
基于LSTM与多头注意力机制的恶意域名检测算法
2019-10-08 09:03黄偲琪张冬梅闫博
软件 2019年2期
黄偲琪 张冬梅 闫博


摘 要: DGA域名是一类由特定算法生成,用来与恶意C&C服务器进行通信的域名,针对DGA域名的检测一直是一个研究热点。有文献提出了基于PCFG模型的DGA域名生成算法,在现有DGA检测方法的测试下,它的抗检测效果非常显著。这是因为它由合法域名生成,具备合法域名的统计特征。基于此,本文提出了将神经网络和自注意力机制相结合的检测模型M-LSTM,它利用Bi-LSTM实现字符序列编码以及初步特征提取,并结合多头注意力机制进行深度特征提取。实验结果表明,该算法在检测基于PCFG模型的域名上效果优异。
关键词: 域名检测;多头注意力机制;PCFG模型
【Abstract】: DGA (domain generation algorithms) domain names are a class of domain names generated by specific algorithms and they are used to communicate with malicious C&C servers. The detection of DGA domain names has always been a research hotspot. DGA based on the PCFG model has been proposed Lately. Under the test of the existing DGA detection technology, its anti-detection effect is very obvious. This is because it is generated by a legal domain name and has the same statistical characteristics of a legitimate domain name. Based on this, this paper proposes a detection model M-LSTM that combines neural network and self-attention mechanism. Bi-LSTM is employed to realize character sequence coding and preliminary feature extraction, combined with Multi-Head Attention mechanism for depth feature extraction. The experimental results show that the algorithm is excellent in detecting domain names based on PCFG model.
【Key words】: Domain name detection; Multi-Head attention mechanism; PCFG model
0 引言
当今世界,互联网已经渗透进到了我们生活中的每一块角落。在带给我无穷便利的同时,不少不法分子开始利用互联网进行违法犯罪活动。近几年不断曝光的勒索软件,DDOS攻击,僵尸网络等就是良好的佐证。它们利用DGA算法生成大量的域名,与隐藏着的C&C(Command and Control)服务器建立通信。在使用这种方式时,C&C服务器不再使用唯一的固定域名,而是在不同时间生成多组域名,黑客只需要注册其中的部分域名,即可实现对僵尸网络的完整控制。据相关实验[1]表明,在采样到的43个恶意软件中,有23个将DGA域名作为唯一通信手段,另外的恶意软件则将恶意域名进行了硬编码。由此可见,DGA域名已经成为当前恶意域名通信的主要形式,针对DGA所生成的恶意域名检查具有非常重要的意义。
1 相关工作
