
群体极化还是协商调和?
——维基百科“Islamophobia”词条实证研究
2019-08-31 06:23尚闻一车尚锟
图书馆论坛 2019年9期
尚闻一,车尚锟
1 研究背景与文献综述
1.1 群体极化
随着网络技术的发展和网络社会影响的扩大,特别是由网民开发工具、提供内容和建设社区[1]的Web2.0模式的高速推进,民众在网络空间中社会交往和活动的重要性日益增强。网民参与网络信息处理与加工的门槛大大降低,信息加工与分享得以普及,于是全民的社会交往和活动向网络空间拓展,大大加强了普通民众公共参与的能力和意愿:“如果……在过去25年间个人倾向加强了,公共参与减少了,那么互联网就是扭转这种倾向的中心力量。”[2]在网络社会中,民众发声能力强化,社会也就注入了新的活力。
网络技术也为社会带来隐忧,一种走向是极端思想的汇流和群体暴力的肆虐。古斯塔夫·勒庞(Gustave Le Bon)在《乌合之众》中指出,作为行动群体一员的个人,其集体心理与个人心理有着本质差别,而其智力也会受到这种差别的影响,于是智力在集体中不起作用,而完全处在无意识情绪的支配之下[3]134-136。这种心理如果不加约束,就会导致“群体极化”(Group Polarization)问题。
托克维尔指出,个人主义会随着身份平等的扩大而不断在社会中扩散[4]625-627。在网络社会中,身份平等正以远胜托克维尔所处时代的程度在社会中扩大,个人主义倾向随之伴生,这种倾向倘若任其发展,相互串联,就会形成“群体极化”现象,即“团体成员一开始即有某些偏向,在商议后,人们朝偏向的方向继续移动,最后形成极端的观点”[5]47。受困于信息过载的网民有对信息过滤的需求,网站经营者又有对相似观点的青睐,群体极化因而形成。群体极化藉由“虚拟串联”进一步发酵,腐蚀“社会粘性”(SocialGlue)[5]41-67。
对群体极化问题,学界从不同角度进行讨论。西方学者主要关注其机制的不同阐释。Van Swol认为,群体极化的产生源于个体希望在群体中获得认同,因此倾向持有与群体相似的观点,并通过更极端化的表达彰显其领袖地位[6]。Vinokur等指出,由于人们在不同观点中普遍倾向选择自己了解更多信息的一种,处在群体中的人们会自然地转向这一群体普遍持有的观点[7]。Abrams等则将这一现象归因于“自我归类”(Self-categorization):群体成员选择相同的观点是为了凸显自己从属于这一群体的身份特征[8]。
在对群体极化概念加以理解的基础上,学界近年来一个重要的研究转向是关注群体极化的测量。对此,这一发轫于政治学的概念不仅受到社会学和心理学等方面的关注,人机交互乃至信息系统领域的学者也试图利用本专业的研究范式对群体极化现象加以度量。Isenberg使用实验方法,论证社会比较(Social Comparison)和说服论证(Persuasive Argumentation)过程对群体极化的引发机制,指明后者的影响尤为重要[9]。Friedkin使用选择转向(Choice Shift)来度量群体极化,解释了社会心理学视域下人际影响网络的构成和地位结构对个体选择变化的影响[10]。Dubrovsky等在人机交互视角下,通过实证研究,比较计算机媒介下和面对面沟通中决策小组地位的影响,也研究了这一过程中决策者倾向的变化和决策的转变[11]。Sia等从信息系统研究角度出发,通过实证研究,引入统计学方法度量,以检验计算机辅助交流(CMC)与群体极化问题的关联[12]。
应对网络空间的“群体极化”问题,必须培养一种“协商调和”机制,即公民进行充分沟通和讨论,以实现理性协商作为决策的前提。对此,在《网络共和国》中提出要抑制群体极化的凯斯·桑斯坦(Cass Sunstein)从政府规训角度提出解决方案,认为应由政府促成网络空间中不同意见的协商[5]90。但仅仅依靠政府进行规制是不足的,网络社区同样可能内蕴着能够促成“协商调和”的内部力量。在Web2.0大潮中,以此为宗旨的Wiki技术正在付诸实践,先行者便是以维基百科为代表的在线协作书写(Collaborative Writing)。
