
基于IP缓存的SYN Flooding防御技术
2019-09-10 07:22:44韩立明
河南科技 2019年32期
韩立明

摘?要:DDOS攻击是当今互联网一种比较重要的安全威胁,而SYN Flooding是DDOS攻击中最常使用的几种网络攻击方式之一。本文先分析了两种主流的防SYN Flooding技术的优点和不足之处,然后引入IP地址缓冲技术,克服了这些方法的不足,从而提高防御SYN Flooding的效率。
关键词:同步洪攻擊;SYN Cache;SYN Cookie;IP缓存
中图分类号:TP393.08 文献标识码:A 文章编号:1003-5168(2019)32-0015-03
IP Cache based Syn Flooding Defense Technology
HAN Liming
(Tongliao Vocational College,Tongliao Inner Mongolia 028000)
Abstract: DDOS attack is one of the most important security threats in the Internet nowadays, and SYN Flooding is one of the most common network attacks in the DDOS. This paper first analyzed the advantages and disadvantages of two main anti-SYN Flooding technologies, and then introduced IP address buffer technology to overcome the shortcomings of these methods, so as to improve the efficiency of anti-SYN Flooding.
Keywords: sync flood attack;SYN Cache;SYN Cookie;IP Cache
当今时代,几乎所有的Internet服务都建立在TCP/IP协议族之上,包括http、ftp、e-mail等。这些服务的可用性依赖于下层传输层协议(TCP)的性能[1]。但是,目前存在一种严重威胁TCP性能的攻击,即SYN Flooding。正常情况下,服务器收到一个SYN段,其认为远程主机要建立一个TCP连接,操作系统分配一定的资源来记录这种状态。通过快速持续的发送SYN段,攻击者很快耗尽主机资源,甚至使其死机。
服务器可以通过改变自身资源分配策略来缓解SYN Flooding带来的冲击。一种办法是先分配尽量少的资源,待到连接完全建立后再分配全部的资源(SYN Cache);另一种办法是不在服务器保留任何状态信息,而返回的SYN/ACK包的ISN中包含一个用密码加密的信息(SYN Cookies)[2-4]。这两种方法都有其优点和不足。为了克服两种方法的不足,本文引进IP缓存技术,该技术充分发挥了两种方法的长处,有效避免了其缺点,同时还能有效找到部分攻击源。
1 SYN Flooding、SYN Cookies和SYN Cache
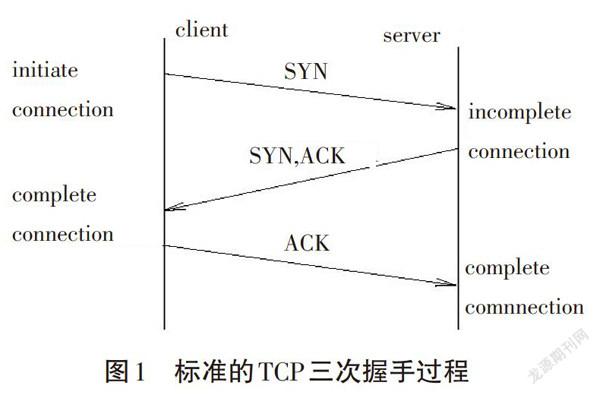
SYN Flooding攻击是利用TCP协议三次握手(见图1)连接建立过程没有对连接请求进行合法性验证的缺陷而设计的攻击方式。当收到一个SYN时,服务器就分配一定的内存、计时器等资源来记录这种半打开状态。SYN Flooding攻击的目标是用大量无用的SYN段占用服务的资源,使其不能向合法的连接提供服务。
为了抵抗这样的攻击,必须设法减少分配给每个不完全连接的资源数量(SYN Cache),甚至不分配资源(SYN Cookie),而是等到连接完全建立时才分配。
