
基于形变模型的多角度三维人脸实时重建
2019-09-09 03:38陈国军裴利强
图学学报 2019年4期
陈国军,曹 岳,杨 静,裴利强
基于形变模型的多角度三维人脸实时重建
陈国军,曹 岳,杨 静,裴利强
(中国石油大学(华东)计算机与通信工程学院,山东 青岛 266580)
采用人脸特征点调整三维形变模型的方法应用于面部三维重建,但模型形变的计算往往会产生误差,且耗时较长。因此运用人脸二维特征点对通用三维形变模型的拟合方法进行改进,提出了一种视频流的多角度实时三维人脸重建方法。首先利用带有三层卷积网络的CLNF算法识别二维特征点,并跟踪特征点位置;然后由五官特征点位置估计头部姿态,更新模型的表情系数,其结果再作用于PCA形状系数,促使当前三维模型发生形变;最后采用ISOMAP算法提取网格纹理信息,进行纹理融合形成特定人脸模型。实验结果表明,该方法在人脸重建过程中具有更好的实时性能,且精确度有所提高。
三维形变模型;特征点提取;表情系数;PCA形状系数;纹理融合
随着视觉感知和获取技术的发展,近年来,人脸三维重建的精确度逐步提高,其流行方法包括激光扫描、结构化光扫描、RGBD相机[1]等。同时,3D人脸模型被广泛应用于建模[2]、动画[3]、游戏[4]、信息安全和3D打印[5]等领域。但是,当前的人脸三维模型往往需要通过昂贵的设备和相当高水平的专业知识来实现高质量的捕获和重建[6],远远超出了一般终端用户的能力,因此限制了该技术的潜在应用。
从二维图像中重建人脸三维模型无需昂贵的设备和专业的操作,具有制作成本低、使用方便、利于推广等优点,一直是该领域的研究热点。基于图像的人脸建模最常用的2种方法为基于明暗恢复形状的方法和基于形变模型的方法。HORN[7]早在20世纪70年代就提出了通过图像明暗变化恢复物体外观形状的方法,类似于物体成像的逆过程,根据人脸照片的亮度变化恢复人脸模型的表面形状。其优点在于数据集的需求较小,通过少量人脸图像恢复人脸的形状模型,但该模型所需条件过于理想化,对拍摄角度、光照方向有要求,实时性较差,无法被广泛应用。
BLANZ和VETTER[8]提出的三维形变模型(3D morphable model, 3DMM)法是目前较为成功的利用二维图像进行人脸重构的方法。通过建立三维人脸的线性组合,结合二维图像调节、拟合得到重构的三维人脸。其创造性地将一个具体的人脸模型分解为形状和纹理2个部分,且具有高度自动化和真实感强的优势,在人脸三维重建领域广受关注。