
大数据量TLV文件快速解析程序设计及应用
2019-09-24 02:00孙立哲
电脑知识与技术 2019年19期
孙立哲

摘要:基于某产品测试实际需求,为了实现对大数据量TLV(Type,Length,Value)文件数据正确性的快速自动校验,采用Java编程语言,基于面向对象技术以及内存映射技术,完成了对具有二级嵌套结构型的大数据量TLV文件解析程序设计。在实际应用中,该程序针对内含十万条记录的约50MB的TLV文件,其解析速率可达到提取单条记录平均耗时在毫秒级,可以满足快速解析大数据量TLV文件以便进一步作数据正确性校验的需求。
关键词:TLV文件;快速解析;内存映射文件;面向对象技术;Java编程
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)19-0016-04
Abstract: From the actual requirements of a product test, in order to achieve the rapid automatic verification for the data correctness of the large amount of data TLV file, this paper using Java programming language, based on object-oriented technology and memory mapping technology, designed a program for parsing TLV file including a large amount of data with a nested structure. In practical application, for a TLV file with the size of 50MB and containing one hundred thousand records, the parsing rate of the program can reach the extraction of a single record average time in milliseconds. It can satisfy the need of quickly analyzing large amount of data TLV files for further data correctness verification.
Key words: TLV format file; fast parsing; memory-mapped file; object-oriented technology; java programming
抽象语法标记[1](ASN.1)是一种ISO/ITU-T标准,描述了一种对数据进行表示、编码、传输和解码的数据格式。TLV文件是指采用标准化编码规则[2](如基本编码规则,BER)对ASN.1所描述的数据进行Tag、Length和Value三元组编码后所形成的数据文件。BER编码有两种方式。一种是定长编码方式,由三部分组成,分别对应TLV中的Tag、Length、Value。另一種是不定长编码方式,由四部分组成,比定长编码多一个结束标记字段[3]。每种类型都能编码成定长编码方式。Tag字段是关于标签和编码格式的信息,Length字段定义Value数值的长度,Value字段表示实际的数值。编码可以是基本型或结构型[4]。如果编码值的Value字段为基本数据类型,则属基本型。如果编码值的Value字段中嵌套有TLV结构数据,则属结构型。根据编码规则,结构型编码值的Tag字节高四位数值为E,低四位数值代表嵌套层级。
