
一种低功耗高效率CNN 加速器设计和实现
2019-10-15 07:17:50廖裕民
现代计算机 2019年24期
廖裕民
(福州瑞芯微电子有限公司,福州350003)
0 引言
随着深度学习的快速发展与应用[1-2],卷积神经网络(Convolutional Neural Network,CNN)正在被越来越广泛的使用,特别是在图像识别和分类场景中获得了巨大的突破性进展。CNN 由于拥有多层的神经网络结构,其自身有很强的学习和并行处理特点[3],是一种拥有多层感知,局部连接和权值共享的网络结构[4],所以最终可以达到较低的网络模型复杂性和较少的网络连接权值个数,因此近年来,越来越多的CNN 正在被图像内容分析[5-6]、内容识别[7-8]等领域得到了广泛的应用。但是随着CNN 的逐步广泛应用,其海量的运算能力需求与当前硬件运算能力的矛盾越来越突出。在现阶段实现卷积神经网络主要还是使用消费级的通用处理器CPU 或者GPU 来实现,其运算效率较低且能耗非常高,因此这还远远不能满足卷积神经网络运算对速度和低能耗的需求。
同时,由于便携电子设备的普及,神经网络运算对便携化的需求也非常强烈,但是便携设备对功耗和工作效率要求非常高[9-10],所以我们提出了这个通用低功耗高效率的CNN 加速电路结构,对可重构和工作效率和功耗都做了针对性的优化设计,以到达到便携设备的要求。
本文提出的加速电路具备以下特点:
(1)通过可重构性设计方法,让电路可以兼容多种神经网络结构和算法,使得这套电路不仅可以完全实现前面提到的多种神经网络图像算法,还可以对将来的算法升级有良好的适应性。
(2)通过双配置寄存器组设计,减少模块的空闲时间,从而提高模块的利用率。
(3)通过利用图像卷积运算中数据稀疏性的特点做了针对性的低功耗设计,使得该加速电路可以运行在较低功耗水平,以适应移动手持设备的需求。
1 总体电路结构
整体的电路结构由以下几个部分构成:主存储器、CPU、取数控制模块、卷积运算模块、激活运算模块、池化运算模块、写数控制模块,以及每个运算模块都带有一个直通单元和寄存器通路选择单元。
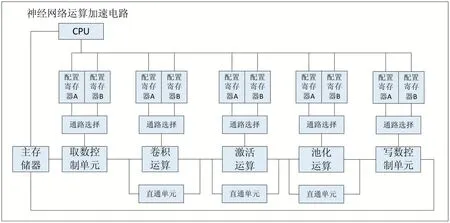
图1 电路总结构
神经网络运算加速电路的连接结构和工作流程如下:
运算加速电路由于采用可重构性的设计结构,将神经网络电路算法拆分为多个小的运算加速模块单元,通过通路配置使其可以适配各种不同的网络结构。因此该运算加速芯片可以完成各种深度学习神经网络处理中所需的图像边沿分割和内容分类等多个算法加速运算。
神经网络运算加速电路包括:主存储器、CPU、取数控制模块、卷积运算模块、激活运算模块、池化运算模块、写数控制模块,以及每个运算模块都带有一个直通单元和寄存器通路选择单元的设计。
其中,除了读写控制两个模块之外,中间的每个模块都有一个直通单元,直通单元负责根据配置将数据流跳过对应模块直接到达下一个运算模块,以实现不同的网络结构。
在电路的工作前需要先完成算法的神经网络结构训练以产生完整的网络结构和所有的网络参数,然后将网络结构和网络参数存入主存储器中,以便运算加速芯片进行加速运算。当所有网络结果和参数存入主存储器后,整个电路可以开始正常工作。