文献[9]通过在二维图像和三维面部模型数据集上训练卷积神经网络,在不考虑细节和纹理特征的情况下,能够实现任意姿态和表情的面部几何重建。文献[10]提出了一种高保真姿态和表情的方法,利用姿态变换造成二维和三维特征点的不对应关系,采用三维形变模型自动生成正面姿态和中性表情的自然人脸模型。文献[11]通过大量的数据标记,提出了一种鲁棒性的,由输入照片直接返回3DMM形状和纹理参数的回归方法,克服了模型泛化问题,生成可用于人脸识别的三维人脸模型。文献[12]发布了SFM (surrey face model)三维形变模型,并提出采用级联回归方法拟合3DMM参数,实现了基于视频重建三维人脸模型的算法4dface,这是面部建模领域的一大飞跃。
尽管对图像和视频的三维建模已有大量的研究,但是从视频中实时重建带有表情的精确三维人脸仍有很大的改进空间。本文提出一种从普通人像视频中自动实时重建三维人脸模型的方法,支持侧脸角度[–40°, 40°],俯仰角度[–20°, 20°]下的头部姿态,在该范围内,相机从不同角度拍摄人脸,采用线性回归的方法拟合不同角度和姿态的人脸二维特征点和三维形状模型,重建过程中使用头部姿态和表情系数调整模型细节状态,最后在300W人脸数据集上验证了本文算法在重建拟合时间和模型准确度上均有所提高。
1 相关工作
本文旨在实现实时重建出具有辨识度的三维人脸模型,过程中不需要严格的定义人物姿态,也无需昂贵的深度获取设备和专业人员的操作,以及后期的加工处理,是一种简单、可广泛推广的快速人脸建模方法。基于二维图像进行三维模型的重建往往对模型和人脸的初始状态有很强的依赖,因此图像特征和通用模型的选择是后续重构计算的基础。本文选择三维形变模型作为通用形变模型,用于和二维特征点的拟合运算。同时,选取68个特征点描述人脸特征,并采用受约束的局部神经域模型(constrained local neural fields, CLNF)算法[13]获取特征点信息。
1.1 三维形变模型
三维人脸模型可以表示多个对象类的表面,每个人脸由一组顶点组成,由顶点在三维空间中的坐标共同描述人脸形状;每个顶点均对应一个RGB像素值,表示人脸皮肤纹理。由此,面部模型可以表示为多点组成的网格{v|i=1,2,···,},为网格的顶点数,则人脸的第个顶点v的坐标为w=(x,y,z)T,RGB颜色由(r,g,b)表示,一个3D人脸可以用一对形状和纹理向量进行描述:(1,1,1,···,x,y,z)T,(1,1,1,···,r,g,b)T。
