
基于深度学习的上市公司财务风险预警研究
2019-10-08 07:13:24刘洪涛
中国乡镇企业会计 2019年9期
刘洪涛
一、绪论
(一)研究背景和目的
深度学习(Deep Learning)是基于对人脑神经元结构的研究提出的一种很复杂的机器学习分类算法,它在图像、声音的识别以及自然语言处理等领域都表现出强大的能力。TensorFlow 是由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护的深度学习框架。自2015 年11 月9 日起,TensorFlow 依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码。
财务风险预警是指基于企业历史财务数据对企业的财务风险做出预测。随着我国资本市场的发展,上市公司的披露信息的数量和质量都有了很大提升,这为使用深度学习评价上市公司财务状况奠定了基础。
虽然深度学习在人工智能领域表现出了很强大的能力,但是目前理论上缺乏足够的支撑。2017 年的NIPS(Neural Information Processing Systems)上,谷歌工程师Ali Rahimi 称,深度学习成为了今天的“炼金术”。基于此,本文的写作目的是在应用层面验证深度学习财务预警的有效性。
(二)财务风险的界定
企业的风险可以分为经营风险和财务风险,其中财务风险特指企业在生产经营中的财务活动与财务治理中所面临的风险。理论界对于财务风险的界定分为狭义和广义两个层面。财务风险的狭义观点是指由于利用负债给企业带来的破产风险或普通股收益发生大幅度变动的风险;广义观点认为财务风险是指企业整个财务活动过程存在的不确定性可能导致企业的实际收益与预期不一致。广义的财务风险是一个多变量、多层次的复合性概念,比较接近于企业整体的风险,最终反映在企业的财务报表中。本文中的财务风险是指广义的财务风险。
(三)文献综述
