
基于Hough变换的大数据特征集成冲突检测建模研究
2019-10-15 07:44:56胡小琴
太原师范学院学报(自然科学版) 2019年3期
胡小琴
(泉州信息工程学院 软件学院,福建 泉州 362000)
0 引言
随着互联网技术的飞速发展,人们迎来了大数据时代,大数据时代的来临使得数据资料的规模得到巨大的统计与整理,借助大数据相关技术可以实现海量数据的提取、管理与处理等操作.大数据具有存储数据量大、数据种类多、实用性强以及蕴藏价值大等特征,由于大数据独特且多元的特征特点,使得大数据在运行操作过程中可能出现冲突问题[1].当大数据库中的数据存在一定的差异时,就会产生冲突.大数据中的特征集成的冲突指的是不同主体对同一个数据客观对象在空间及属性上的看法的不一致性,这种不一致性使得数据信息产生差异.一般情况下,大数据特征冲突具有必然性、可视性、局限性以及积极性等冲突特点,依据冲突数据的空间特征集成以及冲突产生的原因,可以将冲突划分成为几何冲突和属性冲突两大类,在进行具体的研究与检测过程中需要从这两个方面进行具体的研究.由于大数据库中的数据量较大,一旦出现数据特征冲突,就可能引发数据运行延时、拥塞等问题,严重时可能会引发数据运行瘫痪.因此需要定期对大数据进行检测,以此来保证大数据特征集成运行安全[2].与此同时大数据特征集成冲突检测的结果也可以作为理论依据,从而提出具有针对性的冲突处理方案,实现数据冲突的消除.
现阶段已经存在的冲突检测方法包括:基于空间矢量的数据冲突检测方法、基于编码规则的数据冲突检测方法以及基于函数依赖的数据冲突检测方法等.其中空间矢量方法下的数据冲突检测主要针对数据冲突中的几何冲突进行检测,而基于编码规则和函数依赖的数据冲突检测方法仅仅对于属性冲突具有良好的检测效果.经过长时间的研究发现,传统检测方法在应用过程中具有较大的局限性,且存在检测周期长、检测精度低的问题.为了解决传统方法中存在的问题,引入Hough变换的概念,Hough变换也被称为霍夫变换.霍夫变换是一种特征检测,通常被应用在图像分析或者电脑视觉当中,该变换方法可以精准的检测出待检测物体的特征[3].将这种变换方式应用到检测方法当中,构建检测模型进行优化设计,能够在一定程度上降低检测周期,同时提高检测精度.
1 大数据特征集成冲突检测模型设计
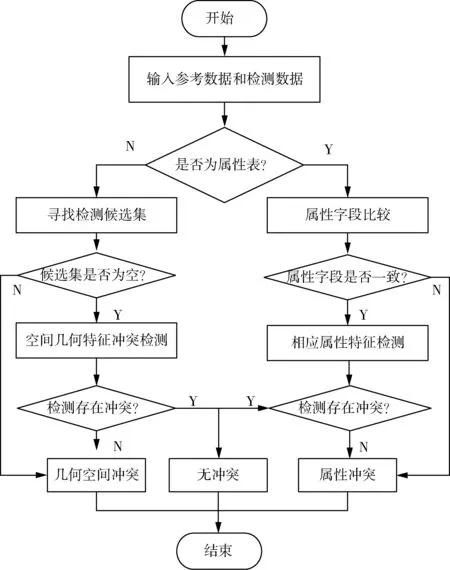
图1 大数据特征集成冲突检测模型构建流程图
1.1 获取初步冲突特征数据
使用大数据特征数据挖掘算法,获取待检测的部分数据库中的特征数据.在特定的检测搜索区域内,选定一个数据节点作为特征数据采集的起点,在数据挖掘采集的过程中以采集起点为中心,逐渐向其邻域扩展进行查询检测,运用所确定的信息优化邻近对象的查询操作,获取初步的冲突特征数据[4].假设数据采集起点为a,每一次数据采集的距离为r.定义一个随机的自然数为k,且定义p的k-距离为(k-distance(p)).计算对象p的k-距离邻域用(Nk-distance)来表示,假设式中k的值为5,则公式1中的关系式成立.
Nk-distance(a)={b,c,d,e,f}.