每个人脸都是独一无二的,由特定的人脸形状和皮肤纹理组成,通过由和的概率分布构成的统计三维人脸模型,可以捕捉到特定个体人脸的形变。本文使用主成分分析法(principal component analysis, PCA)表示和的空间分布,设和为PCA基矩阵,其中r为形状变化;r为纹理变化,一个人脸实例可表示为
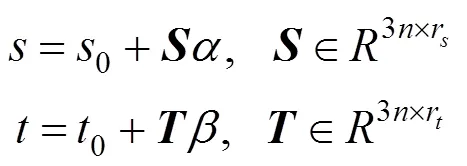
其中,0,0分别为平均人脸的形状和纹理,假设系数和服从正态分布:()~(0,σ),()~(0,σ)。其中,σ,σ是最贴近真实人脸模型的形状参数和纹理参数的变化系数。
由一个人脸模型的平均向量和基向量可拟合成一个特定人脸,不同的模型参数和对应不同的人脸,这种统计三维模型变形能力被称为3DMM。
1.2 特征点提取
面部特征点的提取是图像重建技术的基础,可建立二维人脸与其对应三维模型之间的关系。本文采用目前较好的人脸特征点检测器CLNF算法进行68个面部特征点检测和跟踪。该算法是基于约束局部模型(constrained local model, CLM)[14]的改进,引入了一种包含神经网络层的局部神经域,可以捕获像素值和输出响应之间复杂的非线性关系,加强稀疏性,使结果更加准确。
CLNF特征点检测器由2部分组成:①点分布模型 (point distribution model, PDM)用于捕捉形状变化,包括34个非刚性和6个刚性形状参数来描述人脸形状;②局部贴片patch experts 用于捕捉特征点局部细节变化。其可以在不同姿态、不同光照、或低或高的分辨率下,准确跟踪人脸,并在IBUG数据集上进行了测试,如图1所示。

图1 IBUG数据集上检测人脸特征点
2 模型重建过程
本文从视频连续帧人脸图像实时重建出带有纹理细节的三维面部模型,弥补了单张图片重建的自遮挡问题,由特征点跟踪不同角度人脸变化,实时矫正形变模型,逐步优化,而非一次性重建出最终结果,在细节和准确度方面均有较好的效果。
从视频中提取一帧图像,首先需利用Haar分类器检测人脸区域,再利用CLNF算法在区域内识别人脸特征点的二维位置;然后初始化SFM统计模型(如果是第一帧人脸图像,则初始化平均模型,否则采用上一帧的形变模型),采用黄金标准算法[15]由五官特征点二维位与其在三维模型中的对应坐标计算当前人脸姿态和仿射相机矩阵,通过2次线性回归,求解表情系数和PCA形状系数,使三维模型发生形变。重建方法流程如图2所示。
