
改进的频繁模式挖掘算法①
2019-09-24 06:21:18魏恩超张德生安平平
计算机系统应用 2019年9期
魏恩超,张德生,安平平
1(西安理工大学 理学院,西安 710054)
2(西北师范大学 教育学院,兰州 730070)
数据挖掘(DM,Data Mining)是近年来研究、开发和应用最活跃的一个领域,它是在机器学习、神经网络和模式识别的理论基础上发展而来的,其任务是从海量数据中提取隐含且用户感兴趣的知识和信息[1].
关联规则挖掘是数据挖掘中最重要的研究领域之一,其本质是对频繁模式的挖掘,最早由Agrawal 等提出[2],目的是发现模式之间隐含的内在联系,为后续问题的解决提供决策支持.关联规则挖掘主要包含两个子问题:一是生成频繁模式集,其任务是根据用户设置的最小支持度阈值生成所有频繁模式;另一个是生成关联规则,主要任务是从所有的频繁模式中提取满足最小置信度阈值的规则.
频繁模式挖掘算法大致可分为两类:一种是类Apriori 算法,如文献[3]提出了Inter-Apriori 频繁模式挖掘算法,该算法使用交集策略来减少扫描数据库的次数,使算法达到了较高的效率;文献[4]提出了一种基于三角矩阵和差集的垂直数据格式挖掘频繁模式的算法;文献[5]提出了一种基于前缀项集的候选集存储结构,并利用哈希表进行快速查找,提高了经典Apriori算法在连接步和剪枝步中的效率;文献[6]提出了一种基于矩阵的改进算法,通过事务矩阵和候选项集项目矩阵相乘的矩阵操作改进频繁扫描数据库的问题,优化了Apriori 算法的连接步与剪枝步.这些算法都是由经典的Apriori 算法改进而来,由于Apriori 算法的固有缺陷,使得这些算法的挖掘效率仍然不高.另一类是基于频繁模式增长的算法,如文献[7]提出了一种基于频繁模式树(FP-tree)的FP-growth 算法;文献[8]提出了一种基于COFI-Tree 挖掘N-最有兴趣项集算法,该算法采用COFI-Tree 结构,无需递归构造条件子树FPTree;文献[9]提出了一种基于邻接表的改进FP-Growth算法,该算法使用哈希表存储邻接表,可以快速删除小于最小支持阈值的模式.这类算法利用树结构对数据库进行压缩,不产生候选项集,减少了数据库的扫描次数,但在对大型稠密数据集进行挖掘时会构造大量条件模式基和条件FP-tree,对内存消耗非常大.
为克服前两类算法的局限性,一些研究人员将Apriori 算法和FP-tree 结构结合[10-14].这类算法先将整个数据库投影到FP-tree 上,然后对FP-tree 进行分区,将数据库划分成若干个子数据集,最后利用Apriori 算法的候选生成-测试机制对子数据集进行挖掘.文献[10]首次将Apriori 算法与FP-tree 结合,提出了相应的APFT 算法,该算法不需要递归地生成条件模式基和条件FP-tree,有效提高了挖掘效率.文献[11]在FP-tree 的基础上提出了压缩频繁模式树(CFP-tree),并从最不频繁的项开始划分生成子树,并在每棵子树上执行候选项集生成机制,算法避免了递归生成大量子树,提高了模式挖掘速度;文献[12]利用频繁1-项集对数据库进行分库,统计候选项集支持度计数时只扫描分库,减少了Apriori 算法对数据库的遍历次数;文献[13]提出了一种改进的基于fp-tree 的Apriori 算法,该算法先用尾元将fp-tree 分区,生成数据量更小的子数据集,再动态删除冗余数据将子数据集进一步压缩,最后通过扫描子数据集进行支持数统计;文献[14]将Apriori 算法与FP-growth 算法结合,提出了一种基于事务映射区间求交的频繁模式挖掘算法IITM,只需扫描数据集两次来生成FP-tree,然后扫描FP-tree 将每个项的ID 映射到区间中,通过区间求交进行模式增长.但将FP-tree 结构与Apriori 算法结合后仍存在以下不足:(1) Apriori算法在连接步会花费大量时间判断项集是否满足连接条件;(2) 构建FP-tree 时需要对数据库进行两次扫描,且不支持交互式挖掘与增量挖掘.
