中用以解决系统矛盾的抽象法则——40条发明原理是最流行和最普及的,它利用有限的发明措施來指导发明者解决几乎无限的发明问题,能够使发明者清楚地了解到目前专利所采用了哪些发明原理解决了什么矛盾冲突[6]。然而,人工对专利信息进行40个发明原理的分类,其工作量是非常巨大,甚至无法实现[6]。因而,基于TRIZ的40个发明原理对专利信息进行分类和检索成为当前专利信息管理中一个研究思路。
本文利用自然语言处理技术和机器学习方法,对TRIZ理论中的发明原理的经典描述和已标注发明原理的专利文献进行分析和研究,提出了一种基于TRIZ发明原理的专利自动分类实现方案。该方案关键之处在于其一是基于TRIZ理论中的发明原理的经典描述和已标注发明原理的专利文献构建发明原理字典;其二是基于构建的发明原理的字典对专利文本进行分词和特征选择。使用支持向量机分类算法进行分类模型训练和测试[7]。经试验验证,该方法有效可行。
2 中文专利文本自动分类实现方案设计
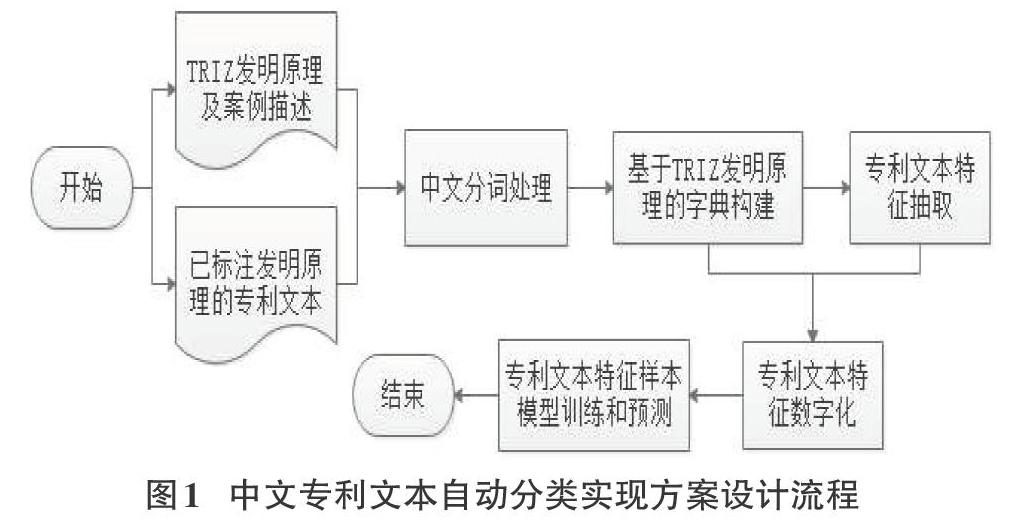
为实现对中文专利文献按照TRIZ发明原理进行分类,本研究对中文专利文本自动分类实现流程中的TRIZ发明原理的字典设计、专利文本的特征抽取、专利文本特征的数字化三项内容进行了分析和设计,然后利用支持向量机分类算法对专利文本数字化样本集进行了分类模型训练和预测,具体流程,如图1所示。
2.1 基于TRIZ发明原理的字典构建
为了准确切分出专利文本中表征TRIZ发明原理的特征词,本研究首先构建了基于TRIZ发明原理的字典。该字典的构建思路具体包括:⑴准备TRIZ发明原理的经典描述和每个发明原理下的案例描述,该项工作参考了TRIZ理论及应用相关的书籍20余部;⑵准备已标注发明原理的专利文献,该工作使用了四川大学创新方法工作专项项目的成果——已标注发明原理的1147条专利;⑶借助分词工具对前面准备的发明原理及相关案例的描述和专利文献进行分词;⑷利用人工识别方式将分词结果中表征发明原理的特征词加入TRIZ发明原理的字典中。基于上述思路构建了TRIZ发明原理的字典。基于构建的TRIZ发明原理的字典对专利文本进行分词,可以大大提高专利文本中表征发明原理的特征词切分的正确率。另外,该字典会随着分析专利文献数量的不断增加而丰富和完善。
2.2 专利文本的特征抽取设计
基于TRIZ发明原理的字典对每条专利进行分词处理后,首先对专利分词结果进行词的去重复处理,然后再利用人工识别方式将去重复处理过的分词结果中表征发明原理的特征词加入TRIZ发明原理的字典中,以进一步丰富和完善发明原理字典内容。基于每条专利去重复处理后的分词结果,对该专利文本进行特征抽取。为了能在专利文本特征抽取时更多的抽取到表征发明原理的特征词,也为了专利文本特征向量维数尽量低,本研究采用的文本特征抽取方法是基于构建的TRIZ发明原理字典,将专利文本的分词结果中有的词并且字典中也有的词抽取出来,而对专利文本分词结果中有的词但字典中没有的词不进行抽取。基于该方法对每条专利进行特征抽取,既能抽取到表征发明原理的词,同时也控制了专利文本的特征向量维数。