1.2 在线协作书写:维基百科
维基百科是全球最具影响力的网络百科全书,作为在线协作书写的代表吸引学界的广泛关注。周庆山等提出维基百科信息自组织模式的六种特征:中立定位、内容和用户开放、协作共享、信息自组织管理和修改、信息增长、用户互动形成规范[13],并注意到其协作书写的基本属性。维基百科的在线协作书写特质,使之成为应对群体极化问题的一个有效尝试。其对群体极化制衡作用的第一种途径,是多元化、差异化的参与者组成。参与者的多元属性是维基百科提高书写质量、特别是抑制群体极化的秘诀所在。Arazy等注意到,维基百科致力于扩大编撰者群体的数量与差异性。而群体差异带来的基于任务的冲突恰恰是提高词条质量的重要因素[14];类似地,Wilkinson等考察了编辑行为和合作行为对词条质量的影响,证实了编撰者的差异性和词条质量呈现正相关[15]。这些差异性不仅有利于词条质量的增强,更增加了维基百科编撰群体的异质性,使之不至于在讨论之初便普遍具备某种偏向,从而抑制了群体极化的风险。
维基百科制衡群体极化的第二种途径,是维基百科协作书写的各种运行机制。Halfaker等对维基百科“拒绝”(reject)机制的实证研究表明:编撰者丰富的经验并不能使他们在避免被拒绝时有所优势;编撰者非常热衷于维护自己的贡献,尽管这种所有权意识行为(Ownership Behavior)不为维基百科的原则所鼓励[16]。他们还在另一个研究中关注了维基百科的“复原”(revert)机制,发现复原机制尽管会在相当程度上打消编撰者(特别是新编撰者)的积极性,但积极影响大于消极影响,有利于维基百科维系其质量[17]。此外,王烽对维基百科拥有的一种独特且相对完善的协商途径——讨论页进行研究,发现“讨论页……不同于条目编辑页直接对条目作出修改,而是通过志愿者对话的形式,对条目的内容与质量进行协商”[18]。这三种维基百科独特的运作模式为词条协作书写提供了有效的协商机制,让各种观点充分交锋,从而促进协商调和。
维基百科多元化的参与者组成和促进观点充分交锋的协商机制引起大量冲突,而这种冲突同时也是抑制群体极化、达致协商调和的关键所在。吴克文分析了互联网群体协作中的冲突模式,提出基于段落编辑历史的文本比较、冲突网络的可视化和内容归属展示三种改进设计[19]。更多学者则针对某一个词条进行案例分析,选取的词条包括英文维基百科“Wukan protests”词条(和对应的百度百科“9·21乌坎村事件”词条)[20]、中文维基百科“南京大屠杀”词条[21]和百度百科“11·13巴黎恐怖袭击事件”词条[22],分别从不同话语框架的建构对话语冲突的反映、在线记忆社群的协作与话语权争夺、在线集体记忆有别于媒介报道的特点等角度,综合利用编辑成员构成及其社会网络分析、词条篇幅变迁分析、讨论页分析等手段进行研究。这些基于某一词条的案例分析并未试图针对群体极化问题进行实证分析,但仍为本文提供了诸多借鉴。
综上所述,对于在线协作书写的代表维基百科与群体极化问题的关联,学界已从参与者组成、协商机制和书写中的冲突三个角度进行了充分的讨论。“正如启蒙运动引导了一个知识创造的新组织模型,新网络也帮助把科学界转变为一个逐渐开放和协作的网络。”[23]163“大规模协作”的先驱维基百科并不掩盖编撰者观点的差异,相反,其运行机制为了避免百科全书成为某些特定群体的“回音室”,着力让拥有不同背景、秉持不同观点的编撰者相互协作。以此为背景,本文通过实证研究,讨论维基百科在线协作书写对群体极化的抑制作用。本文选取英文维基百科“Islamophobia”(伊斯兰恐惧症)这一极具争议性的词条,通过对其讨论页文本的情感倾向分析和对词条编辑用户的社会网络分析,试图回应如下问题:在维基百科运行中,参与协作的编撰者的意见在讨论后是进一步分化,走向“群体极化”,还是会相互调和,实现理想的“协商调和”模式?
