
数据挖掘经典分类聚类算法的研究综述
2019-09-10 13:10:35姚奇峰杨连贺
现代信息科技 2019年24期
关键词:数据挖掘
姚奇峰 杨连贺



摘 要:对于当下的学生来说,数据挖掘是一门经久不衰的学科,而对于从事数据挖掘的工作者来说,更是深刻地体会到了数据挖掘强有力的发展前景。数据挖掘这个领域应用最多的就是算法,掌握算法的意义就抓住了数据挖掘的核心。如今,虽然数据挖掘技术的应用相当广泛,但是就算法而言其本质并未发生改变。现今运用的都是一些比较经典的算法,如传统的决策树算法等,同时这些算法也是学习数据挖掘算法的根基。文中主要列举相关算法并应用相应的实例加以佐证,指出其中的不足和需要改进的地方,以此让读者更容易理解各种算法的原理和运行流程。
关键词:数据挖掘;决策树算法;算法原理;算法改进
中图分类号:TP312 文献标识码:A 文章编号:2096-4706(2019)24-0086-03
Abstract:Data mining is an enduring subject for current students. For those who are worked in data mining,they have a deep understanding of the strong development prospects of data mining. Algorithms are the most widely used in the field of data mining. The people who grasp the meaning of algorithm then grasp the core of data mining. In the new era,although the application of data mining technology is quite extensive,its essence has not changed even in law. Nowadays,some classical algorithms are used,such as the traditional decision tree algorithm,but these algorithms are also the foundation of learning data mining algorithms. This paper mainly lists the related algorithms and proves them with corresponding examples,It also points out the shortcomings and the areas needing improvement,this will make it easier for readers to understand the principles and operating procedures of various algorithms.
Keywords:data mining;decision tree algorithms;algorithm principle;algorithm improvement
0 引 言
近年來,数据挖掘(Data Mining)这门综合性很强的学科发展迅速,就其本身而言涉及很多领域的知识,如对于模式识别而言,在识别一组图像、文字或者语言的时候,我们可以提取其中的相关特征来达到找出想要信息的目的。就机器学习这个领域来说,算法是它的内在本质,这与数据挖掘技术也是脱不了关系的。不仅如此,数据挖掘还涉及数据库技术、统计学、计算机网络和可视化分析。可以说数据挖掘技术与人们的生活密不可分。
1 数据挖掘的定义及过程