(1)
公式1中a为冲突特征数据采集的起点,而b-f表示的是采集邻域范围内的冲突特征采集目标数据.在初始采集区域内未被采集的数据对象用集合o表示,接着对公式2中表示的范围进行进一步数据采集.
dist(a,s)≤2·d(a,o)+k-distanace(a).
(2)
将未被采集的数据重新与邻域采集区域结合在一起,对此进行重复查询采集流程,当查询范围内冲突特征数据超过采集阙值时,重复一次操作,最终获取数据冲突中的初步冲突特征数据集.
1.2 量化大数据特征冲突权值
采用去一划分的方法计算采集的冲突特征数据的离群性权值量化,使用信息熵作为数据权值量化的介质.假设获取初步冲突特征数据集为X={x1,x2,…,xn},以集合中的任意一个变量xn为例,假设其取值集合为S(x)[5].那么可以通过公式3计算特征冲突数据的信息熵.
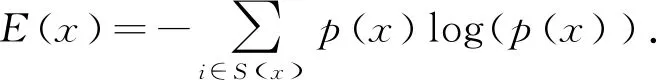
(3)
式中函数p(x)代表任意变量xn的几率函数.计算连续数据变量的信息熵,利用相邻变量计算出的信息熵得出信息熵增量的结果[6].以信息熵增量为依据将取值集合为S(x)划分为两个区域,并以公式4的方式进行记录.
(4)
对两个划分区域的信息熵进行计算,并相减得出信息熵的增量Δx.将大数据冲突数据的属性看做一个集合,用Δx对集合中对象的属性权值做详细的量化.权值量化公式如公式5所示.
1.1 背景资料 试题的题干: 水稻是我国最重要的粮食作物。稻瘟病是由稻瘟病菌(Mp)侵染水稻引起的病害,严重危害粮食生产安全。与使用农药相比,抗稻瘟病基因的利用是控制稻瘟病更加有效、安全和经济的措施。
