
决策空间定向搜索的高维多目标优化策略*
2019-10-24 05:49郑金华董南江杨圣祥
软件学报 2019年9期
郑金华,董南江,阮 干,邹 娟,杨圣祥,3
1(智能计算与信息处理教育部重点实验室(湘潭大学),湖南 湘潭 411105)
2(智能信息处理与应用湖南省重点实验室(衡阳师范学院),湖南 衡阳 421002)
3(School of Computer Science and Informatics,De Montfort University,Leicester LE19BH,UK)
通讯作者:董南江,E-mail:643260047@qq.com;邹娟,E-mail:zoujuan@xtu.edu.cn
现实世界中存在多目标优化问题(multi-objective optimization problem,简称MOP)[1,2],这些多目标优化问题中不同目标之间的优化存在着相互冲突的关系,不同于单目标优化问题的最优解只有一个,多目标优化问题的最优解是一组均衡解.多进目标化算法(multi-objective evolutionary algorithm,简称MOEA)[1,2]是一类基于群体智能的迭代优化算法,因其能够在单次运行中找到一组解,被广泛地应用于求解多目标优化问题,受到越来越多研究者的关注.MOEA 的目标是寻找尽可能接近最优均衡解集的一组均衡解集,这组决策向量解集称为帕瑞托解集(Pareto set,简称PS),PS 对应的在目标空间的目标向量集称为帕瑞托前沿(Pareto front,简称PF).
现有的MOEA 在求解多目标优化问题时有两个关键的部分,一是如何生成解,二是如何保留解.
· 如何生成解主要与交叉及变异算子相关,对于连续多目标优化问题经常使用的交叉及变异算子有模拟二进制交叉[3,4]、差分变异[5]、多项式变异[6]等;
· 对于如何保留解可以根据保留解的方式把现有算法大致分为:基于支配关系的算法,如NSGA-II[7],SPEA2[8]等;基于分解和参考点的方法,如MOEA/D[9]及其衍生算法、NSGA-III[10]等;基于指标的算法,如HypE[11]等.保留解通常选择适应度值高的个体保留下来,将适应度值低的个体删除掉.适应度的计算通常会考虑解的收敛性和分布性,常用的分布性保持机制有聚集距离方法[7]、修剪的方法[8]、小生境技术[1]、均匀生成权重向量[9]或参考点方法[10]等,常用的收敛性保持机制有 Pareto 支配[1,7]及MOEAD 中用到的聚集函数[8]等.
传统的基于支配关系的算法,如NSGA-II 和SPEA2,在求解低维的多目标优化问题时已具有较好的效果,但是随着目标维数的增加,当目标数大于3 时,问题的优化难度将显著增加.主要原因有:(1)算法本身的搜索能力不足;(2)选择压力不足.目标维数增加后,不同目标间优化冲突加剧,收敛性和分布性难以平衡[12-15].当优化问题的最优PF 比较复杂和目标维数较大时,基于分解的算法就很难恰当地对问题进行分解[16].基于指标的算法对于高维多目标优化则随着目标维数增加,算法的时间复杂度呈指数增加;同时,由于指标的特性,会使得算法偏好于PF 中的某些特殊点[16].
现有MOEA 的普遍做法是:在一次种群迭代优化过程中同时保持种群的多样性和收敛性,计算资源分配均匀,试图在每次迭代中覆盖整个PF,相应的计算资源也总是均匀地分配在整个PF 上,导致具体分配到每个PF 的子部分计算资源匮乏.对高维MOP 来说,算法本身搜索能力已经不足,这时再将计算资源均匀分配,则会导致每一子部分的搜索能力更加不足,从而进一步降低算法的搜索能力.
另一方面,现有MOEA 对优化问题的特性利用并不是很充足.根据库恩塔克定理,连续多目标优化问题的特性[17,18]是PS,是m-1(m为MOP 的目标维数)维的流体,同时,交叉变异算子的共性是子代个体与父代个体成一定关系,以更高的概率分布在父代个体周围[3-6],因此,在PF 附近的父代个体更容易生成好的子代个体.
本文主要是对基于支配关系这一类算法进行研究.根据以上两点,在如何生成解方面做了进一步的工作,利用多目标优化问题的特性,为克服多目标优化算法在高维问题中遇到的困难,提出了基于决策空间的定向搜索策略(decision space,简称DS),通过影响子代个体的生成区域来影响算法的收敛性和分布性.基本思想是,将算法的整个优化过程分为3 个阶段:第1 阶段,针对问题进行采样分析,判断出问题决策空间的收敛性控制向量和分布性控制向量,并在之后的搜索过程中,基于采样分析结果确定收敛性子空间和分布性子空间;第2 阶段,算法沿着收敛性子空间搜索,使少数解先到达真实PF 附近;第3 阶段,算法沿着分布性子空间搜索,使种群尽可能接近且广泛地覆盖真实PF.基于问题采样的分析结果,先在收敛性子空间中搜索,不仅局部集中了计算资源,同时也克服了高维问题中选择压力不足的问题,当少数个体逼近真实PF 后,再通过在分布性子空间的搜索,使种群均匀广泛地覆盖整个PF.
近年来,也有关于目标空间收敛性和分布性的研究,主要代表有大规模多目标进化算法LMEA[19].LMEA主要是通过对决策变量分类,然后对分类后的决策变量进行分别优化的算法.本文是提出一种有方向性地搜索的策略,可以与其他基于支配关系的算法相结合.本文中,DS 策略的采样分析方法确定搜索方向与决策变量分类有一定的相似性,但是整体的搜索策略是完全不同的:LMEA 算法中,依然把收敛性和分布性在一次迭代优化中同时考虑;而DS 策略则是将收敛性和分布性按阶段分开考虑,收敛性相同的个体间比较分布性,分布性相同的个体间比较收敛性,增加了算法的搜索能力.
本文的主要贡献如下:
(1)对解决高维连续多目标优化问题提供了新的视角.由于连续多目标优化问题的特性及优化过程中收敛性和分布性难以平衡,而直接将收敛性和分布性分开在算法的不同阶段进行搜索;
(2)新个体的产生不再是独立于优化问题.以往算子在生成个体时是独立于目标空间的,目标空间不会对其产生影响;DS 通过优化问题的采样分析,判断问题在决策空间以及目标空间的变化趋势,分析结果将对算法搜索过程中子代个体的生成进行宏观的影响,一定程度增强了算法的搜索能力;
(3)将DS 策略结合到NSGA-II,SPEA2 中,通过DTLZ,WFG 测试问题对DS-NSGA-II 进行了测试.并与一些比较经典和流行的算法进行了对比实验.
本文第1 节主要介绍动机及给出的相关定义.第2 节详细介绍基于决策空间的定向搜索策略.第3 节进行实验对比并对实验结果进行分析.第4 节对本文进行总结及展望下一步研究工作.
1 动机及相关定义给出
1.1 连续多目标优化问题的特性
根据库恩塔克条件(KKT)可以得出:对于连续的多目标优化问题,PS 是分段连续的m-1 维流体,m为目标空间的维数.这种性质称为多目标优化问题的特性[17,18].
定理1.假设当x*∈Ω(Ω的维数为n)时,目标函数fi(x),i=1,…,m是连续可微的,如果x*是一个Pareto 解,则存在一个向量α≥0,满足:

满足公式(1)的点称为KKT 点.公式(1)有n+1 个等式约束和n+m变量x1,…,xn,α1,…,αm,因此在连续可微的情况下,多目标优化问题的PS 是分段连续的m-1 维的流体.具体地说,对于二维的优化问题,其PS 是一条曲线;对于三维的优化问题,其PS 是一个曲面.
由于PS 是m-1 维的流体,为简化理解,我们将个体在决策空间中距真实PS 上某一点的距离视为搜索到该点所需的计算资源,则可以得出这样的结论:在真实PS 附近的父代个体,更容易生成位于PS 附近其他位置上的子代个体.如图1 所示,曲线为真实PS,A,B个体是已知的父代个体,C为想要搜索得到的子代个体,由于A个体相对于B个体更靠近C,则相较于B个体,通过A个体进行基因重组更容易搜索得到C个体.
