
神经网络机器翻译之语境式学习
2019-10-15 07:44杨寅冬
太原师范学院学报(自然科学版) 2019年3期
杨寅冬,姚 洁
(1.安徽邮电职业技术学院 计算机系,安徽 合肥 230031;2.安徽邮电职业技术学院公共基础部,安徽 合肥 230031)
0 引言
尽管神经网络机器翻译在学术界和工业界迅速普及,并且在该领域最近取得一定的成功,但人们发现神经网络机器翻译在很大程度上无法利用除当前源语句之外的其他语境信息,这是因为大语境机器翻译系统往往忽略附加语境信息,例如先前的语句、相关图像.最近所开展的大量研究致力于构建一种可以更好地利用附加语境信息的新网络架构,但是收效甚微.
在本文中,我们从“学习”的角度来解决大语境神经网络机器翻译问题.通过向与语境正确配对的翻译(而不是与语境错误匹配的翻译)赋予更大的对数概率,使模型更好地利用附加语境信息.
通过设计,我们将该正则项应用于标注、语句和批层次中,使用改良版转换器,对文档级翻译进行实验.实验结果表明,与之前的实验结果不同,经过本文提出的学习算法训练的模型确实对该语境敏感,并且在整体质量方面略有改善(单位BLEU).这些结论表明,本文所述的学习方法在构建一种有效的大语境神经翻译模型方面是一种具有发展前景的方法.
1 大语境神经网络机器翻译背景
大语境神经网络机器翻译系统是在传统神经网络机器翻译系统的基础上发展起来的,它将某语句翻译成目标语言的Y语句时,大语境神经网络机器翻译系统除了考虑源语句X之外,还考虑了语境C[1].在多模式机器翻译的情况中,附加语境信息是指源语句X所描述的图像.在文档级机器翻译的情况中,附加语境信息C可以包括包含源语句X的文档中的其他句子.这种大语境神经网络机器翻译系统由编码器器fC组成,编码器fC将附加语境信息C编码成一组向量表示,这些向量表示又与原始编码器fX中从源语句X中提取的那些语句组合在一起.然后,解码器g使用这些向量,来计算自回归范例中靶序列Y的条件分布,即:
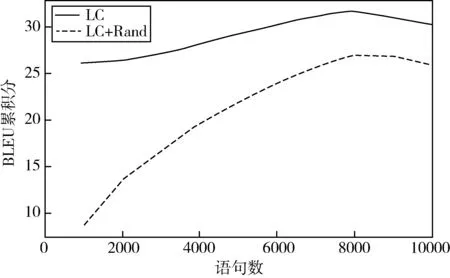
Pθ(yt|y 其中θ是神经网络翻译模型中所有参数的集合.f(C)和g通常是指神经网络,例如视觉注意力的循环神经网络、卷积神经网络和自我注意神经网络[2-4]. 在给定一组训练三元组D(tr)=x(tr)*y(tr)*c(tr)={(X1,Y1,C1),…,(XN,YN,CN)}情况下,通常过最大化对数似然,来完成训练.对数似然定义为 (1) 在本文中,我们关注的是“学习”而不是网络架构.我们的目标是提出一种可以与任何潜在的大语境神经网络机器翻译系统一起配套使用的学习算法,而不是提出一种可以扩大翻译范围的新架构[5]. 为了实现这点,首先要注意,根据总概率定律, pθ(yt|y (2) 因此,在给定源X的条件下,在整个语境C中,附加语境信息总体上是“中性的”. 尽管这些“中性”“有用”和“有害”的语境是在标注级别定义的,但我们可以通过定义以下计分函数,轻松地对它们进行扩展,直至覆盖所有级别: (data)sdata(yt|·)=∑Y∈Yssent(Y|·) . 通过使用从三个不同级别进行定义的分数,我们正则化学习算法,以便神经翻译系统优先以有用的方式使用语境.正则项适用于所有三个级别:标注、语句和整个数据,并且基于相似度损失: (3) 其中,αd,αs和αT是数据 、语句和标志级别的正则化强度.δd、δs和δT是对应的边际值. 本文所述出的正则项明确表明了所有级别的附加语境的有用性.我们使用相似度损失,使模型产生轻微偏差,以便以有用的方式使用语境,但这不一定使模型必须完全依赖语境.这是因为大多数必要信息已经包含在源X里,附加语境C仅只需提供一些补充信息. 当根据方程式(2)上下文丢失时,计算分数并非易事,因为它需要(1)访问p(C|X);(2)边缘化所有可能存在的C,而这个是比较难以处理的.在本文中,通过使用语句pdata(C)的数据分布,我们得出了求得p(C|X)近似值的最简单方法. 假设语境C独立于源X,即p(C|X)=p(C),并且语境C遵循数据分布,则通过随机统一选择M训练语境,来得出近似估计值: 其中Cm是第m个样本. 