
可装配的大数据流式计算引擎
2019-09-10 20:04:49李爽张飞王颖卓
现代信息科技 2019年13期
李爽 张飞 王颖卓

摘 要:本方案涉及大数据技术领域一种流式数据计算引擎的实现方法和装置,包括:接收用户编辑请求,所述编辑请求中包括算子及其配置信息;根据所述算子及其配置信息提交给编译引擎,编译引擎通过编译识别所述算子及其配置信息,对所述的算子及其配置分配运行空间及监控设备,提交编译后的算子及其配置信息到计算引擎进行数值计算,并通过推送引擎将计算结果通知到最终用户。
关键词:流式数据计算引擎;流式计算算子;算子运行空间
中图分类号:TP274 文献标识码:A 文章编号:2096-4706(2019)13-0100-03
Assemblable Big Data Flow Computing Engine
LI Shuang,ZHANG Fei,WANG Yingzhuo
(Technology Division of China UnionPay,Shanghai 201201,China)
Abstract:This project involves the implementation method and device of a flow data computing engine in the field of big data technology,including:receiving user edit request,which includes operator and configuration information;described according to the operator and its configuration information to compile the engine,engine operator described by compiling recognition and its configuration,its configuration information to described by the operator operating space distribution and monitoring equipment,and its configuration information to submit the compiled operator calculation engine,numerical calculation,and the results to the end user via the push engine.
Keywords:flow data computing engine;flow calculation operator;operator operating space
0 引 言
大數据的实时计算一直都是大数据领域一个比较热门的方向,现有的大数据实时计算框架丰富多样,比较有影响的有Flink、SparkSream、Storm等,以及各个公司根据自己的产品特点自行研究的一些大数据实时计算框架。
实时计算框架的多源性虽然丰富了开发人员、终端使用人员的选择,但是也给开发人员和终端人员的使用带来困扰,而且在很大程度上影响了开发人员和终端人员之间在不同实时计算框架之间的协同工作。在多种技术并行的情况下极大地影响了开发人员和终端使用人员的入门门槛。
1 技术背景
现有业界的相关产品以阿里巴巴网络技术有限公司的实时计算调度装置为典型代表,其由数据源管理装置、内部数据结构转换装置、算法表达翻译及执行引擎等装置外加一组相关的装置管理装置构成。