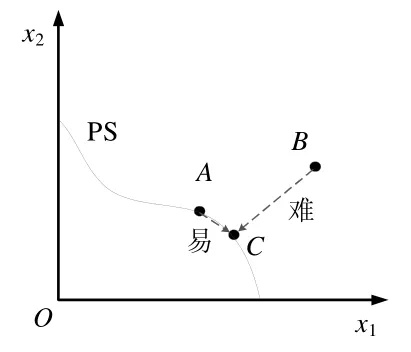
Fig.1 Schematic map of search difficulty图1 搜索难易程度示意图
1.2 计算资源分配
现有多目标优化算法的普遍做法是:在一次迭代过程中试图保证整个种群在目标空间的收敛性和分布性,算法的收敛性保持机制和分布性保持机制在同时发挥着作用.因此,整个种群是在不断地迭代优化过程中整体去逼近整个真实PF.
MOEA 每一次迭代优化得出的解集中,个体的收敛程度和分布均匀性是不尽相同的.不过,为了方便理解,暂且将其理解为大致相同.如图2 所示,F1,F2视为目标空间中平行于真实PF 的一层子空间,将F2附近的个体作为一个种群P2,种群大小为n,经过m次迭代进化后得到F1附近的种群P1.由于算法在每次迭代中同时保证种群的分布性和收敛性,因此可以近似理解为种群P2是沿着虚线方向同步搜索至种群P1.如果将每个个体看做计算资源的单元,则P2搜索至P1消耗计算资源m×n,每一条虚线方向分配计算资源m个.因此可以理解为传统的MOEA 是将计算资源尽量均匀分配,求得最优PF 的各个子部分,各子部分之间通过遗传算子存在一定的联系.
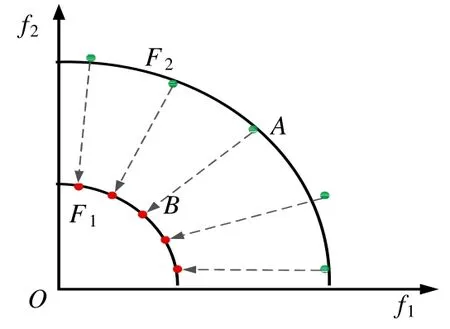
Fig.2 Schematic diagram of resource allocation model图2 资源分配模型示意图
1.3 收敛性与分布性
多目标优化算法追求的目标是求得的最终解集尽可能地靠近真实的PF,同时尽可能均匀和广泛地覆盖真实PF,前者是收敛性,后者是分布性.在多目标优化过程中,尤其是高维多目标优化问题,生成的解绝大部分个体是互不支配的,且收敛程度是不一样的.下面将给出一些名词的含义.
· 收敛度:如果我们把目标空间进行分层,真实PF 为最里层,每一层与真实PF 结构平行相似,个体所在层的位置代表其收敛程度,越接近真实PF 层,则收敛程度越高;
· 同收敛性个体:将收敛程度相同(位于同一层)但在不同位置的个体称为同收敛性个体;
· 同分布性个体:将在每一层中相对位置相同但收敛程度不同的个体称为同分布性个体.
如图3 中,F1为目标空间中真实PF,则3 条曲线的收敛程度是:F1>F2>F3;A点和B点都位于F2层附近的不同位置,所以A,B为同收敛性个体;同理,B点和C点位于不同层的附近,但在各自层的相对位置相同,所以B,C为同分布性个体;而A点和C点则是收敛性和分布性都不相同的个体.在高维多目标问题优化时,种群中个体间的关系绝大部分是A点和C点的关系.
· 收敛性子空间:在决策空间中存在这样一个子空间Ω:在Ω中,绝大部分个体之间是支配与被支配的关系,则称Ω空间为收敛性方向子空间;
· 分布性子空间:在决策空间中存在这样一个子空间Ω:在Ω中,绝大部分个体之间是互不支配的关系,则称Ω空间为分布性方向子空间;
· 子空间的确定:先确定一个点R,以R点为基点,结合子空间控制向量V[n],确定子空间Ω.
子空间控制向量V[n],n为决策空间变量的维数,V[i]值为0 或1:V[i]为1,则表示子空间Ω在Xi变量上的范围是变量Xi的上下界;V[i]为0,则表示子空间Ω在Xi变量上为固定值,其值的大小由点R在Xi变量上的值确定.
以图3、图4 为例,将图4 中的个体与图3 中的个体相对应,图4 为个体在决策空间的位置,图3 为个体在目标空间的位置.图4 的决策变量是2 维的,则其子空间是一维的.从图3 可以看出,A,B为收敛程度相同分布位置不同的个体,所以A,B在决策空间中同一个分布性子空间;而B,C在同一收敛性子空间,为分布性相同收敛性不同的个体.收敛性子空间Ω1由C(或B)和收敛性控制向量V-con={1,0}确定:V-con[0]=1,表示Ω1子空间在X1变量上的范围是X1的定义区间;V-con[0]=0,表示子空间Ω1中X2变量的值与个体C(或B)的X2相同.同理,分布性子空间Ω2由个体A(或B)和分布性控制向量V-div[2]确定,V-div[0]={0,1}:V-div[0]=0,表示子空间Ω2中X1变量的值与个体A(或B)的X1相同;V-div[1]=1,表示子空间Ω2在X2变量上的范围是X2的定义区间.
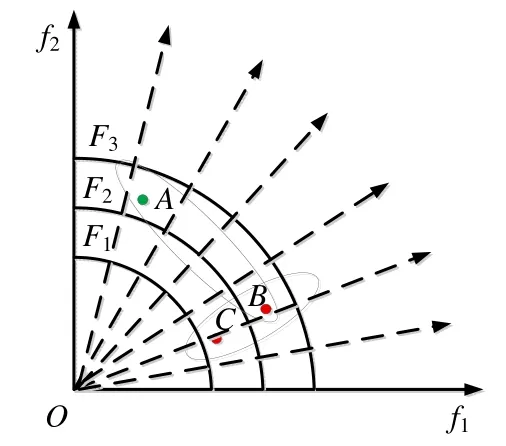
Fig.3 Convergence and distribution图3 收敛性和分布性
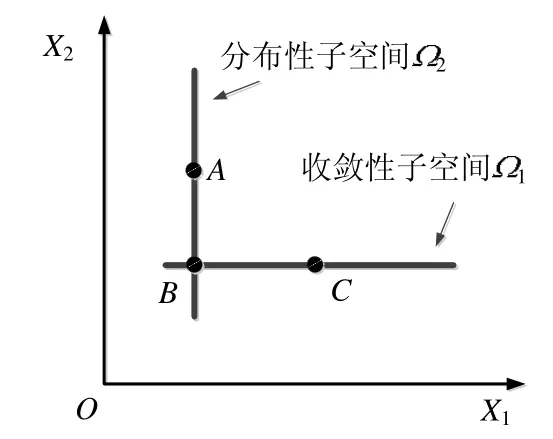
Fig.4 Subspace model图4 子空间模型
在本文中,点和控制向量确定子空间的方法只能确定与某一轴垂直或平行的子空间.对于ZDT,DTLZ,WFG等一系列问题,使用该方法已经可以较准确地确定收敛性和分布性子空间.在本文中,我们也只考虑了这种情况.而当PS 比较复杂时,通过这种方法去确定子空间的准确性会降低,这时会导致算法的搜索效率不高.在实际应用中也有许多问题PS 是相对复杂的,对于复杂PS 多目标优化问题对应的子空间的确定,将是我下一步研究的重点内容.
现有的MOEA 在对收敛性不同且互不支配的个体进行选择时,根据算法偏好对收敛性和分布性进行量化,然后择优选择或随机选择[20-23].图3 中,A点和C点的收敛性和分布性均不同,这时对A和C做出选择必然对种群的收敛性或分布性一方造成损失:选择A点损失种群的收敛性,选择C点损失种群的分布性.正确的做法是在相同分布性的个体之间比较收敛性,然后择优保留;在相同收敛性的个体之间比较分布性,然后择优保留.