某产品的合作双方之间采用TLV文件进行数据传输,单个TLV文件大小基本在几十兆字节,数据量一般在十万。在TLV文件提供方完成数据文件生成后,进行文件传输前需对文件内数据进行正确性校验。因为文件数据量比较大,且数据本身生成规则比较复杂,单纯以手工方式进行校验,完成全部校验耗时极长。为了实现对大数据量TLV文件数据正确性的快速自动校验,需要实现从TLV文件中快速提取各条数据。在大数据量文件处理方面,内存映射文件方法[5]提供了一种高效文件操作途径。基于内存映射文件方法,应用程序可以通过内存指针对磁盘上的文件进行访问,其过程如同对加载了文件的内存进行访问,不必执行文件I/O操作,也无需对文件内容进行缓冲处理。由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等操作,内存映射文件方法在处理大数据文件时表现出显著的速度优势[6-7]。本文基于面向对象技术[8]以及内存映射技术,在Eclipse开发平台[9]采用Java编程语言,完成了对具有二级嵌套结构型的大数据量TLV文件解析程序设计。经过对内含十万条记录的49.6MB的TLV文件进行实践解析,验证了其解析速率可达到提取单条记录平均耗时在毫秒级,基于此实现了对大批量数据正确性的快速校验,进而完成了对该产品的功能自动化测试。
1 TLV文件数据结构实例简介
某产品生成的TLV文件内含有记录条目总数、各记录数据以及其共有数据,各数据以二级嵌套结构型TLV编码值组成。一级嵌套结构的Tag标签和二级结构嵌套的Tag标签均为一个字节表示,该字节对应的十六进制字串表示分别记为E1和E2。一级结构的Value值中含记录条目总数itemCount、各记录数据的共有数据pubData1(可有一条或多条)以及顺序排列的各记录数据Item。记录条目总数itemCount和共有数据pubData1均为基本型TLV编码数据,每个Item记录数据均为一个结构型TLV编码数据,即该TLV文件中的二级结构数据。Item记录数据的Value由多个基本型itemData编码数据组成。二级嵌套结构的TLV文件完整数据结构实例如图1所示。
Length值采用BER编码规则的定长编码方式。Value值的字节长度小于等于127时,采用短型长度表示法。Value值的字节长度大于127时,采用长型长度表示法。短型长度表示法的Length字段由一个字节组成,最高位为零,其余位表示长度值。长型长度表示法的Length字段由多个字节组成,第一个字节最高位为一,其余位表示存放长度所占字节数,其余字节存放长度值。
2 大数据量TLV文件解析程序设计
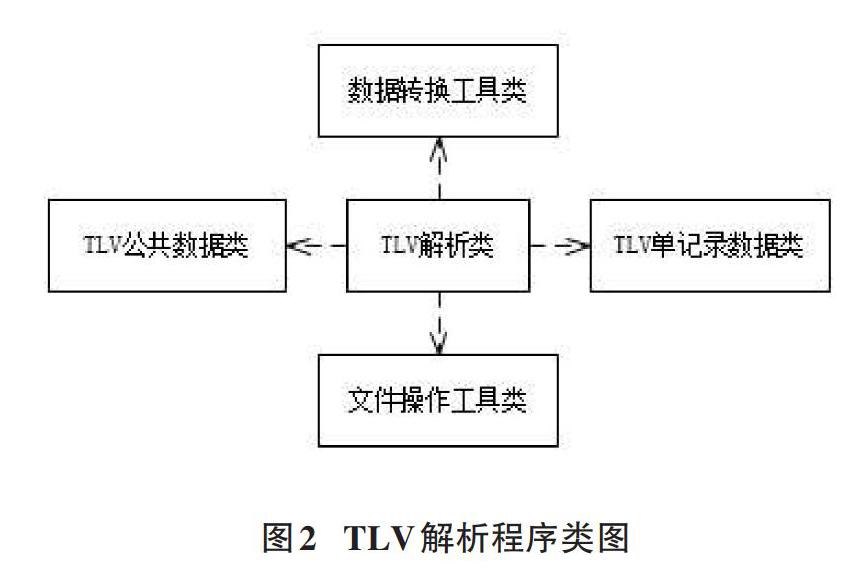
本文针对特定二级嵌套结构型数据文件的TLV解析程序,主要由五个类构成,分别为TLV公共数据类、TLV单记录数据类、TLV解析类、数据转换工具类和文件操作工具类。TLV解析程序类图如图2所示。