目前业界的相关产品在通用化、易用化方面的开发实施成本都非常高,试分析如下。
数据源管理:现有的数据源管理装置要么要求数据源实现统一的数据源访问接口(例如JDBC、ODBC、BDE等),要么由平台进行自适配数据源工作。导致增加数据源非常困难,尤其是非结构化数据源的引入基本不存在一个统一的数据源访问接口,而且数据提取规则形式多样,同一份文件甚至有数十种不同的解读方式,导致自行适配基本不可能完成。
内部数据结构转换:现有的数据源转换要求对具体的业务流程和抽象都有非常明确的认知和了解,否则抽象出来的内部数据结构会存在各种偏差。终端使用人员基本无法参与,需要额外引入相关建模人员。
算法表达翻译及执行:现有的方式不可避免地会引入新的约定或者语法规则,会给开发、终端使用人员带来额外的学习成本。
相关的管理系统:现有的相关管理装置至少会包含用户管理、数据源管理管理、内部数据结构转换管理、算法表达翻译及执行引擎管理等管理系统。管理关系复杂,部署维护成本高。
2 实现方式
2.1 流式计算引擎整体流程
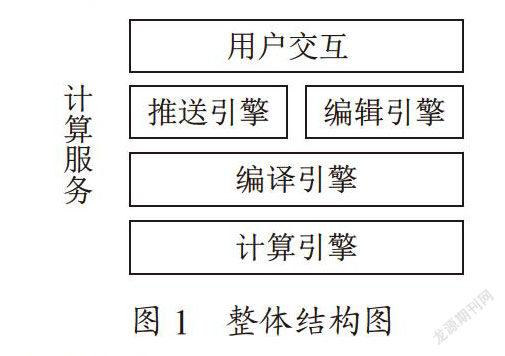
一个典型的装置结构如图1所示,其中用户交互部分涵盖了推送引擎和编辑引擎两个功能装置。用户通过编辑引擎输入算子描述,编写业务逻辑。编辑引擎会根据该算子的配置规则,进行编辑校验,包括语法助手、文法检查等。并对所编辑的任务进行调度显示以及完整的任务管理。编辑引擎通过轮询数据库的方式对用户编辑的任务进行触发条件检测,当满足触发条件时则通过RESTful接口推送业务算子及对应的描述信息到编译引擎。
2.2 编译引擎建立
编译引擎识别并编译用户定义的业务逻辑,选择对应的算子。编译引擎至少要完成以下功能:
(1)通过用户给定的配置参数编译成一个独立的具备输入输出的能完成独立功能的特定程序代码算子。
(2)根据创建出的算子发现对应的流数据处理平台,并能够创建一个使之运行、销毁的运行空间,该空间可以但不仅限于使用计算机操作系统所提供的线程或者进程来实现。
(3)一个能监视提交算子的运行状态的任务审计子功能,在必要的时候对算子的运行状态进行告警处理。用来发现、创建、执行、销毁具体算子的特定程序代码。
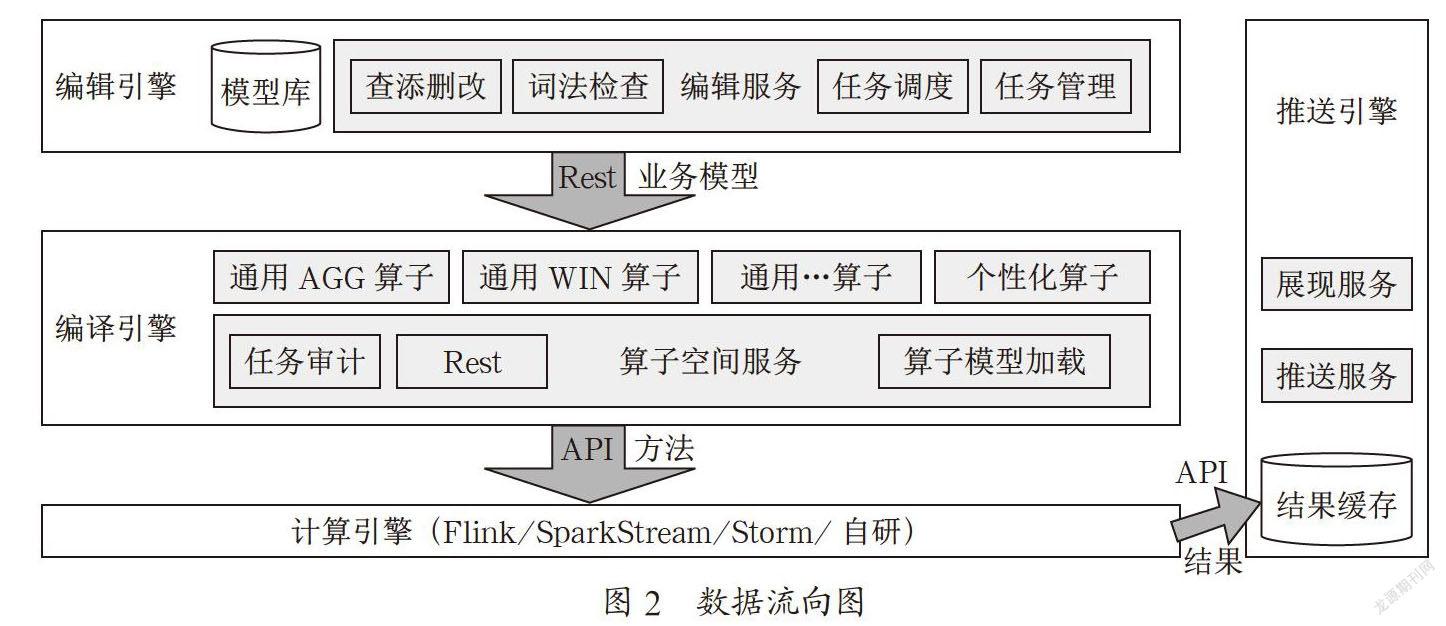
整个装置的数据流如图2所示,其中接口调用方式以RESTful为优先考虑的接口暴露方式,在具体实现中可以使用其他方式进行替换。
编译引擎:作为整个提案的核心,该编译引擎定义并实现了对外的算子调用接口(优先的RESTful接口)、算子管理、算子空间管理、算子审计管理等。
算子空间:作为算子执行的核心,该装置定义并实现了算子的实现发现、创建,及运行、销毁等管理动作。
通用算子模型:约定、发布、管理、审核所有算子的实现是否符合算子开发规范及惯例接口。
算子审计:针对算子的运行状态提供相应的审计报。
2.3 计算引擎建立
计算引擎实现具体的数值计算。包括窗口聚合、累计、TOP、ABTest、CEP等具体算子的任务分发。分发系统包括但不仅限于Flink、SparkStream、Storm,或者任何其他流数据计算平台。计算引擎处于整个流式数据计算引擎的计算核心,还可通过图3所示的方法流程对计算引擎进行补充。
如图3所示,该方法流程可包括:
本方案采用算子通过选择特定的实时计算框架对数据源直接进行操作,对数据源不进行任何管理,对应的传统技术的数据源管理装置,在本提案中没有该装置的存在,相应的也不需要引入传统技术中该装置的各种弊端。