从视频连续帧可以获取不同角度的人脸图像,每张人脸图像均可跟踪到68个特征点,并拟合一个形变的三维模型。本文将前一帧形变后的三维模型作为后一帧模型形变的基础,使得最终生成的三维模型经历了不同角度人脸姿态的拟合变形,使其更接近真实人脸形状。同时,在姿态角度变化过程中,还可以全方位获取人脸的纹理细节特征。
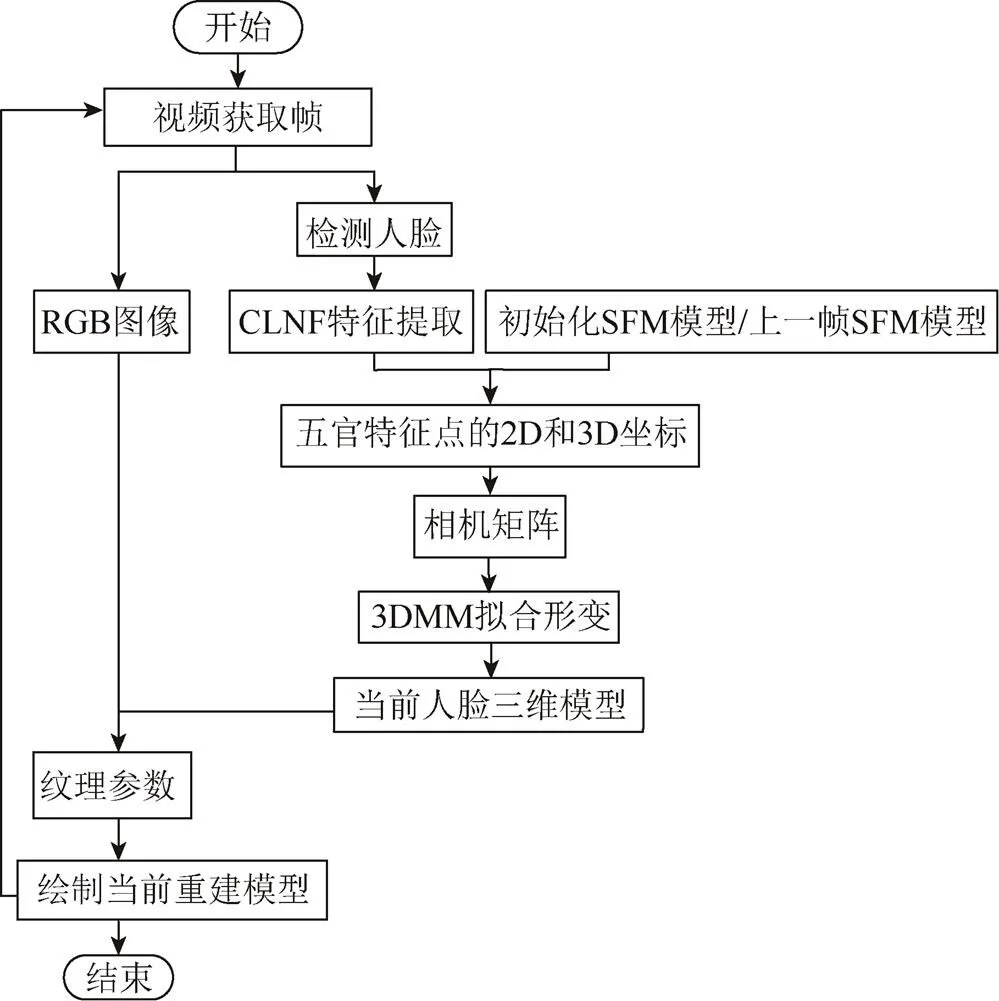
图2 方法流程图
2.1 面部模型的建立
建立稠密对齐的人脸模型,以便于采用统一的向量形式来表示人脸形状,使得每个三维顶点在形变过程中保持相同的物理意义。
本文采用的稠密对齐模型是SFM形变模型,共有3 448个顶点,可生成6 736个密集对应的三角面片,包含一个PCA形状模型,一个PCA颜色模型以及相关数据源,诸如2D纹理展开表示特征点语义对应属性等。SFM模型的构建过程中,使用3dMDface2相机系统对169个不同种族、不同年龄的人脸进行扫描,覆盖了多元文化的人脸特征信息,得到的PCA基矩阵包含63个形状特征向量和132个颜色特征向量,保留了99%的原始数据变化。一个新生成的人脸形状模型可表示为
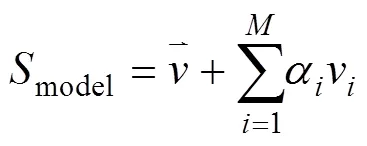
其中,M=63为主成分数,主成分集合V={v1,v2,···,vM},分别表示脸型长宽、大小、圆脸、方脸等不同面部形状特征;α为主成分变化系数。图3为随机设置不同PCA形状系数生成的人脸模型。
除此之外,鉴于表情是人脸的重要属性之一,为了在重建过程中能够保留原视频中生动的表情信息,本文定义了一种表情模型(blendshapes)作为参考模型,可表示为
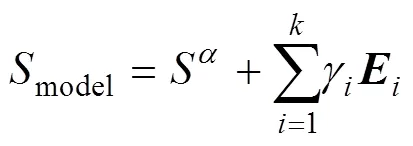
其中,Sα为形状系数生成的模型;k=6为主元表情个数,分别是生气、厌恶、害怕、高兴、悲伤及惊讶;γi为每种表情变化系数;E为主要表情向量组。以平均人脸形状为基础模型,分别调整6个系数,可生成具有不同表情的形状模型,如图4所示。
综上,本文的面部模型由PAC的形状模型和表情模型共同构成,二者均属于线性模型,相互独立,且有各自独立的系数和成分;又相互作用,表情模型可以在形状模型的基础上形变,形状模型也可以在表情模型的基础上形变。
2.2 模型的拟合变形
