
基于改进LeNet-5的交通标志识别算法研究
2019-09-25 04:16褚莹陶纪宇凌力
微型电脑应用 2019年9期
褚莹, 陶纪宇, 凌力
(复旦大学 通信科学与工程学, 上海 200433)
0 引言
随着社会的快速发展和居民收入的增加,汽车保有量急剧上升,汽车行业受到越来越多的关注。WayMo公司研发的无人驾驶汽车已经在公路上测试[1];特斯拉已经在汽车上推出了自动驾驶系统[2]。
作为自动驾驶系统中的关键部分,交通标志识别系统(traffic sign recognition)一般分为交通标志位置检测和交通标志识别两个部分。本文将侧重对交通标志识别系统中交通标志识别的部分进行研究。
国外学者早在20世纪80年代就意识到了智能交通的重要性。1987年,日本Akatsuka[4]等学者通过模板匹配方法,率先实现了交通标志检测识别系统。1996年,美国学者Estevez[5]等人通过RGB差分和Maxima边缘检测定位待识别区域中的交通标志边缘。2011年,主题为交通标志识别的国际神经网络联合会议召开,大力推动了交通标志识别的发展。
国内对于交通标志识别的研究起步较晚,在交通标志识别领域距离国外研究在技术和水平上仍有一定差距。
在此基础上,本文主要针对卷积神经网络以及卷积神经网络在交通标志识别领域的应用进行了研究,提出了适用于真实场景的交通标志识别的高性能卷积神经网络TSRCNN网络。
1 Lenet-5模型
LeNet-5模型是由Yann[6]等人提出的轻量级卷积神经网络模型。LeNet-5模型作为首个在手写数字识别领域中获得优异成绩的卷积神经网络,奠定了卷积神经网络在图像识别领域中的地位。
LeNet-5模型共包含7层网络(不包含输入层),针对手写数字识别的模型的结构及参数如图1所示。
2 TSRCNN模型
LeNet-5作为手写数目识别的经典模型,在交通标志识别领域表现并不十分出色。不过在实验中我们发现LeNet-5的经典结构对于构造交通标志识别领域的卷积神经网络仍有很大的参考价值,因此在LeNet-5的基础上,我们构建了交通标志识别领域的TSRCNN卷积神经网络,最终在比利时交通标志数据集上达到了98.56%的正确率。
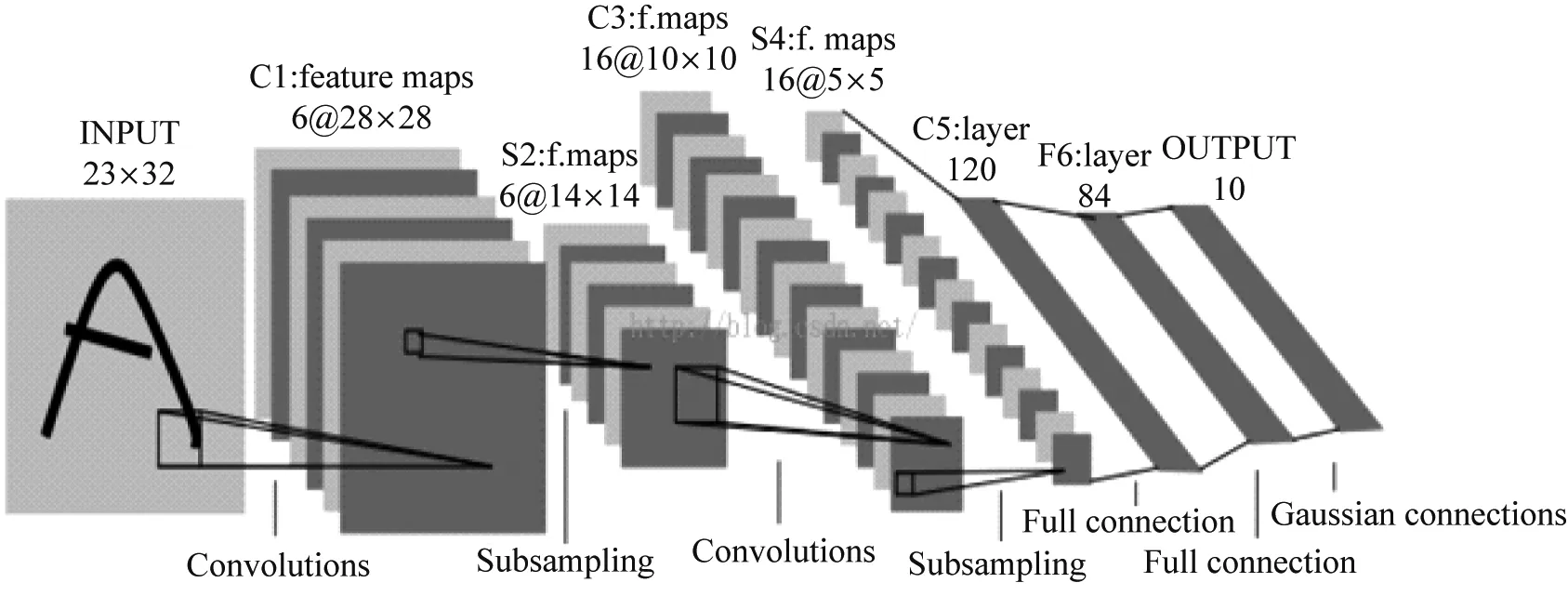
图1 LeNet-5模型结构示意图
TSRCNN模型结构如图2所示,具体参数如表1所示。