本文的出发点就是摒弃之前MOEA 在每一次迭代中同时保证种群的分布性和收敛性的做法,在搜索过程中,宏观影响子代个体的生成区域,集中计算资源先保证种群的收敛性,使少数解快速搜索到真实PS 附近,然后根据多目标优化问题的特性进行分布性搜索,使整个种群均匀覆盖PF.这样,在具体到一个子部分时,相当于增加了算法的搜索能力.而将算法的收敛性和分布性分开,也增加了环境选择时的选择压力.以图2 为例,先集中整个种群的计算资源,从A点开始沿着AB虚线方向搜索,使得少数解快速搜索至B点;然后改变搜索方向,利用算法分布性保持机制使种群较好地覆盖整个PF.
2 DS:基于决策空间的定向搜索策略
2.1 基本思想
根据连续多目标优化问题的特性,即多目标优化问题的真实PS 是一个m-1 维的流体,可以得出:如果有一个解先到达真实PF 附近,可以通过这个解更快地找到其他好的解,然后通过分布性保持策略,最终使得整个种群较好地覆盖整个PF 面.
与之对应,在算法的搜索过程中分为两个阶段——收敛性搜索阶段和分布性搜索阶段:收敛性搜索阶段,算法侧重于问题的收敛性,其目的是优先使得少数解到达真实PF 附近;分布性阶段,基于优先到达PF 附近的少数几个个体,确定分布性子空间,通过重组算子及分布性保持策略,将整个种群扩展开来覆盖整个PF.
在第1.3 节中,通过对问题分布性和收敛性的分析得出:不同收敛性、不同分布性个体之间的比较优劣进而选择,必然导致收敛性或分布性其中一方受到损失,而相同收敛性个体之间比较分布性,相同分布性个体之间比较收敛性,这样才更高效.所以在搜索过程的收敛性搜索阶段,尽可能产生分布性相同的个体,比较其收敛性,使得少数个体快速抵达真实PF 附近;在分布性搜索阶段,基于快速抵达真实PF 的少数解,通过重组算子生成收敛性相同但分布性不同的解,通过分布性保持策略,使整个种群更好地覆盖整个PF.
从图5 中可以了解到基于决策空间的定向搜索策略的整体框架:先对多目标优化问题进行采样分析,确定收敛性子空间和分布性子空间的控制向量,在不同搜索阶段,根据子空间控制向量确定搜索子空间,通过子空间映射有效控制子代个体生成区域,这时,父代个体产生子代个体并不是独立于优化问题的,而是受到问题采样分析结果的宏观影响,同时也达到集中计算资源的效果.当结束条件满足时,输出最新优化种群作为最优解集.收敛性子空间搜索时,种群个体多为同分布性个体;分布性子空间搜索时,种群多为同收敛性个体.
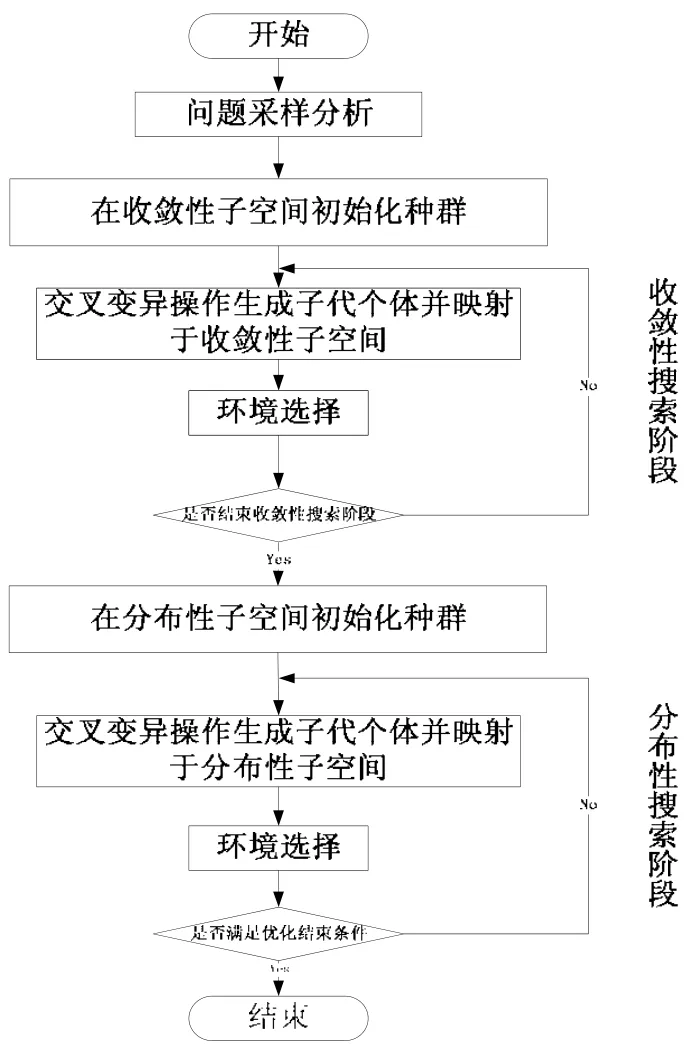
Fig.5 Flow chart of the algorithm图5 算法流程图
整体思想虽然简单,但有如下优点:首先,优化问题的特性及基因重组算子生成子代个体在父代个体周围的特性,决定了先收敛性后分布性搜索策略的可行性,DS 策略充分利用了连续多目标问题的特性来增强算法的搜索效率;其次,将收敛性和分布性分开在不同阶段搜索,化解了高维多目标优化问题中收敛性和分布性难以平衡的难点,使得该策略在高维优化问题中会有较好的表现;最后,收敛性和分布性分开搜索可以使计算资源在具体时刻具体子部分更加集中,增强了算法的搜索能力.
2.2 算法流程
基于决策空间定向搜索策略可以与基于支配关系的算法相结合,解决高维的连续多目标优化问题,而且对原有算法的改动较小,使得加入DS 策略比较简单.图5 中给出了结合DS 策略的算法流程.
问题采样分析在一定程度上是对问题特性的一种解析,问题的采样分析得出解空间中收敛性子空间和分布性子空间的方向趋势特征,即子空间控制向量.需要注意的是:
· 在收敛性搜索阶段,是要使少数解快速搜索到真实PF 上的任意一个位置,所以在种群初始之初随机生成一个解,以该个体为中心,结合收敛性子空间控制向量确定收敛性子空间,在收敛性子空间中生成初始种群,然后不断迭代,在收敛性子空间搜索优化;
· 在分布性搜索阶段,初始化与收敛性类似,不同的是以收敛性搜索阶段所得的最优的一个或少数几个最优解为中心,结合分布性子空间控制向量确定分布性子空间.
结合DS 策略的算法并没有对原算法的收敛性和分布性保持机制进行改动,算法仍然使用原算法的环境选择和匹配选择机制.DS 策略主要是通过控制算法的搜索区域(即子代个体的产生区域)来影响算法的收敛性和分布性.在收敛性搜索阶段,算法主要在收敛性子空间搜索,种群内个体多为同分布性个体,此时,算法侧重于种群的收敛性,这时主要是原算法的收敛性机制发挥作用,集中计算资源,使少数解快速优化至真实PF 上或附近;在分布性搜索阶段,算法主要在分布性子空间搜索,种群内个体多为同收敛性个体,算法侧重于种群的分布性,这时主要是原算法的分布性机制发挥作用,使种群可以很好地覆盖整个PF.
2.3 问题采样分析
问题采样分析的准确程度很大程度决定了算法优化的速率和准确度.通过问题采样分析,我们得出分布性子空间和收敛性子空间的控制向量,进而确定收敛性子空间和分布性子空间,对迭代优化过程中生成子代个体进行引导,提高搜索效率.算法1 描述了问题采样分析的流程.
算法1.优化问题采样分析.
输入:决策变量维数n,优化问题,对每一维决策变量采样次数J;
输出:收敛性子空间控制向量:V-con[n];分布性子空间控制向量:V-div[n].

这里,针对每一维的决策变量进行J次的个体采样,决策变量维数是n,则总的采样个体数为n×J.对于第i维决策变量采样得到的J个个体,如果J个个体均为支配或被支配关系,则赋值V-con[i]=1,V-div[i]=0;反之,则赋值V-con[i]=0,V-div[i]=1.最终得出子空间控制向量V-con[n],V-div[n].关于如何通过子空间控制向量V-con[n],V-div[n]来确定子空间,已在第1.3 节中说明并举例.