本文提出一种基于表情系数和PCA形状系数的线性回归拟合方法。单目视频序列中跟踪每一帧图像的68个特征点,选取50个中心区域(眉毛、眼睛、鼻子、嘴)的特征点,采用齐次坐标xÎ3表示。可以避免由于人脸角度变化太大或自遮挡造成的脸部轮廓的特征点丢失或不准。根据SFM模型的2D-3D特征点对应关系元数据,得到特征点在该模型中的三维坐标XÎ4,也用齐次坐标表示,从而计算出表示当前头部姿态的3×4仿射相机矩阵,包括3×3的旋转参数,平移参数,,以及缩放比例。
给定相机矩阵和该组二维特征点,可通过最小化损失函数计算当前表情系数,即
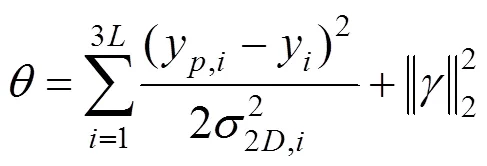
其中,为特征点的数量;y为第个特征点的齐次坐标;y为第个特征点对应的三维模型坐标通过估计的相机矩阵投影到二维坐标系中的坐标显示,即
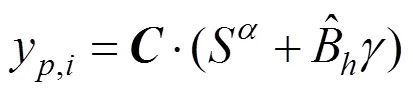
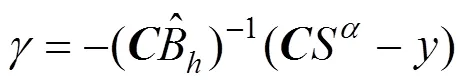
将求解的表情系数带入式(2),通用模型发生第1次形变拟合,使模型与原始图像具有相同的姿态和表情。
对于表示人脸轮廓的边界区域特征点,可根据人脸姿态将剩余18个特征点划分为2类。引入可见的一侧二维轮廓点作为额外对应点,参与PCA形状系数的拟合,建立代价方程,满足人脸真实二维特征点和模型投影到二维图像的特征点的距离最小,如式(3)的损失函数,代替,不同的是三维模型投影到二维空间的特征点的计算,即
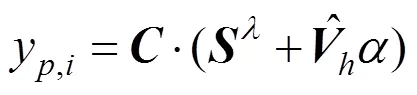
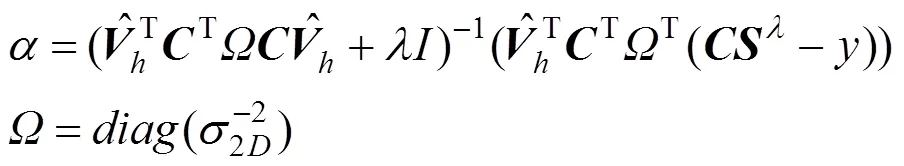
将所得的PCA形状系数代入式(2),通用模型发生第2次形变,其符合视频中人脸形状的拟合变形。至此,算法完成了当前角度和姿态下的三维模型形状的2次拟合,最终生成的模型将用于下一帧数据的迭代拟合,如图5所示。

图5 拟合过程
2.3 纹理提取
模型拟合完成之后,将该帧面部纹理映射到isomap[17],即每个像素均能在三维网格的全局映射中得到体现。isomap是一种将三维模型三角网格投影到二维空间的纹理映射图,其能够保持平面内两点的几何距离不变,如图6(a)所示。

图6 纹理映射与投影
对于映射图中的每个像素点(,),可根据相机矩阵计算出当前人脸姿态,求出该点在当前姿态下是否可见∈(01),若可见,将该点对应的RGB赋值到映射图中的相应位置。在多角度三维人脸纹理映射过程中,基于isomap全局映射网格的紧密对应关系,记录网格中每个点的可见度,初始状态下为不可见=0,若当前角度下计算得=1,则将该点颜色值映射到网格,遍历多角度二维图像,逐步填充映射图中不可见区域,最终生成完整的人脸纹理映射图。