主存储器存储了网络结构和网络参数,包括网络层数量,每层网络卷积核个数、宽度、高度、通道数、卷积步长、PADDING 大小、卷积核数值、激活函数类型、池化大小参数等。同时主存储器还负责存储网络层间的中间运算结果。
CPU 在电路开始工作后,从主存储器中读取出网络结构参数对各个模块的配置寄存器进行配置控制,根据网络结构选择需要的模块,将不需要的模块通过配置该模块的直通单元有效而使其被绕过。
在CPU 配置完成后,取数控制单元,根据配置寄存器信息对存储器进行特征数据和卷积核数据的读取操作,并把读取数据送往卷积运算模块。
卷积运算模块:对特征数据和卷积核进行神经网络的卷积运算和反卷积运算,该电路在设计时充分考虑了图像卷积运算中数据稀疏性的特点做了针对性的低功耗设计,使得该加速电路可以运行在较低功耗水平。具体结构后面有详述。
激活运算模块:可以进行神经网络的激活函数运算,支持ReLU、PReLU、sigmoid 激活函数。
反池化模块:可以进行反卷积运算,将结果送往池化运算模块。
池化运算模块:可以完成神经网络的池化运算,将池化运算结果送往写数控制模块。
2 双寄存器组配置结构
为了提高整个神经网络加速运算的工作效率,减少网络层之间的运算时间间隔,我们设计了一种双寄存器组结构,该结构为每个运算模块都设计了AB 两组配置寄存器和一个寄存器选通控制单元,分别可以存储两层网络的配置。
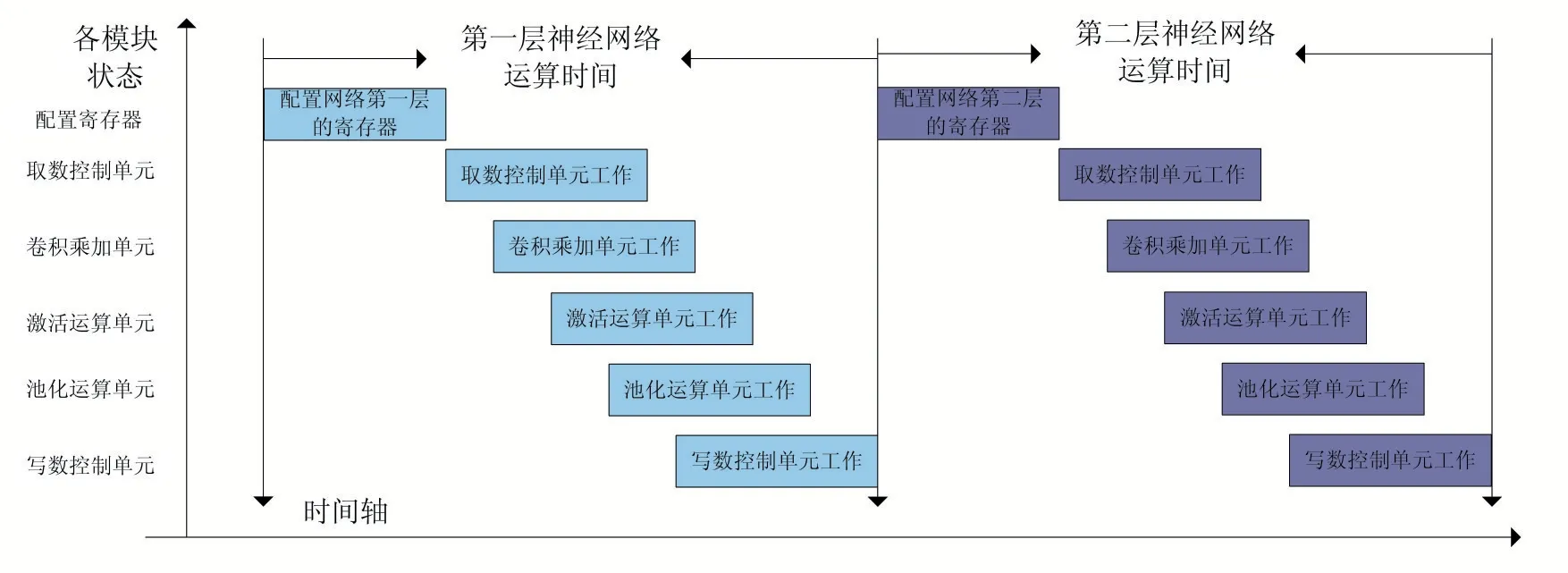
图2 正常NN 加速电路工作流程
图2 是正常情况下的神经网络加速运算流程,下一层的运算依赖于前一层运算的全部结束,可以看到每个模块实际工作中都会存在大量的空闲。
为了解决这个问题,提升加速电路的工作效率,减少电路的空闲时间,我们为每个运算模块都设计了AB两组配置寄存器和一个寄存器选通控制单元,使得各个模块工作时不再依赖于前一网络层运算完毕,而是自己模块完成当前层的运算后可以立即切换到下一层的运算,达到图3 中的工作效果。
双寄存器组的具体工作方式:
(1)在加速电路开始工作前,CPU 先将前两层网络的配置分别配置到每个模块的配置寄存器A 和配置寄存器B。然后加速电路可以开始工作,工作开始后首先使用配置寄存器A 中的配置进行第一层网络的工作。
(2)当第一个模块完成当前层的工作后,将本层工作完成信号送往本模块的寄存器选通控制单元和CPU,然后本模块的寄存器选通控制单元立刻将该模块的寄存器改为寄存器B 也就是下一个网络层的配置,该模块可以立刻进入下一层的工作处理。同时,CPU 在收到该模块的本层工作完成信号后,对寄存器A 中的配置进行配置更新,更新为第三层网络的配置。
(3)当模块完成第二层网络的运算工作后,同样的将本层工作完成信号送往本模块的寄存器选通控制单元和CPU,然后本模块的寄存器选通控制单元立刻将该模块的寄存器改为寄存器A 也就是第三层网络的配置,该模块可以立刻进入第三层的工作处理。同时,CPU 在收到该模块的本层工作完成信号后,对寄存器B 中的配置进行配置更新,更新为第四层网络的配置。