2 研究方法
在文献调研的基础上,笔者提出研究框架,见图1。首先,收集英文维基百科词条“Islamophobia”(伊斯兰恐惧症)讨论页(Talk Page)中的自然语言文本数据和词条编辑历史(Revision History)中的编辑数据;接着,展开两个并行的数据分析过程:情感倾向分析和社会网络分析;最后,对数据分析的结果进行评估与阐释。
在研究框架中,两个并行的数据分析过程——情感倾向分析和社会网络分析在逻辑上相互联系、相互补充。情感倾向分析讨论页中文本的情感倾向变化,反映用户针对词条内容进行相互沟通与辩争时情绪和观点的变化,关注用户的讨论行为;而社会网络分析则针对编辑行为,依托词条编辑数据,通过基于词条编辑关系构建的编辑网络,分析用户的编辑关系变化,反映用户对词条进行编辑时立场的转移,关注用户的编辑行为。二者互为表里:编辑行为所处的立场,决定讨论行为所秉持的观点,而讨论后观点的变迁又深刻影响着下一步的编辑行为。本研究选用情感倾向分析和社会网络分析,分别考察词条发展过程中用户讨论行为和编辑行为的变化。通过对这两种行为的度量,分析维基百科独特的“讨论页”功能对用户编辑行为的影响,从而理解维基百科在线协作书写影响网络民主的内在机制。
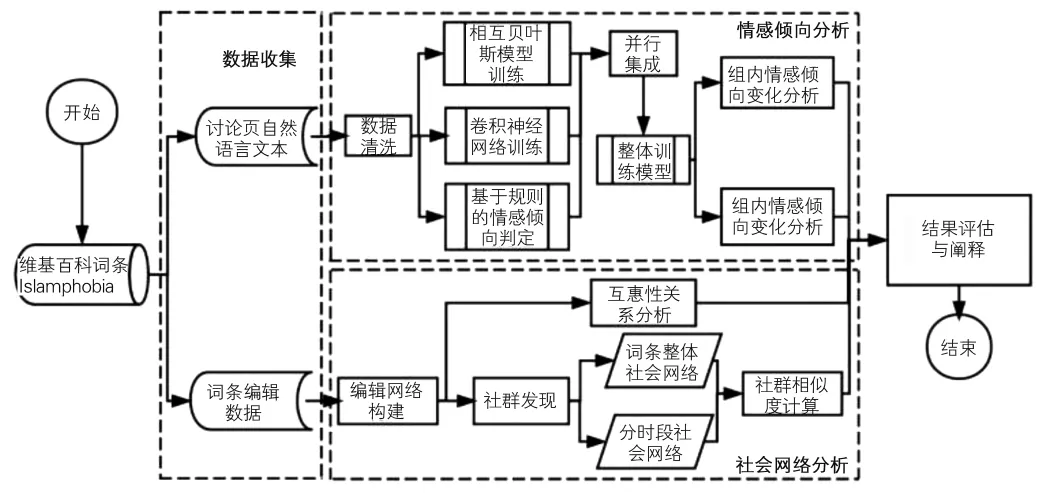
图1 研究框架
2.1 数据收集
本研究选取“Islamophobia”(伊斯兰恐惧症)词条作为数据源。“伊斯兰恐惧症”专指非穆斯林针对伊斯兰信仰的原生恐惧与仇恨,这一说法最早产生于1970年代。2001年“9·11事件”后,随着西方对伊斯兰世界敌视情绪的增长而升温,引起激烈辩争。这一概念影响颇大,John Esposito等甚至撰写专著进行探讨[24]。
“Islamophobia”词条的诸多优点使之成为群体极化问题研究的天然数据源。第一,这一词条极具争议性,关涉文明冲突、宗教对立和族群对话等母题,对其话语权的争夺贯穿词条编辑历史的全过程,符合“群体极化”定义中“团体成员一开始具有某些偏向”的特征;第二,这一词条影响力大,编辑次数逾5000次;第三,促成伊斯兰恐惧症升温的“9·11事件”与维基百科的创建同在2001年,该词条较早吸引了维基百科编辑用户的关注,创建时间早。同时,尽管仅使用一个词条存在样本量不足而导致的效度问题,但该词条较强的代表性和词条内部较大的数据量可以在一定程度上克服样本量的局限性。