(5)
式中f(p)与f(q)表示的是第i维属性的值,p与q是集合S中的任意一个数据,d(p,q)表示属性的加权距离.通过公式得到归一化处置完成的权值量化结果.
1.3 实现大数据特征集成
按照量化的大数据特征冲突权值,对采集的初始冲突特征采集数据进行特征集成,特征集成过程如图2所示.
按照图中的特征集成流程,通过限定数据特征序列、特征表达以及Hough变换处理三个步骤实现数据特征集成,且经过Hough变换处理后,可以确保集成的数据具有较高的特征精度[7].
1.3.1 选定大数据特征序列
参考量化后的特征冲突权值,选定大数据的特征序列,选定的过程如图3所示.
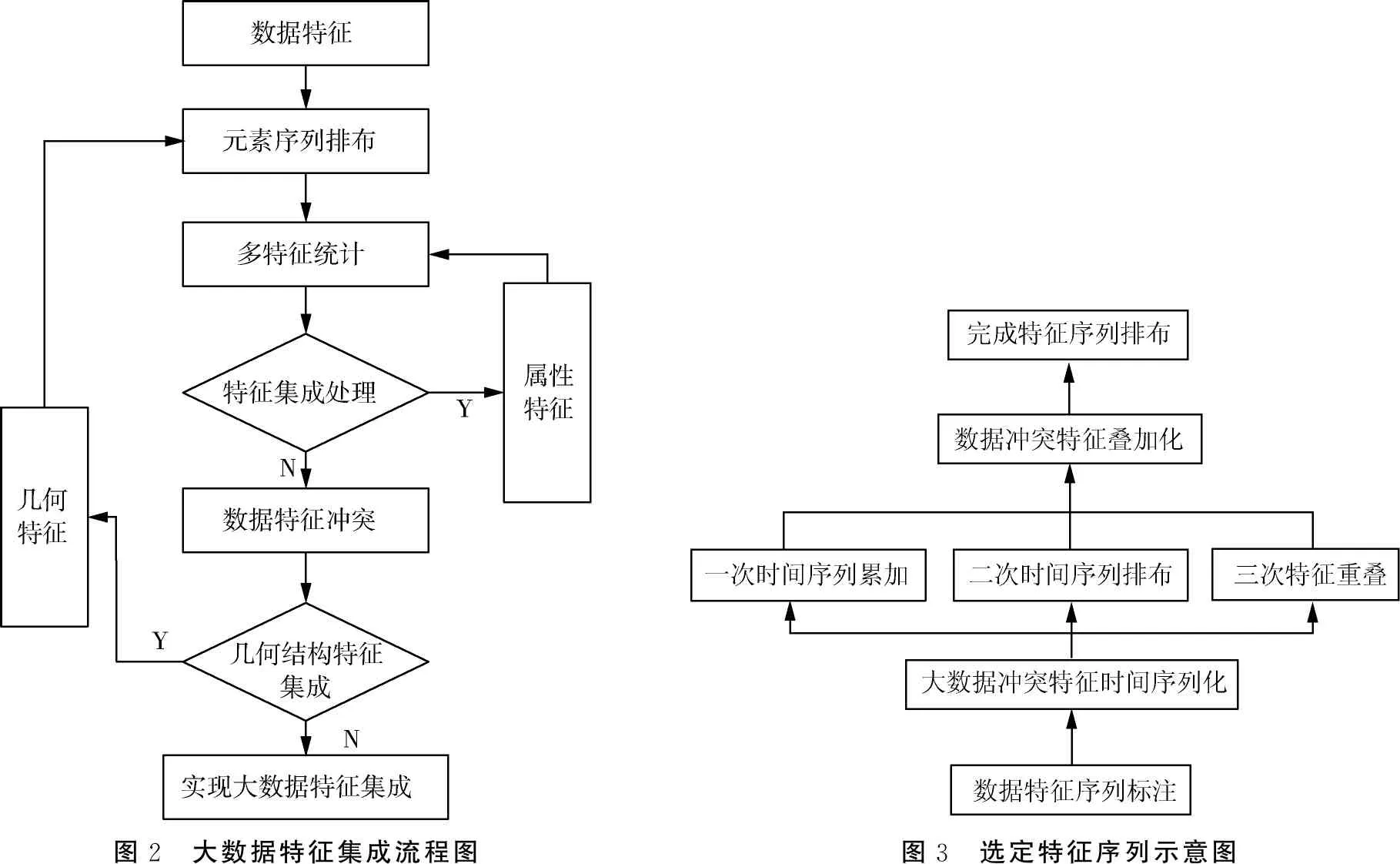
图2 大数据特征集成流程图图3 选定特征序列示意图
由于大数据中数据的复杂度较高会影响特征表达结果,选定大数据特征序列的过程中,首先按照量化的权值进行特征跟踪,根据特征的跟踪结果对其他普通数据进行特征忽略,突变特征进行集中时间性排列[8].分别进行两次特征特征跟踪与排列,最终将多个特征选定结果重叠在一起,最终在不发生插入序列的情况下,以定式序列为大数据的特征序列.
1.3.2 大数据特征表达
在选定特征序列的阶段下完成大数据多特征的表达,通过提取方式获得大数据冲突特征的基本表达元素.数据特征表达分为两个步骤,首先进行大数据的全局特征表达,接着进行大数据的局部特征表达[9].在全局特征表达的过程中,对整个待测数据进行特征计算与提取,而针对局部特征表达的过程仅需要反馈全局特征中的部分特征,进而进行统一表达.