我们当然可以更有效地估计p(C|X)的值.一种方法是使用Wang和Cho(2016)所述的大语境循环语言模型[6].另一种可能的方法是使用现有的检索引擎来构建非参数采样器,我们会在后续文章中讨论该点. 图1 基于大语境模型且按语句得分差异排序的测试集BLEU累积分 “中性”“有用”和“有害”语境的条件也可作为构建大语境神经机器翻译系统固有的评价指标的基础.对于一个充分训练的大语境翻译系统来说 ΔDθ=s(y|x,c;θ)-s(y|x,θ)>0 实验数据使用Open- Subtitles2018 En→Ru并行数据, 从2M的实例中选择相同的数据子集,使用32k合并操作,在源语言和目标之间建立BPE子字标注词汇表. 实验模型与构建基础转换器的大语境转换所提出的系统类似,该系统将当前和之前的语句作为输入项.每一个当前和之前的语句由一个通用的6层转换器编码器独立编码[9].通过参考之前语句中标注的最终表示并以非线性的方式组合当前和之前语句的输出项,来获得当前语句中每个标注的最终表示.使用标准转换器的同一个解码器,并共享矩阵内的所有字词. 使用初始步长为10-4的Adam来训练每个模型.使用贪婪解码[10-11],每半个阶段评估模型一次,并且当开发时的BLEU得分在连续五次评估后均未得到改善时,将学习速率减半.基于初步实验期间测试集的BLEU分数,令正则项(3)的系数和差值为aT=ad=1,as=0,δT=δs=0和δd=log(1.1).模型以5的光束尺寸进行评估,根据长度调整分数. 表1 报告语境(经边缘化处理)正确配对和错误配对的BLEU分数 取三个随机语境(经过边缘化处理)的BLEU分数平均值.测试集的BLEU分数用括号显示.f通过定某个随机语境,而不是忽略某个语境,使参数与大语境模型相匹配. 图1对比了正确配对(LC)和错误配对(LC+Rand)语句的翻译质量(单位BLEU).根据差值ssent(Y|X,C)-ssent(Y|X)对测试集中的语句进行排序,并报告BLEU累积分[12].对于那些被大语境模型认为可以结合其他语境进行翻译的语句,这种分数差距更大.该分数差距(使用参考翻译)与实际翻译质量之间得到匹配,从而进一步论证了本文所述方法的有效性. 通过使用多级成对排序损失,本文所议的新正则项可以推动大语境机器翻译模型将附加语境信息纳入考虑范畴.经验评估结果表明,使用本文所述的方法训练的大语境翻译模型确实对附加语境信息变得更加敏感,并且优于上下文无关的基准模型.我们认为该项研究是令人振奋的第一步,从而开发出适用于大语境模型的更好的语境式学习算法.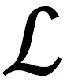
2 学习利用语境
2.1 中性、有用和有害的语境

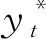
2.2 语境正则化
2.3 上下文无关的分数估计
2.4 固有的评价指标
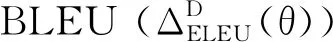
3 实验环境和参数设置

4 实验评估和结果分析
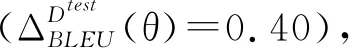
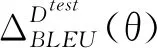
5 结束语
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29怀化学院学报(2021年5期)2021-12-01兰州理工大学学报(2021年3期)2021-07-05兰州理工大学学报(2021年3期)2021-07-05科学技术创新(2021年5期)2021-03-17
——编码器演艺科技(2020年7期)2020-08-13新世纪智能(语文备考)(2020年4期)2020-07-25上海师范大学学报·自然科学版(2018年3期)2018-05-14探测与控制学报(2015年4期)2015-12-15小学生·多元智能大王(2014年6期)2014-07-09