该词条自2003年创建以来,每年的编辑次数明显波动:2003年22次;2004年118次;2005年792次;2006年、2007年达到峰值,均超过1000次;2008年后编辑次数高速下降,2008年303次;2009年跌至50次,从此再也没有回到过峰值。密集编辑反映的是词条热度的变迁,当词条热度骤降,群体极化现象便不显著。因此,本研究选取该词条创建、发展至鼎盛期的讨论和编辑历史作为研究对象,截取2003-2007年讨论页中全部的讨论文本和编辑数据进行分析研究。其中,讨论页记录用户有关词条内容的辩争、讨论与协商,提供的自然语言文本数据能够反映处于不同立场的讨论参与者之间情感倾向的变化;而编辑数据记录不同用户对词条修改的全部历史,能够揭示用户之间的编辑关系,反映编辑用户对词条内容话语权的争夺。在数据分析阶段,本文对讨论页文本数据进行情感倾向分析,对编辑数据进行社会网络分析。
2.2 情感倾向分析
对数据收集阶段获取的2003-2007年记录于讨论页的全部文本(词条讨论页Archive1-10及Archive11的前33组数据),首先在预处理阶段进行数据清洗,对换行问题和部分元数据的缺失进行自动修复,并将清洗后的数据以一组对话为基本单元、以讨论对话的缩进作为判定对话对象的标准,创建情感倾向分析的数据源。为了得出每一组对话的情感倾向,研究使用三个模型进行训练。
(1)利用自然语言处理工具NLTK自带的、基于电影评论文本及其对应情感倾向数据训练的朴素贝叶斯(Naive Bayes)模型(使用的数据集为nltk.corpus中的movie reviews),使用NLTK提供的分类器直接进行训练[25]。使用这一分类器是机器学习领域的通用方法,优势在于作为训练数据的电影评论文本较为完备、标签也较为细致:内置的情感分析相关语料既包含整个句子的三元分类标注,也包含重要情感词的情感倾向数值(为[-1,1]区间内的一位小数)。因此,利用NLTK内已集成好的朴素贝叶斯分类器既可以输出情感倾向的三元分类值(-1、0、1,即反对、中立、支持),又可以输出具体的极性值(即[-1,1]区间内的、表示情感倾向具体强度的任意一个小数)。训练数据共有2000条,按照4:1划分训练集与测试集;最终的训练集共有1600条、测试集共有400条数据,准确率达73.5%。
(2)利用卷积神经网络(CNN)训练互联网电影数据库(IMDb)共10662条电影评论文本及其对应的情感倾向数据,选取这一训练集同样沿用机器学习领域通用的做法,旨在利用其完备的数据集以达到良好的训练效果。每条数据由两个部分组成:评论文本和对应的情感倾向(标签为pos或neg,分别表示积极和消极),10662条数据中正负向情感的训练数据各一半。参考Kim在多项任务中获得“顶尖水准”(state of the art)的模型[26],对这些以txt格式存储、包含文本和类别标注的训练数据进行深度学习。