为解决这些问题,本文在APFT 算法的基础上提出了一种改进的频繁模式挖掘算法.主要进行了如下改进:(1)在算法的连接步前加入预处理过程,减少比较次数;(2)提出了一种新的紧凑前缀树结构,只需对数据库进行一次扫描就可以构造出一棵紧凑的模式树,且支持交互式挖掘与增量挖掘,能有效处理数据流问题.
1 问题陈述
1.1 频繁模式挖掘
设I={I1,I2,···,Im}是所有项的集合,不失一般性,I中的项按字典顺序排列,即I1<···<Im.T为一个事务,每个事务都由唯一的标识符TID和与之对应的项集Item(T)(Item(T)⊆I)构成,所有事务构成了事务数据库D,D中包含事务的个数称为数据库的大小,记为S ize(D).设X⊆I为一个项集,项集中包含项的个数叫做项集的长度,记为Length(X),即Length(X)=|X|,长度为k的项集称为k-项集.事务T包含项集X,当且仅当X⊆Item(T),项集X的支持度计数 σ (X)定 义为数据库D中包含项集X的事务数,即σ (X)=|{T|T∈D∧X⊆Item(T)}|,项集X的支持度sup(X) 定义为包含项集X的事务在数据库D中所占的比例,即sup(X)=σ(X)/S ize(D).项集X为频繁模式,当且仅当sup(X)≥minsup,其中minsup为给定的最小支持度阈值,长度为k的频繁项集称为频繁k-项集,记为Fk.
频繁模式挖掘定义为,在给定的数据库D和最小支持度阈值minsup条 件下,找出所有频繁模式FI=F1∪F2∪···∪Fl,l为频繁模式的最大长度.
1.2 Apriori 算法
Apriori 算法[2]最早由Agrawal 等提出,该算法使用先验性质压缩搜索空间,并使用一种逐层搜索的迭代方法,其中k-项集用于探索(k+1)-项集.Apriori 算法主要包含以下3 个步骤:
连接步:这一步主要是为了生成候选k-项集Ck,设l1和l2是频繁(k-1)项 集Fk-1中 的项集,记号li[j]表示li的第j项,项集中的项按字典顺序排列,如果有(l1[1]=l2[1])∧···∧(l1[k-2]=l2[k-2])∧(l1[k-1]<l2[k-1]),则连接l1和l2生成候选k-项集Ck,其中Ck={l1[1],l1[2],···,l1[k-1],l2[k-1]}.
剪枝步:利用频繁项集的反单调性对候选k-项集Ck进行剪枝,生成频繁k-项集Fk.如果候选k-项集的一个(k-1)项 子集不在Fk-1中,则该候选项集为非频繁项集,否则需要遍历数据库进行支持数统计,进一步验证Ck是否频繁.
统计支持度计数:扫描数据库D,对候选k-项集Ck在数据库中出现的次数进行累加,根据给定的最小支持度阈值minsup生成频繁k-项集.
1.3 FP-tree 结构
为克服Apriori 算法的缺陷,韩家炜等提出了基于FP-tree 的FP-Growth 算法[7],该算法只需对数据库进行两次扫描,且不产生候选项集,FP-tree 结构能对数据库进行有效压缩.
FP-tree 中每个节点由4 个域组成:项标识itemname、节点计数item-count、节点链item-link和父节点指针item-parent.同时为了方便对树进行操作,FPtree 还包含一个频繁项头表header-table,它由两个域组成:项标识item-name和项元链链头node-link,其中node-link 是指向FP-tree 中具有相同项标识的首节点指针,FP-tree 中实线是父节点指针,虚线是节点链.FPtree 相关概念及结构细节见文献[1].使用表1中的示例数据生成的FP-tree 如图1所示,设最小支持度阈值minsup=3.