1.3.3 特征数据Hough变换处理
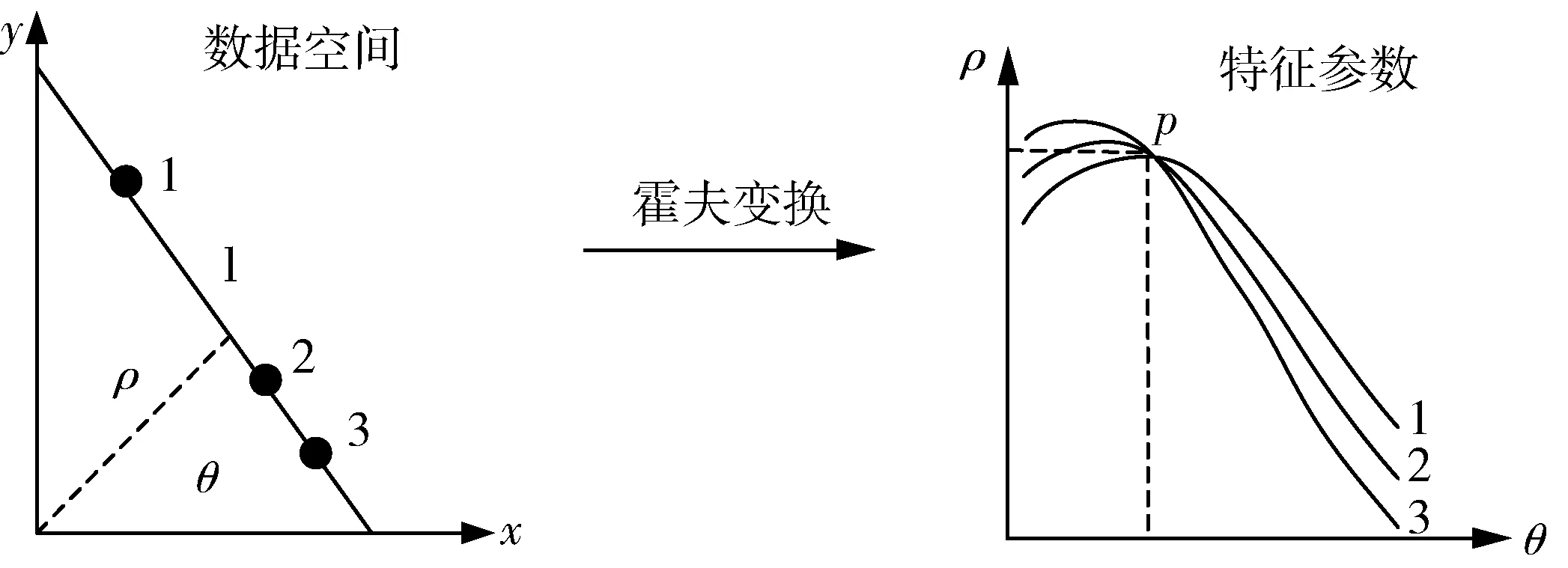
图4 直线检测中的Hough变换示意图
将大数据特征表达结果集中在一起实现数据特征集成,然而在输出数据特征集成结果之前,需要对特征数据进行Hough变换处理,以此来提高数据特征集成冲突的检测精度.基本检测中的Hough变换处理情况如图4所示.
在标准参数化方式下,大数据空间中的直线特征l的表达式为:
ρ=xcosθ-ysinθ,ρ≥0,0≤θ<π.
(6)
式中ρ表示的是直线特征l相对于数据采集起点的距离,θ表示的是直线特征l与横向正方向上的交角[10].在大数据参数空间中,针对直线特征的检测中,使用标准Hough变换可以表示为:
(7)
按照公式7中的表达式,若能确定参数空间中的起始点,将起始点的坐标代入到公式7当中,便可以实现直线特征的检测.
1.4 配置冲突判断规则
大数据特征集成冲突检测的关键在于大数据冲突判断规则的确定,由现实大数据特征集成描述关系确定大数据与特征之间的关系集合,形成大数据特征对象间的判断规则,用公式8来表示.
RAB={TR,SR,AR}.
(8)
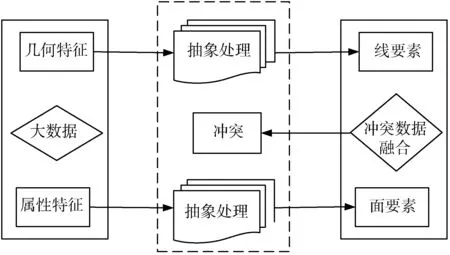
图5 冲突判断示意图
式中的集合元素分别表示的是大数据与特征集成之间的结构约束集、关系约束集以及语义关系约束集.从公式8中的表达式来看,结构约束集的规则是相对明确的,根据实际情况来确定对象间的合理与不合理的关系,从而确定冲突是否存在[11].根据数据与特征集成之间的关系产生的冲突判断流程,如图5所示.
根据大数据特征集成的冲突判断待检测大数据库中存在冲突,则可以进行进一步的冲突分类处理.
1.5 输出冲突检测结果
大数据特征集成冲突大致可以分为,几何空间特征冲突和属性特征冲突两种,其中几何空间特征冲突主要指的是空间实体重要的特征冲突,进行空间数据间的几何冲突检测,需要对目标对象的几何特征做出定量和定性分析,并通过合理的方式进行具体描述.在对空间要素点、线、面分析的基础上,确定了对象间的空间关系的组合,如表1所示.