在具体实现中,使用Tensorflow作为深度学习框架,构建包含词嵌入(Word Embedding,将自然语言词语转化为高维向量)层[27-28]、卷积层、池化层以及随机失活方法和softmax决策函数的模型,采用L2正则化技术避免过拟合。模型在词嵌入层设置窗口大小为5、词语向量维度为128,共训练200轮次(epoch),每一轮次150批(batch)。同样按照4:1划分训练集与测试集,最终的训练集为8530条、测试集为2132条,通过调参,准确率可达到85%。
(3)考虑到上述两种基于机器学习的方法所使用的训练数据都是电影评论文本,而非Wikipedia讨论页文本,因此本研究使用基于规则的方法,以词语为特征进行基于规则的匹配,从而为情感倾向判定提供补充。研究采用在WordNet词集[29]基础上扩展而出、被广泛应用于情感识别任务的情感语义网词集SentiWordNet[30-31]。这一词集共包含100000多个词条记录,每个词条记录由词性、词条编号、正向情感值、负向情感值、同义词词条名和注释组成。因为词集共包含名词、形容词、动词和副词四种词性,每个词语可以具有多个词性,在不同词性下对应的情感倾向值也不同。所以,本研究通过词性识别和词形还原(基于NLTK工具包的句法分析和词形还原工具实现),得到文本中每个词语的词性和原始词形(去掉复数、动词时态等),然后通过停用词表进行词语过滤,将选中的词语根据词性在词集中搜索其对应的正负向情感倾向值,将段落中所有选中词语的正向情感倾向值和负向情感倾向值分别累加,根据二者的相对大小关系判定每段对话的情感倾向。
上述3种模型是情感分析中最为主流、性能最为优越的几种模型。不过,这3种模型各有优劣,为进一步提高结果的信度,采用集成学习中并行集成[32]的方法,将3个模型结合起来以提高准确率。由于前两种模型均为基于电影评论数据进行机器学习得到的模型,为平衡机器学习方法和基于规则的方法,将基于规则的模型3赋予2倍的权重,3个模型的最终权重比例为1∶1∶2。通过加权和集成,得到最终的情感分析结果:对每一条评论,在1(正向情感)、0(中立情感)和-1(负向情感)中输出一个情感倾向的取值。
2.3 社会网络分析
对2003-2007年全部编辑数据,提取每次作出编辑行为的用户ID及其编辑时间,按照时间顺序排列。然后,对每次编辑,以作出编辑行为的用户作为发起方、以该次编辑所对应的上一次编辑的用户作为接收方,建立一组关系(其意义为,用户的编辑行为代表作出这次编辑的用户对上一次编辑的用户的修改)。以这些关系为数据源,分别建立基于全部数据的词条整体社会网络,以及基于2005年及更早、2006年和2007年三段编辑数据(这三段数据大致相等)的3个分时段子网络(按照时间顺序依次命名为分时网络A、B、C)。