表1 样例数据集

图1 FP-tree 结构
1.4 APFT 算法
APFT 算法[10]使用Apriori 算法挖掘基于FP-tree的频繁模式,该算法仍采用分治策略.APFT 算法主要包括两个步骤,第一步是利用FP-growth 算法中构造树的方法构造FP-tree;第二步是利用Apriori 算法挖掘FP-tree.在第二步中,需要添加一个名为N Table的附加节点表,表中的每个项由两个域组成:Item-name和Item-support.Item-name 表示在条件子树FPTj(j=1,2,···,n)中 节点的名称,I tem-support表示与频繁1-项集Ij(j=1,2,···,n)一起出现的节点数,即项的支持度计数.APFT 是最早将Apriori 算法与FP-tree 结合的算法,但由于Apriori 算法与FP-tree 自身的缺陷导致该算法仍存在一些不足,因此本文对APFT 中的连接步与树构造方法进行了改进,使算法能有效处理数据流问题.APFT 算法的伪代码如算法1 所示.

算法1.APFT Input: FP-tree,minsup Output: all frequent patterns L 1) L=L1;Ij 2) for each item in header table,in top down order LI j=Apriori-mining(Ij)3);L=L∪LI1∪LI2∪···∪LIn 4) return;Apriori-mining(Ij)Pseudocode 1) Find item p in the header table which has the same name with;q=p.tablelink I j 2);3) while q is not null 4) for each node qj!=root on the prefix path of q 5) if NTablehas a entry N such that N.Item-name=qj.item-name N.Item-support=N.Item-support+q.count 6);7) else NTable 8) add an entry N to the;N.Item-name=q j.item-name 9);N.Item-support=q.count 10);q=q.tablelink 11);k=1 12);Fk={i|i∈NTable∧i.item-support≥minsup}13) 14) repeat k=k+1 15);Ck=apriori-gen(Fk-1)16);q=p.tablelink 17);18) while q is not null t of q 19) find prefix path Ct=subset(Ck,t)20);c∈Ct 21) for each c.support=c.support+q.count 22);q=q.tablelink 23);Fk={c|c∈Ck∧c.support≥min_S up}24) 25) until Fk=Ø 26) return LIi=Ii∪F1∪F2∪···∪Fk
2 改进算法
2.1 算法改进思想
为了提高基于FP-tree 的Apriori 算法的挖掘效率,从进一步缩减数据库扫描次数以及增强算法的交互式挖掘与增量挖掘的方向改进.首先,将Apriori 算法的apriori_gen()函数中的连接步进行优化.由于连接步需要大量比较步骤,并且会产生大量无用的候选项集,因此增加了后续剪枝步和支持度计数步的时间开销.其次,将CP-tree[15]进行扩展,提出了一个新的树结构ECP-tree(Extension of Compact Pattern tree).由于在构造CP-tree 的过程中包含所有项,不论是频繁项还是非频繁项都参与了树的构造,因此占用了大量的内存空间,并且会影响频繁模式的挖掘效率.在新构造的ECP-tree 中只包含频繁项,删除了非频繁项,并且只经过一次数据库扫描就可以构造出一棵紧凑的前缀树,新构造的树结构不仅支持交互式挖掘而且也支持增量挖掘.
2.2 优化连接步
在给出优化思想之前,首先了解两个关于集合的性质.
性质1.包含k个不同项的k-项集有k个不同的(k-1)项子集;
性质2.假设I 为k-项集中的一个项,根据性质1 可得,在k个子集中必有(k-1)个子集包含项I.
在Apriori 算法的apriori_gen()函数的连接步中,需要进行多次前(k-1)项的比较,这大大增加了算法的时间开销.经研究发现,存在这样一个性质:
性质3.假设I 为频繁k-项集Fk中的一个项,如果包含I 的频繁k-项集还能产生频繁(k+1)- 项集,则包含I 的频繁k-项集的总数不小于k.如果项集总数小于k,那么Fk就不用参与后续的连接步.证明过程如下:
反证法:假设包含项 I的Fk参与了后续的连接步,那么就会生成包含项I 的候选(k+1)-项集Ck+1.如果候选项集Ck+1不 被删除,则必须满足Ck+1的k+1 个k项子集必须都是频繁的,即这k+1 个k项子集必须在频繁k-项集中,根据性质2 可得,在k+1 个k项子集中有k 个子集包含项I,也就是说包含项I 的项集总数不小于k.反之,如果包含项I 的项集总数小于k,那么连接生成的Ck+1必然会被剪掉.
根据性质3,可对连接步进行优化,在连接之前进行预处理,删除不满足条件的Fk.预处理过程的伪代码如下所示:

