
烃源岩总有机碳含量测井预测模型探讨
——以陆丰凹陷文昌组为例
2019-10-29 08:56蒋德鑫姜正龙杨舒越
岩性油气藏 2019年6期
蒋德鑫,姜正龙,张 贺,杨舒越
(中国地质大学(北京)海洋学院,北京 100083)
0 引言
烃源岩总有机碳(TOC)含量是评价烃源岩生烃潜力的重要指标,直接通过样品测试获得准确的TOC 数据是离散的,在评价全取值井段和整个地区的烃源岩生烃潜力时只能取其平均值,这样就导致非均质层段烃源岩的TOC 取值不合理,难以满足精细勘探的需要[1]。因此,学者们提出了利用连续的测井数据来识别、评价烃源岩,并定量预测TOC、生烃潜力(S1+S2)等参数的多种模型[1-9],如:从早期的定性识别模型,发展到单参数等效体积构成模型[6,8,10]、双参数交会图半定量评价模型[7],再到量化程度较高的多元回归方程定量模型[11-13]、Δ logR模型[9,14]和人工神经网络预测模型[15-16],以及测井-地震联合预测技术[17-18],其中主要方法有3 种:①多元回归模型。该模型是通过研究一个因变量与2 个或2 个以上自变量关系建立多个变量之间线性或非线性数学关系式的统计方法[1]。首先,根据各测井参数与TOC 之间的相关性高低依次参与拟合曲线,二者之间可能的相关关系有对数关系、指数关系和线性关系等。徐新德等[4]、朱光有等[5]、郑兆惠[19]运用烃源岩TOC 与测井电阻率值之间的对数关系[w(TOC)-log(Rd)]进行相关拟合分析,刘超[3]将烃源岩TOC 与测井电阻率值之间改进为幂指型关系,而徐思煌等[11]、袁彩萍等[12]在评价惠州凹陷文昌组烃源岩是采用线型[w(TOC)-log(Rd)]关系进行拟合。这说明多元回归模型具有很强的地域性,并且测井参数与TOC 之间的相关性不能太低。Yu 等[20]提出了基于机器学习的高斯过程回归(GPR)算法,对可能的参数不断试错,能有效解决数据之间相关性弱的问题。②Δ logR法。Passey 等[21]等选取电阻率曲线与声波时差曲线(或者密度曲线和中子孔隙度曲线)进行叠合分析,用Δ logR法识别烃源岩并计算TOC。该方法需要已知成熟度数据,适用于碳酸盐岩和碎屑岩[1],但电阻率曲线的值变化不宜太小。刘超等[14]提出了变系数的Δ logR法。Zhao 等[22]根据Δ logR法叠合测井曲线的思路,利用密度曲线与中子孔隙度曲线得到了一条黏土指示曲线,与伽马曲线一起能有效地区分富黏土的有机质地层与非有机质地层,2 条曲线的差值(Δd)与TOC 有较好的相关性。Δ logR法适用于烃源岩层和非烃源岩层区分度较高的地区。③神经网络模型。王贵文等[23]利用多层前向(BP)神经网络定性识别了烃源岩层与非烃源岩层,并将神经网络与Δ logR法计算结果进行比较,认为人工神经网络模型不强求预测值接近平均值,且能使预测结果保留实际的细节变化。在预测TOC 方面的明显优势在于不要求测井参数与实测TOC 间具有明显的映射关系,适用于在难以用显性表达式建立测井参数与实测TOC 关系的地区,但该方法在算法上较复杂,需要大量数据的支持才能保证机器学习的预测效果。Johnson 等[24]采用4 种测井曲线监督学习的BP(Back Propagation)算法较好地预测了TOC 值。Shalaby 等[16]对比了传统TOC 预测方法与神经网络模型的差异,发现Δ logR法的预测效果优于神经网络模型。
文昌组为珠江口盆地的主要烃源岩,该层埋深较大,海上钻井很难大量获取烃源岩的测试样品,通过测井参数进行烃源岩TOC 的模拟计算可以弥补样品测试的不足,并进一步预测研究区烃源岩厚度和评价生烃潜力。以该盆地珠一坳陷陆丰凹陷文昌组烃源岩为分析对象,对比多元回归模型、人工神经网络模型和改进的曲线叠合模型在烃源岩TOC 预测中的不同效果,优选有效预测TOC 测井方法组合,以期为全盆地烃源岩TOC 评价提供技术支撑。
1 地质背景
珠江口盆地位于南海北部大陆架,是具有过渡动力背景、下部陆相断陷和上部海相坳陷的被动大陆边缘断陷-坳陷叠合盆地[25-26]。二级构造单元为北部隆起带、北部坳陷带、中央隆起带、南部坳陷带及南部隆起带,共同组成了“三隆两坳”南北分带、东西分块的构造格局[25],其中陆丰凹陷位于北部坳陷带的珠一坳陷内(图1),研究对象为文昌组。