就数据挖掘的定义而言,可以用一个例子加以说明:例如想对在某网络平台购买某一商品的人数进行分析,首先应该明白我们需要的是什么数据,有用的数据需要具备哪些特征,之后需要从大量信息中找出具备这些特征的信息。因此可以利用一些基本的辅助工具如Python编辑一些搜集信息的程序,在搜集信息之前可以设定被搜集信息的属性,当数据提取完毕之后需要对数据进行一定的处理,因为搜集的数据难免会有各种问题,把无用的信息剔除,保留有用信息,进而可以得到我们想要的信息。这个过程可以称之为数据挖掘,它可以整合分析所得到的数据。
数据挖掘的过程主要包括以下几个方面:(1)首先清楚客户想要什么。在大量数据中搜集相关信息,认清所要解决的问题;(2)建立一个统一的数据挖掘库。在对信息收集时,不同信息的来源是不同的,难免要对数据进行一些基本的操作,而把数据放在一个统一的数据库中方便对数据的修改和维护运用;(3)对收集的数据进行压缩处理。一般情况下,收集的数据都是比较多的,大量的数据会使程序的运行效率降低,提高程序运行效率的唯一办法就是减小数据量,对数据进行压缩;(4)对所用的数据进行清理。剔除不必要的信息,对空白数据进行补全;(5)整理分析数据。在将数据变换为可用形式之后选择合适的工具和算法对数据进行处理得出有价值的信息;(6)对挖掘结果进行评估。
2 常用的数据挖掘算法
2.1 ID3算法
ID3算法采用信息增益作为属性计算的一种方式,总会选择结果相对较大的一个属性,它是一种相对经典的决策树算法,同时也是一种遍历选择最优的算法。ID3属于分类算法的一种,因此在建立决策树模型时该算法首先会计算各个属性的信息增益,以此来作为属性选择的判断条件。现有一个数据集用A表示,样本集中存在多个属性,但我们只需要其中的属性B,所以在用ID3算法运行此数据集时会以属性B作为分割样本的判断条件,则按B属性划分后的信息增益为:
如表1所示,我们为研究身高、长相、体型、收入与一个人是否受欢迎之间的关系,在學校周边进行随机采访,此次采访只限男性,共采访三十位随机路人。针对此次采访制作采访结果表格,并把采访到的数据存放其中制作成一个小数据集,现只截取部分数据,用ID3算法来构建其决策树模型,并根据其决策树模型画出决策树。
现根据身高、长相、收入、体型四个特征来判断此人是否受欢迎,表1就是一个小型的数据集,我们使用ID3算法来构建它的决策树模型并以此来画出此数据集的决策树。实验运行的环境为:Windows 7、Python 3.7、Intel i54210-U以及4G内存。其决策树模型为:
由以上实验可以看出虽然ID3算法会选择信息增益相对较大的属性,但信息增益有其本身的缺点,即会不经易间选择一些无用的信息,这使得其中有价值的信息大大减少,这种局限性也使得ID3这种算法只能用于分类。
2.2 C4.5算法
C4.5算法相对于ID3算法而言更实用一点,它应用到分类的思想,同时也可以根据决策树模型画出决策树。信息增益的计算是在ID3算法中最重要的应用,而在C4.5算法中则不同,它更细化了选择属性的计算过程——采用信息增益率进行选择。同时,在其原始计算代码中也多出了计算信息增益率的公式,这也使得C4.5算法克服了ID3算法中使用信息增益作为特征判断条件时带来诸多无价值信息的不足。信息增益率定义为:
在对缺失值的处理方面C4.5算法也有自己的方法,如k为样本集A中的一个实例,在给定属性的情况下,若在节点c中有8个为该属性,剩下2个为非该属性,则该属性在样本集占比为80%,于是实例的80%被分配到占比较多的一方,这就是C4.5处理缺失值的方法。
现有数据如表1,我们用C4.5算法根据身高、长相、收入、体型等特征来判断他的受欢迎程度,并构建决策树模型。首先根据数据运行出小数据集的决策树模型:C4.5算法对ID3算法加以改进有其自身的优势。就算法本身而言,C4.5的准确率是相对较高的,但由于要对现有的数据集执行多次命令,其花费的时间也相对较多,所以此算法在效率上欠佳,同时由于其计算机制的问题,在样本属性的选择上也会存在一定的误差。
2.3 K-Means算法
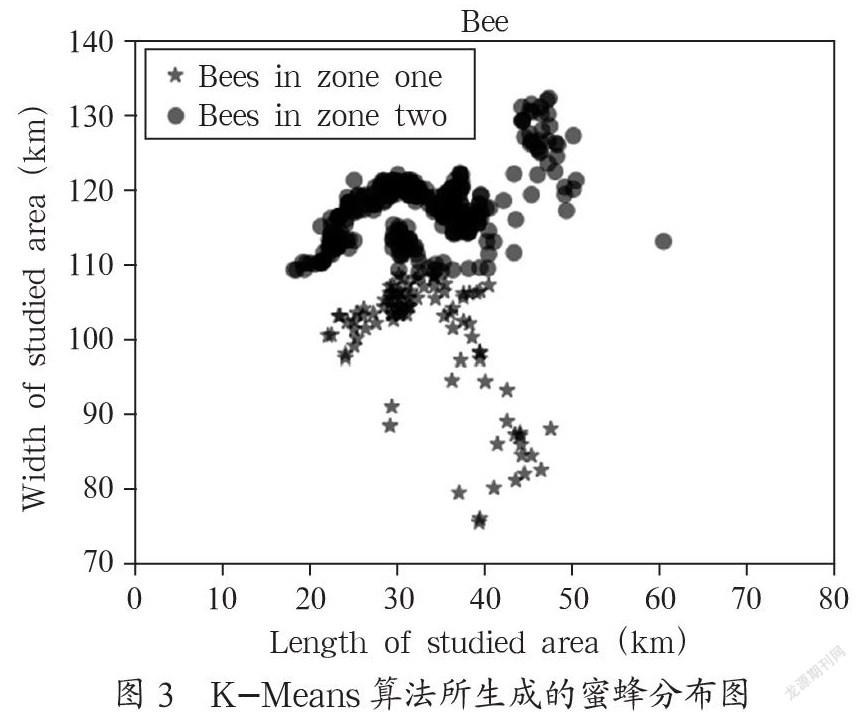