受第一次经济危机的影响,西方学者开始财务风险预警的研究。财务预警定量分析开始于1932 年Fitz Patrick 进行的一项研究:他以19 对破产和非破产公司作为样本,运用单个财务比率将样本划分为破产和非破产两组,发现判别能力最高的两个指标是净资产收益率和股东权益/负债。1966 年,Beaver 沿着Fitz Patrick 的思路,使用5 个财务比率作为变量,分别对79 家经营成功和79 家经营失败的公司进行了一元判定预测,发现最好的财务指标是现金流量/负债,其次是资产负债率。
为减少使用单一指标的片面性,人们开始尝试使用多变量模型预测财务风险。1968 年,Altman 提出了Z 计分模型。该模型运用5 种财务比率来预测财务风险,分别是营运资金/资产、留存收益/资产、EBIT/资产、股东的权益资产/负债和销售额/资产。同样在20 世纪70 年代,日本开发银行调查部发表的《利用经营指标进行企业风险评价的新尝试——利用多变量分析的探索》中使用6 种财务比率来预测财务风险,分别是销售额增长率、总资本利润率、利息率、资产负债率、流动比率和粗附加值生产率。
1977 年,Altman、Haldeman 和Narayanan 提 出 了ZETA 模型,对Z 模型做了一些优化。同年,Martin 第一次建立了多元logistic 财务风险预警模型。1980 年,Ohlson运用Logistic 模型对1970-1976 年的105 家破产公司和2058 家正常公司进行了财务预警分析。他发现以资产规模、资本结构、资产报酬率和短期流动性四项财务指标的财务预警的准确度可达96.12%,同时发现在研究选用的财务指标往往滞后于财务危机的发生日,所以存在高估预测能力的情况。
财务风险预警模型先后经历了单变量模型、多变量模型、Logistic 模型等线性模型发展阶段。由于线性模型依赖于严格的假设,且没有自适应学习的能力,人们又探索了人工神经网络模型等非线性的预测模型。
上世纪80 年代,西方学者开始将人工智能技术应用到企业财务风险预警上来。1988 年,Dutta 和Shekhar 首次将神经网络技术应用到企业债券等级的预测上。随后,在1990 年Odom 和Sharda 将神经网络应用到企业财务风险预警的问题上。他们以129 家企业(65 家破产企业和64 家非破产企业)作为研究样本,以Z 模型中的5 个财务指标作为输入变量,结果发现预测效果比判别分析法好。1993 年,Coats 和Fant 沿着这一思路,继续以Z 模型的5 个财务变量作为输入变量建立神经网络模型,结果发现神经网络模型比Z 模型更适合于企业长期财务风险的预测。