图2 TSRCNN模型结构示意图
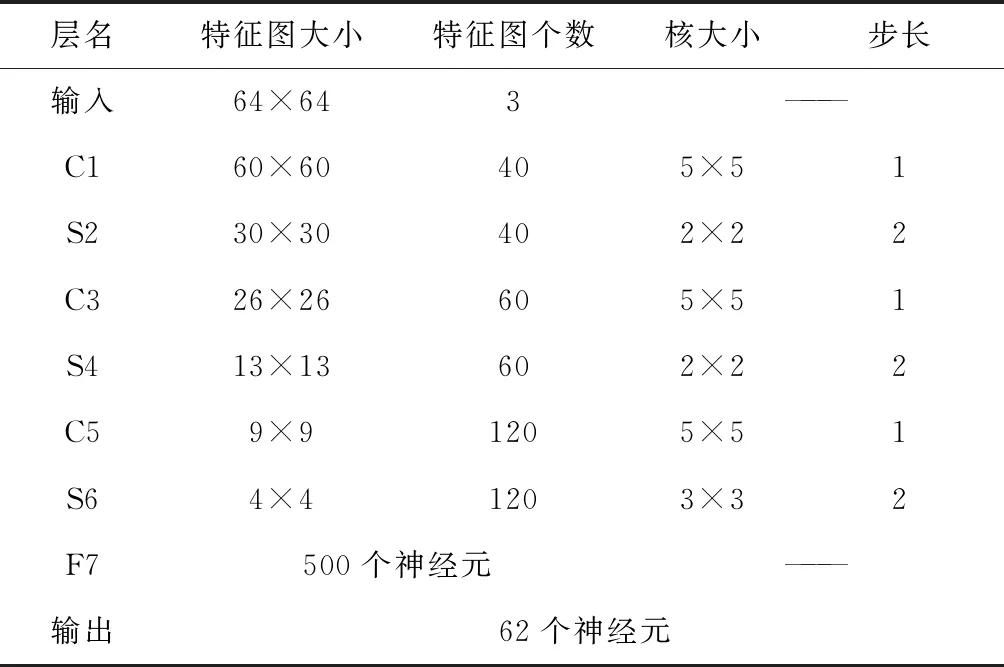
层名特征图大小特征图个数核大小步长输入64×643———C160×60405×51S230×30402×22C326×26605×51S413×13602×22C59×91205×51S64×41203×32F7500个神经元———输出62个神经元
其中Dropout策略和BN层的有效性在模型性能测试与分析一节中将通过实验验证。
3 数据集预处理
因为标准数据集均在真实场景下采集,因此我们选择采用比利时交通标志标准数据集作为模型的训练数据集。
比利时交通标志数据集共包含62种交通标志,共4 575张训练图,2 520张测试图。数据集中部分交通标志,由车载相机在车辆行驶途中拍摄得到,如图3所示。

