
车牌识别的设计与研究
2019-09-24 02:00张奥祥
电脑知识与技术 2019年19期
张奥祥


摘要:智能交通管理应用趋势逐步加升,车牌识别是智能交通中重要的一部分。车牌识别应用于许多场合如停车场管理、小区门禁、高速收费处等。该文利用图像处理技术和MATLAB软件的使用来研究车牌的识别,利用Canny算子进行车牌的边缘检测,在字符分割中应用投影法进行分割,应用模板匹配进行车牌的字符识别。
关键词:图像图像处理;Canny算子;投影法;模板匹配;MATLAB
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2019)19-0205-03
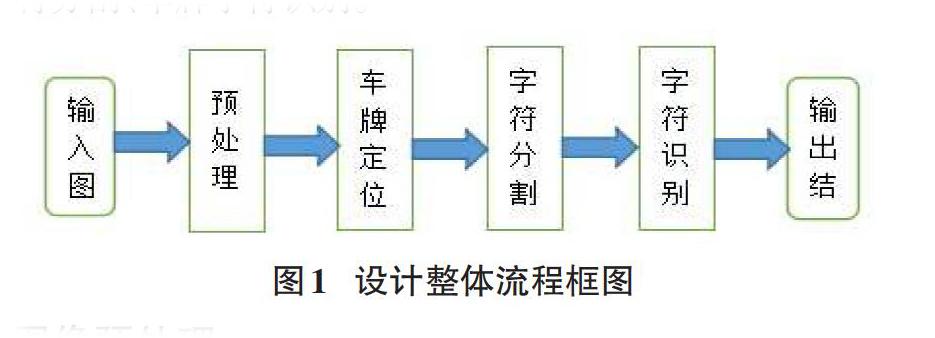
随着现代社会车辆的不断增多,车牌识别的重要性不言而喻,车牌识别的应用使得交通运输和管理的效率增长了许多。车牌识别技术近几十年来不断地改进、发展。文中主要把车牌识别归纳为四大部分:车牌图像的预处理、车牌定位、车牌字符分割、车牌字符识别。
1 图像预处理
1.1 图像灰度化
现代相机,手机等拍摄设备所采集的图片均为彩色图片,但在车牌识别中,彩色图片对车牌的精确定位并没有益处,会耗费大量的时间和计算工作,因此我们要对彩色图片进行灰度化。彩色图像通过灰度处理转化为灰度图像这一过程叫作图像灰度化,彩色图像的每个像素的颜色由R、G、B三个分量组成,即红、绿、蓝三种颜色。每种颜色都有255种灰度值可以进行选择,(0表示黑色,255表示白色)。灰度图像就是R、G、B三个分量灰度值相同的一种特殊图像。
1.2 图像去噪
图像去噪的常用方法为:均值滤波、中值滤波、高斯滤波。均值滤波在对于边缘的去噪过于剧烈,在去噪的同时对图像的部分细节也有损坏,反而会使图像变得更加模糊,不能很好地去除噪声点。高斯滤波对于边缘噪声的去除效果欠佳。中值滤波可以很好地去除图像中的噪声点,但是在夜间的时候,由于光照强度反光等因素的影响,导致夜间车辆图像各像素点灰度值差距较大,利用中值滤波进行图像平滑导致滤波之后的灰度值变化较大,图像有些失真,尤其是车牌区域,字符的清晰较滤波之前反而变得更加模糊。因此,中值滤波运用于夜间车辆识别系统中还存在一定的缺陷。
本文首先将图像进行高斯滤波处理,对图像的像素点附近邻域的灰度值进行相应的加权平均,这样能有效地消除近似高斯噪声的噪声部分,然后对高斯滤波之后的图像采取中值滤波处理。既利用了中值滤波对图像平滑处理的优势,又解决了中值滤波在夜间对车牌识别的一定的缺陷。
1.3 车牌的边缘性检测
不同的图像灰度值是不同的,常规情况下边界处会有明显的边缘,利用此特征可以进行图像的分割。需要注意的是:图像的边缘并不等同于物体间的边界,图像中像素的值有突变的地方即为图像边缘,而物体间的边界是指在现实世界中真实存在与物体之间的边界。边缘存在的地方未必存在边界,同样,边界存在的地方不一定有边缘。现实场景中的物体是三维的,而图像只具有二维信息,从三维到二维的投影成像不可避免地会丢失一部分图像的信息;此外,光照和噪声对成像过程的影响也是不可避免。
常用的边缘检测算法:(1)Sobel算子;(2)Roberts算子;(3)Laplace算子;(4)Canny算子。设计选用Canny算子進行车牌图像的边缘性检测。图像边缘作为一种图像的基本特征,被应用于图像处理的实际案例中。图像的边缘检测是获得车牌轮廓的重要方式。车牌边缘特征明显,独立存在一定区域,并且中国车牌有着特有的背景和尺寸,对于车牌定位和边缘的提取都有很大的帮助。