国内关于神经网络在财务风险预警中应用的研究起步较晚。1995 年,黄小原等在《预测》杂志上发表了关于神经网络预警系统的理论介绍,但由于数据量、机器算力都有限,这篇文章只能停留在理论层面。2002 年之后,随着大数据和人工智能应用的发展,与神经网络和财务预警相关的文献出现快速增长。杨保安等选取了15 项财务指标、30 个训练样本设计三层(15*15*3)的BP 神经网络,这篇文章引起了较大的关注和更多相关的尝试,但文章中的神经网络训练节点数高于训练样本数,可能存在过拟合的问题。黄宏远等通过变异系数和相关系数对最为常用的衡量公司绩效的22 项指标进行初步筛选和二次筛选,将相关程度较高的输入转换成少数几个因子作为神经网络的输入。这种做法类似卷积神经网络的卷积过程,可以有效减少数据的维度。
在大多数文献中,训练神经网络时训练集的数据量都是几十到两三百家上市公司一到两年的数据,很难满足神经网络的训练要求。近几年来,随着数据获取技术、财务数据库的发展,数据量级的提升使得神经网络的预测结果能够更加可靠。曹兴选取A 股全部非ST 上市公司2014 年的数据,同时选取2008 至2016 年ST 企业前两年的数据作为训练样本,训练的神经网络成功预测了两年后ST 博元的财务危机。宋歌等采用2007 年至2016年3513 家上市公司的相关财务数据为研究样本,结果显示神经网络对所有上市公司是否陷入财务危机的预测准确率可以达到72%以上。
(四)本文的研究思路
本文认为,在之前的研究文献中,大多存在两方面的问题:第一是对行业因素考虑不充分,第二是多以ST/非ST 分类作为标记高风险企业的基础。首先,不同行业的企业的财务指标呈现的特征并不总是一样的,如轻、重资产企业在营运资本、周转率上就有明显的不同。如果不考虑行业因素,神经网络得出的结论就会出现问题,最终的输出可能取决于训练集中轻、重资产企业所占比重。其次,经过对大量ST 企业财务指标的分析,本文认为简单地以ST/非ST 分类方法标记高风险企业是有问题的,因为ST 公司中存在很多通过盈余管理美化财务指标的情况,而非ST 公司首年出现亏损并不会被ST,所以公司是否ST 与其财务指标所反映出情况的好坏没有确定性的关系。