2.4 子空间映射
不同的搜索阶段在相对应的子空间进行搜索优化.当子空间确定后,由于算法的搜索是集中计算资源对相应子空间进行优化搜索,而在以往的进化算法中采用的基因重组算子生成的解很有可能不在我们确定的目标子空间(收敛性子空间或分布性子空间)中,本文并没有重新设计算子使得生成的解位于目标子空间内,而是采用原有的基因重组算子生成子代个体,然后通过一定的位置变换,使得新生成的个体位于目标子空间中.在本文中,我们具体采用的是映射的方法,将生成的子代个体映射到目标子空间中去,集中计算资源在相应的子空间中搜索.算法2 具体描述了如何在目标子空间生成子代个体.
算法2.在目标子空间生成解.
输入:种群P,种群大小N;
输出:种群Q.

以图6 为例,在二维的决策空间中,子空间为一维的流体,A′点为通过现有的交叉变异及变异算子生成的子代个体,将个体A′对子空间进行投影,得到个体A″,这时,用A″替代个体A′进行之后的个体评价及算法优化.

Fig.6 Subspace mapping图6 子空间映射
2.5 算法时间复杂分析
在算法中加入DS 策略,并不会增加原有算法的时间复杂度.DS 策略的加入,是对原有算法的搜索过程进行了宏观的控制.相对于原算法,DS 策略的加入主要是增加了问题采样和生成子代个体时的目标子空间映射.问题采样分析的时间复杂度为n·J(n为决策空间维数,J为针对每一维变量的采样次数);目标子空间映射在上一节详细描述,并不会增加算法时间复杂度,因此,加入DS 策略并不会增加算法的时间复杂度.例如,NSGAII 的时间复杂度为O(rN2),则加入DS 策略的时间复杂度仍是O(rN2);SPEA2 的时间复杂度为O(rN3),则加入DS 策略的时间复杂度仍是O(rN3).其中,r为优化问题的目标维数.
3 实验分析
DS 策略可以与基于支配关系的算法相结合,而与其他有强制性机制保证分布性和收敛性的算法则较难结合,比如MOEAD,NSGA-III,因为MOEAD 中均匀生成权重向量、NSGA-III 中的均匀生成参考点等这些机制导致DS 策略前期侧重收敛性搜索优化时效果不佳,因此本文选择NSGA-II,SPEA2 算法与DS 策略结合进行实验比较与分析.为了检验DS 策略的有效性,首先将结合了DS 策略的NSGA-II,SPEA2 算法(DS-NSGA-II,DSSPEA2)与原NSGA-II,SPEA2 算法进行实验对比,来检验加入DS 策略之后对原有算法的影响;然后,基于DSNSGA-II 选取一些比较经典主流的算法MOEAD-PBI,NSGA-III,Hype,MSOPS[24],LMEA 算法做对比实验,来进行性能比较,检验DS-NSGAII 在高维多目标优化问题中的性能.本文采用DTLZ 系列[25]、WFG 系列[26]测试问题,并分别采用IGD[27]和HV[28]指标对优化结果进行评价.DTLZ,WFG 系列测试问题包含多种特性,包括线性问题、凸面问题、凹面问题、多峰问题、连续问题、非连续问题以及退化问题等[20,21].
3.1 实验参数设置
为了公平地比较所有的优化算法,本文采取推荐的参数值作为算法比较的参数值.本文涉及到的算法采用模拟二进制交叉和多项式变异的方法生成子代种群.正如在文献[16]中推荐的,交叉的分配指标数(Nc)设为20,变异的分配指标数(Nm)设定为20,并且交叉的概率(Pc)设定为1.0,变异概率(Pm)设定为1/D,其中,D是决策变量的数量.为了避免生成的权重分布在Pareto 前沿的边界上,采用NSGA-III 推荐的双层参考点生成策略[10]去生成均匀分布的MOEA/D 权重向量和NSGA-III 的参考点.DS 策略中采样分析部分取J值为8.J值越大,采样分析结果越准确,对于绝大多数问题,J取8 已经可以较准确地确定子空间的控制向量.本文其他算法对同一问题采用相同的种群大小,对于4 维~10 维的测试问题设置种群大小为120,对于15 维、20 维的测试问题设置种群大小为220.Hype,MSOPS,LMEA 均采用原文推荐的参数设置[11,19,24].每个算法针对所有测试问题都进行30 次独立重复实验.本文以个体的总评价次数作为算法的结束条件,表1 为所有的测试问题及其相对应的结束条件.

Table 1 Terminate conditions表1 结束条件
在DS 策略中,两个搜索阶段间的转换有一个条件,这里同样把评价次数作为转换的条件.将转换搜索阶段的评价次数设置为SUM×r,r为一个比值,取值范围[0,1].当已评价的次数大于SUM*r时,将收敛性搜索阶段转变为分布性搜索阶段.
r的取值范围平均分成10 等分(参数变化梯度为0.1)进行实验(r为0,即没有收敛性搜索,显然不利于问题的优化,所以是以r取值0.1 为起始值进行的实验),并统计DS-NSGA-II 算法在参数r不同取值下的IGD 值变化规律,独立重复实验30 次.如图7 所示,给出了难收敛问题DTLZ3、退化问题DTLZ5、不连续PF 问题DTLZ7在8 维目标上的实验结果.
r的值反映了在收敛性搜索阶段分配的计算资源,从图7 中可以看出,
· 当r=0.1 时,IGD 值很高;
· 随着r值的增加,IGD 值显著减少;
· 当r为0.5 时,IGD 值到达最小值;
· 之后,再随着r值的增加,IGD 值并没有再减少甚至有增大的趋势.
这是因为当部分点已经优化至真实PF 附近时,再增加更多的计算资源也不会改善其收敛性,因为其收敛性已经最优.因此,本文将r的值设为0.5,即收敛性搜索阶段和分布性搜索阶段获得的计算资源基本相同.

Fig.7 IGD means with different values of r图7 r 取不同值情况下的IGD 均值
3.2 评价指标
本节介绍两个综合性评价指标,分别是反转世代距离IGD[27]和超体积指标HV[28].
· 反转世代距离IGD 采用Pareto 最优解集真实PF*中的个体到算法所求得的非支配解解集的平均距离来表示,其计算公式为

· 超体积指标HV 因其良好的理论支撑,已成为较流行的评价指标.通过计算非支配解集与参考点(最差点)围成的空间的超体积的值,实现对MOEA 综合性能的评价,计算公式为

其中,λ代表勒贝格测度;vi代表参考点和非支配个体pi构成的超体积;S代表非支配解集,pi为S中的第i个个体.由于超体积指标HV的计算时间非常大,本文采用蒙特卡洛HV指标.
3.3 实验结果分析
本节中将实验结果以图表的形式给出,表2 列出了所有实验的均值和方差(括号内是方差).其中表现最好的结果用灰色底纹标识.本文通过符号检验的方法对实验数据进行显著性分析,其中,显著性水平阈值设置为0.05,signtest值越小,表明算法间的显著性差异越大.†标识signtest值小于0.05 的情况.
1)DS-NSGA-II VS NSGA-II &DS-SPEA2 VS SPEA2
DS 策略可与基于支配关系的多目标进化算法相结合.本文将基于支配关系的经典算法NSGA-II 和SPEA2与DS 策略相结合,分别得到算法DS-NSGA-II 和DS-SPEA2,采用DTLZ 系列测试问题进行测试,通过对比引入DS 策略前后算法的性能来验证DS 的有效性.NSGA-II 和SPEA2 在低维多目标优化问题中算法性能较好,且DS 主要是针对高维多目标优化问题的一种策略,所以在该节中对DTLZ 系列测试问题在4 维~6 维、8 维这4个维度进行对比实验.IGD 作为评价指标,实验结果在表2 中给出,IGD 均值越小,表示算法性能越优秀.