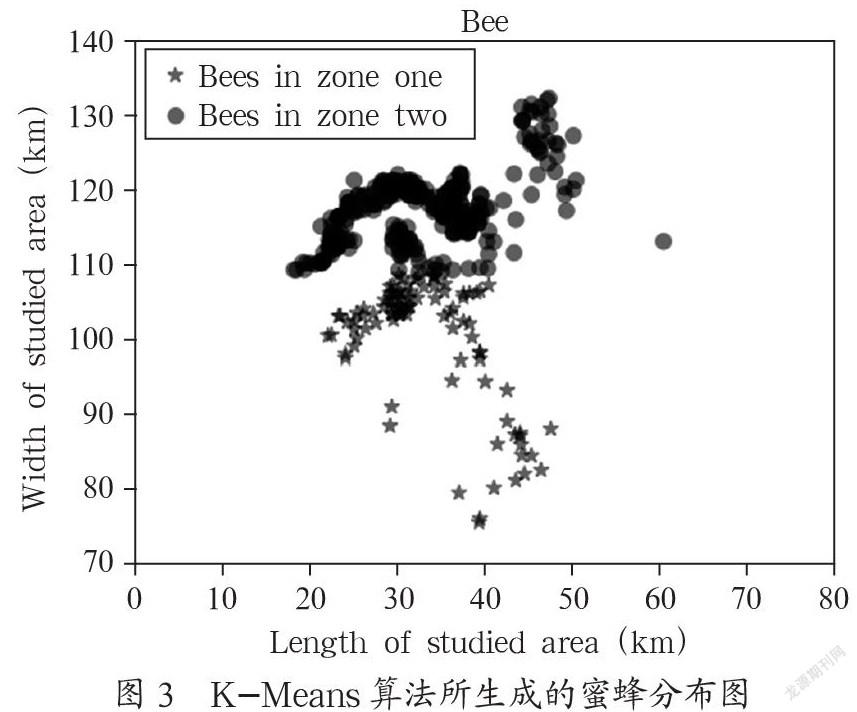
K-Means(K-Means Clustering)算法是一种无监督式的学习算法,同时也是一种使用广泛,较为受欢迎的算法。所谓聚类就是把属性相同或者类似的数据放在一起构成一个簇数据集合,若能达到集合内差异性较低而集合间差异性较高的话就是一个好的聚类。K-Means算法的原理也相对较容易理解,首先随机选取k个种子点作为原始的中心点,之后依次计算各个样本点到种子点的欧氏距离,若该点到原始中心点的距离近,则该点属于此原始中心点的数据集合,之后这个点移动到数据集合的中心,同样计算它到各点的欧氏距离,直到中心点不再移动。K-Means算法可以直观地反映出研究者所想要的信息,下面用一组数据加以说明。若把某一地区当作一个二维平面图建立坐标系,以蜜蜂的所在区域研究该地区的蜜蜂分布情况,用K-Means算法对数据集进行处理后得到的试验结果如图3所示。
虽然K-Means算法的原理很容易被人理解,在某些簇间差异相对明显的情况下效果较好,但是这种算法也存在明显的缺点。K-Means算法的结果与最开始中心点的选择关系密不可分,初始点的选择不合适会导致最后的结果较差,因此需要做大量的工作来确定最开始中心点的取值。
3 结 论
经过详细介绍了三种常用的数据挖掘算法,旨在使学者更加容易地理解和学习,在此基础上才能对各种数据挖掘算法有更深入的了解。首先,在ID3算法的试验中我们使用了四种属性构建了判断一个人是否受欢迎的决策树,同时也分析了ID3算法的不足之处。之后介绍了ID3的改进算法C4.5,在相同的试验中采用C4.5算法去运行相同的数据集,得出比ID3更确切的决策树,同时也指出C4.5算法需要改进的地方。最后使用K-Means算法聚类蜜蜂的分布情况。各试验步骤详细原理清楚,不足之处在于在聚类蜜蜂的分布情况时建立的坐标系精度不够准确,使最后的结果存在一定的误差,在此基础上尚可改进。
参考文献:
[1] 杨秀港.数据挖掘算法综述 [J].科技经济导刊,2019,27(5):166.
[2] 蔡萌萌,张巍巍,王泓霖.大数据时代的数据挖掘综述 [J].价值工程,2019,38(5):155-157.
[3] 王宇翔.大数据背景下的数据挖掘算法综述 [J].通讯世界,2018(11):21-22.
[4] 杨小平.数据挖掘三大经典算法在交通领域的应用综述 [J].物联网技术,2018,8(11):42-44+48.
[5] 刘维.数据挖掘中聚类算法综述 [J].江苏商论,2018(7):120-125.
[6] 王雅轩,顼聪.数据挖掘技术的综述 [J].电子技术与软件工程,2015(8):204-205.
[7] 周丽英.面向软件开发信息库的数据挖掘综述 [J].中国管理信息化,2016,19(12):184.
[8] 梁辰,陈明浩.数据挖掘ID3分类算法研究综述 [J].信息通信,2015(5):26-28.
作者简介:姚奇峰(1991-),男,汉族,河北邢台人,硕士,研究方向:计算机技术,数据挖掘;杨连贺(1965-),男,汉族,天津人,教授,博士,博导,研究方向:数据挖掘。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
中国交通信息化(2020年1期)2020-07-27 02:50:04
电力与能源(2017年6期)2017-05-14 06:19:37
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
信息通信技术(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
河南科技(2014年19期)2014-02-27 14:15:26
电子设计工程(2014年18期)2014-02-27 12:00:13
电子设计工程(2014年18期)2014-02-27 12:00:12
智能系统学报(2013年1期)2013-01-28 10:16:55