SYN Cache机制用了一个全局Hash表代替每个端口的线性表来存储半连接的状态,每个Hash值对应一个线性表。SYN Cache的设计思想就是尽量减少每个部分连接占用的资源数量,使服务器可以容纳更多的半连接。另外,采用连接池循环使用技术使攻击者的难度加大。SYN Cache的一个缺点是在SYN Flooding强度很大的情况下,Cache有可能溢出。
SYN Cookies实际上是返回给远程计算机的初始化序列号(Initial Sequence Number,ISN),合法的连接将在三次握手的最后一步将其返回服务器。服务器通过连接的初始SYN包的源IP、端口号、时间戳及服务器定期变化的密码来计算ISN,服务器收到第三步的ACK,取出ISN,解密后与ACK包中的信息进行验证。有较好的算法可以保证ISN难以伪造和重用,这样在服务器端不用维护每个未完成连接的状态信息。只要第三步ACK验证通过,便可以通过ACK中的信息建立完整的连接。但是,SYN Cookies丢失了一些TCP选项,对TCP性能有一些影响,另外与T/TCP也存在一些兼容性问题。
2 IP缓存机制
总的来说,SYN Cookies在判断一个连接是否合法方面非常有效,而SYN Cache在保持TCP各项性能方面非常有效。在此基础上,本文提出一种IP缓存机制,该方法融合了上述两种方法的优点,并有效克服其不足。
据估计,当今Internet环境中,绝大多数是Web数据流(约80%)。Web数据流有以下特点:从一个连接请求一个页面,先建立一个TCP连接得到主页面,随后紧跟着若干嵌入页面的元素,将各自与服务器建立一个TCP连接。可以预期,在同一个IP地址到服务器的两个相邻连接的时间间隔大部分分布在一个较短的时间范围内。而且,现在Internet中大部分接入是通过代理服务器,通过代理服务器到服务器的连接都是代理的IP地址,相邻连接的间隔时间更集中于1h的时间范围内。
IP缓存正是基于上述假设。IP缓存的设计思想是:每一个连接,先用SYN Cookies技术判断其合法性,如果合法,便在服务器上记录有关的源IP地址等信息(称为goodlist表),对以后的连接,如果起始IP地址和服务器记录的地址一致,便允许直接建立连接(为了进一步节省资源,连接采用SYN Cache方式来建立)。为了防止服务器记录的信息占用过多内存,必须定期清理goodlist。上述假设保证了在一定命中率下,goodlist的容量不用太大。IP缓存再设置badlist来存放明显是伪装的SYN连接的IP地址名单。
IP缓存的工作原理如下。第一,初始化goodlist,badlist为空。第二,对任何TCP连接请求(新到SYN段),查询badlist,如果源IP地址在其中,拒绝该连接请求;再检查其是否在goodlist中,如果在,该连接按SYN Cache方式处理,同时更新白名单中相应条目的时间戳;如果也不在goodlist中,该连接按SYN Cookies方式处理。第三,对于每个成功建立的连接,如果goodlist中没有记录,则将相应的条目添加到goodlist;如果已经在goodlist中,更新其goodconnect计数,同时更新RTT估计值和时间戳。第四,每次连接关闭,如果IP还在goodlist中,则更新其时间戳和RTT估计。
可以把SYN Flooding中的源IP地址分成两种特征:第一,是伪造的随机IP地址;第二,伪造IP,但通过代理服务器产生IP,到达服务器的IP是代理服务器的IP地址,这种IP地址是真实的IP地址。
SYN Flooding攻击时可能混杂了两种类型的SYN段。对于第一种特点的SYN Flooding,SYN Cookies机制可以有效识别,从而不可能进入goodlist,也不会占用Cache资源,即使偶尔会有某个IP地址恰好在goodlist中而进入Cache,由于这种可能性非常小(攻击者随机产生源IP地址),对Cache不会造成不良影响。对于第二种SYN Flooding,由于从同一代理服务器出来的还可能有其他合法连接,所以这种连接很可能进入Cache和goodlist,但是这时Cache中将表现出大量的连接超时,相应的badconnet将很快增加,在时间[T1]内被检测到,而被加入badlist。这将有效阻隔这种类型的SYN攻击,同时,这时badlist记录的都是真实的IP,所以源追踪要容易很多。