3 实 验
针对本文提出的基于形变模型的多角度重建方法,与当前流行的视频重建算法进行精确度、时间和渲染效果3方面的对比实验。数据集使用300W人脸数据集,平台笔记本配置为Intel(R) Core(TM)i5-7200U处理器,2.50 GHz 主频,8 GB内存,以及NVIDIA GeForce 930MX显卡。
实验1. 精确度对比
随机提取300W数据集中的若干张图片,首先标记出数据集标记的68个特征点位置如图6(b)空心方块;然后用本文方法对SFM三维形变模型进行拟合变形并将模型顶点投影到二维平面,如图6密集实心点,而空心圆则是模型投影的特征点位置。
计算特征点的均方根误差(root mean square error, RMSE)用于衡量模型拟合的精确度,实验中,采集了数据集中不同角度的人脸图像,并与4dface采用模型拟合算法进行对比,如图7所示,结果显示本文方法拟合精确度更高。
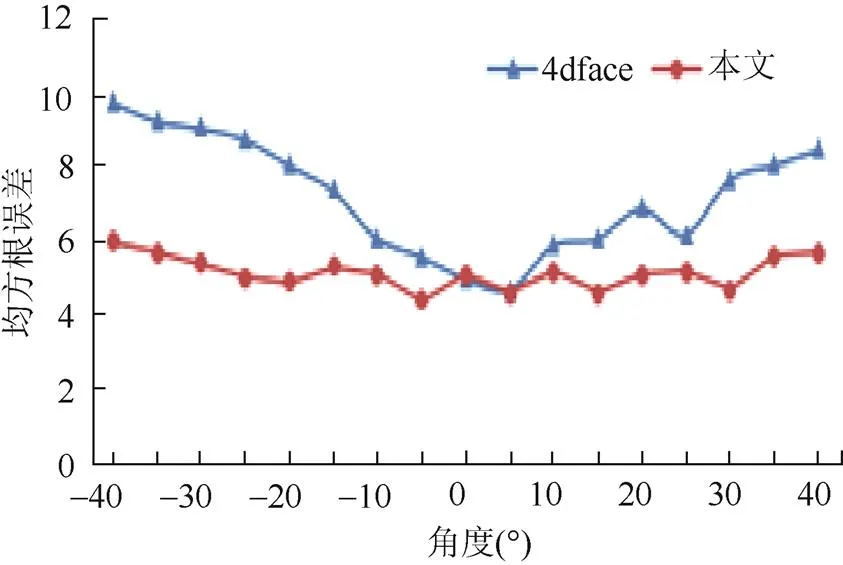
图7 精确度对比图
实验2.时间对比
本文通过改善特征点提取方式,减少迭代次数,优化拟合算法,从而极大地提高了实时性能。4dface的视频图像人脸重建帧率大约在4~7 fps,本文重建的实时帧率约为20~25 fps。

表1 平均耗时对比(毫秒/帧)
表1对比了每一帧图像在特征点提取和三维形变模型拟合过程中平均消耗的时间,证明本文算法在实时性能方面具有鲁棒性。
实验3.渲染效果
模型渲染效果的好坏是三维面部模型最直观的表现。本文提出的纹理渲染是一种由粗到细,随着视频中人脸角度变化逐步填充自遮挡区域的纹理获取方法,相比于4dface采用的纹理叠加取平均的方法,更能保障人脸细节特征不丢失不模糊,且基本还原了所有面部细节,如痘痘、斑点及皱纹;放大局部图像,发现眼部细节未随着角度变化而模糊,如图8所示。
图8(a)展示了人脸的整体重建效果,依次是本文方法多角度重建、单张图的重建及4dface方法的重建;图8(b)放大眼部图像,可以看出本文的方法与4dface相比,纹理更加清晰;图8(c)放大鼻子图像,显示本文方法解决了单张图像重建的自遮挡导致的局部“空洞”问题;图8(d)为本文在表情重建方面的效果。
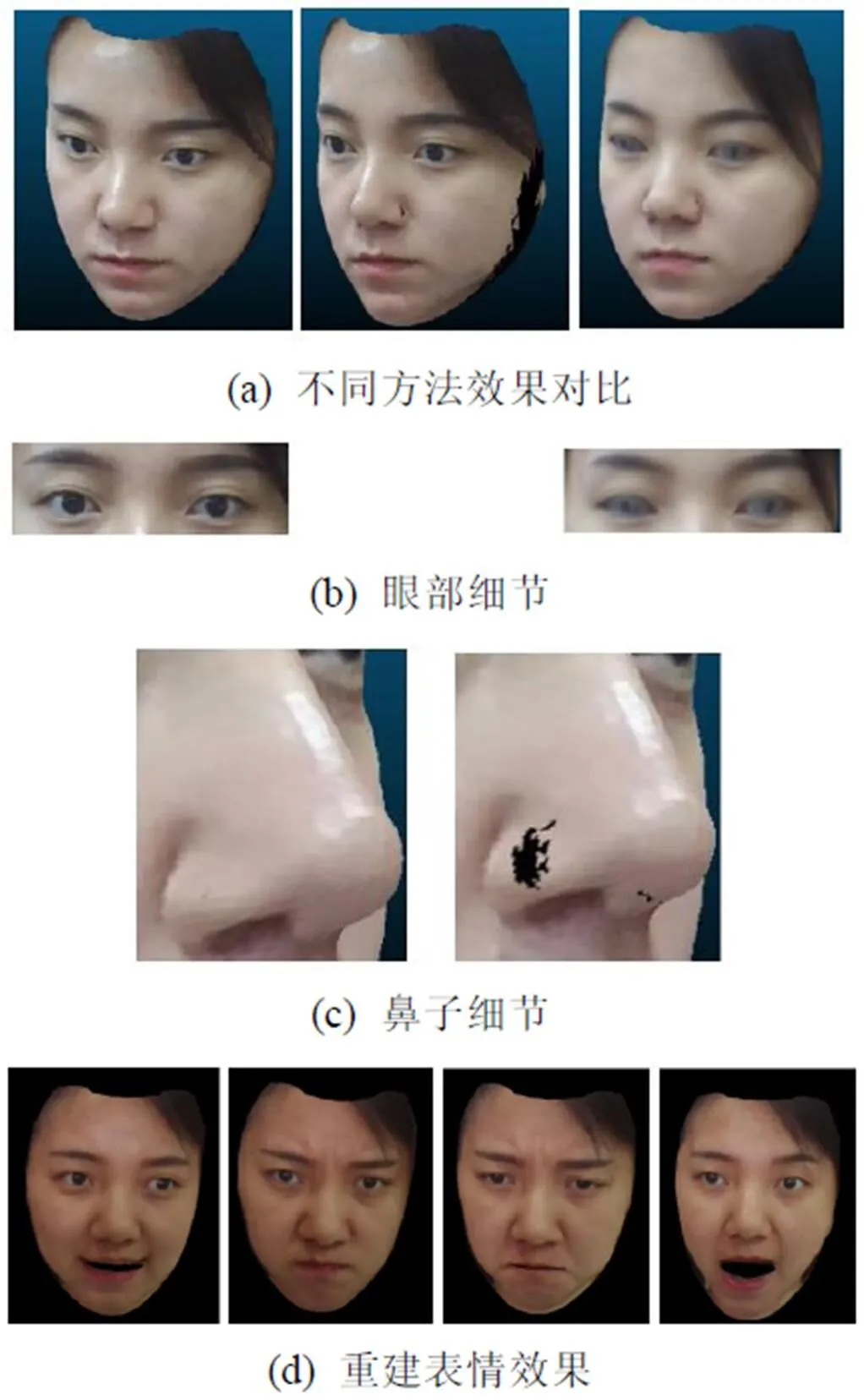
图8 模型渲染效果图
4 结束语