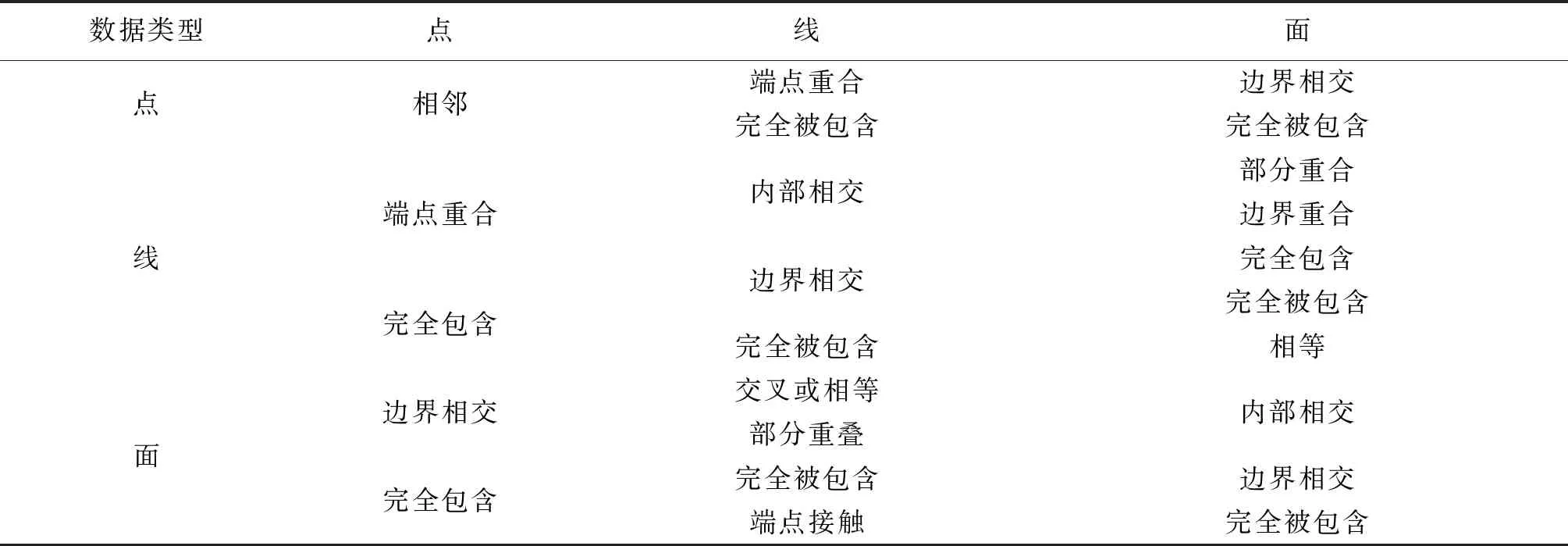
表1 几何空间特征冲突关系
在对矢量数据自身拓扑逻辑正确性判定的基础上对空间冲突关系、语义关系的进一步判定可以确定数据冲突的存在性[12].属性特征用于对现实事物或现象的描述决定了不同数据源对相同实体对象某种属性的描述可能相同、相近或有差异.按照两种冲突的定义实现大数据特征集成的冲突分类.
在大数据特征集成冲突分类处理完成后,从几何冲突和属性冲突两个方面进行冲突检测.在冲突检测中,两种冲突检测相结合按照一定的顺序进行不同数据特征机场的冲突检测,具体的检测过程如图6所示.