图1 珠江口盆地珠一坳陷平面位置及地层发育特征图(据文献[27]修改)Fig.1 Location and stratum development characteristics of Zhuyi Depression in Pearl River Mouth Basin
文昌组主要为半深湖亚相沉积,岩性以灰黑色泥岩为主,下部为砂岩夹薄层状泥岩,底部为砂泥岩互层[12,28-29](图1)。由于珠一坳陷古近系发育3幕(Ⅰa幕、Ⅰb幕和Ⅱ幕)裂陷旋回[25],相应地发育2套烃源岩,一套位于文昌组,另一套位于文昌组上部的恩平组。下文昌组(文昌组沉积早期,Ⅰa幕)烃源岩TOC 高,有机质类型很好,以Ⅰ—Ⅱ1型干酪根为主,最大残留厚度均超过了800 m;上文昌组(文昌组沉积晚期,Ⅰb幕)烃源岩以Ⅱ型干酪根为主,最大残留厚度达700 m,但生烃洼陷面积增大,有效烃源岩规模也很大[25],因此,能很好地建立起烃源岩地球化学参数与测井参数之间的预测关系。
2 测井预测模型建立
2.1 多元回归模型
通过对陆丰凹陷文昌组烃源岩TOC 和测井参数(66 组数据)的相关关系(图2)对比发现,TOC 与电阻率、声波时差、自然伽马和中子孔隙度均呈正相关关系,与密度均呈负相关关系。每种测井参数与TOC 的相关程度都不均一,则可以考虑对文昌组建立5 种测井参数与TOC 之间的多元回归模型来预测TOC 的大小,通过实测值和预测值的对比以及相关系数来优选出适用的回归预测模型。结合研究区测井曲线与实测TOC 的相关关系和前人模型[11],拟采用以下模型:

式中:a,b,c,d,e,f为待定系数;Rd为电阻率,Ω·m;CNL为中子孔隙度,%;GR为自然伽马,API;AC为声波时差,μs/m;DEN为密度,g/cm3。
具体步骤为:①建立好TOC 和测井参数的计算关系,设置未知参数(a,···,f);②利用现有的实测TOC 数据和对应深度的测井参数,在MATLAB中进行待定系数模型的回归拟合计算,算出未知参数(a,···,f)的回归拟合值,得到多元回归模型;③将没有实测TOC 层段的测井数据代入上述模型中,算出连续的预测TOC。
陆丰凹陷共有4 口井钻遇文昌组,且有实测TOC 数据和对应深度的测井数据,按照半深湖亚相、滨浅湖亚相和三角洲前缘亚相分别建立陆丰凹陷分相带预测模型,可得到3 个相带的模型(表1)。模型中各测井参数的系数表示,在协调5 种测井参数值的条件下,该测井参数对预测TOC值的影响情况。由于不同测井参数之间的数量级有所差异,各系数的数量级也不相同。

图2 陆丰凹陷文昌组各测井参数与TOC 的响应关系Fig.2 Relationship between logging data and TOC content of Wenchang Formation in Lufeng Sag

表1 陆丰凹陷文昌组各相带多元回归预测模型Table 1 Multi-variate regression prediction model for each facies of Wenchang Formation in Lufeng Sag
2.2 BP 神经网络模型
多元回归模型是建立测井参数与TOC 之间的具体函数模型,各值之间有一一对应的映射关系,而人工神经网络方法在很难用显式函数表达的非结构性计算问题方面优越性很大[23],无须事先确定输入(测井参数)输出TOC 之间映射关系的数学方程,仅通过机器自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果,期望值与输出值之差为误差。BP 神经网络的结构组成有输入层、隐藏层和输出层,每一层包含多个神经元(图3),其计算过程由正向计算过程和反向计算过程组成,正向传播过程,输入值从输入层经隐藏层逐层处理,并转向输出层,每一层神经元的状态只影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入反向传播,将误差信号沿原来的连接通路返回,通过修改各神经元的权值,使得误差信号最小,以期使网络的实际输出值和期望输出值的误差均方差为最小。此方法无需明确各测井曲线与对应TOC 之间的响应关系,机器通过大量数据的学习得到测井参数与TOC 之间的对应规则,从而进行TOC 的预测。该方法在四川盆地[22]、鄂尔多斯盆地[30]的实际应用中取得了很好的效果。