1.4 图像二值化
图像的二值化,实际上就是把图像上的灰度值设置为0(黑)或白(255),目的是将图像的背景和前景分离,达到仅有黑白的视觉效果。将256个亮度等级的灰度图像通过适当的阈值选取,然后获得仍然可以反映图像整体和局部特征的二值化图像。灰度等级有256个,给我们呈现出不同色彩的视觉效果。本文是对车牌进行识别,首先我们要通过处理采集车牌图像中的信息,对车牌区域进行定位。因此,在进行车牌的边缘检测后,我们需要进一步进行二值化使车身和车牌分离。
本文选用Otsu算法(最大类间方差法也称“大津法”)进行图像二值化。其原理是利用图像的灰度特性,把灰度图像分成背景和前景(目标)两部分。背景和前景之间的类间方差越大,就说明构成图像的这两部分的差别越大,若部分目标被误分为背景或者部分背景被误分为目标,将会导致两部分差别变小。因此,使类间方差最大的分割意味着错分概率最小。
2 车牌定位
2.1 我国车牌的特点
我国的车牌是根据GA36-2014《中华人民共和国机动车号牌》的规定进行机动车的车牌底色和数字颜色的搭配。我国的机动车号牌的种类十分丰富,常见的有黄底黑字车牌、黑底白字车牌、蓝底白字车牌。其中尤为常见的为普通小汽车所挂的蓝底白字车牌,其长度是440MM,宽度是140MM,由7的字符和一个点分隔符组成,第一个字符为汉字,后面6位由字母和阿拉伯数字组成;车牌中每个字符的宽度都为45MM,高度都为90MM,车牌中第二个字符和第三个字符的间隔是35MM,其余相邻的字符间的距离都是15MM。
2.2 车牌定位算法
数学形态学是由一组形态学的代数运算子组成的,包括的基本运算有四个: 膨胀、腐蚀、开运算和闭运算,它们在二值图像和灰度图像中各有特点。在这些基本运算的基础上还可推导和组合出各种有关数学形态学实用算法。形态学处理文中主要应用了开运算和闭运算操作方式。在简述开、闭运算前需要对膨胀和腐蚀以简单介绍下。
膨胀:其实,膨胀就是求局部最大值的操作。按数学方面来说,其就是求局部最大值的操作。膨胀运算在填补图像各部分小图像的间隙处理方面非常有益。
腐蚀:腐蚀与膨胀是一对相反的操作。数学角度出发,腐蚀就是求局部最小值的操作。腐蚀运算可以有效地清除图像中无意义的杂乱小图像。
开运算是一种复合运算,其就是图像先进行一次腐蚀运算,对腐蚀后得到的图像再进行膨胀运算。
闭运算也算是一种复合运算,计算过程于开运算的顺序相反,先进行膨胀运算,再进行腐蚀运算。
3 车牌字符分割
字符分割环节是承上启下的部分,在上述的车牌定位得到大概的车牌区域后,接着需要把字符分割出来,进而继续进行下面的字符识别环节。车牌字符分割的目的就是,把定位到的车牌分割成8个区域,汉子和后面的6个字符,把点分隔符去除。只有字符精确的分割出来,在下一环节的字符识别中才能更加准确。也就是说,字符分割直接影响字符识别的结果。
3.1 车牌校正处理
车牌校正是车牌定位和字符分割不可或缺的环节。在车牌的抓拍过程中可能由于摄像头一定程度的倾斜,司机再挂车牌时造成一定的倾斜,或者由于车牌的损坏造成的获取的车牌图像存在一定程度的角度倾斜。车牌整体的倾斜直接导致了,车牌上字符的倾斜,字符间的间隔大小也发生了改变。所以这种倾斜不仅会给下一步字符分割带来困难,最终对车牌识别的正确率造成影响。因此,我们需要对车牌进行校正,车牌最常见的是水平水平方向的倾斜。常用的方法是Hough变换法和Radon变换法。本文使用了Hough变换法对车牌进行校正。