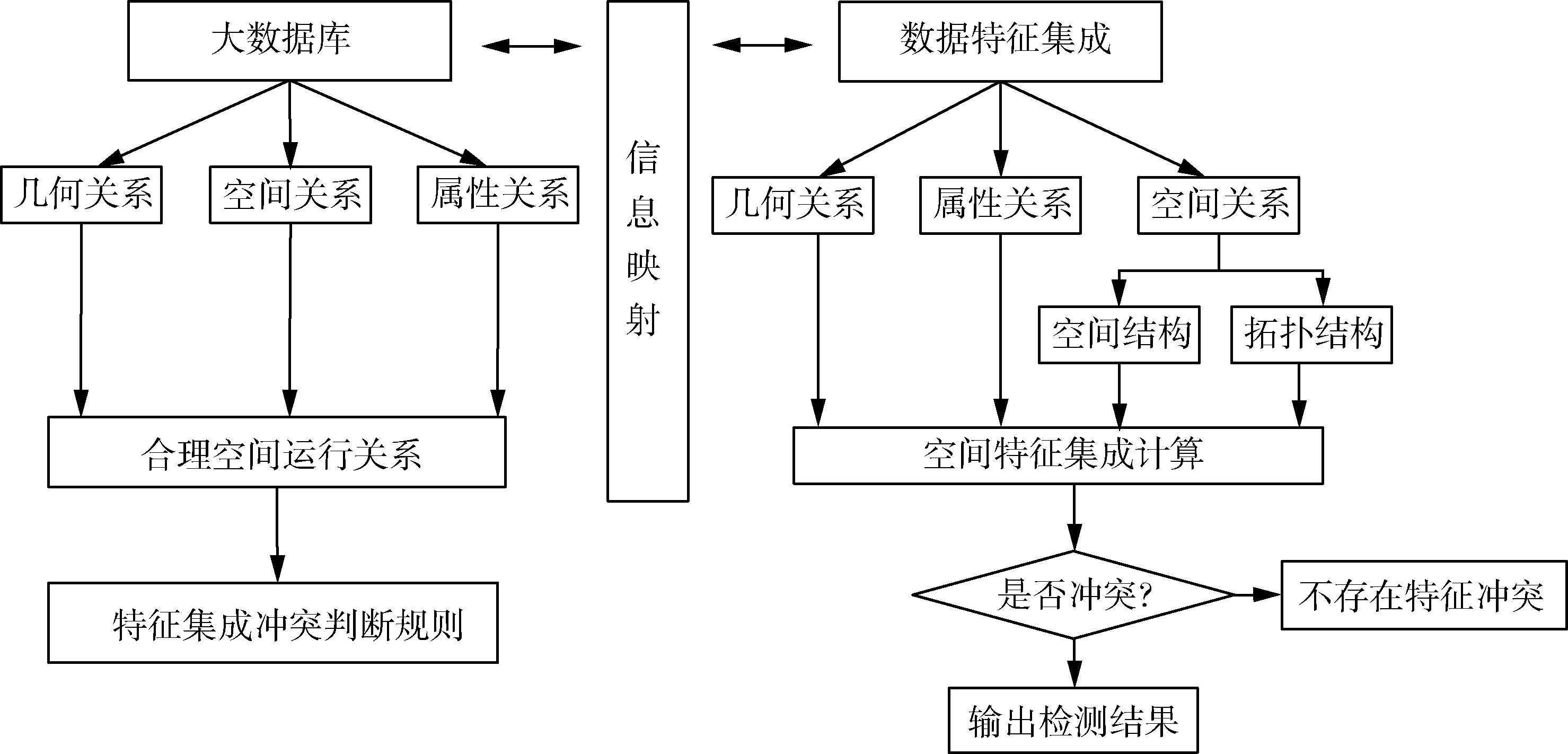
图6 大数据特征检测模型
按照图中的检测模型的流程,根据输入的数据判断数据类型,以不同的特征集成检测方法.接着将其进行相似度的计算与比较,确认冲突类型输出检测结果.
2 对比实验分析
为了验证设计的大数据特征集成冲突检测模型的有效性,设计对比实验.在实验中针对大数据特征集成冲突检测的召回率和检测准确率作为实验的对比参数,以此来判断检测模型的性能.
2.1 实验环境及数据来源
此次对比实验的实验环境选择操作系统为Windows 7,Intel core i7 6700CPU,ROM内存为8GB,且4核心8线程、3.4GHZ主频的PC机作为对比实验的主要实验环境.选择的实验对象来自于中国电子信息数据库中编号A00-B12区间内的数据,总数据量为2 GB.