3 IP缓存的性能分析
为了保证IP缓存机制能起到良好的作用,其必须满足以下几个条件:合法连接到来时在goodlist中的命中率要高,否则便退化到SYN Cookies(命中率和[T1]值正相关);goodlist的大小体现值[N]应足够小,否则goodlist的查询和修改将成为瓶颈,[N]与[T1]负相关;在选择将IP记录放入badlist时应采用恰当的算法,尽量避免合法连接被错误放入badlist,并避免具有攻击流的IP长期占用Cache;[T2]的值应根据实际情况合理配置,避免从相同代理服务器产生的合法连接不能建立,同时还要避免badlist太大造成查詢或修改瓶颈。
前两个条件是相互矛盾的,必须折中选择一个合适的值。
令从同一IP地址到服务器的两个相邻TCP连接之间的时间间隔分布为[P(T)]([T]>0),即小于[T]时间的个数占总数的比例为[P(T)],则:
[0+∞P(T)dT=1] (1)
令[δ=0TP(T)dT]。同时,令每个连接平均消耗处理器时间为[t],则在[T]时间内到达的连接数为:Total=[T]/[t],每个这样的连接来自与goodlist中的IP不同的IP的概率为[1-δ],所以goodlist的大小为:
[Sg=(1-δ)T/t] (2)
一般[t]在毫秒数量级,不妨设为1ms。
假设在一般Web访问中,同一个页面有20个连接,这些连接将在10s以内到达服务器,取[T]=10s,则[δ]>(20-1)/20=0.95,代入式(2)可得:[Sg]=(1-0.95)×10/0.001=500。
可见,在保证goodlist命中率在95%的情况下,goodlist的大小在103的数量级,对查询和插入删除都不会造成瓶颈。
为了防止从代理服务器出来的SYN Flooding占用Cache资源,一般情况下,如果没有SYN Flooding攻击,各个IP对应的badconnect计数将会很小,相反,如果存在SYN Flooding,相应IP的badconnect计数将会急剧增加,另外goodconnect也可以作为参考。所以,通过badconnect计数器来判断具有很高的可信度。
关于badconnect计数,可以参考RTT来设置,如果Cache中的條目被清除出,在Cache中的时间[t]小于累计的平均RTT(记录在goodlist),则badconnect加一个较小的值[a],如果[t]>>RT,则badconnect加一个较大的值[b]。选取的值要使得在有无SYN Flooding的情况下badconnect计数差异尽量大。
关于badlist的容量问题,发动一次SYN Flooding攻击的计算机通过的代理服务器个数一般不会超过几百的数量级,所以badlist的容量不是问题。至于时间[T2]的选择,主要考虑攻击源的追查和影响的正常用户两方面,由于每个badlist条目只影响从该代理出来的用户,可以根据攻击的强度适当选择屏蔽时间,同时可以进行实时的源追踪。
4 结语
本文结合两种比较有效的SYN Flooding抵御方法,以此为基础,引入IP缓存机制,融合两种方法的优点,有效克服各自的缺点,提高了防御SYN Flooding的性能。IP缓存机制还有两个特点,一是涉及的参数很多,和服务器提供的服务等网站自身特点相关,攻击者要攻破这样的防御体制需要更多动态数据,这在实践中是很难的;二是IP缓存机制可以有效分辨出自真实代理服务器的攻击,可以快速进行源追查,一般发动一次攻击都是有组织的行为,找到部分的攻击源有利于找到始作俑者。
参考文献:
[1]史蒂文斯.TCP/IP协议详解卷一:协议[M].北京:机械工业出版社,2016.
[2]特南鲍姆.计算机网络[M].北京:清华大学出版社,2014.
[3]陈平平,张永超,李长森.SYN Flooding攻击问题的分析[J].计算机工程与设计,2015(1):114-117.
[4]汪晓平.SYN flooding网络开发技术[M].北京:人民邮电出版社,2013.