TLV公共数据类是实体类,内含记录总数属性、公共数据串属性、公共数据串长度属性以及分别对各属性进行设置的Setter方法和读取的Getter方法。TLV公共数据类用于存放解析过程中从TLV文件中读取的记录总数和公共数据。
TLV单记录数据类是实体类,内含各数据串属性及其长度属性以及分别对各属性进行设置和读取的方法。TLV单记录数据类用于存放解析过程中从TLV文件中读取的单条记录下的各数据。数据串属性个数与TLV单记录中所含数据个数保持一致。
TLV解析类内含待解析TLV文件名配置属性、解析后文件存储目录属性、MappedByteBuffer类对象buffer属性、TLV公共数据类对象tlvPubInfo属性、TLV单记录数据类对象tlvItem属性、TLV单记录起始位置索引值tlv_Item_Index属性、下一个TLV单记录起始位置索引值tlv_NextItem_Index属性、主函数方法、初始化方法、TLV解析方法、获取TLV公共数据方法、获取单记录数据方法、根据Tag索引值获取TLV中长度和数值方法、写TLV公共数据到二进制文件方法和写单记录数据到二进制文件方法。所有属性变量均为静态成员变量。主函数方法是整个解析程序的入口。初始化方法用于对待解析TLV文件名配置属性和解析后文件存储目录属性进行初始化。TLV解析方法内部通过实例化RandomAccessFile类对象并调用其getChannel方法從待解析TLV文件获得一个FileChannel类对象,再调用FileChannel类对象的map方法将文件映射到内存MappedByteBuffer类对象(ByteBuffer类的子类)缓存,通过调用ByteBuffer类的get方法按位置逐字节读取文件数据。获取TLV公共数据方法用于从TLV文件中读取公共数据并存于TLV公共数据类对象,获取首个单记录Tag位置索引值并存于tlv_Item_Index属性。获取单记录数据方法用于根据tlv_Item_Index属性值从TLV文件中读取单个记录的数据并存于TLV单记录数据类对象,获取下一个单记录Tag位置索引值并存于tlv_NextItem_Index属性,更新tlv_Item_Index属性值为tlv_NextItem_Index属性值。根据Tag索引值获取TLV中长度和数值方法供获取TLV公共数据方法和获取单记录数据方法调用,该方法内部实现根据TLV中Tag字节所在位置索引值读取该TLV中Length所占字节数、Length数值和Value数据值。写TLV公共数据到文件方法和写单记录数据到二进制文件方法分别用于将TLV公共数据类对象数据和TLV单记录数据类对象数据写入指定目录下的二进制文件。
文件操作工具类完成解析过程中文件夹创建以及各文件的创建与写入。文件操作工具类内含创建目录方法和写二进制文件方法。创建目录方法先判断目录是否存在,若不存在则新建,若存在则使用已有目录。写二进制文件方法实现将已知长度的二进制数据写入给定文件名的文件中。数据转换工具类用于完成在解析过程中所需的各数据转换。数据转换工具类内含将ASCII码十六进制字串转为数据字串方法、将单字节转为两字符的十六进制字串方法、将十六进制字串转为字节数组方法和将字节数组转为十六进制字串方法。