本文的研究思路具体可以划分为以下四步:
1.财务指标的选取
选取合适的财务指标,可以代表企业的财务状况并作为神经网络的输入。
2.数据收集、处理和标记
收集足够多的数据,剔除其中不能使用的数据,并按神经网络的输入要求进行处理(主要是标准化和标记数据的过程)。同时把其中一部分数据划分出来作为测试集,不参与神经网络的训练。
3.训练和调整神经网络
搭建并训练神经网络模型,通过调整训练参数,获得一个近似最优的预测模型。
4.预测和分析
使用在测试集上表现最好的神经网络预测部分2018 年非ST 公司的财务风险,并结合对这些公司的财务分析得出预测结果是否可靠的结论。
二、神经网络财务风险预测体系设计
(一)财务指标体系的建立
本步骤包含两个主要问题:选取财务指标的数量和选取哪几个指标。选取的财务指标的数量关系到神经网络的输入节点个数,也就关系到整个网络的规模。在数据量有限的情况下,显然选取的指标不能越多越好,应该保持在一个合理的区间内。另一方面,选取什么样的财务指标直接关系到最终预测结果的好坏。
本文先分析以往研究中被选用次数较多的财务指标,再从中选择本文使用的财务指标。下表列出了本文文献综述中涉及的大部分财务指标。
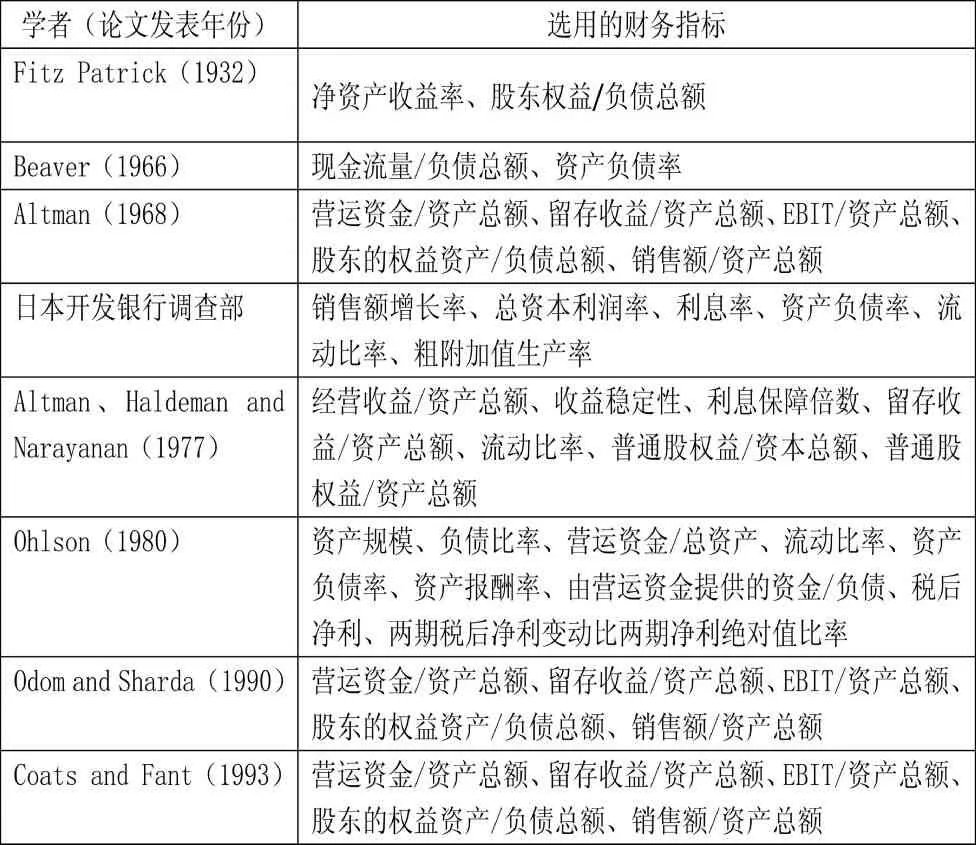
表1 文献综述中的财务指标汇总
秦志敏(2012)对我国上市公司财务预警变量的选择问题做了一些研究,通过分析这篇论文中提到的国内外经典研究成果,发现在经典文献中被使用次数最多的财务指标依次是:总资产报酬率、资产负债率、流动比率、总资产周转率、净资产收益率、产权比率、留存收益/总资产和营运资本/总资产。非财务指标中,审计意见和董事所占股份比例被多次使用。在较新的文献中,被更多考虑的是现金流量指标、每股指标和成长能力指标。
综合以上信息,本文在选用指标时尽量选用在经典文献中常用的指标,同时选用一些新文献中使用的指标。本文把选用的指标分为9 类,分别是结构比率、偿债能力、盈利能力、营运能力、成长能力、每股指标、现金流量、非财务指标和反映行业盈利能力的行业指标。具体指标的选取如下表所示:
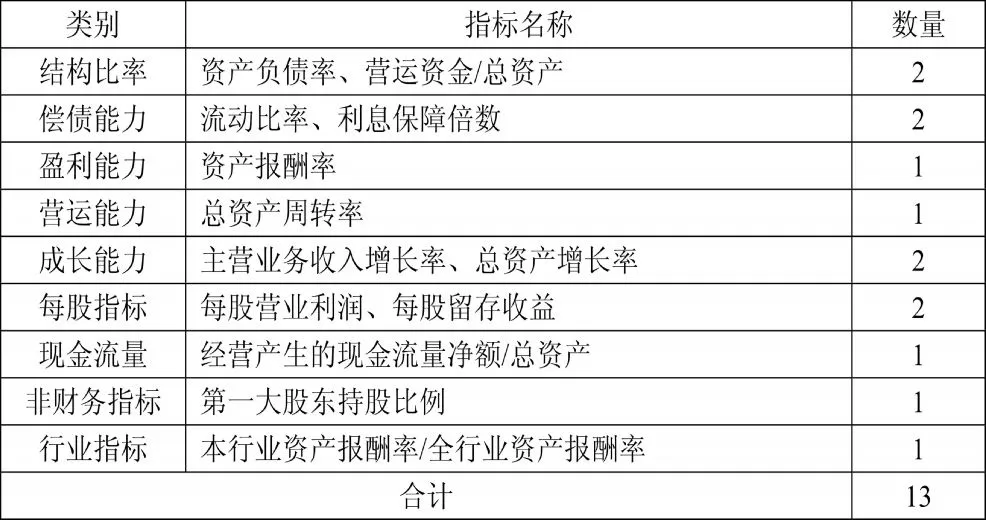
表2 财务指标体系
(二)数据收集、处理和标记
本文中使用的原始数据全部取自国泰安数据库及相关公司财务报告。参与训练的有效数据条数为18225 条,包括国泰安数据库中2005 年-2017 年全部沪深A 股上市公司数据和2018 年部分沪深A 股上市公司数据。本文在数据清理时去掉了含缺失项的数据和本行业内公司数量过少的公司数据,便于以后的数据处理。
一般来说,输入数据可以使用归一化的处理方法,以消除各指标计量单位不同的影响。但本文采用的数据极差较大,经初步测试直接归一化后的数据呈现两极化的特点,此时离差归一化方法(最大最小值归一化)就不再适用了。
本文中标准化过程采用Z-score 标准化,这种方法适用于原始数据近似服从高斯分布的情况。本文的行业分类采用证监会二级行业分类(共82 类)。下式中的均值是对应指标同年度的行业均值,标准差是对应指标同年度的行业标准差。

在没有进行进一步数据处理的情况下,本文直接使用标准化后的数据训练了几次神经网络。在训练集上测试神经网络时,输出的预测值往往集中在一个较小的区间中,区分度较小。经分析本文认为,由于ST 公司往往会进行盈余管理美化财务指标,且一家公司只有连续亏损才会被ST,所以直接选用ST 公司的财务指标作为危机企业的指标是不尽合理的,同时非ST 公司也不一定意味着其财务状况良好。
在危机企业的标记方法上,本文采用了手工标记的方式,重点关注盈利能力、成长能力、现金流量和行业指标四个方面。虽然这种方法具有很强的主观色彩,但实践证明这种标记方法的效果甚至会优于直接使用ST/非ST 分类的标记方法。
(三)训练和调整神经网络
经大量实验,本文训练的神经网络确定为3 个隐藏层(14*9*5)、输出层节点数为1 的4 层神经网络,输出的结果经Sigmoid 函数转化为0-1 之间的实数。
训练过程中loss 值的下降如下图所示:
(四)测试结果
在本阶段的测试中按照输出值的大小进行分级,预测结果和对应级别如下表所示:
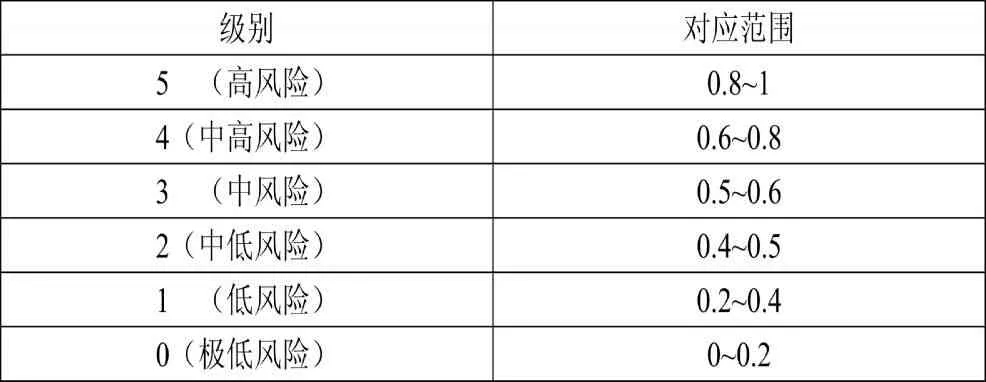
表3 基于预测结果的评级表