图3 BP 神经网络结构模式图Fig.3 Structure model of BP artificial neural network
此模型需要将已知数据按一定比例分为训练集(70%)、验证集(15%)和测试集(15%)。训练集即为网络初始化状态机器需要学习的数据;验证集用于进一步确定模型中的超参数(隐含层的节点个数等),即模型的调参;测试集是用于评估模型的精确度(泛化能力),即评价模型的应用效果。
陆丰凹陷66 组TOC 数据按70%,15%,15%的比例随机分配训练集、验证集和测试集。由于神经网络建立需要基于大量数据的不断学习,受到实际数据量的限制,故未再按照沉积相划分数据。输入层输入5 种测井参数,隐藏层神经元个数设置为10,输出层输出对应的TOC 数据(图3),模型训练算法采用Levenberg-Marqurdt(LM)算法。
2.3 曲线叠合模型
Zhao 等[22]以受黏土矿物和有机质控制的烃源岩的自然伽马测井响应为基础,建立了一套实用的黏土指标曲线(Icl),用密度测井和中子测井反映黏土含量。关系如下

式中:ΦNa为灰岩标定的表观中子孔隙度,%;ΦN为中子孔隙度,%。

式中:ΦDa为灰岩标定的表观密度孔隙度,%;ρb为岩石体积密度,g/cm3;ρma为灰岩密度,取值2.71,g/cm3;ρf为流体密度,取值1.00,g/cm3。

式中:Ic1为黏土指标曲线。
在自然伽马曲线上叠加适当比例的黏土指标曲线,这是为了解决出现在烃源岩电阻率测井读数中的电阻率异常波动而改进的Δ logR法。该模型还有助于区分烃源岩层段和非烃源岩层段,在非烃源岩层段中,2 条曲线相互叠置,而在烃源岩层段中,曲线之间存在着分离。曲线之间的间隔定义为Δd,表示为

其中

式中:GR'为伽马曲线值占其所取刻度范围值的比例;Ic1'为黏土指标曲线值占其所取刻度范围值的比例;Δd为GR'曲线和Ic1'曲线间的间隔;GRleft为自然伽马曲线的左刻度,API;GRright为自然伽马曲线的右刻度,API;Iclleft为黏土指标曲线左刻度,%;Iclright为黏土指标曲线右刻度,%。
Δd大小随干酪根含量的增加而增加。如果建立了实测TOC 与Δd的关系,则可以预测井段的TOC,表示为

此方法是按单井曲线建立预测模型。本文选取陆丰凹陷LF16-X 井进行分析,在对GR曲线和Icl曲线叠合时,由于该井段未见明显的大套非烃源岩层段,2 条曲线无法找到完全叠合的非烃源岩段,并且烃源岩层段由于有机质含量的不同,2 条曲线变化波动程度不同,故在实际操作中取Δd的绝对值。得到关系式