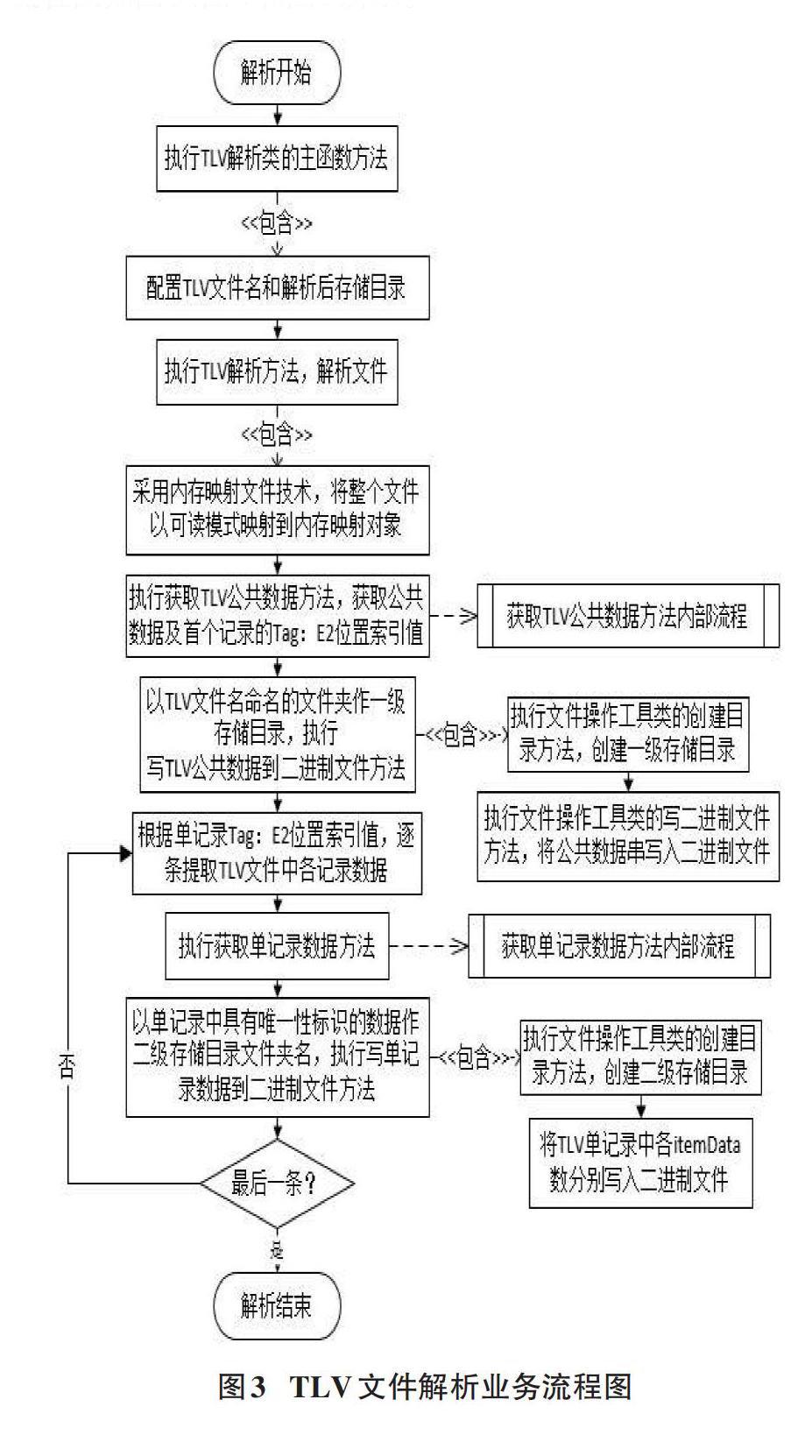
在完成TLV文件到内存对象映射后,根据文件数据二级嵌套结构特点,依次逐字节进行解析。从一级嵌套结构中提取公共信息、记录总数以及首个二级嵌套结构Tag索引位置。从首个二级嵌套结构Tag索引位置开始依次提取单记录下各数据。解析过程中Value数据根据Length字段数据特点进行提取,具体实现:根据Tag标签所在索引位置确定Length字段首字节所在索引位置,根据Length字段首字节高四位判断Value值长度是否大于127。若Value值长度不大于127,则从Length字段所在索引位置的下一个字节开始提取指定长度的Value数据。若Value长度大于127,则根据Length首字节低四位判断Length字段其余字节个数及对应的长度值,然后从Length字段首字节所在索引位置加长度值所占字节个数后所得索引位置的下一个字节开始提取指定长度的Value数据。结构型编码值中,Value值中嵌套一个或多个子TLV编码值的情况下,嵌套的首个TLV编码值的Tag标签索引位置为结构型编码值的Tag标签所在索引位置加其Length字段所占字节数后所得位置索引值的下一个字节所在位置,非首个TLV编码值的Tag标签索引位置与首个相比,还要再顺延首个TLV编码值中Value值长度个数的字节。解析过程中创建两级文件夹目录,一级文件夹目录名以TLV文件名命名并存于解析前配置的存储目录下,二级文件夹目录名以单记录数据中具有唯一性标识的字段值命名,存于一级文件夹目录下。有多少条Item记录,则创建多少个二级文件夹目录。一级文件夹下存放用于记录公共信息pubData1的数据文件。二级文件夹目录下存放该Item记录下各itemData数据文件,一个itemData对应一个数据文件。整个解析过程业务流程图如图3、图4和图5所示。
3 TLV文件解析程序在实际产品测试中的应用
TLV文件数据结构实例简介中所提及的产品,其主要功能是按某种规则生成各种数据存于数据库,再从数据库按一定规则提取相应数据生成TLV文件,以便于在网络上进行数据传输。针对该产品若要实现各数据正确性自动化校验,需要完成三个环节的自动化代码设计,这三个环节按顺序分别是检查数据库中各数据是否正确、解析TLV文件提取各数据和对TLV中各数据与数据库中各数据作一致性对比。
本文的TLV解析程序即对应第二个环节。执行该TLV解析程序,对内含十万条记录的49.6 MB的TLV文件进行解析,整个解析过程耗时约为16分钟,即提取单条长度为521字节的记录数据平均耗时为9.6毫秒。解析耗时少,速度快。
将该解析程序集成到产品功能自动化测试脚本中,即在对数据库各数据正确性作比对后,通过实例化TLV解析类对象并调用对象的TLV解析方法进行TLV文件解析,最后分别读取解析后存于磁盘中的各数据文件中数据与数据库中对应数据作一致性对比,从而实现整个数据正确性校验过程的全自动化执行。解析后所得的各数据可全部完成对比校验,且校验结果准确率为百分百。