测试集为数据收集阶段随机选出的100 家正常公司(标记为0)的数据和100 家高风险公司(标记为1)的数据。在测试集上测试的结果如下表所示,其中正确率的计算公式为:预测风险级别为3 级及以上的公司数量/预测风险级别为2 级及以下的公司数量。
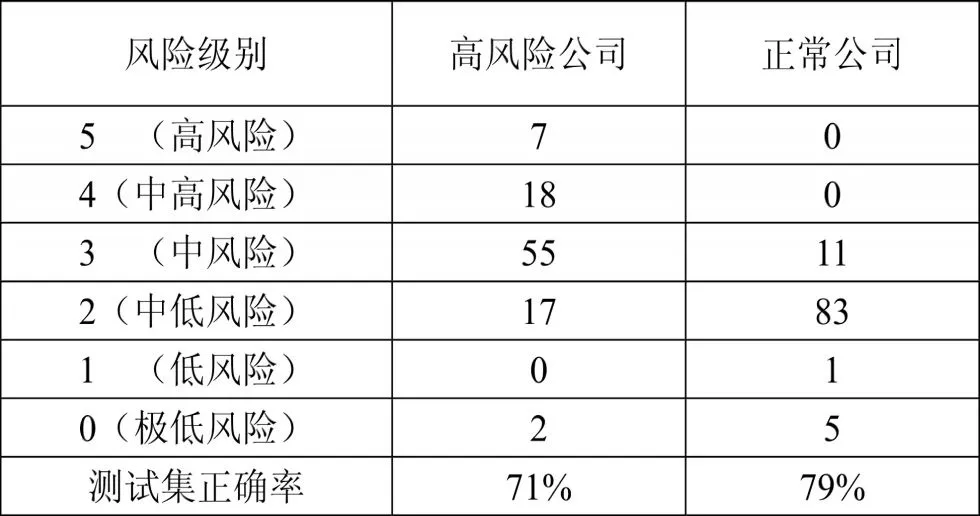
表4 预测结果统计表
三、应用实例
本文从沪深A 股的非ST 公司中随机抽取55 家,使用这些公司2018 年年报的数据计算各指标并标准化,输入神经网络后得到如下的结果:
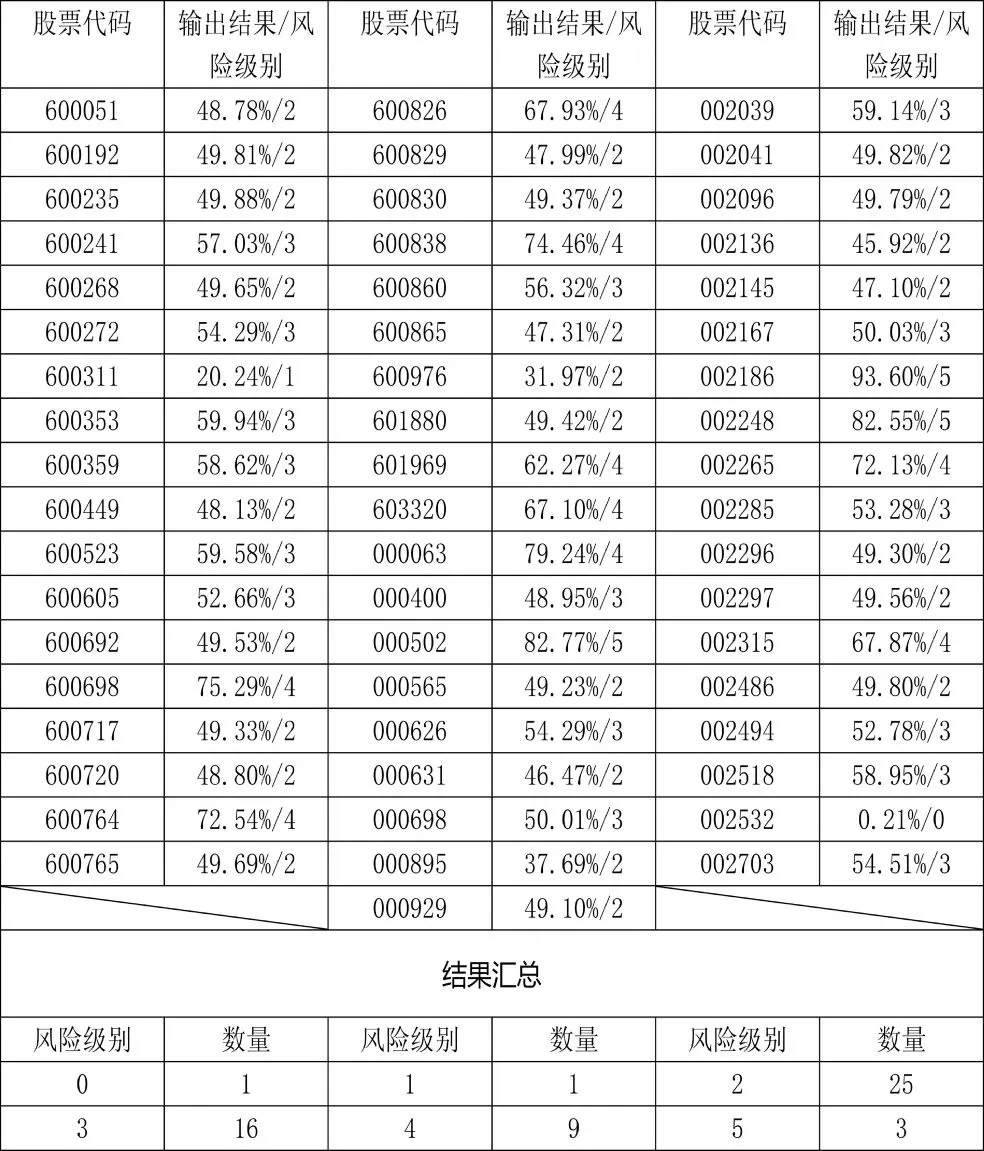
表5 应用实例预测结果表
本文对预测级别为第5 级的三家公司(股票代码000502、002186 和002248)进行验证,三家公司的基本信息如下:

表6 风险等级为5 的公司基本信息
以上三家公司2018 年度主营业务收入增长率和总资产增长率均为负数。绿景控股报告了重大资产出售事项,且其本报告期盈利的原因是子公司广州明安出售北京明安100%股权、明安康和100%股权及南宁明安70%股权,本期确认投资收益。全聚德披露的信息显示,其2018 年归属股东净利润较2017 年几乎减少一半,营收和利润的跌幅均为自2004 年上市以来最高。华东数控披露的审计报告中提到:“华东数控2016 年度亏损,2017年度利润主要来源于政府补助和资产处置收益,2018 年度继续亏损”,“其流动资产小于流动负债,这些事项或情况表明存在可能导致公司持续经营能力产生重大疑虑的重大不确定性。”
通过以上简单分析,三家公司的确出现了财务危机,可见神经网络的预测风险较高时,预测的结果是可靠的。
一般认为企业财务状况的变化是连续的,企业出现高度财务风险暗示着其必然经过了中低风险、中风险、中高风险这些阶段。财务风险预警当然是越早越好,所以本文更关心的是神经网络输出中低风险时,预测的结果是否可靠。再从表5 中预测风险等级为2 的公司中随机抽取1 家(股票代码为600692),其基本信息如表7 所示:

表7 风险等级为2 的公司基本信息
亚通股份主要财务数据如表8 所示:
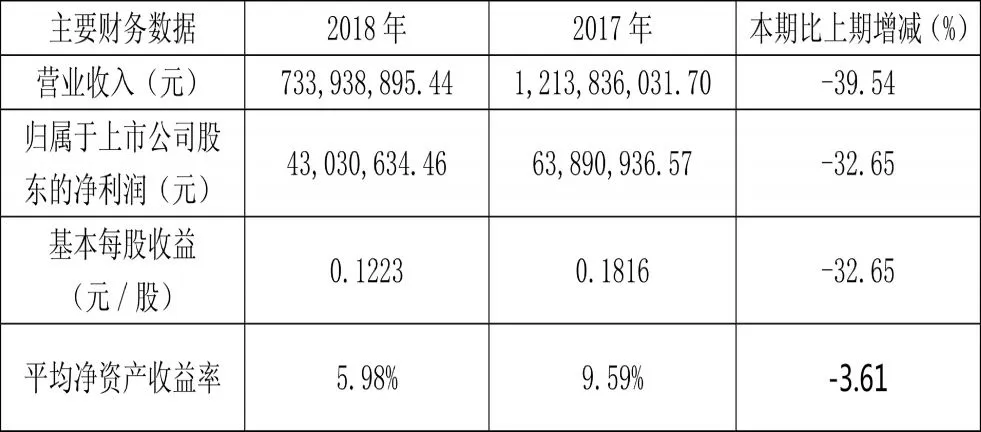