算法2.Pretreatment Input:频繁k-项集Fk Output:满足连接条件的频繁-项集Fi∈Fk kLk 1) for each items 2) for each item I∈Fk I∈Fi 3) if 4) I.count++5) for each item I.count<k I∈Fi 6) if 7) delete from Lk FiFk 8) return
为了说明优化流程,用以下示例说明具体过程.假设表2是事务数据库产生的所有频繁3-项集F3.

表2 所有频繁3-项集
在原始Apriori 算法中,保留所有频繁3-项集进入连接步,连接产生的候选4-项集C4(未剪枝的候选项集)如表3所示.
如表3所示,表2中的12 个频繁3-项集连接后共产生16 个候选4-项集,根据剪枝原理,剪枝后剩下的候选4-项集只有{I2,I3,I4,I10}.只有这一个候选4-项集进入支持度计数步.连接步的预处理过程如下所示:
第一步:计算表2中12 个频繁3-项集中每一个项的计数,结果如表4所示.
第二步:由表4可知,项I1、I5、I6、I7、I8、I9的计数小于k(即,3),因此对所有包含项I1、I5、I6、I7、I8、I9的频繁3-项集F3进行剪枝,剪枝后的频繁3-项集L3如表5所示.预处理后只剩4 个频繁3-项集,按照连接规则将这4 个频繁项集进行连接,生成一个候选4-项集{I2,I3,I4,I10},对这个候选项集进行剪枝操作,没有被剪掉,进入支持度计数步.预处理后的结果与原始Apriori 算法结果相同,故预处理步骤是合理的.

表4 频繁3-项集中每个项计数

表5 预处理后的频繁3-项集
2.3 新树的构造
新树的构造主要包括两个阶段:1)插入阶段;2)重构阶段.在插入阶段,通过逐一扫描数据库中的事务项集,根据项在事务中出现的先后顺序将它们插入树中.由于将事务插入树中时,它维护 I-list 并更新I -list中各个项的支持度计数,因此,在插入所有事务后,树结构在I -list中具有数据库中所有项的支持度计数.在重构阶段,根据项的支持度计数以降序方式重新排列I-list,只保留频繁项,即支持度大于等于用户指定的最小支持度阈值的项,并根据新排列的I -list重新构造树节点.在树重构中,使用分支排序方法(BSM,Branch Sorting Method)[15],该方法逐一对未排序的路径进行排序并按项的支持度计数降序排列I -list实现重构.
本文对分支排序方法(BSM)进行了改进,使该算法能够适应新提出的树结构.在改进方法中,如果路径没有按照新的排序顺序进行排序,则将该路径删除,并删除非频繁的项,将剩余的频繁项按排序顺序排列到一个临时数组中,最后再按顺序插入树中,重复此过程最终将得到一棵紧凑的模式树.改进的分支排序方法(IBSM,Improve Branch Sorting Method)的伪代码如算法3 所示.