从表2 可以看出:由于DS 策略的引入,在DTLZ 系列测试问题中,DS-NSGA-II 和DS-SPEA2 在几乎所有问题的不同维度上性能都优于NSGA-II 和SPEA2,尤其对于比较难收敛的DTLZ1,DTLZ3 问题.从表中可以看出,NSGAII,SPEA2 算法的求解结果随着目标维数的增加,IGD值也显著增加;而结合DS 策略之后,求解结果的IGD值全部降低到1 以内.可见:随着目标维数的增加,DS 策略对算法性能提高的程度也越高.NSGA-II 和SPEA2 在求解高维多目标优化问题时能力匮乏,主要原因一是随着目标维数的增加,非支配解集在种群中的占比显著增加,导致算法的选择压力显著下降;二是目标维数的增加一般伴随着决策空间的增大,决策空间的增大导致算法的搜索能力不足.而DS 策略的引入,收敛性搜索阶段在收敛性子空间产生解,减小了非支配解集的比例,增加了选择压力.不同阶段在不同子空间搜索,避免了收敛性和分布性难以平衡的难点,集中了计算资源,增加了算法的搜索能力.因此,DS 策略的引入,加强了NSGA-II,SPEA2 在求解高维多目标优化问题上的性能.
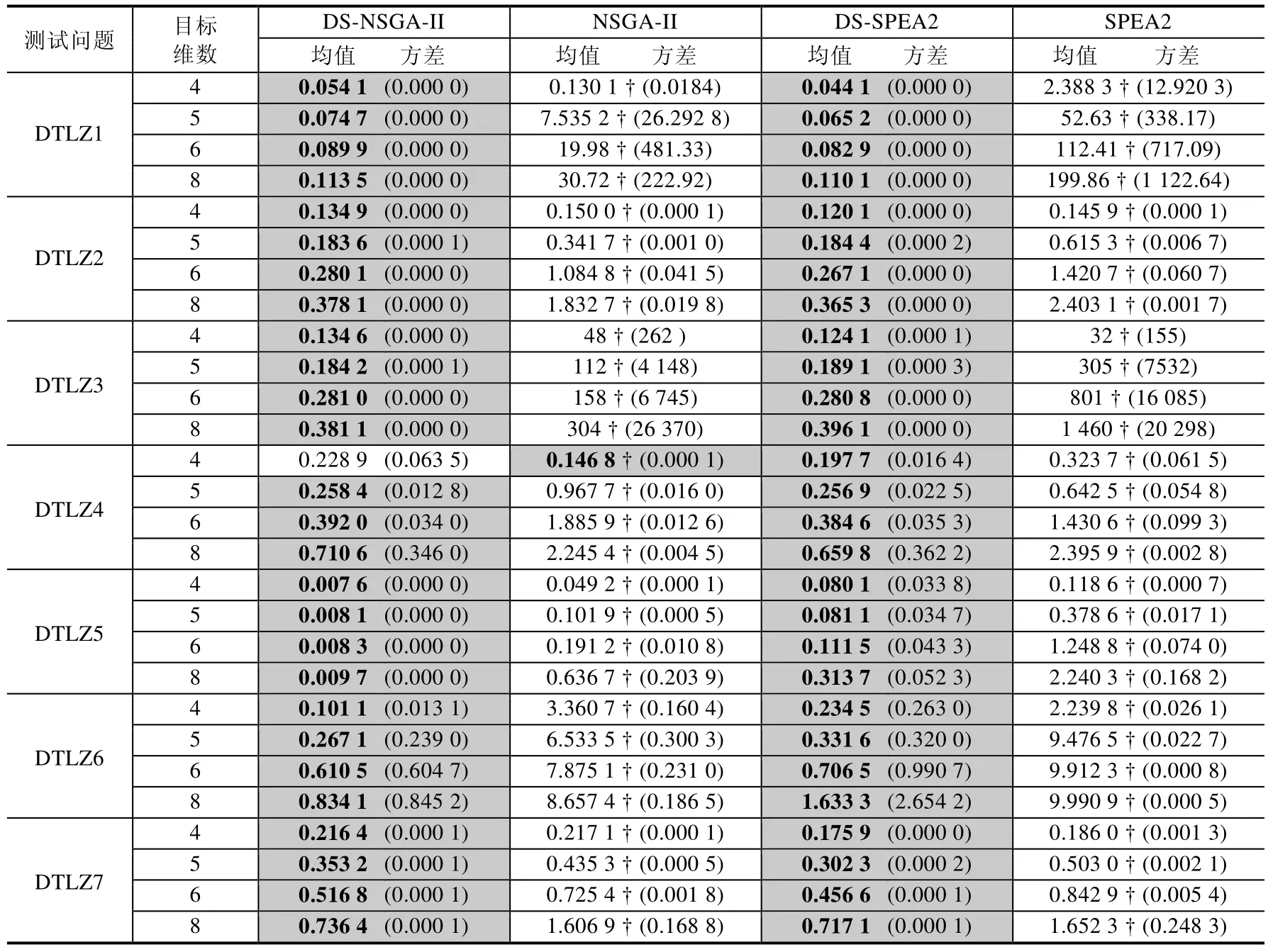
Table 2 Experimental results of DS-NSGA-II,NSGA-II,DS-SPEA2 and SPEA2 on DTLZ test problems表2 DS-NSGA-II,NSGA-II,DS-SPEA2,SPEA2 在DTLZ 测试问题上的实验结果
图8、图9 是4 个算法对5 维的DTLZ1,DTLZ3 问题的优化结果图,图中平行坐标中,横坐标是目标空间不同的目标,纵坐标是目标值.从图8、图9 中可以看出,引入DS 策略后的算法在DTLZ1 问题上目标值可以很好地收敛到0~0.5 范围内且分布性良好;在DTLZ3 问题上,目标值可以很好地收敛到0~1 范围内且分布性良好;而原算法NSGA-II 和SPEA2 则不能收敛.同时我们也可以看到,DS-SPEA2 在DTLZ1,DTLZ3 上的分布性略好于DS-NSGA-II.这是由于SPEA2 的修剪策略比NSGA-II 的聚集距离在分布性保持上要好一些,但是修剪策略的时间复杂度相对较大.从图中可以直观地体会到:DS 策略的引入,使算法在高维多目标问题优化上性能有了显著的提升.
2)与其他算法比较
本节主要是进一步验证DS 策略的有效性,证明将收敛性和分布性分开考虑的可行性,所以选取了不同类型的MOEAS 中比较有代表性的算法进行对比实验.由于DS-SPEA2 的时间复杂度相比DS-NSGA-II 的时间复杂度要大,所以在本节中,我们采用DS-NSGA-II 与不同类型的算法进行进一步的比较,包括MOEAD-PBI,NSGA-III,Hype,MSOPS,LMEA.MOEAD 是基于分解的算法,NSGAII 是基于参考点,Hype 是基于指标的,MSOPS是基于新支配关系,LMEA 是一种决策变量分类的大规模多目标算法.测试问题采用DTLZ 系列和WFG 系列,分别在8 维、10 维、15 维、20 维这4 个维度上做对比实验.DTLZ 问题采用IGD 评价指标,WFG 问题采用HV指标,IGD指标数值越小,表示算法性能越优秀;HV指标数值越大,表示算法性能越优秀.表3 是DTLZ 系列测试问题的IGD指标测试结果,表4 是WFG 系列测试问题的HV指标测试结果.