本文通过视频流多角度人脸图像,结合形变模型进行三维人脸模型的实时重建。多角度的人脸拍摄弥补了基于单张图片进行三维重建的自遮挡导致局部信息缺失问题;三维形变模型的方法解决了基于二维图像重建三维模型所存在的深度信息缺失问题。并且,本文的重建是全自动,无需手动干预的实时重建方法,自动特征点的定位算法的引入,提高了特征点定位的准确性和效率。本文提出的形变拟合方算法,与传统拟合过程相比,极大降低了时间开销,同时精确度也略有提高。最后在纹理融合阶段,本文纹理提取方法能够保留面部纹理细节,使重建模型更具真实感。但纹理提取容易受到光照的影响,如果面部光照极不均匀,可能造成重建模型的皮肤纹理深浅不一致的情况,这将是后续研究的工作。
[1] KHOSHELHAM K, ELBERINK S O. Accuracy and resolution of kinect depth data for indoor mapping applications [J]. Sensors, 2012, 12(2): 1437-1454.
[2] 栾悉道, 应龙, 谢毓湘, 等. 三维建模技术研究进展[J]. 计算机科学, 2008, 35(2): 208-210, 229.
[3] HU L W, LI H, SAITO S, et al. Avatar digitization from a single image for real-time rendering [J]. ACM Transactions on Graphics, 2017, 36(6): 1-14.
[4] LIM C P, NONIS D, HEDBERG J. Gaming in a 3D multiuser virtual environment: Engaging students in science lessons [J]. British Journal of Educational Technology, 2006, 37(2): 211-231.
[5] 李小丽, 马剑雄, 李萍, 等. 3D打印技术及应用趋势[J]. 自动化仪表, 2014, 35(1): 1-5.
[6] LI T Y, BOLKART T, BLACK M J, et al. Learning a model of facial shape and expression from 4D scans [J]. ACM Transactions on Graphics, 2017, 36(6): 1-17.