2.2 对比实验过程
为了避免大数据特征集成冲突的偶然性影响实验结果,在对比实验中设置四次冲突检测,每一次的检测方法相同.对四次冲突检测的结果取平均值,作为实验的最终结果.为凸显设计检测模型的性能,在对比实验中设置传统的冲突检测模型作为实验的对比模型,两种模型针对相同的实验对象数据进行检测和分析,在检测过程中除了使用的检测方法不同外,其他的参数数据均相同.对比实验启动后,首先向数据库发布存储以及调用的指令,使得数据库可以正常的进行日常运作,在大数据库运行过程中将两种检测方法同时应用到数据库当中.由于数据库中的数据相同,发布的任务指令也相同,因此两种检测模型中产生的特征集成冲突也相同.设定两个模型的检测时间相同,在检测终止后,输出对应的检测结果数据,进行对比分析.
2.3 实验结果分析
经过对比实验步骤得出两种冲突检测模型的检测结果,对检测结果进行统计与对比,得出实验对比结果如表2所示.
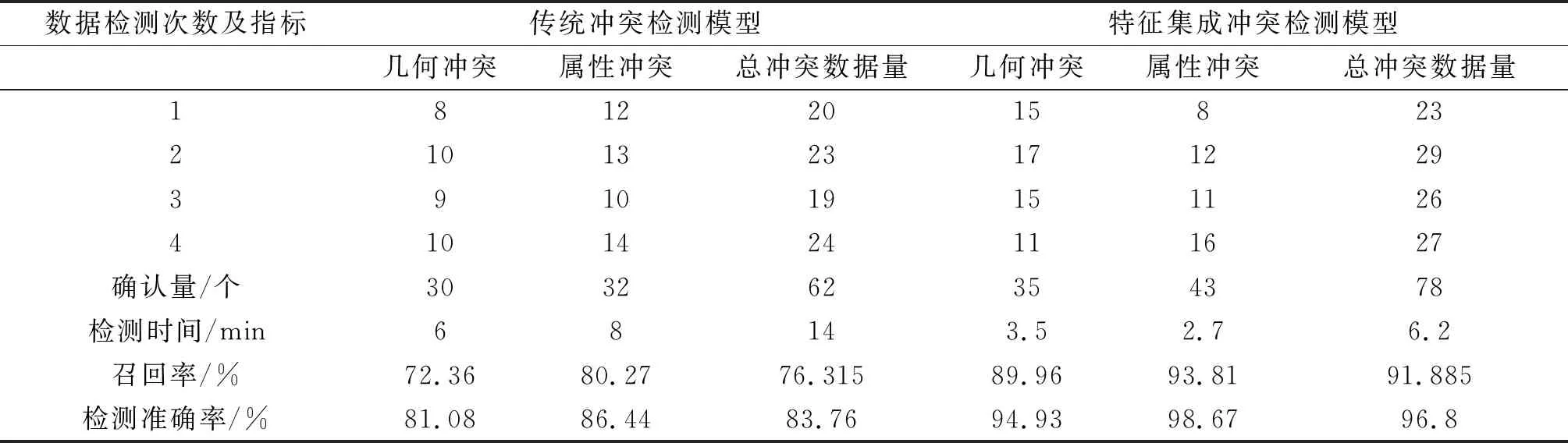
表2 实验结果数据对比
表2中的实验对比结果表明,两种冲突检测模型的平均检测准确率均在80%以上,具有较高的应用价值.在检测时间方面,设计的特征集成冲突检测模型的平均检测时间为3.1 min,比传统检测模型节省3.9 min.在检测准确率方面,比传统检测模型的平均准确率提升了13.04%.
3 结束语
在大数据特征集成冲突检测模型中引入Hough变换算法,在提升检测准确率的同时,也加快检测的速度.将该检测模型应用到实际的大数据研究工作当中,也可以起到一定程度的积极作用.但是设计完成的大数据特征集成冲突检测模型尚未对检测出来的冲突进行有效的处理,针对这一方面还等待进一步研究.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
电子测试(2017年12期)2017-12-18 06:35:48
科教导刊·电子版(2017年22期)2017-09-20 11:03:18
电脑知识与技术(2017年12期)2017-07-29 15:51:25
科技与创新(2017年8期)2017-06-07 20:40:47
自动化学报(2017年7期)2017-04-18 13:41:02
雷达学报(2017年6期)2017-03-26 07:52:58
池州学院学报(2015年3期)2016-01-05 01:13:00