该解析程序是基于已知二级嵌套结构型TLV文件数据结构定制开发的,暂不具有普适性。若要使其具有一定的通用性,可在此基础上作扩展改进。比如,若待解析TLV文件中数据不确定是否有嵌套结构型,或不知有几层嵌套结构,可根据每个TLV编码值的Tag字节的高四位是否为E判断其是否为嵌套结构型,然后参照本文解析程序业务处理流程中所提及的关于Length字段的判断等作后续分析。针对嵌套结构型TLV编码值,继续根据其Value字段中的Tag判断是否有次级嵌套结构型,依次类推,最终判断出嵌套层级。每增加一个嵌套结构,则按嵌套关系增加一级对应的文件夹目录,用于存储该嵌套结构下的各数据字段。对于在同一嵌套层级结构下不确定有多少个TLV编码值的情况,可采用基于cglib动态创建类及动态添加类成员属性的方式[10],针对该层级在程序执行过程中动态创建对应的类及属性。
4 结语
本文从某产品测试实际需求出发,为了实现对大数据量TLV文件数据正确性的快速自动校验,采用Java编程语言,基于面向对象技术以及内存映射技术,完成了对具有二级嵌套结构型的大数据量TLV文件解析程序设计,并将该程序集成到产品功能自动化测试中,完成了大批量数据的快速校验,校验耗时少,速率快。
参考文献:
[1] International Telecommunications Union. ISO/IEC 8824-1, Information technology—Abstract Syntax Notation One (ASN.1): Specification of basic notation [S]. Geneva, Switzerland: ITU-T, 2015.
[2] International Telecommunications Union. ISO/IEC 8825-1, Information technology—ASN.1 encoding rules: Specification of Basic Encoding Rules (BER), Canonical Encoding Rules (CER) and Distinguished Encoding Rules (DER) [S]. Geneva, Switzerland: ITU-T, 2015.
[3] 娜仁. 一种嵌套数据格式的描述文法及其解析工具的设计与实现 [D]. 北京邮电大学,2018.
[4] 王沁,許娜,张燕,等. 优化TLV编码规则[J]. 计算机科学,2008,35(11):104-261.
[5] Cay S. Horstmann. Java核心技术 卷I:基础知识 [M]. 周立新,陈波,等译. 10版. 北京:机械工业出版社,2016.
[6] 杨宁学,诸昌钤,聂爱丽. 内存映射文件及其在大数据量文件快速存取中的应用 [J]. 计算机应用研究,2004(8):187-188.
[7] 于慧彬,齐鹏,梁捷,等. 内存映射文件在大数据量海洋调查数据处理中的应用 [J]. 海洋技术,2010,29(1):32-35.
[8] 丁任霜. 面向对象设计与应用[M]. 1版. 北京:北京大学出版社,2011.
[9] Eclipse Foundation. Eclipse [EB/OL]. [2006-6-2]. https://help.eclipse.org/2019-03/index.jsp
[10] 孙艺博,陈英,高晨红. 基于CGLIB的AOP动态实现机制[J]. 计算机工程与设计,2005,26(11):3118-3120.
【通联编辑:梁书】