[7] HORN B K P. Height and gradient from shading [J]. International Journal of Computer Vision, 1990, 5(1): 37-75.
[8] BLANZ V, VETTER T. Face recognition based on fitting a 3D morphable model [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(9): 1063-1074.
[9] JACKSON A S, BULAT A, ARGYRIOU V, et al. Large pose 3D face reconstruction from a single image via direct volumetric CNN regression [C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2017: 1031-1039.
[10] ZHU X Y, LEI Z, YAN J J, et al. High-fidelity pose and expression normalization for face recognition in the wild [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 90-98.
[11] TRAN A T, HASSNER T, MASI I, et al. Regressing robust and discriminative 3D morphable models with a very deep neural network [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Computer Society, 2017: 1493-1502.
[12] HUBER P, HU G S, TENA R, et al. A multiresolution 3D morphable face model and fitting framework [EB/OL]. [2018-09-13]. http://epubs.surrey.ac.uk/809478/.
[13] BALTRUSAITIS T, ROBINSON P, MORENCY L P. Constrained local neural fields for robust facial landmark detection in the wild [C]//2013 IEEE International Conference on Computer Vision Workshops. New York: IEEE Press, 2013: 354-361.
[14] CRISTINACCE D, COOTES T. Automatic feature localisation with constrained local models [J]. Pattern Recognition, 2008, 41(10): 3054-3067.
[15] HARTLEY R, ZISSERMAN A. Multiple view geometry in computer vision [M]. Cambridge: Cambridge University Press, 2003: 102-107.
[16] LAWSON C L, HANSON R J. Solving least squares problems [J]. Society for Industrial and Applied Mathematics, 1995, 77(1): 673-682.
[17] TENENBAUM J B. A global geometric framework for nonlinear dimensionality reduction [J]. Science, 2000, 290(5500): 2319-2323.
Real-Time Reconstruction of Multi-Angle 3D Human Faces Based on Morphable Model
CHEN Guo-jun, CAO Yue, YANG Jing, PEI Li-qiang
(College of Computer and Communication Engineering, China University of Petroleum, Qingdao Shandong 266580, China)
The method that uses face landmarks to adjust the 3D morphable model is widely applied in 3D face reconstruction, but the calculation of morphable model is time-consuming and often produces errors. In this paper, we improve the fitting method of general 3D morphable model using 2D landmarks of face, and propose a real-time 3D face reconstruction method with multiple angles of video frames. First of all, we recognize the location of landmarks by the CLNF algorithm with three-layer convolutional neural networks and track the landmarks. Then, the head posture is estimated from five senses of face landmarks, and the blendshape coefficients of the model is updated, which can be used to calculate the PCA shape coefficients so as to promote the deformation of the current 3D model. Finally, we employ the ISOMAP algorithm to extract the texture information of the mesh, and proceed texture fusion to form a specific face model. Experimental results demonstrate that our method has better real-time performance and accuracy in 3D face reconstruction.
3D morphable model; landmarks extraction; blendshape coefficients; PCA shape coefficients; texture fusion
TP 391
10.11996/JG.j.2095-302X.2019040659
A
2095-302X(2019)04-0659-06
2018-11-13;
定稿日期:2018-11-21
国家“863”计划主题项目子课题(2015AA016403);虚拟现实技术与系统国家重点实验室(北京航空航天大学)开放基金(BUAA-VR-15KF-13)
陈国军(1968-),男,江苏如东人,副教授,博士,硕士生导师。主要研究方向为图形图像处理、计算机视觉等。E-mail:chengj@upc.edu.cn
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
动漫星空(2018年9期)2018-10-26
Coco薇(2017年8期)2017-08-03
小天使·五年级语数英综合(2016年12期)2016-12-09
Coco薇(2015年5期)2016-03-29
小朋友·聪明学堂(2015年7期)2015-11-30
奇闻怪事(2014年5期)2014-05-13