早期的DGA算法经常以一个特定的参数作为种子,比如时间,热门网站的内容等,它们被用以初始化一个伪随机算法。僵尸主机便利用该算法自动生成大量的域名对远程的主机进行尝试,一旦尝试成功即可进行通信。例如,Conficker C变种的DGA每天可产生50000个域名,其生成的域名标签长度为4到10个字符,并且有116种可能的后缀。Ramnit算法则对种子进行四则以及取模运算以生成域名。目前也有一些DGA基于字典建模生成,如suppobox,它将随机两个字符串进行拼接得到域名。
到目前为止,恶意域名在检测方式上主要分为逆向技术和利用机器学习的方式两大类。其中逆向技术由于需要消耗大量的人力资源,且分析周期较长,已逐渐不再适合恶意域名的检测。在机器学习领域,目前的检测方向主要集中在针对域名结构及字符特征的分布检测,以及主机在使用域名时产生的流量特征检测两方面。
在字符特征方面,文献[2]针对DGA生成域名与正常域名的字符分布不同,利用域名的K-L距离,编辑距离,Jaccard系数分别作为特征向量进行分析;文献[3]利用单个DGA域的词汇特征对域名进行分析;文献[4]分析了固定域名的字符组成,利用机器学习的模型检测由DGA生成的域名;文献[5]通过分析域名序列中的詞素来分类恶意域名。
在流量特征方面,文献[6]利用了失败的DNS的请求流量进行分析;文献[7]利用了不存在域名(Non-Existent)流量数据监测随机生成的域名;文献[8]利用马尔科夫模型来区分正常流量和恶意域名的流量;文献[9]提出从网络中cache-footprints的分布来推断未知的恶意域名;文献[10]则提出通过DNS查询模式来评估僵尸网络流量分布的方法。
虽然目前的DGA检测方法针对已有的DGA域名具有比较好的检测效果,但是随着新型DGA生成算法的不断出现,现有的检测方法显得不够通用。文献[11]就提出了两种全新的DGA生成算法,这两种算法分别基于隐马尔科夫模型(HMM)和概率上下文无关语法(PCFG)。文献[11]的实验表明,在商用DGA检测系统Pleiades[6] 和BotDigger[9]的检测下,这两种DGA域名相较现有的DGA域名具备良好的抗检测效果,现有的DGA检测系统都出现了误报率偏高的问题。事实上,新型DGA生成算法已开始在针对现有检测方式的方向上不断发展,不断完善DGA域名的检测机制会是将来的一个重要命题。
本文旨在针对其中一种基于PCFG模型的DGA域名生成算法进行检测。考虑到PCFG模型的使用场景,本文也从文本处理的角度进行探索,深入研究了文本分类[12-16],之后本文利用Bi-LSTM网络结合多头注意力(Multi-Head Attention)[17]机制,提出一种针对PCFG-based 域名的检测模型M-LSTM。这个模型将域名编码成词向量后输入双向LSTM网络,LSTM将初步捕捉编码后字符序列间的潜在依赖关系。同时我们在模型中应用了Multi-Head Attention机制,它可以直接提取全局的依赖。经过Multi-Head Attention层,每个位置的特征向量将被放入第二个LSTM层以得出最后的结果。实验结果显示,相比于文献[11]中提到的传统方式检测PCFG-based域名的方案,M-LSTM在检测此类域名时优势十分明显。同时通过对比实验,也证明了Multi-Head Attention机制在这类问题中带来了明显的效果提升。
2 基于PCFG模型的恶意域名特点分析
文献[11]提出了一种利用PCFG模型进行域名生成的方法。CFG即上下文无关语法,它是对语言的一种形式化描述,具体表现为四元组G = (N,Σ,R,S),其中N表示非终结符,Σ表示终结符,S为特殊的开始符号,R表示规则。CFG的一次推导实际对应着一棵语法解析树,而推导最终的结果就是一个句子。
PCFG是CFG的扩展形式,它可以由(G, θ)表示。实现上,它是对规则集R中的每条规则都赋予一个概率p,而一个推导实际就是从开始符S开始应用一系列规则最终生成非终结符串的过程,因此这个推导(对应的语法树)的概率就是在此过程中应用的所有规则概率的乘积,即:
(1)pcfg_dict:集合来源于经过断字的英文字典;
(2)pcfg_dict_num:集合来源于1中的pcfg_ dict加上数字集合;
(3)pcfg_ipv4:集合来源于合法的经分割后的IPv4域名;
(4)pcfg_ipv4_num:集合来源于3中的pcfg_ ipv4加上一个非字母集合;
文献[11]的实验结果表明,a,c若从第四个集合中选取,所生成的恶意域名具备最优的抗检测效果。因此在本文中我们也将着重对由第四种数据源所构成的域名进行检测和分析。这类DGA域名具备以下特征:
如表1所示,基于PCFG模型的域名和合法域名在字符分布的特征上非常接近。这是由于基于PCFG的域名本身来源于合法域名,将合法域名拆分并重新拼接后的恶意域名自然具备合法域名的字符分布特征。
一旦PCFG的语法解析树确定,域名的组成将只和源集合的选取以及规则的概率相关;这也意味着同一个PCFG模型下,可以生成多种类型的域名。
文献[11]给出的第四类源生成的域名便是由合法域名的部分与数字两部分组成,生成这些域名的PCFG模型规定了三条规则,生成的域名是“字母+数字”这样的类型。鉴于此,我们也可以尝试通过构造其他PCFG模型来试着生成其他类型的域名:
如表2所示,恶意域名的生成依赖模型事先定义好的规则以及概率分布,如果规则足够复杂,概率分布均匀,同一个PCFG模型可以生成多种形式的域名。如模型4,它可以生成“字母+数字”这样类型的域名,也可以生成“字母+数字+字母”这样类型的域名。这从侧面说明了基于PCFG模型的DGA可拓展性非常强,使得我们通过找特征去判别域名带来了一定的挑战。
3 M-LSTM检测模型
由上文可知,对于PCFG-based的恶意域名,如果要人工提取特征将会是一个比较困难的工作。因此本文利用神经网络替代人工提取特征的特点,结合Multi-head Attention机制,设计一个针对PCFG- based域名检测的模型M-LSTM。
3.1 M-LSTM算法模型
模型如图3所示。
在构建算法模型时,最关键的一步是将LSTM网络与Multi-Head Attention机制相结合。在文献[18]的实验中,LSTM网络在检测一些基于字典的DGA域名,包括PCFG-based域名时,显示出的效果不是非常优异;Multi-Head Attention机制仅使用加权求和来生成输出向量,它的表达能力也是有限的。单独使用这两个技术都存在一些局限性,因此我们将这两者结合,在Multi-Head Attention层之前增加了Embedding层和LSTM层来增强网络的表达能力,它们负责将输入字符序列进行编码转换以及初步的特征提取。由Multi-Head Attention在此基础上继续进行序列间潜在关系的捕捉。
考虑到字符序列间前后向的关联关系,本文在LSTM层采用的是Bi-LSTM。最后目标是将各个位置的特征向量整合进行合法域名与恶意域名的二分类,因此在Multi-Head Attention层的后面再加上了一层Bi-LSTM,经过处理后的输出将输入softmax层,得到最后的概率分布。
3.2 M-LSTM检测方法
3.2.1 预处理
进行检测前需要将待检测域名的字符序列在Embedding层进行编码。由于每一个LSTM单元的输入是每个域名字符的词向量,因此我们需要先在Embedding层对域名进行一些预处理。预处理分为两步:
(1)字典构建
首先生成每个字符的索引字典,形式为(字符:下标),即构建出一个字符与id的映射。
(2)向量编码
将每个字符编码为LSTM网络隐藏单元数大小的向量,最后将得到维度为[字典长度,LSTM隐藏层节点数]的词向量矩陣,它将随着网络一起进行训练。在使用时,可以通过上一步的索引找到每个字符所对应的词向量。
3.2.2 网络处理
(1)Bi-LSTM层I
经过Embedding的处理后,我们将字符序列输入Bi-LSTM层I,经过LSTM网络的处理后,它将返回两个元组,分别用来保存前向后向的每一步输出以及前向后向的状态值。一个LSTM的核心单元结构如下图4所示:
LSTM单元通过“门”(gate)来控制,丢弃或者增加信息,从而实现遗忘或记忆的功能。“门”是一种使信息选择性通过的结构,它们由一个sigmoid函数和一个元素级相乘操作组成。Sigmoid函数的输出值在[0,1]区间内,0代表完全丢弃,1代表完全通过。一个LSTM单元有三个这样的门:遗忘门(forget gate),输入门(input gate)和输出门(output gate)。这样的单元设计允许神经网络存储长序列上的访问状态,从而减轻梯度消失问题。
对于域名检测而言,LSTM单元状态空间可以捕获域名的字母组合,这对于我们区分合法域名和非法域名非常重要。它可以在连续或分散的序列中学习到多个字符之间的依赖关系。
4 实验
4.1 实验设计
本实验拟利用数据集测试M-LSTM模型针对PCFG-based恶意域名检测的准确度,为此我们准备了两组对比实验:
(1)利用文献基于KL散度,编辑距离,Jaccard系数的检测方式,对PCFG-based恶意域名进行检测,并将结果与M-LSTM进行对比。
(2)用文献[18]给出的LSTM模型针对PCFG- based恶意域名进行检测,与M-LSTM相对比。
第一组实验简单地比较了传统的检测方法和M-LSTM在检测PCFG-based域名上的差异。
考虑到M-LSTM模型主要利用了Self-Attention机制作为特征提取的一种手段,与单纯的LSTM模型相比,Self-Attention机制能在整体的角度捕捉序列间潜在关系。因此实验二将两者比较,证明在加上Self-Attention机制后,模型在检测PCFG-based域名效果的提升情况。
在两次实验中,我们将使用4个不同的PCFG模型来产生恶意域名,使得实验结果更加具有普遍性。4个模型如下:
4.2 实验步骤
4.2.1 数据集准备
本文按照文献[11]给出的方式准备数据集,本次利用PCFG模型生成均为主机名。
合法域名来源于Alexa,从Alexa上抓取了排名前1M的合法域名,并按照文献给出的算法进行域名拆分和重新生成恶意域名。
其中域名集合(合法域名和恶意域名混合)的60%将作为训练集,20%作为测试集,20%作为验证集。
4.2.2 参数设置
模型初始化时所需要确定的参数。
4.3 实验结果
实验一:传统检测方式与M-LSTM模型检测效果的比较。
实验结果见表。结果表明,检测同一个PCFG模型时,横向比较召回率,精确度和F1三项指标,整体上都有M-LSTM > Jaccard系数 > 编辑距离 > KL散度。可见M-LSTM模型在PCFG-based域名上的检测效果确实好于传统手段。从具体的数字分析,M-LSTM的F1分值都在90%以上,而传统手段中表现最好的Jaccard系数,F1值最高也仅有56.31。M-LSTM检测效果平均提升了77%。这从侧面也证明了基于PCFG模型的惡意域名成功地挑战了传统的检测手段。
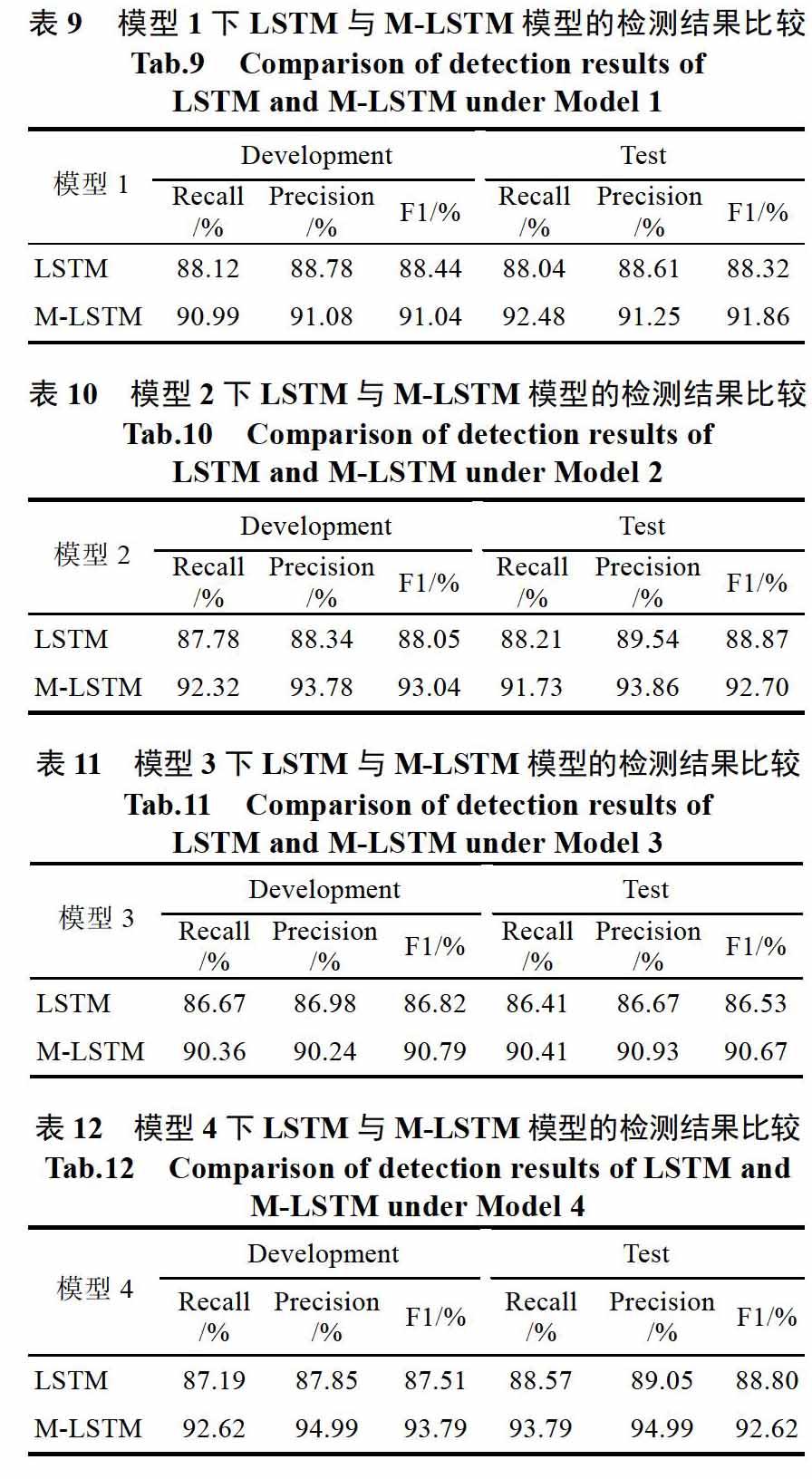
实验二:LSTM检测模型与M-LSTM模型检测效果的比较。
实验结果如上表所示。M-LSTM在LSTM模型的基础上增加了Self-Attention层。实验结果展示了在检测4类PCFG模型时,M-LSTM的效果均好于LSTM。M-LSTM的检测效果平均提升了4.67%。
从模型的角度分析,在检测率上模型2 > 模型4 > 模型1 > 模型3,可见M-LSTM的检测效果受不同的PCFG模型影响。在分析部分将对这块重点分析。
总体而言,实验结果表明了加上Self-Attention层后,模型的特征提取更加充分,使得模型的检测效果相比LSTM模型有了一定的提高。
5 实验分析
5.1 特征提取分析