图3 比利时交通标志数据集中部分标志图
如图4所示。

图4 64×64像素和32×32像素的交通标志
图片的尺寸分别是64×64和32×32,可以看到32×32的图片中肉眼也已经难以辨别细节,因此最终在本实验中我们选取64×64为归一化的图片尺寸。
数据集中每类交通标志的分布图,如图5所示。

图5 比利时训练集中各类交通标志数量分布示意图
可以看到交通标志的分布并不均衡。考虑到由于每个类别的样本基数不同,需要扩充的数量也不同,所以最终采用了重复的方式扩充数据集,平衡各分类的分布。
我们以训练样本数最多的类别为标准——类别为22的交通标志拥有375张训练图,以375为标准扩充现有的数据集,每类数据集重复次数可以表示为式(1)。
(1)
式中xi为每i类数据集现有的训练样本数目,yi为数据集需要重复的次数。为了保证数据平衡,每类数据集采用重复本类数据集内所有的训练样本的方法,避免对清晰图像/模糊图像的判别率失衡。较之前得到了显著的提升。
经过重复操作后,训练集样本总数由原来的4 575张,扩充到21 094张。新的训练数据集分布图可以看到均衡性得到了提升。如图6所示。

图6 比利时训练集数据增广后各类交通标志数量分布示意图
4 实验性能测试与分析
4.1 实验平台简介
本文中使用的仿真实验平台为Ubuntu16.04操作系统,硬件环境为2核Intel(R) Core(TM) i5-7 500 CPU @ 3.40 GHz,内存为10 GB,显卡为NVIDA的 GTX 1 050 Ti,显存为4 G。
本实验模型实验均在Caffe环境下搭建。Caffe是由伯克利视觉学习中心和社区共同开发,该项目创建于伯克利大学的贾扬清博士[7]在攻读博士期间。
4.2 数据集增广有效性验证
本小节中的对比实验中仅对使用的数据集作区别。模型采用Adam优化器,初始学习率为0.001,每个实验中共对训练集进行10 000次迭代,每100次迭代后对模型进行准确率测试,如表2所示。

表2 数据集增广对比实验
从表2可见,当我们使用经过增广的数据集,TSRCNN模型能够到达98.56%的识别准确率,说明模型对整个数据集的识别率得到了提升。
4.3 批量归一化层有效性验证
Sergey[8]等人于2015年提出批量归一化(batch normalize, BN层)的方法。该方法的提出是为了解决模型训练过程中内部协变量转移的问题。
我们共构建两种网络模型进行对比试验。除网络结构外,训练相关的参数均保持一致。
对两种不同结构网络进行仿真实验后得到的结果如表3所示。

表3 BN层对比实验
可以看出在加入BN层后,网络的准确率从98.12%提升到98.56%。两种网络结构在训练过程中准确率的上升趋势图,如图7所示。
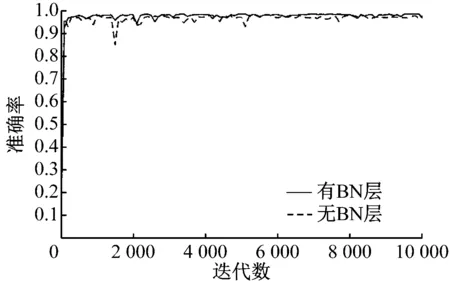
图7 包含BN层TSRCNN模型与不包含BN层模型
可以看到BN层的加入让准确率的上升过程显得更为平稳。
4.4 Dropout最佳参数选择
Dropout作为一种经典的正则化方法[9],在卷积神经网络中的作用主要是防止网络过拟合。Dropout策略通常在全连接层使用,因此我们选择对F7全连接层使用该策略。使用Dropout的经验值一般设置为0.5,在本实验中我们选择0,0.4,0.5,0.6三个数值进行比较,如表4所示。