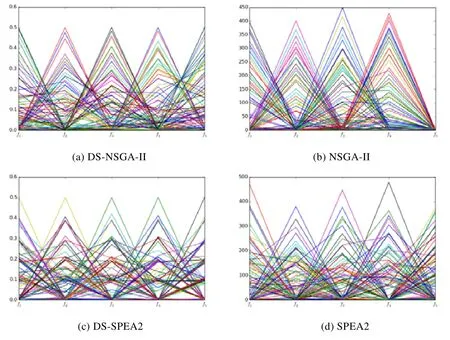
Fig.8 Experimental results of DS-NSGA-II,DS-SPEA2,NSGA-II and SPEA2 on DTLZ1 problem图8 DS-NSGA-II,DS-SPEA2,NSGA-II,SPEA2 在DTLZ1 问题上的实验结果图
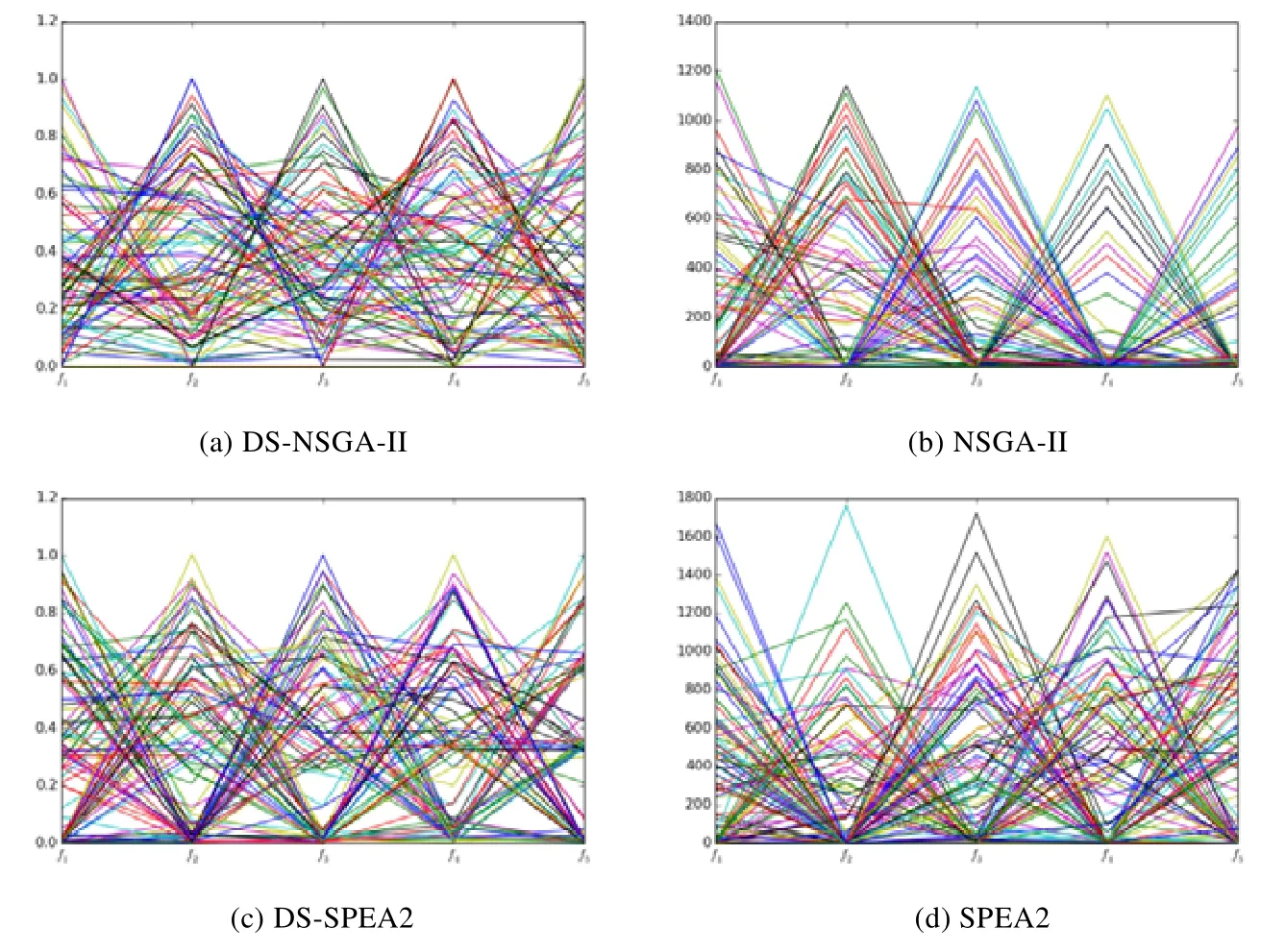
Fig.9 Experimental results of DS-NSGA-II,DS-SPEA2,NSGA-II and SPEA2 on DTLZ3 problem图9 DS-NSGA-II,DS-SPEA2,NSGA-II,SPEA2 在DTLZ3 问题上的实验结果图
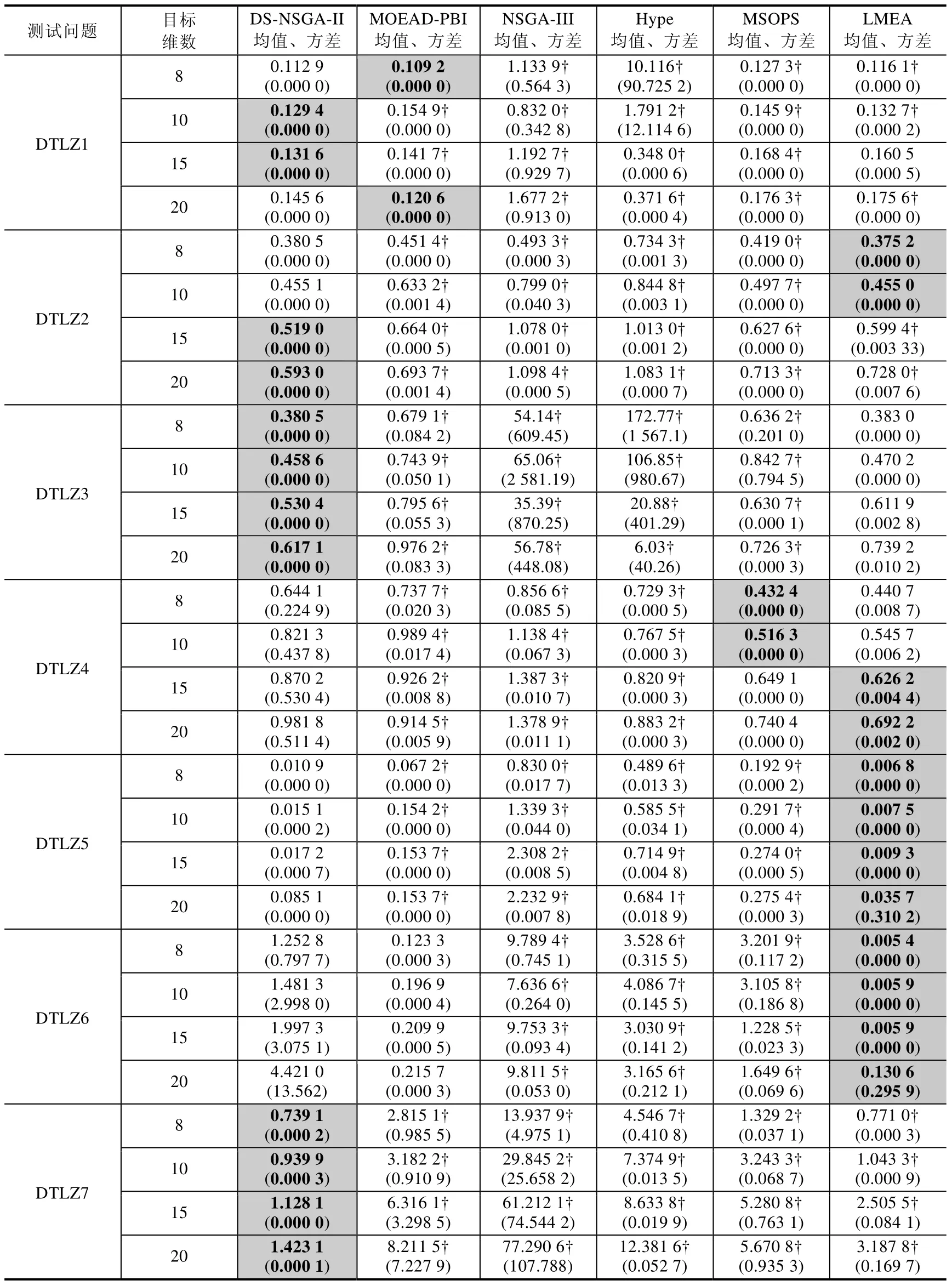
Table 3 Experimental results of DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS and LMEA on DTLZ series test problems表3 DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS,LMEA 在DTLZ 系列测试问题上的实验结果
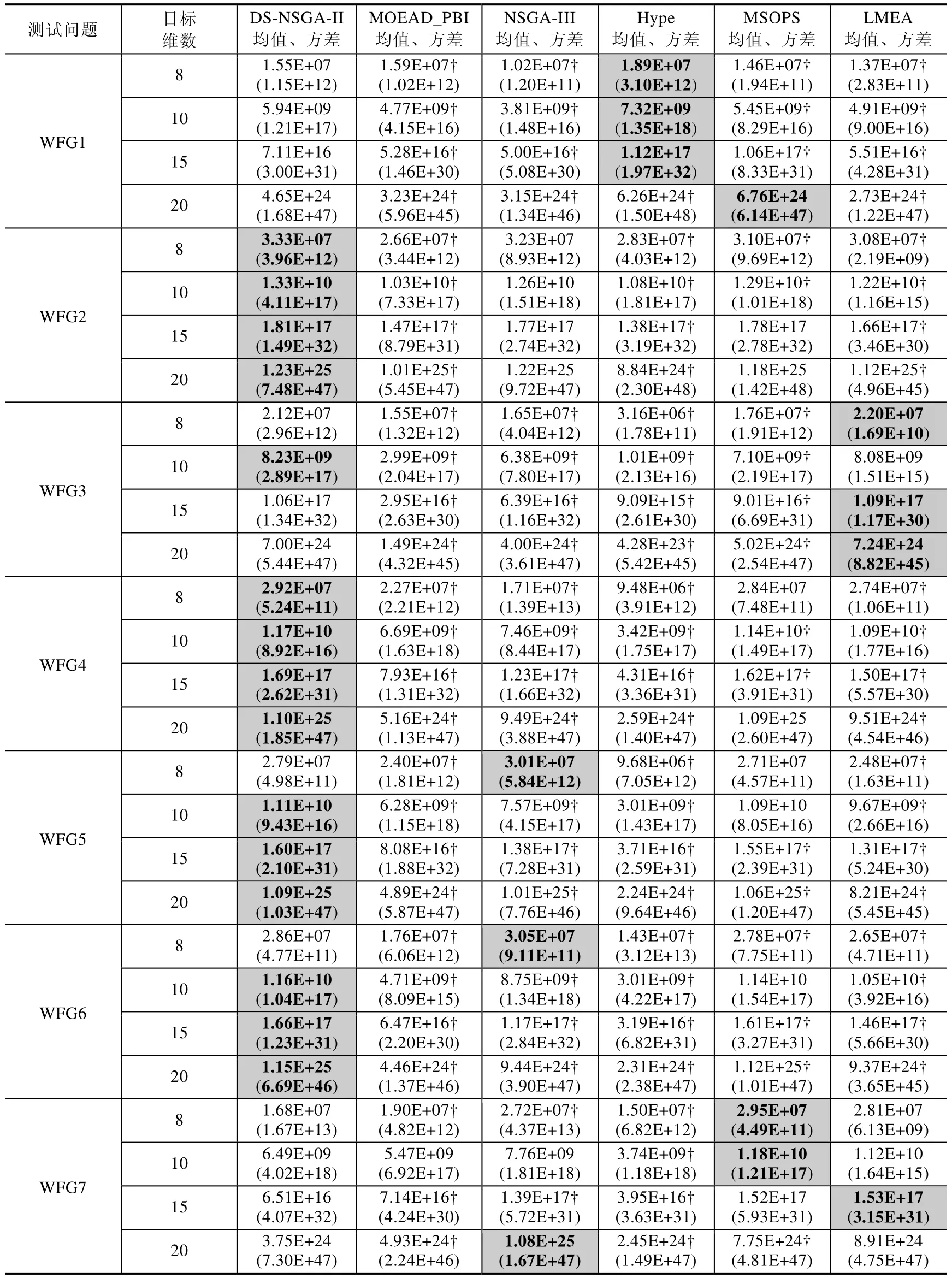