首先,对网络中的互惠性关系进行分析。互惠性是度量有向网络中两个节点相互连接程度的指标[33]55-56。由于本文中的社会网络由以时间为顺序的编辑数据构建,网络中的互惠关系实质上是一种“A修订B,B反过来修订A”的交替修订关系,反映的是尖锐的冲突和话语权争夺。剔除网络中反映自反关系的数据(即连续两次修改都由同一个用户作出,代表用户进行自我修订)后,本研究首先计算词条整体社会网络互惠性关系的占比;随后,对三个子网络分别计算互惠性关系的占比,从而得到互惠性关系占比变化的趋势。
其次,分别对整体社会网络和3个子网络,使用在时间效率和准确性上都很优越的Louvain模块化算法进行社群发现,以探测复杂网络中的社群结构。这一算法分为两个阶段:第一阶段将节点不断加入到能使局部模块性(Modularity)达到最大化的社群中,第二阶段则从第一阶段的结果出发构建一个新的网络。二者不断迭代,直到各个节点所属的社群不再发生变化。这一用于计算模块性的公式为:
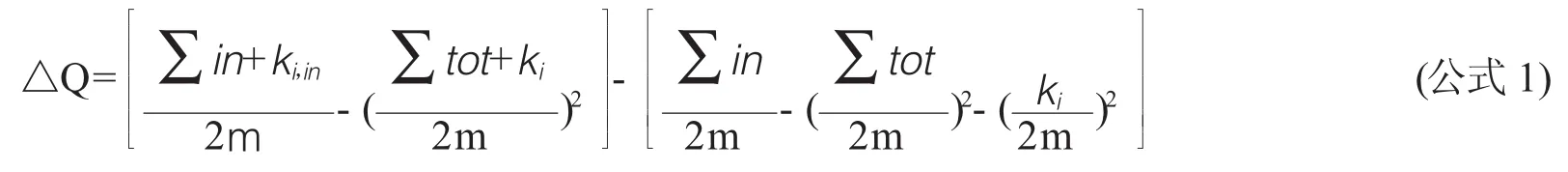
其中,△Q为模块性的增量,∑in为节点被归入的社群内部所有边的权重之和,∑tot为指向这一社群中所有顶点的所有边的权重之和,ki为指向顶点i的所有边的权重之和,ki,in为从顶点i出发并指向这一社群内所有顶点的所有边的权重之和,m为整个网络中所有边的权重之和[34]。整体社会网络社群发现的结果被呈现于开源可视化和网络分析平台Gephi[35]中,利用Force Atlas算法进行布局,并基于Laplacian动力(Laplacian Dynamics)方法[36]对社群划分后的网络进行可视化呈现。
最后,对3个分时网络的社群发现结果进行横向比较,计算3个网络间的社群相似度。这种相似性计算实质上是数据结构“图”的相似性计算。衡量相同用户在不断时段所属社群的关系,实质上就是不同图的公共顶点间边的重合度的计算。在3类主流的图的相似性算法(精确计算[37]、基于图的特征属性计算[38]和基于顶点相似的迭代计算[39])中,因为本研究处理的数据集较小,不受到算法复杂度的过度制约,无需降低精确度以换取时空代价,所以采用复杂度和精确度都较高的精确计算方法,比较图公共顶点间边集合重合的比例,将这一比例定义为社群相似度。此处,边的重合的意义为:同时出现在两个子网络中的用户,在两个网络中属于同一个社群。