算法3.IBSM Input:T和I Output:仅包含频繁项的Tsort和Isort 1) Compute Isort from I in frequency-descending order using merge sort technique 2) for each branch Bi in T 3) for each unprocessed path Pj in Bi 4) if Pj contains only frequent items in order according to Isort 5) Process_Branch(Pj)6) else Sort_path(Pj)7) Terminate when all the branches are sorted and output Tsort ang Isort.8) Process_Branch(P){9) for each branching node nb in P from the leafP node≠10) for each sub-path from the leafk with k p 11) if item ranks of all nodes between nb and leafk are greater than that of nb 12) P=sub-path from nb to leafk 13) if P is contains only frequent items in order according to Isort 14) Process_Branch(P)15) else P=path from the root to leafk 16) Sort_path(P)17) }18) Sort_ path(Q){19) Reduce the count of all node of Q by the value of leafQcount 20) Delete all nodes contains infrequent items and sort remaining nodes in an array according to Isort order 21) Delete all nodes having count zero from Q 22) Insert sorted Q into T at the location from where it was taken 23)}
为了更好地理解改进树重构方法的工作原理,使用表1给出的样例数据库进行详细说明,设最小支持度阈值minsup=3.图2为插入阶段后的树结构T和项列表I,此过程与原始分支排序方法中的插入阶段略有不同.由于项列表I和前缀树T 没有按项的支持度计数降序排列,因此,为了使用IBSM 以项的降序重构树,首先对I 进行排序以生成只包含频繁项的新列表Isort,如图3所示.重构从树的第一个分支开始,即最左边的分支,从图2所示树的根节点开始.由于分支的第一个路径 {f:1,a:1,c:1,d:1,g:1,i:1,m:1,p:1}是一个未排序的路径,因此将该路径从树中移除,移除后的树如图4所示,将移除的路径存放在一个临时数组中并按Isort中项的顺序对余下的频繁项进行重新排列,排序后的路径为{ f:1,c:1,a:1,m:1,p:1},如图5所示.然后再按顺序插入树中,图6显示了第一个路径排序完成后的树结构.重复此过程,直到所有路径都完成排序,图7显示了重构后的最终树.