Table 4 Experimental results of DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS and LMEA on WFG series test problems表4 DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS,LMEA 在WFG 系列测试问题上的实验结果
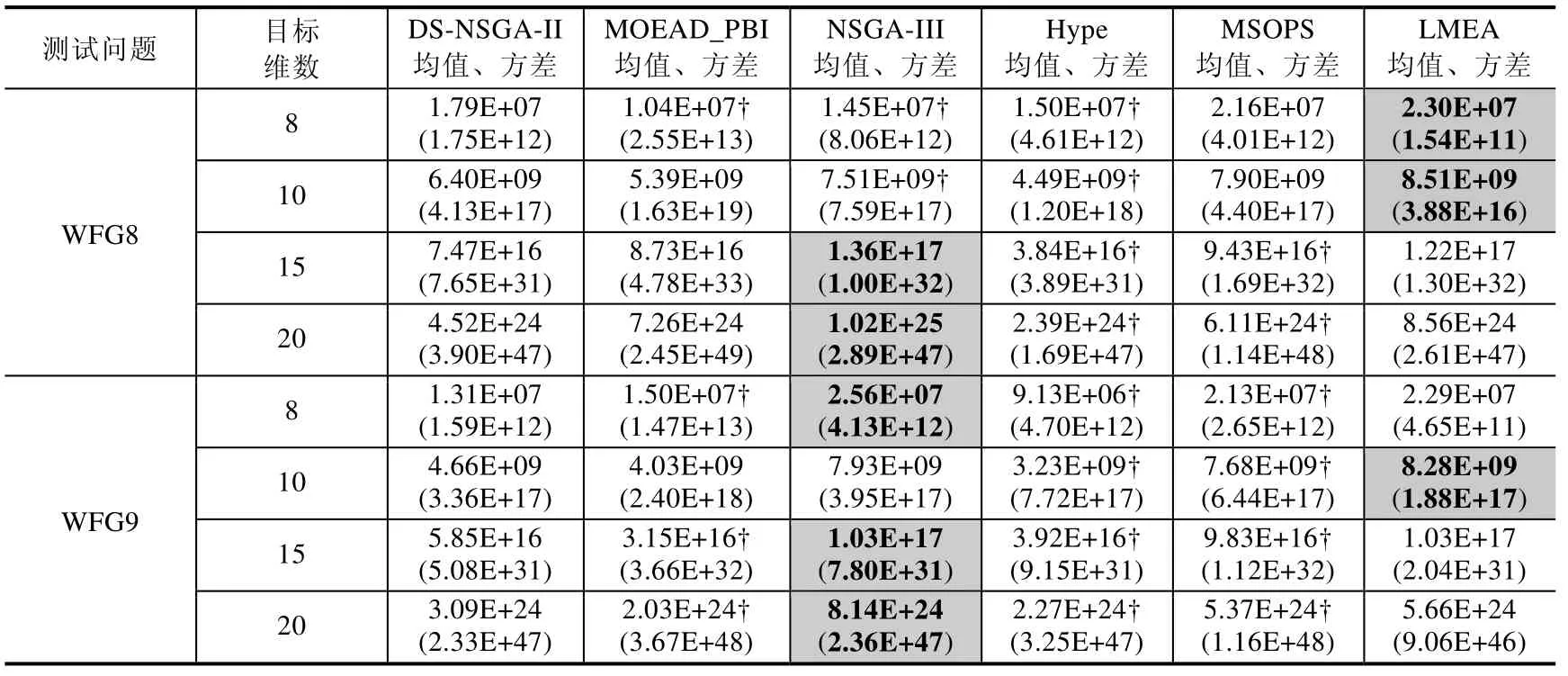
Table 4 Experimental results of DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS and LMEA on WFG series test problems (Continued)表4 DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS,LMEA 在WFG 系列测试问题上的实验结果(续)
从表3 和表4 中我们可以看到,DS-NSGA-II 不论在DTLZ 系列测试问题还是在WFG 系列测试问题上,对大部分的测试问题都具有良好的表现.DTLZ1-3 测试问题中,DS-NSGA-II 大部分情况下不同程度地优于其他算法,LMEA 的IGD值较接近于DS-NSGAII.但总体略差,而在DTLZ5-6 退化的测试问题上,LMEA 表现较好,但是DS-NSGA-II 在这类问题尤其是DTLZ5 上明显优于其他算法.在DTLZ7 不连续的测试问题中,DS-NSGA-II 则优于其他算法.在WFG2,WFG5,WFG6 测试问题上,DS-NSGA-II 表现良好;对于WFG3 问题,LMEA 表现更好一些,但是DS-NSGA-II 与之相比非常接近且明显好于其他算法.