3 结果讨论:在线协作书写中的协商调和
3.1 情感倾向:组内趋向激烈,组间趋向缓和
对本文2.2中得到的情感分析结果,分别进行组内情感倾向变化分析和组间情感倾向变化分析。对前者,选取在同一组讨论中至少有两次对话的两个用户,比较其前半段对话与后半段对话的平均情感倾向;对后者,选取至少在两组讨论中有过对话的两个用户,比较其在前一半讨论中与后一半讨论中的平均情感倾向(若同一组讨论中对话次数或讨论组数为奇数次,则将处于中间位置的一次对话或讨论归于前半段对话或前一半讨论)。
在组内比较中,在剔除同组讨论前后半段对话情感倾向一致的数据后,以同组讨论中两位用户对话的次数为标准,分别计算不同次数下情感倾向上升的比例。如表1所示,组内情感倾向上升的总数目占据少数。其中,在同组讨论中两名用户有2~3次对话时,后半段对话相对于前半段情感倾向上升的比例在50%左右;而有4~8次时,情感倾向上升的比例下降到42.42%,明显低于情感倾向下降的比例;当同组讨论对话数目进一步增多到9次及以上,这一比例继续下降到41.67%。这一结果表明,当两名用户在同一组讨论中进行少量(2~3次)对话时,其情感倾向在讨论前后的变化并无明显的偏向,上升与下降的可能性相仿;随着对话的深入,在往复交流中,情感倾向越发可能随着讨论的持续而趋于下降。总的来看,两名用户在同一组讨论后的情感倾向相对于讨论前会趋于激烈。
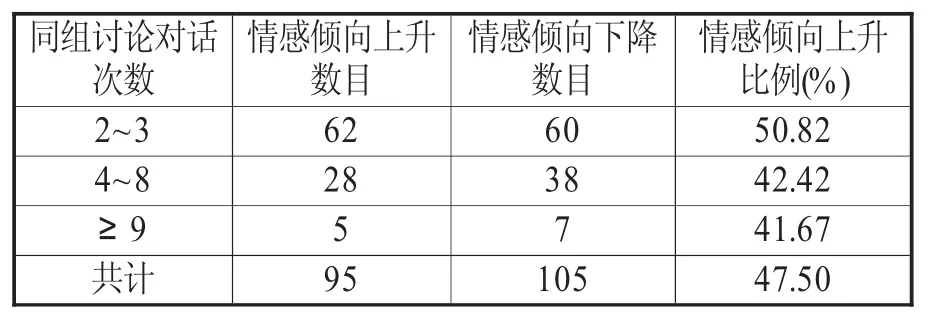
表1 组内情感倾向变化
在组间比较中,同样剔除前一半讨论与后一半讨论平均情感倾向一致的数据,以两位用户参加讨论的组数为标准,分别计算不同组数下情感倾向上升的比例。如表2所示,组间情感倾向上升的总数目占据多数。其中,在两名用户参与2~3组讨论时,后一半讨论相对于前一半,其情感倾向上升的略高于50%;而在参与4~8组时,情感倾向上升的比例迅速增长到60%,明显高于情感倾向下降的比例;不过,这种偏向不会始终持续,当两名用户参与讨论的组数继续增多(达到9次及以上)时,情感倾向的偏向出现逆转,上升的比例小于下降的比例。
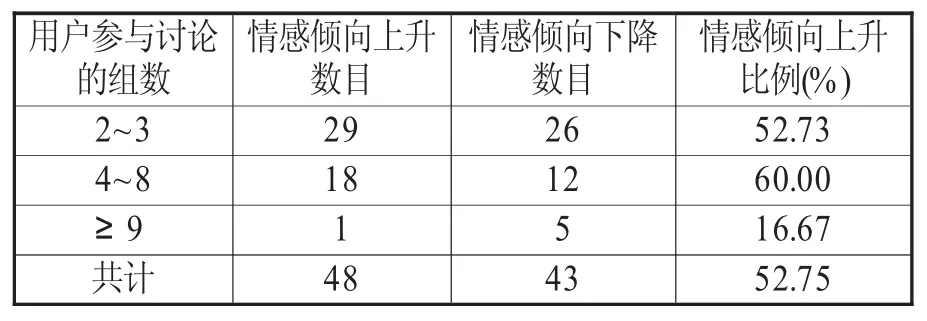
表2 组间情感倾向变化
组间分析的结果表明,当两名用户参与讨论组数较少(2~3组)时,在靠后讨论中的情感倾向比靠前讨论中的倾向,上升的可能性略高于下降的可能性。随着两名用户讨论话题的增多,彼此之间更加熟悉、更加理解,情感倾向上升的可能性大幅增加,明显高于情感倾向下降的可能性。但当两人继续围绕不同的话题讨论,在往复交锋中,情感倾向下降的可能性反而会逆转、超越上升的可能性。不过,这一异常情况仅涉及6组数据,可能属于样本量规模过小而出现的偶然情况。这一异常并不妨碍组间比较的总体结论:当两名用户进行2组或以上讨论时,靠后的讨论的情感倾向相对于靠前的讨论整体会趋于缓和。