利用Hough变换进行车牌边框的检测,确定边框水平线的倾斜角度,根据倾斜角度,进行相应的旋转,获得校正后的图像。具体步骤如下:
(1)图像预处理。读取图像,转换为灰度图像,去除离散的噪声点。
(2)利用边缘检测,对图像中的水平线进行强化处理。
(3)基于Hough变换检测车牌图像的边框,获取倾斜角度。
(4)根据倾斜角度,对车牌图像进行倾斜校正。
3.2 字符分割预处理-边框去除
由于车牌定位时对位置的限制并不是十分精确,车牌的上下边框、铆钉等会有噪声产生影响字符分割的精确,为了提高分割准确度,在分割之前需要对车牌进行铆钉和边框的去除操作。文中采用统计白色像素点个数的方法去除车牌的上下左右边框。去边框后,如图所示。
3.3 字符分割
字符分割的方法有很多种,没有一种是万能的,我们应该视我们的实验而定。常用的字符分割的方法:基于投影法的字符分割、基于模板匹配的字符分割、基于字符轮廓的字符分割等等。文中所使用的字符分割算法为基于垂直投影的字符分割算法。
基于垂直投影的字符分割算法:利用车牌相邻字符间的空白间隔来对字符进行切割。其方法的主要流程为首先把处理后的车牌图像进行二值化处理,接着二值化处理;然后再对此图像在垂直方向上进行投影;通过投影,会形成一定的波峰和波谷,然后找到两峰之间的波点。
4 车牌字符识别
字符识别是车牌识别的最后一步,也可以说是整个车牌識别体系中最重要的一个环节,准确的识别字符,最终车牌的识别成功率才会提高。在车牌定位、车牌字符分割的成功铺垫下,在这一环节,我们只要选择一个合适的字符识别的算法,便可以高效、准确的识别字符。常见的字符识别的方法有:基于字符特征匹配的字符识别算法、基于神经网络的字符识别算法、基于支持向量机SVM的模式识别算法和利用模板匹配的字符识别。
本文利用模板匹配方法对车牌字符进行识别。其原理简单来讲就是创建一个字符库,把分割的车牌字符与库里的字符进行匹配。首先我们根据我国的车牌特征,创建一个字符库。序号0-9为阿拉伯数字0-9,序号10-35为26个英文字母,36-66为31个省市包括自治区的车牌标志(此处未包括香港、澳门自治区,台湾地区),如:北京“京”、安徽“皖”、上海“沪”等等。然后利用MATLAB软件进行算法的使用对车牌字符进行匹配。
5 总结与展望
通过运用图像图形处理的相关知识以及MATLAB的应用,完成了车牌识别的整个过程。文中把车牌识别概括为四大部分:车牌图像的预处理、车牌的定位、车牌字符分割和车牌字符识别,四个部分依次进行,环环相扣,每前一步的操作都影响着后一步的进行。文中应用了OTSU算法、Canny算子的边缘检测,相比的其他方法,对车牌识别的效率和成功率更高。
文中仅对常见的蓝色车牌进行了实验研究,对一些特殊的车牌(如:警用、部队、大使馆以及新能源等等)还需要进一步的改进和探究。在最后一步的字符识别中,还存在一定的错误,比如把“0”识别成了“O”。后面还需要进行更多的试验,进而是车牌识别的成功率更上一层楼。
参考文献:
[1] 顾李云.基于图像处理的车牌识别算法的研究与设计[D].南京邮电大学,2018.
[2] 孙春泉.车牌识别中关键算法的研究与改进[D].安徽理工大学,2018.
[3] 黄辰阳.基于图像处理的车牌识别方法研究[D].广东工业大学,2018.
【通联编辑:代影】