同时,我们也能看到,DS-NSGA-II 在DTLZ 系列中的DTLZ4,DTLZ6 问题上,在WFG 系列中的WFG1,WFG7~WFG9 问题上的性能并不是很好.关于DS-NSGA-II 对大部分测试问题性能良好的原因,在前面小节中已有解释,这里主要分析一下DS-NSGA-II 为何在DTLZ4,DTLZ6,WFG7~WFG9 这些测试问题上表现不佳,主要原因有两个方面:一是本文中问题采样分析的方法较为初始简单,采样分析结果与实际问题可能会有一定的偏差,导致在算法的搜索过程中产生一定偏差;二是NSGA-II 算法的分布性保持机制(聚集距离)本身存在一定的瓶颈.同时,DTLZ4,WFG 问题对算法的保持分布性的能力要求较高.
图10 是6 个算法在15 维的DTLZ3 和WFG3 的实验结果图(左列为DTLZ3,右列为WFG3).
Fig.10 Experimental results of DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS and LMEA on DTLZ3 and WFG3图10 DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS,LMEA 在DTLZ3 和WFG3 上的实验结果图
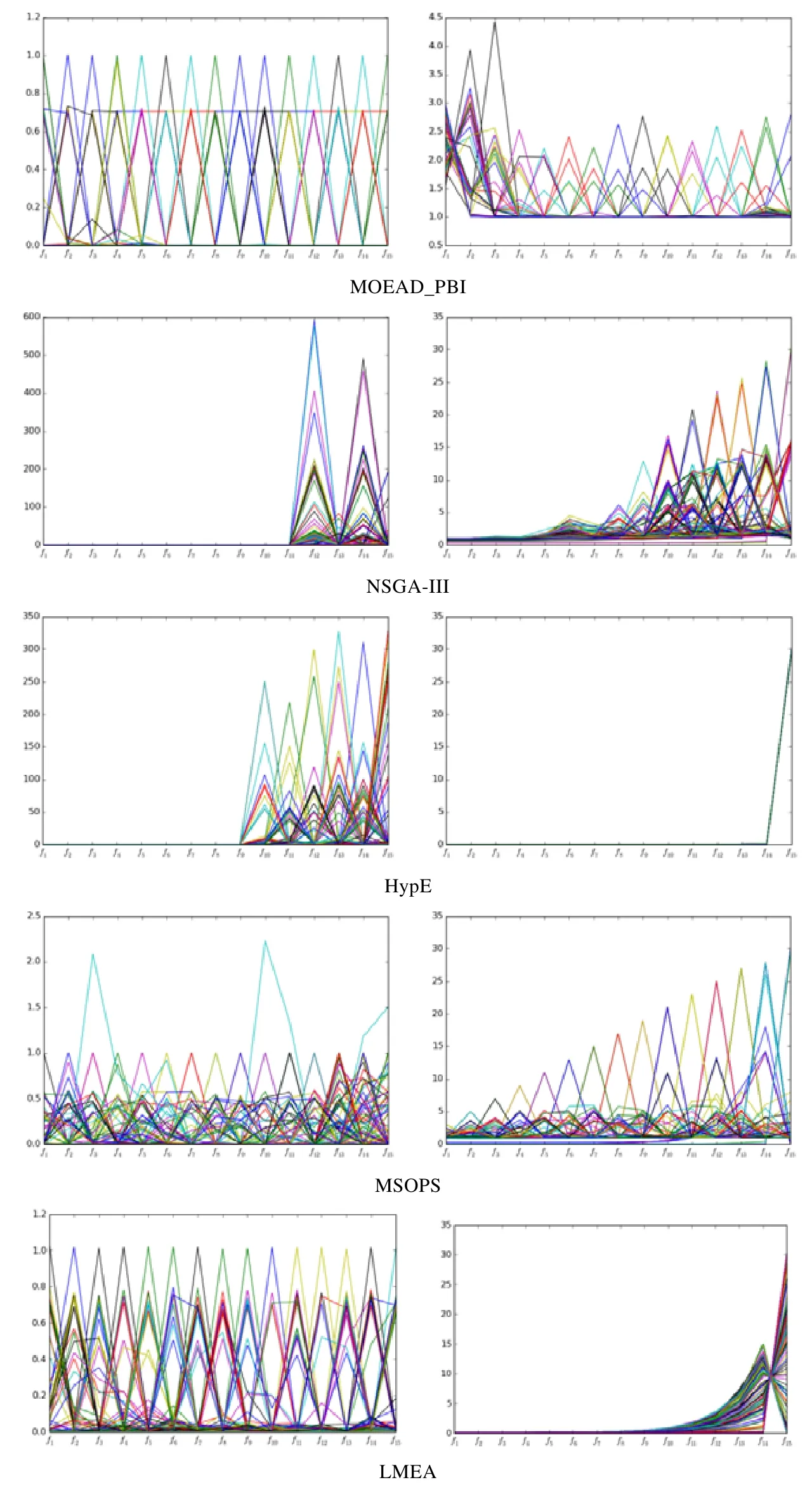
Fig.10 Experimental results of DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS and LMEA on DTLZ3 and WFG3 (Continued)图10 DS-NSGA-II,MOEAD_PBI,NSGA-III,Hype,MSOPS,LMEA 在DTLZ3 和WFG3 上的实验结果图(续)
从图中我们可以看出,NSGA-III 和Hype 在DTLZ3 问题上都不能很好地收敛;DS-NSGA-II,MOEAD-PBI,MSOPS,LMEA 都可以收敛;DS-NSGA-II,LMEA 的分布性较优.
WFG3 是一个退化问题,从图中我们可以看出,Hype 收敛于一点;其他算法甚至都不能收敛;DS-NSGA-II 与LMEA 不仅能很好地收敛到PF 上,而且分布性也较好.
总体而言,从实验结果看,引入DS 策略的算法较之原算法对于连续高维多目标优化问题在性能上有了明显的提高.与当下比较流行经典的一些其他算法相比较,虽然DS-NSGA-II 并不是在高维所有测试的问题上都优于其他方法,但在绝大多数问题上优于其他算法或性能接近.总之,由于DS 策略的引入,使得DS-NSGA-II 与当下较流行的高维多目进化算法相比有了较强的竞争力.
4 总结与展望
本文提出一种基于决策空间的定向搜索策略,通过对优化问题的采样分析,得出决策空间的收敛性控制向量和分布性控制向量,再通过一个或少数几个解,确定收敛性子空间和分布性子空间,一改之前算法同时保持收敛性和分布性的机制,将算法搜索过程分为收敛性搜索阶段和分布性搜索阶段,分别对应收敛性子空间和分布性子空间进行搜索优化.在收敛性搜索阶段,侧重于种群的收敛性,使少数几个解可以快速收敛至真实PF 附近;在分布性搜索阶段,侧重于种群的分布性,利用原算法的分布性保持机制,使种群较均匀广泛地覆盖整个PF,同时也会对算法的收敛性进行微小的优化.
本文具有以下创新性和优点.
(1)根据连续多目标优化问题的特性,对多目标优化提供了新的视角:对种群的收敛性和分布性进行分阶段侧重优化.这样可以很大程度弱化高维多目标问题优化时收敛性和分布性之间的冲突;
(2)提出在种群中个体间的比较是:同分布性个体之间比较收敛性,或同收敛性个体之间比较分布性.这样可以在高维多目标问题优化环境选择时,增加个体的选择压力;
(3)根据对优化问题的采样分析,在算法优化过程中对子代个体的生成有一个宏观的影响,使得搜索的目的性更强.对于高维多目标优化问题搜索能力不足的问题,有目的性地搜索集中了计算资源,避免了在不必要区域进行搜索导致的计算资源浪费.
同时,DS 策略也面临一些问题,如:针对优化问题的采样分析和子空间确定的准确性,很大程度会影响算法的效率和准确性,采用什么样的数学方法进行采样分析,以及是否在搜索过程中对问题进行多次有针对性的采样分析;对于复杂PS 问题的优化,如何准确地确定子空间,以及确定后如何高效恰当地在子空间中生成解等.
这些问题都需要花费时间和精力进一步研究,这也是本人下一步的研究内容.
猜你喜欢
今日农业(2022年15期)2022-09-20
生物学教学(2018年3期)2018-08-08
中学生物学(2018年8期)2018-03-01
小天使·五年级语数英综合(2017年3期)2017-04-25
读写算·小学低年级(2017年1期)2017-02-06
商业经济研究(2016年14期)2016-09-14
科教导刊·电子版(2016年16期)2016-07-18
财经科学(2015年1期)2015-07-02
中学生物学(2008年6期)2008-08-29