基于传统字符特征的检测方式,主要将重心聚焦在字符的随机分布上。如Zeus,Kraken等DGA,字符的分布特征与合法域名相差很大。因此使用KL散度,编辑距离,Jaccard系数进行检测可以得到比较良好的效果。但是PCFG-based域名,从合法域名中将字符部分和数字部分进行拼装,辅以一些连字符等,从构造方式来看,与合法域名如出一辙。甚至如果在基数足够大的情况下,有可能生成与合法域名完全相同的域名。从这个角度来看,用字符特征去区分合法域名和PCFG-based的域名具有一定的难度。而且同一个特征很难应用于同一模型产生的不同类型的域名。而采用LSTM的优势在于不需要人工提取适用所有DGA种类的特征(实际上这也并不可能)来进行分类,特征的提取工作交给了整个网络,我们只需要将域名序列编码后输入即可。即便同一PCFG模型下产生了多类域名,整个网络也可以依靠网络的内部结构来学习特征。同时我们采用了Self-Attention机制,它一次性获取整体依赖的优势使得结果更加精确。
实验一的结果证明了检测同一个PCFG模型所生成的域名时,M-LSTM的效果要远优于传统的检测方式。
5.2 Multi-Head Attention层分析
M-LSTM模型不僅仅将LSTM作为特征提取的手段,它在实现上增加了一层Multi-Head Attention,这也是提升检测效果的关键所在。Multi-Head Attention采用了自注意力机制,它的优点在于它能够一步捕捉到全局之间的联系,完全解决长距离的依赖问题。另外,多头计算可以认为网络在多个不同的子空间内进行学习,它将不同子空间内的信息整合,尽可能地捕捉每个位置的特征。
图6是M-LSTM模型的Accuracy曲线,在不同的PCFG模型下,M-LSTM的Accuracy收敛值不同。这是因为不同模型生成域名的检测复杂度具有差异。
图6也显示了M-LSTM模型的收敛速度较快,在不同的模型下M-LSTM均在第五轮迭代前就完成了收敛。从侧面证明了模型提取特征效果优异。
5.3 模型分析
PCFG模型是可以拓展的,它的可拓展性来自规则的多样性每个规则应用的概率。模型生成的域名受概率以及规则控制,这使得安全人员几乎很难在短时间内通过恶意域名精确地反推出PCFG模型。表8至表11中的数据也显示了M-LSTM模型针对不同PCFG模型具有不同的检测效果。实验二中有多对对照试验:
模型1和模型2区别在于每个所分配规则的概率不同。规则B -> a B c是自嵌套的,这意味着域名在一定的概率下可以递归嵌套。结果表明,模型2的F1值要高于模型1,这是因为模型2的自嵌套概率更大,生成的域名更长,导致与合法域名出现了较大的距离,因此在检测率上反而更高。
模型1和模型3区别在于模型3不再采用自嵌套的规则。生成的域名更像是两个合法域名拆分后的排列组合。表12的数据证明了它的域名长度,KL散度等与合法域名十分接近。从结果来看,模型3的检测率也是四个模型中最低的。
模型3和模型4的区别在于生成域名的类型。模型3的域名较为简单,而模型4在模型3的基础上,增加了域名生成的类别。从结果来看,模型4的检测率偏高,这是因为模型4生成的域名中,abc123def类的域名容易被检测,它和合法域名间的“距离”更大。
6 结论
本文提出了一个利用LSTM网络与Multi-Head机制来检测PCFG-based域名的方法。实验证明了M-LSTM模型在此类DGA域名上的检测效果好于传统的检测方法和检测模型。模型的优点在于利用无特征的LSTM网络来捕捉域名内在联系,利用Multi-Head Attention机制来更充分地捕捉长距离特征。这避免了人为提特征以及特征不足以分类的困难。不同的PCFG模型上的检测率不同,说明PCFG不是固定不变的,它的模式可以根据使用者制定的规则而扩展。实验中M-LSTM在不同的PCFG模型上都表现出了较优秀的效果,证明了该模型在PCFG-based域名检测中的有效性。
参考文献
Plohmann D, Yakdan K, Klatt M, A comprehensive measurement study of domain generating malware[C]//25th USENIX Security Symposium. Austin: Usenix, 2016: 263-278.