2.3 专利文本特征的数字化设计
为了使特征抽取处理后的专利文本易于处理,需要对专利文本特征进行数字化处理。一般来说,文本信息的数字化就是对文本建立特征向量空间模型。BoW(Bag of words)模型是一种比较简单的构建文本信息特征向量的方法, 其思路是将特征选择后的每个词作为列向量,每篇文本的特征词作为行向量建立矩阵,将文本信息中出现列向量对应单词的位置置为1,在文本中未出现单词的位置置为0。本研究对专利文本特征的数字化思路是将TRIZ发明原理字典中的每个词语表示为文本空间向量的列向量,将每篇专利表示为文本空间向量的行向量, 将每条专利文本特征向量与由TRIZ发明原理字典构成的列向量进行比对,在专利文本特征向量有列向量对应的特征词的位置设置为1,在没有列向量对应特征词的位置设置为0,以此实现专利文本特征的数字化。
2.4 专利文本分类器的构建
为了实现专利文本特征的模型构建和预测,本研究采用了支持向量机分类算法。由于本研究属于多分类应用,而支持向量机是一个典型的两分类算法,本工作采用了支持向量机构建多分类器的思路,即通过两两任意组合的方式设计分类器,将其中一类标记为正,另一类标记为负,构建多个分类器[8]。
3 中文专利文本自动分类实现
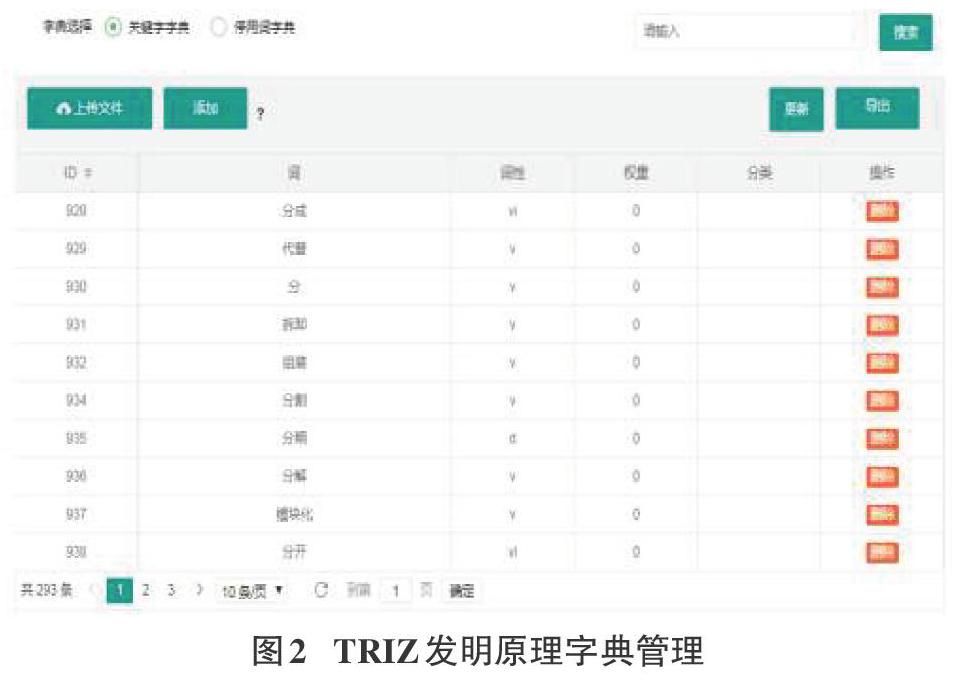
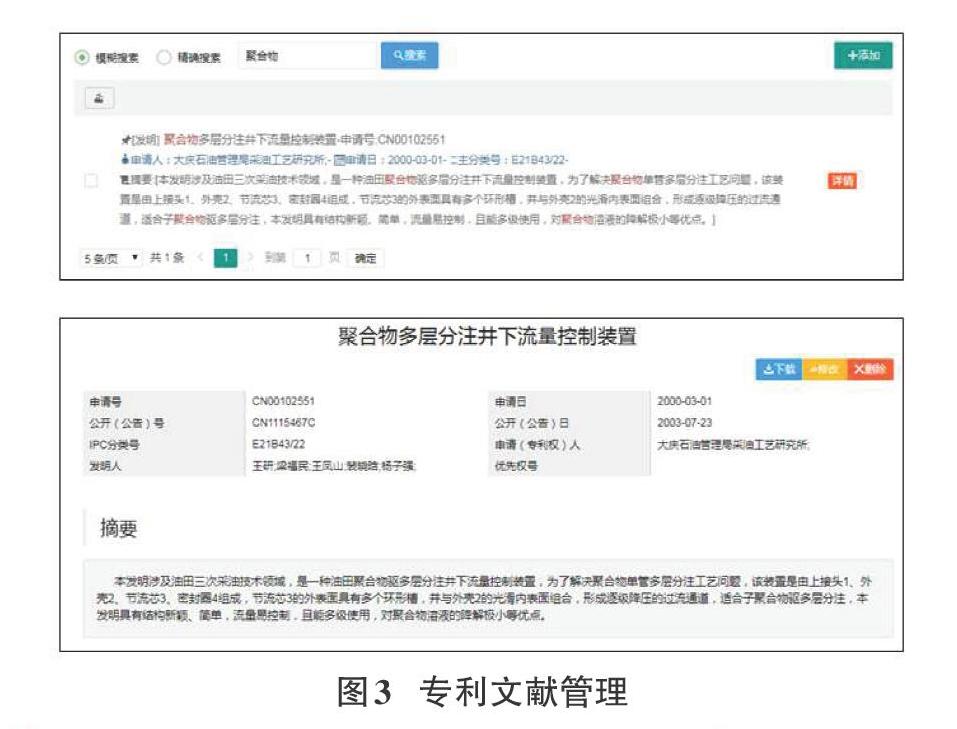
为了验证本研究方案的可行性,利用PYTHON编程语言和jieba中文分词工具包对20多部TRIZ理論及应用相关书籍中的发明原理的描述和案例进行了分词,并对四川大学创新方法工作专项项目成果中已标注发明原理的专利文献的标题和摘要使用同样的方法进行了分词处理,然后人工识别出能表征发明原理的特征词。利用JAVA编程语言和JAVA WEB开发技术设计了能实现该方案的软件,该软件实现了TRIZ发明原理字典的管理、专利文献管理、专利文本分词管理、专利文本特征向量生成、专利文本特征数字化等功能。具体功能如图2~图5所示。
为了验证该方案中专利自动分类模型训练和预测效果,对四川大学创新方法工作专项项目成果中已标注发明原理的专利文献中属于分割原理、抽取原理和局部质量原理三个发明原理的专利文本进行多分类模型的训练和预测。本实验所用数据具体情况见表1,使用MATLAB仿真环境和支持向量机(Support Vector Machine)分类算法进行专利文本模型训练和预测。三种类别的专利样本通过两两组合进行模型训练和预测,每两个类别实验随机选择训练样本数据和测试样本数据,且都重复50次,得到的模型平均预测精度结果见表2。