表8 亚通股份2017 与2018 年主要财务数据
与2017 年相比,亚通股份2018 年营收和净利润均出现了负增长。亚通股份在其披露的年度报告中表示,2018 年主营业务收入较上年减少主要系国际钢材贸易减少和房地产交付率下降所致。亚通股份的财务风险确有增大的趋势,可见神经网络输出中低风险的预测结果时,仍然可以起到较好的风险提示作用。
四、总结
本文采用沪深A 股部分上市公司的财务指标为样本,使用TensorFlow 框架搭建神经网络模型,训练后的神经网络达到了75%左右的正确率,且在实际应用中能起到较好的风险提示作用。本文较之前研究的创新之处主要体现在以下两点:第一,充分考虑了行业因素,不仅在指标标准化时采用了行业均值和标准差,还在神经网络的输入中加入了一个基于行业整体盈利能力的行业指标;第二,放弃了传统的基于ST/非ST 公司的分类方式,尽量减少公司盈余管理对预测效果的影响。同时,本文最大的缺陷也在于此,因为这种方法带有很强的主观判断。
本文通过训练好的神经网络评价了2018 年部分非ST 公司的财务风险,并结合中低风险公司亚通股份的预测情况,验证了神经网络在财务风险预警中的有用性。通过应用实例的验证,可以认为本文训练的神经网络在实际应用中是比较可靠的。
综上所述,深度学习在处理非线性问题上有很大优势,在财务风险预测领域也有很好的表现和发展前景。
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
今日农业(2019年12期)2019-08-13 00:50:02
现代营销(创富信息版)(2018年8期)2018-09-08 08:51:58
现代园艺(2017年22期)2018-01-19 05:07:01
中国财政年鉴(2017年0期)2017-07-04 08:49:18
中国财政年鉴(2016年0期)2016-06-05 15:23:31
重型机械(2016年1期)2016-03-01 03:42:04
火控雷达技术(2016年3期)2016-02-06 02:30:27
财经界(学术版)(2015年20期)2015-12-23 09:20:15
大连工业大学学报(2015年4期)2015-12-11 04:06:52