3 结果及讨论
3.1 多元回归模型计算结果
表2 为3 种方法预测TOC 的结果,评价指标为:均方误差(MSE),决定系数(R2)和相对误差,MSE 越小,R2越大,相对误差越小,拟合效果越好。预测结果表明陆丰凹陷多元回归模型半深湖亚相和三角洲前缘亚相的结果要比滨浅湖亚相好,滨浅湖亚相的相对误差为42.4%,半深湖亚相和三角洲前缘亚相相对误差均小于30.0%,所有数据综合的相对误差为29.8%。由于多元回归算法会将所有参合的值平均化,TOC 离散性较高的凹陷或相带,拟合结果会趋于平均值,过高或过低的TOC 点预测与拟结果偏差较大。
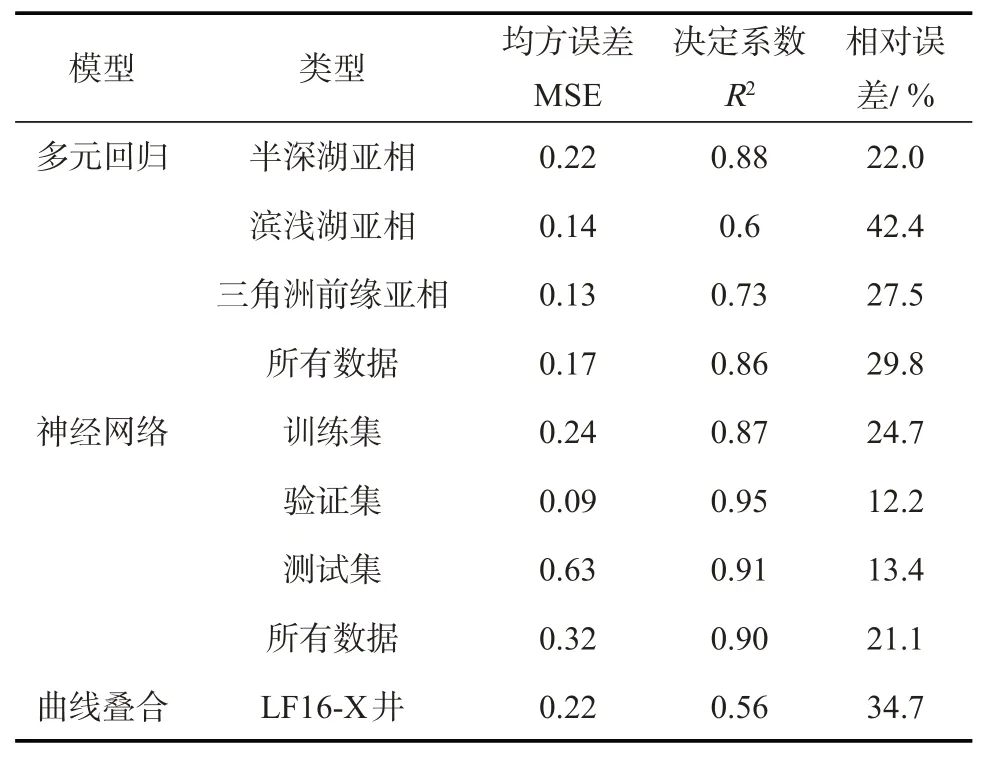
表2 陆丰凹陷多元回归模型、神经网络模型和曲线叠合模型结果对比Table 2 Result comparison of multi-variate regression model,neural network model and curve overlapping model in Lufeng Sag
3.2 BP 神经网络模型计算结果
BP 神经网络模型计算结果与网络参数的设定有一定的关系,包括网络节点、初始权值、最小训练速率和迭代次数(学习次数)等。评价模型应用效果的测试集R2为0.91,所有数据综合的R2为0.90,其相对误差为21.1%。
3.3 曲线叠合模型计算结果
对陆丰凹陷单井进行曲线叠合模型分析,其中LF16-X 井预测结果表明:R2为0.56,MSE 为0.22,相对误差在34.7%左右,预测效果比上述2 种方法稍差。
同时,3 种模型的输出值(预测TOC)与目标值(实测TOC)误差频率分布直方图表明(图4),神经网络模型的误差分布呈标准正态分布,集中在0 值附近,极个别值的误差大于1;多元回归模型的误差均在-1 到1 之间,误差分布比神经网络模型更分散;曲线叠合模型的误差在-1 到1 之间均匀分布。

图4 陆丰凹陷3 种模型实测TOC 与预测TOC 误差分布Fig.4 Error distribution of accurate and predicted TOC content of three models in Lufeng Sag
3.4 讨论
计算结果对比表明:神经网络模型的预测效果最优,与能有效反映有机质含量的自然伽马曲线变化趋势大致相同;多元回归模型对半深湖亚相的烃源岩TOC 预测效果较好,滨浅湖亚相效果次之;曲线叠合模型预测曲线细节反映不强,高频趋势较弱,与自然伽马测井和黏土指标曲线的变化趋势不同,因而应用效果不好(图5—6)。
3 种模型对陆丰凹陷烃源岩TOC 预测效果不同,分析其原因如下:
(1)地质条件和方法优越性决定了神经网络模型的适用性较高。由于陆丰凹陷文昌组沉积相变化较大、薄层砂泥岩互层发育和TOC 值变化较大等多个因素叠加,烃源岩测井响应不明显,TOC 与测井曲线线性相关性低(参见图2)。因此,TOC 与测井参数之间的映射关系难用显式函数表达。对于这一问题,神经网络算法具有很好的优越性。陆丰凹陷的半深湖亚相烃源岩发育,品质较好,与测井参数有很好的相关性,因此,用多元回归模型半深湖亚相预测效果较好。从岩性剖面看,文昌组整体发育湖相地层,各深度段均发育有机质,曲线叠合模型处理中无法找到大套非烃源岩段使曲线叠合(图6),加之该方法在调整曲线范围时存在一定的人为误差,因而对烃源岩段Δd的计算就存在一定的误差,在实际处理中可以结合上覆恩平组进行曲线的叠合。