(4)每个模块都遵照上面所述的顺序进行工作,不依赖于整层网络运算结束后整体切换到下一层进行工作,实现了完全流水作业,大幅减少了各模块的空闲状态时间,从而提升了的电路工作效率。

图3 双寄存器组电路工作流程
3 低功耗卷积运算电路结构
由于大量的神经网络运算图像具有稀疏性的特点。因此我们针对待运算图像中出现的数据稀疏性矩阵运算特点,设计了针对性的功耗优化和运算电路。该电路可以有效地降低卷积神经网络电路运算过程中的运算数量和运算过程中消耗的功耗。
卷积层是所有神经网络运算中最重要也随耗费硬件资源和功耗的部分,卷积运算的计算公式如下:
Fi=σ(Wc(i)*Fi-1+bi).
其中,Fi表示第i 卷积层的卷积结果,Fi-1表示第i-1 卷积层的卷积结果,Wc(i)表示第i 卷积层的权值,符号“*”表示卷积运算,bi表示第i 卷积层的偏置,σ表示激活函数运算。
针对图像的稀疏性,本文提出的针对性优化的卷积运算电路结构如图4。
在乘加阵列的设计上,将32 个乘加器划分为4 个时钟组,每个时钟组包含相同数量的8 个乘加器单元。然后通过对待运算的特征数据和卷积核数据进行非零判断,如果特征数据或者卷积核数据值任意一个为零则表示该次运算的结果必然为零,因此只对该次运算的位置进行标记而不做乘加运算,当完成整个待运算矩阵的非零判断后,根据剩下的非零运算的数量来判断需要打开多少个时钟组的乘加单元,而不需要用到的时钟组在此次运算中时钟始终处于关闭状态,最后在运算完成后,根据前面非零判断时对零数据的位置进行恢复后完成后累加,从而实现了低功耗的卷积运算处理。
乘加阵列单元的具体工作过程:
(1)两个非零判断单元分别负责对特征数据和卷积核中的数据进行非零判断,如果数据为零,则输出高有效信号到逻辑“或”电路。
(2)逻辑“或”电路负责对两个非零判断单元的判断结果进行逻辑“或”操作,将运算结果送往非零统计单元和通路开关和分配单元。因为零乘以任何数都为零,所以只要待相乘的两个数中任何一个为零则运算结果必然为零,所以在此使用了或操作。
(3)非零统计单元负责对逻辑“或”电路输出的特征数据和卷积核数据都非零的操作数进行统计,并将统计数据送往门控时钟单元。
(4)通路开关负责根逻辑“或”电路输出的判断结果,在特征数据和卷积核数据都非零时将数据送往分配单元。在有零时,不将数据送往分配单元。
(5)分配单元根据通路开关送来的数据,依次送往每个乘加阵列组,例如先送组1 的8 个乘加器,然后再是组2 的8 个乘加器,直到送满整个乘加阵列。同时并将该非零数据在特征数据流中的序号送往非零数据序号存储单元。而从实现了将整个序列中的非零数据重新整齐排列到规整缓存单元中,并将这些非零数据的序号送往累加缓存单元以方便累加时还原矩阵位置。
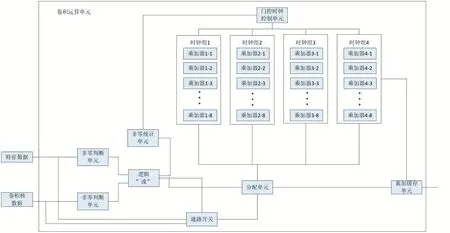
图4 卷积运算电路结构
(6)门控时时钟判断单元根据非零数据个数和乘加阵列的每个门控时钟控制的乘加器组中乘加器的个数,来决定打开几个乘加器组的时钟。
(7)乘加器单元负责对特征数据和卷积核数据进行乘加运算操作,并将乘加结果送往累加缓存单元。