S. Yadav, A. K. K. Reddy, A. L. N. Reddy, and S. Ranjan, “Detecting algorithmically generated malicious domain names,” in Proc. 10th ACM SIGCOMM Conf. Internet Meas., 2010, pp. 48-61.
XiLuo, Liming Wang, “DGASensor: Fast Detection for DGA-Based Malwares” ICCBN '17 Proceedings of the 5th International Conference on Communications and Broadband Networking, 2017-02-20
M. Mowbray and J. Hagen, “Finding domain-generation algorithms by looking at length distribution, ” in Proc. IEEE Int. Symp. Softw. Rel. Eng. Workshops (ISSREW), Nov. 2014, pp. 395–400.
Z. Wei-Wei and G. J. L. Qian, “Detecting machine generated domain names based on morpheme features, ” in Proc. Int. Workshop Cloud Comput. Inf. Secur., 2013, pp. 408–411.
T. -S. Wang, H. -T. Lin, W. -T. Cheng, and C. -Y. Chen, “DBod: Clustering and detecting DGA-based botnets using DNS traffic analysis, ” Comput. Secur., vol. 64, pp. 1–15, Jan. 2017.
M. Antonakakis et al., “From throw-away traffic to bots: Detecting the rise of DGA-based malware,” in Proc. USENIX Secur. Symp., 2012, pp. 491–506.
Maria Jose Erquiaga, “Detecting DGA Malware Traffic Through Behavioral Models ” IEEE, 2016-6
T. Wang, X. Hu, J. Jang, S. Ji, M. Stoecklin, and T. Taylor, “BotMeter: Charting DGA-botnet landscapes in large networks, ” in Proc. IEEE 36th Int. Conf. Distrib. Comput. Syst. (ICDCS), Jun. 2016, pp. 334–343.
T. -S. Wang, H. -T. Lin, W. -T. Cheng, and C. -Y. Chen, “DBod: Clustering and detecting DGA-based botnets using DNS traffic analysis, ” Comput. Secur., vol. 64, pp. 1–15, Jan. 2017.
Yu Fu, Lu Yu, Oluwakemi Hambolu, Ilker Ozcelik, Benafsh Husain, “Stealthy Domain Generation Algorithms” IEEE Transactions on Information Forensics and Security (Volume: 12, Issue: 6, June 2017)
陳海红. 多核SVM 文本分类研究[J]. 软件, 2015, 36(5): 7-10.
罗笑玲, 黄绍锋, 欧阳天优, 等. 基于多分类器集成的图像文字识别技术及其应用研究[J]. 软件, 2015, 36(3): 98-102
王宏涛, 孙剑伟. 基于BP 神经网络和SVM 的分类方法研究[J]. 软件, 2015, 36(11): 96-99.
张玉环, 钱江. 基于两种 LSTM 结构的文本情感分析[J]. 软件, 2018, 39(1): 116-120.
张晓明, 尹鸿峰. 基于卷积神经网络和语义信息的场景分类[J]. 软件, 2018, 39(01): 29-34.
Ashish Vaswani, Noam Shazeer, Niki Parmar, “Attention is all your need”, Computation and Language (cs. CL); Machine Learning (cs. LG), arXiv: 1706.03762.
Woodbridge J, Anderson H S, Ahuja A, et al. Predic ting domain generation algorithms with long short-ter m memory networks[EB/OL]. arXiv, 2016-11-2[1018-3-10]. https:// arxiv.org/abs/1611.00791.