表4 不同概率Dropout对照实验准确率
从表4中我们可以看到在使用Dropout策略后,模型的识别准确率得到了显著提升。其中当Dropout概率为0.5时,模型达到了最高的准确率98.56%,因此我们在TSRCNN模型中Dropout概率采用0.5。
4.5 卷积层和全连接层参数比较
本小节将通过多组对比实验,确认模型中卷积核尺寸及数目和全连接层节点数。
(1)卷积核尺寸对比实验
在TSRCNN模型的卷积核尺寸实验中,我们对所有卷积层均采用一样的卷积核尺寸。我们将测试三种常用的卷积核尺寸:3×7,5×5,7×7。除网络结构外,训练相关的参数均保持一致,如表5、图8所示。

表5 卷积核尺寸对照实验准确率

图8 不同卷积核模型准确率变化趋势
从表5和图8中可以看到采用5×5的卷积核尺寸的模型在测试集上获得了最高的准确率,因此我们卷积核尺寸均采用5×5。
(2)卷积核数目对比实验
为了确认最佳的模型结构,我们对卷积核数目开展了9组对比实验,如表6所示。
从表6中可以看到采用当C1卷积层采用40个卷积核,C3卷积层采用60个卷积核,C5卷积层采用120个卷积核时,模型在测试集上获得了最高的准确率。因此,我们最后三层卷积层卷积核数目选用40、60、120。
(3)全连接层节点数对比实验
全连接层我们测试了3种节点数:400、500和600,除全连接层的节点数目外,TSRCNN模型其他结构不做更改,如表7所示。
从表7中可以看到采用当全连接层采用500个节点时,模型在测试集上获得了最高的准确率。因此我们全连接层采用500个节点。

表6 卷积核数目对照实验准确率
4.6 TSRCNN模型实验结果及分析
在本小节中,我们将对TSRCNN模型进行测试分析。为了更直观的展示各个优化措施的有效性,我们设置了包含五种模型结构的对比实验,五种模型结构为:
(1)LeNet-5模型:数据集使用未增广的原数据集;
(2)TSRCNN基础模型:TSRCNN基础模型是指使用未增广数据集及未加上Dropout和BN层训练得到的模型;
(3)TSRCNN基础模型+增广数据集;
(4)TSRCNN基础模型+增广数据集+Dropout;
(5)TSRCNN模型(TSRCNN基础模型+增广数据集+Dropout+BN)。
我们在表8中使用序号代表模型的类别,LeNet-5模型为模型一,TSRCNN基础模型为模型二,其他模型以此类推,如表8所示。

表8 对照实验准确率
从表8中可以看到,我们使用的优化措施使得模型的识别准确率从95.44%逐步上升至98.56%。可以看到TSRCNN误差的下降趋势较为稳定,如图9所示。
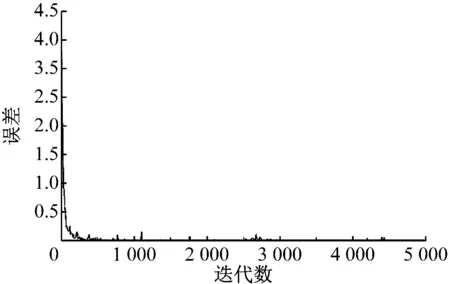
图9 TSRCNN模型误差变化趋势
同时如图10所示。
TSRCNN模型在保持高准确率的同时,整体的准确率趋势同样表现的很稳定。
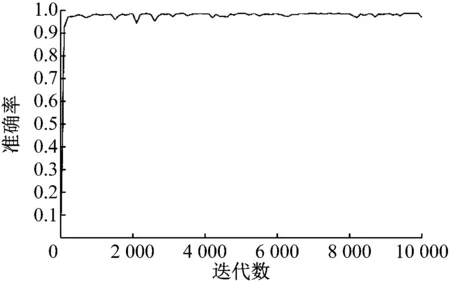
图10 TSRCNN模型准确率变化趋势
实验结果证明,对LeNet-5模型做的改进措施包括:基础结构的调整、数据集增广、加入的Dropout策略和BN层,均有效的提升了模型的识别准确率。
5 总结
本文通过对交通标志数据集、LeNet-5网络结构进行优化调整,构造了在交通标志识别领域表现更为优秀的TSRCNN网络。经实验验证,TSRCNN模型在交通标志识别数据集上能够获得98.56%的高准确率。未来的工作中,可以通过模型压缩的算法,在保持正确率的情况对模型的结构进行压缩,获得更高性能的网络。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2016年8期)2016-05-14