图2 插入阶段后的I和T
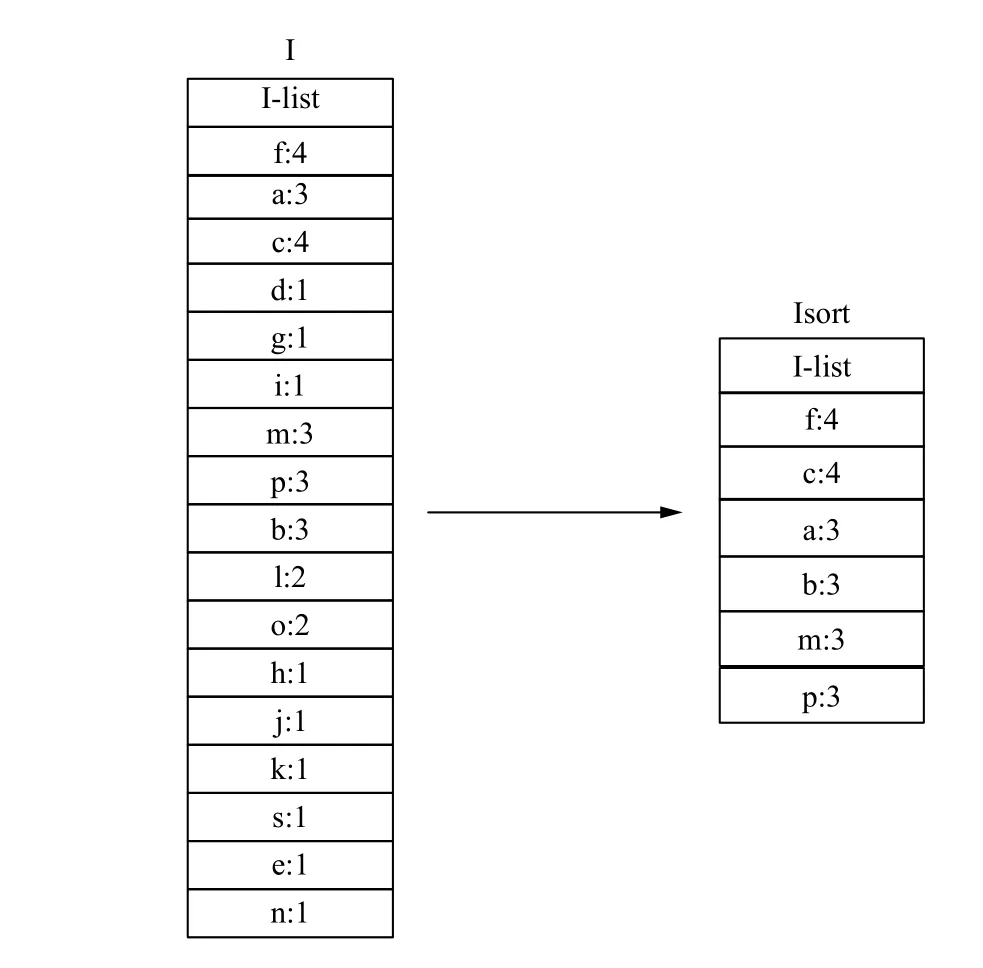
图3 重排I 构造Isort
新提出的树结构只需对数据库进行一次扫描,就可以构造出一棵与FP-tree 完全相同的树.新的树结构支持交互式挖掘,在交互式挖掘中,用户可以为同一个数据库更改指定的最小支持度阈值.在这种情况下,我们可以在插入所有事务后保存树,然后根据用户指定的最小支持度阈值重构树,在I -list中保存着所有项的总支持度计数,可以根据不同的最小支持度阈值只保留频繁项,而不需要重新扫描数据库.因此,新提出的树结构不需要像FP-tree 那样重新扫描数据库以实现交互式挖掘.新的树结构也支持增量挖掘,在增量挖掘中,可以对原始数据库中的事务进行添加和/或删除.在这种情况下,我们可以在原始数据库中插入所有事务后保存树,当添加新事务和/或删除一些旧事务时,可以在树中添加新事务的分支并且删除那些被删除的事务分支,重构树不需要像FP-tree 那样再次扫描原始数据库.
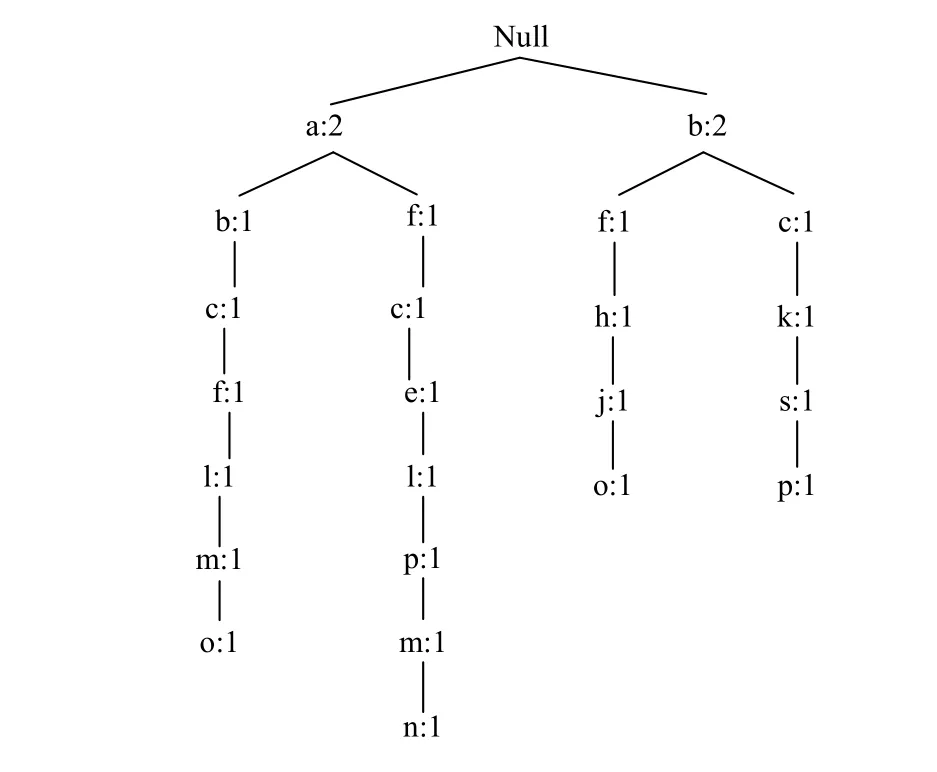
图4 移除未排序路径