(8)累加缓存单元在乘加器单元完成乘加运算后,从非零数据序号存储单元读取本次乘加运算结果对应的矩阵位置点,完成后对乘加结果的累加操作。
(9)直到整个卷积核的全部channel 完成累加,此时的累加结果作为最终卷积结果输出。
4 实验结果
通过以上提出的神经网络加速电路,可以快速完成各种神经网络算法加速处理。
为了测试本文提出的电路结构,我们采用LeNet网络结构进行实验,如图5 所示,网络包含卷积、激活、池化等运算,对应于硬件的卷积运算模块、激活运算模块、池化运算模块,同时可分为4 层运算。作为硬件运算结果的对比参考值,本文使用TensorFlow 对网络进行网络搭建和参数训练,将权重等参数载入主存储器,通过C 代码控制CPU 配置神经网络运算加速芯片,最终得到运算结果。
然后,根据本文提出的结构,使用硬件描述语言Verilog 完成了电路的设计实现,在VCS 仿真工具下进行功能仿真正确后,经过Quartus 综合,将网表下载到FPGA 器件Stratix IV EP4SE820 中,具体实验流程如下:
开始的准备工作:
首先,准备好待处理图像数据,和电路实现的算法对应的TensorFlow 算法模型;
然后,将待处理图像数据经过TensorFlow 算法模型的计算得到参考正确结果。此时,准备工作结束。
正式试验流程:
首先,将待处理图像数据和网络参数初始化到RAM 中;
然后,打开神经网络加速电路使其开始工作,加速电路读取RAM 中的待处理图像和网络参数进行神经网络层运算处理后将该层的数据结果写回RAM 的另一段地址。然后开始读入下一层的网络参数和上一层的运算结果开始下一层的运算,如此循环直到所有网络层完成运算和结果导出。
最后,将经过神经网络加速电路处理后的RAM 中的结果数据导出,并且和之前准备的参考正确结果进行比对,则可以判断电路是否可以正确工作。
实验结果表明本文设计的神经网络加速电路在FPGA 上对100 幅测试图像进行测试,测试精度为95%,与算法运算结果完全一致。
5 结语
本文提出了一套通用低功耗高效率的CNN 加速电路结构。该结构具有可重构、工作效率高、低功耗的特点,可以快速完成各种神经网络算法的图像处理,同时可以满足便携设备的功耗和性能需求。

图5 LeNet网络结构
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
成都信息工程大学学报(2021年1期)2021-07-22 07:21:34
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
计算机应用(2020年5期)2020-06-07 07:06:44
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
电子设计工程(2014年17期)2014-02-27 11:59:53
电子设计工程(2014年12期)2014-02-27 11:58:16
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:33