本方案采用算子对源数据进行直接解析,对数据结构不做任何二次抽象化操作,对应的传统技术的内部数据结构转换装置,在本提案中没有该装置的存在,相应地也不需要引入传统技术中该装置的各种弊端。
只发布具体执行算子,不引入任何约定或者语法规定(算子的配置参数约定例外),对应的传统技术的算法表达翻译及执行引擎装置,但在本提案中对其进行了颠覆性定义。所以不具备可比性。
构建简单,编辑引擎装置、推送引擎装置、编译引擎装置,计算引擎装置四类及相应的管理装置(其中编辑引擎装置、推送引擎装置均属于用户交互管理),不需要对数据源、数据进行二次抽象、算法表达及管理等系统管理。
2.4 实现包确定
基于上述的技术构思,本案提的实现结构如图4所示。
本方案中的装置管理系统采用前后端分离方式,其中GUI管理页面采用成熟的商业化GUI构建软件EXTJS实现,但仅限于内部使用,不作为对外提供的用户界面,同时也提供了基于HTTP的RESTful接口和内部RPC调用接口进行直接管理,为减少部署资源的使用及部署复杂度,同样地也可以使用对应的管理流程制度,作为一个辅助的可选装置存在。在整个提案中可以通过各种表现形式进行替换。
本方案中的编辑引擎具有多样化的实现方式,不限于GUI、CUI等输入方式,但是核心必然是对发布算子进行选择,对选择确定的算子进行运行时的参数配置,以及任务的提交,提交方式也不限于HTTP RESTful,也可采用其他RPC提交方式。
本方案中的编译引擎具有多样化的实现方式,不限于具体的实现语言。但优选的具有反射功能的类似java语言或者其他语言实现。
本方案中计算引擎不限于提供对Flink、SparkStream、Storm等实时计算引擎的审计接口封装,封装形式优先以RESTful接口进行提供,但不仅限于此。
推送引擎将计算好的结果推送给用户。并具有多样化的通知方式,不限于RESTful、Kafaka、数据库、短信或者其他数据推送通知方式。
该案例可采用的最简化实施可能会非常简易,但以算子为基本调度运行的典型特征不会发生改变,所以可选的开始流程可以从任务调度直接开始,同时显示服务和通知服务作为可选的步骤也可以不出现在整个流程中。
3 结 论
该案例可采用的最简化实施可能会非常简易,但以算子为基本调度运行的典型特征不会发生改变,所以可选的开始流程可以从任务调度直接开始,同时显示服务和通知服务作为可选的步骤也可以不出现在整个流程中。
参考文献:
[1] 孙大为.大数据流式计算:应用特征和技术挑战 [J].大数据,2015,1(3):99-105.
[2] 靳永超,吴怀谷.基于Storm和Hadoop的大数据处理架构的研究 [J].现代计算机(专业版),2015(4):9-12.
[3] 张华,王东辉,吴烜.流式计算的分布式框架的应用 [J].信息与电脑(理论版),2014(10):142-143.
[4] 刘子英,唐宏建,肖嘉耀,等.基于流式计算的Web实时故障诊断分析与设计 [J].华东交通大学学报,2014,31(1):119-123.
[5] 朱月琴,谭永杰,张建通,等.基于Hadoop的地质大数据融合与挖掘技术框架 [J].测绘学报,2015,44(S1):152-159.
[6] 李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考 [J].中国科学院院刊,2012,27(6):647-657.
作者简介:李爽(1986.04-),男,汉族,辽宁鞍山人,中级
职称,本科,研究方向:大数据开发;通讯作者:张飞(1981.05-),男,汉族,陕西西安人,中级工程师,本科,研究方向:大数据开发;王颖卓(1978.05-),男,汉族,江西赣州人,架构师,硕士,研究方向:大數据开发。