图5 陆丰凹陷模型预测TOC 与实测TOC 对比(a)—(d)多元回归模型预测结果;(e)—(h)BP 神经网络模型预测结果;(i)曲线叠合模型预测结果Fig.5 Comparison of real TOC with predicted TOC by the models in Lufeng Sag
(2)某些相带的地质条件决定了多元回归模型效果一般。测井参数与TOC 相关性较低,单因素测井曲线往往难以有效区分出烃源岩,多元回归模型综合考虑多条曲线,相关性有明显提高,但该方法误差较大,会对较低值估计过高而对高值估计过低[1]。
测井曲线与岩性以及岩石的有机地球化学参数存在一定的对应关系,这种对应关系是烃源岩TOC 测井预测的基础,但在实际操作中,由于区域地质情况复杂,成岩作用、后期改造作用等因素导致烃源岩的测井响应不明显。在对烃源岩TOC 进行测井预测之前应对TOC 与测井参数的相关性进行分析。沉积相对岩性的控制作用较强,可按不同沉积相进行相关性分析,若相关性较好,可以采用多元回归模型进行预测,由于地区地质背景差异,建模过程中应综合考虑地质情况,每个地区应单独建模分析;若很难找到TOC 与测井参数的对应关系,可以采用非线性的神经网络模型计算,大量的数据能提高机器学习的效果,预测的结果也更好。
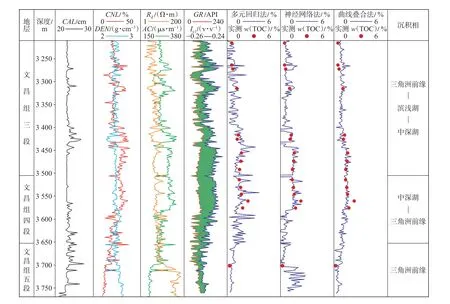
图6 陆丰凹陷LF16-X 井3 种测井预测方法预测结果对比Fig.6 Comparison of three logging prediction methods of well LF16-X in Lufeng Sag
4 结论
(1)利用电阻率曲线、声波时差曲线、中子孔隙度曲线、自然伽马曲线和密度曲线等5 种测井参数,采用多元回归模型、BP 神经网络模型和曲线叠合模型对陆丰凹陷文昌组烃源岩TOC 定量预测是可行的。
(2)多元回归模型对半深湖亚相、三角洲前缘亚相的TOC 预测效果较好,对滨浅湖亚相的预测效果次之,这与沉积相控制的岩性发育有关;BP 神经网络模型预测TOC 整体效果比多元回归模型好,预测结果受到训练数据量的影响,数据量太少不适用此方法;曲线叠合模型预测效果较差。
(3)多元回归模型需要实测TOC 与测井参数有明显的响应关系,并根据实际地质情况选取不同的模型参数;实测TOC 与测井参数的对应关系较弱,可采用神经网络模型,模型预测的效果与输入数据量有关,也与数据本身的质量有关;曲线叠合模型适用于自然伽马曲线对黏土和TOC 响应明显的地层,并且目标曲线在非烃源岩层能较好叠合。
猜你喜欢
军事文摘(2022年18期)2022-10-14
理财周刊(2022年4期)2022-04-30
中国海上油气(2020年5期)2020-10-20
天府新论(2020年1期)2020-01-07
石油地质与工程(2019年3期)2019-09-10
西南石油大学学报(自然科学版)(2018年2期)2018-06-26
源流(2016年2期)2016-04-09
大江南北(2016年8期)2016-02-27
西南石油大学学报(自然科学版)(2015年4期)2015-08-20
中国海上油气(2015年3期)2015-07-01