图5 在临时数组中对路径排序
3 实验分析
为验证所提方法的有效性,将改进方法运用到APFT 算法中来挖掘频繁模式,且与原始APFT 算法、FP-Growth 算法以及Apriori 算法进行比较.本文算法实验平台为:Intel Core i7-4790 CPU 3.6 GHz 处理器和8 GB 内存,Windows 10 64 位操作系统,开发软件为Matlab R2014a.实验所用的数据集有两个,mushroom数据库和T10I4D100K 数据库,均可从http://fimi.ua.ac.be/data/.下载,数据集的特征如表6所示.本文分别在这两种数据集上进行对比试验,每组试验的参数都是不变的,都是通过改变最小支持度阈值从而记录算法的运行时间,算法运行的时间越小代表算法的挖掘速度越快.

图6 将排序后的路径插入T 中

图7 重构后的最终树

表6 数据库特征
在相同条件下,算法独立实验10 次,取其运行时间的均值作为算法最终结果.两个数据集在不同算法和不同最小支持度阈值下的运行时间对比如表7和表8所示,单位为秒(即,s).从表中可以看出,本文改进算法在运行时间上明显优于其他几个算法,说明本文改进算法有效提高了频繁模式的挖掘速度.从图8和图9中可以看出本文改进算法比原始APFT 算法更高效,主要原因有两个:1)在算法的apriori_gen()函数前加入了连接预处理步骤,对进入连接步的频繁k-项集进行剪枝,减少了两两频繁项集前(k-1)项的比较次数,因此减小了连接步的时间消耗,并且候选项集的数量也减少了,减小了剪枝步的时间开销;2)新提出的树构只需对数据库进行一次扫描就可以构造出一颗紧凑的模式树,虽然增加了树重构过程但这一过程基本上不会花费太多时间,并且在挖掘过程中不需要额外的空间,因此本文改进算法具有更好的空间可扩展性.

表7 mushroom 上不同算法运行时间对比

表8 T10I4D100K 上不同算法运行时间对比

图8 mushroom 上运行时间对比

图9 T10I4D100K 上运行时间对比
4 结束语
本文针对传统频繁模式挖掘算法存在的固有缺陷,提出了一种基于APFT 算法的改进频繁模式挖掘算法.首先,在算法的连接步前加入预处理过程,对参与连接的频繁k-项集进行有效剪枝,大大减少了连接步与剪枝步的时间开销;其次,对CP-tree 进行扩展提出了一种新的树结构ECP-tree,新的树结构是一棵紧凑的前缀模式树;然后,再将改进点与APFT 算法结合用于频繁模式挖掘;最后,利用实验验证了改进算法的有效性.
为了有效对频繁模式进行挖掘,本文将改进点与APFT 算法结合,由于新提出的连接预处理方法与紧凑树结构具有较好的可移植性,因此改进点可与其它类似算法结合,且并不影响挖掘效率,相应地还能增强原始算法处理数据流问题的能力.
下一步的研究工作包括:1)继续完善算法,往并行计算方向扩展;2)将该算法的思想扩展到最大、闭频繁模式的挖掘领域.
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
天津诗人(2017年2期)2017-03-16 03:09:39
浙江大学学报(理学版)(2017年1期)2017-02-07 09:53:45
电脑知识与技术(2015年14期)2015-07-24 11:30:20
浙江大学学报(工学版)(2015年6期)2015-03-01 01:18:24
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:33
计算机工程(2014年6期)2014-02-28 01:26:12
河南科技(2014年11期)2014-02-27 14:17:57