从表2的模型预测正确率结果可以看出,分割与抽取两类模型预测正确率较高,其次是分割和局部质量分类模型的预测正确率,最后是抽取和局部质量分类模型预测正确率,该结果表明训练样本数量越多,模型预测正确率越高,符合机器学习统计原理,因此,按照本研究设计方案进行模型训练与预测是可行的。但模型预测正确率效果不理想,分析产生该结果的原因主要是模型训练样本数量太少,分割原理样本最多为40个,另外两类都为24个,对于维数较高的样本来说,该实验中训练样本数量太少;另外一个原因是TRIZ发明原理字典里面的特征词还不全面。随着TRIZ发明原理字典的不断完善以及训练样本数据的增加,模型预测正确率会明显提高。
4 结束语
本文基于TRIZ理论中的发明原理,对中文专利文献按发明原理自动分类的实现方案进行了设计和实现。其中,对基于TRIZ发明原理的字典构建、专利文本特征抽取、专利特征向量数字化以及基于SVM的自动分类模型的训练和预测进行了详细设计和具体实现。仿真实验结果表明,本文提出的中文专利按TRIZ发明原理自动分类的设计方案是可行的。为了进一步提高模型预测正确率,增加专利自动分类模型训练样本数量和完善基于TRIZ发明原理的字典是下一步要开展的工作。
参考文献:
[1] 杨雪琴,关玉兰.专利文献与企业技术创新[J].青海科技,2001(2):48-49.
[2] 贾杉杉. 基于IPC的专利文本自动分类研究综述[A]. 中国计算机用户协会网络应用分会.中国计算机用户协会网络应用分会2017年第二十一届网络新技术与应用年会论文集[C].北京:中国计算机用户协会网络应用分会:北京联合大学北京市信息服务工程重点实验室,2017:4.
[3] 刘玉琴,桂婕,朱东华.基于IPC知识结构的专利自动分类方法[J].计算机工程,2008,34( 3) : 207-209.
[4] HE Cong,HAN Tong Loh.Grouping of TRIZ Inventive Principles to Facilitate Automatic Patent Classification[J]. Expert Systems with Applications,2008,34(1) : 788-795.
[5] 秦曉梅.基于TRIZ的专利标引系统的设计与实现[J].电脑知识与技术,2018,14(22):65-66.
[6] 翟继强, 王克奇. 依据TRIZ发明原理的中文专利自动分类[J].哈尔滨理工大学学报, 2013, 18(3): 1-5.
[7] 李云,高茂庭.支持向量机在文本分类上的研究[J].电脑知识与技术,2009,5(10):2643-2645.
[8] 庞剑锋,卜东波, 白硕. 基于向量空间模型的文本自动分类系统的研究与实现 [J]. 计算机应用研究, 2001(9) :23-26.
【通联编辑:梁书】