综合上述结果可以发现,在组内比较时,随着时间的推移,用户讨论的情感倾向更多地向负向移动,情感趋于激烈。而在组间比较时,随着两名用户参与讨论次数的增多,情感倾向更多地往正向移动,情感趋于缓和。
3.2 社会网络:用户社群重组,编辑关系协调
对本文2.3所建立的整体社会网络的互惠性关系进行分析,发现互惠性关系共有712条,占全部非自反性关系的35.55%。这意味着:平均每三次编辑行为,就有一次以上是对针对自己的修改而反过来所作出的重新修订。这一比例反映出对“Islamophobia”词条极为激烈的话语权争夺。大量编辑用户并不满意他人对自己所编词条文本的修改,因而要对新的版本再行改正。当然,第二次修改往往并非对他人的修改作简单撤销、恢复原状,词条也正是在这样的交替修改中日臻完善。然而,这种对他人修改自己版本的重新修订,仍能非常清晰地反应出对词条编辑主导地位的争夺。
由表3可见,分时网络的互惠性关系占比呈现出鲜明的下降趋势:从分时网络A的41.72%下降到分时网络B的38.81%,并在分时网络C中骤降为26.82%。这一趋势表明,在他人对自己的版本进行修改后,越来越少的用户会立即反过来对新的版本再行修订。尽管直到2007年,互惠性关系的占比依然可观,但话语权争夺激烈度呈现出逐年降低的趋势仍是极为明晰的事实。随着时间推移,更多用户选择接受他人对自己的修订。这一方面反映出原始编辑用户对针对自身的修改愈发乐于接纳;另一方面则反映出第一次修改本身趋于理性。二者相辅相成,共同促成编辑关系逐渐由对立变为协调。对整体网络社群发现的结果将整体网络分成7个社群,如图2所示。
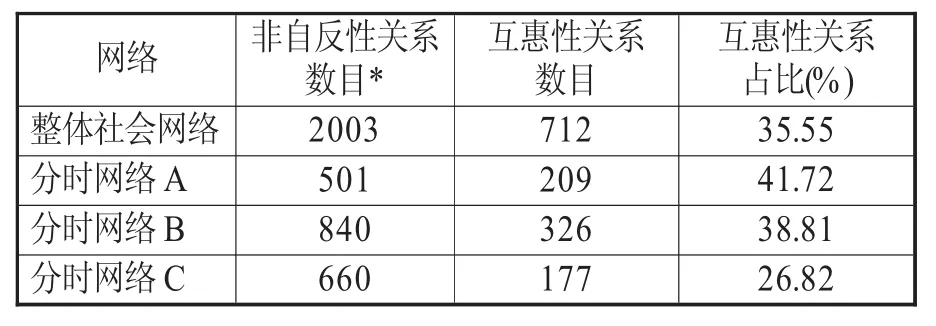
表3 互惠性关系占比
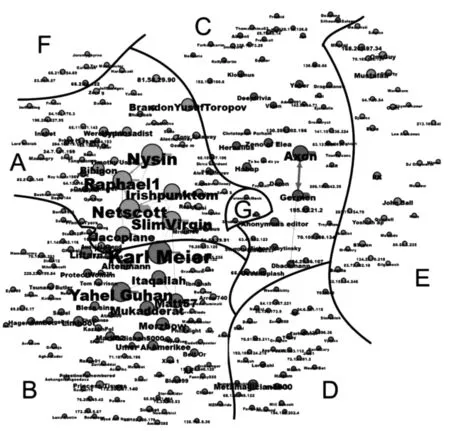
图2 “Islamophobia”词条编辑的社会网络
将对50位及以上用户作过修改的用户定义为核心用户,并将对20位及以上用户作出过修改的用户定义为活跃用户,可以发现:尽管并不存在一位或几位起到绝对主导地位的用户,但用户的社会网络仍很不平衡。大部分编辑行为由少量核心用户和活跃用户作出,而这些用户的分布非常集中。6位核心用户全部处于社群A(Nysin、Netscott、 Raphael1、 SlimVirgin) 和 B(Karl Meier、YahelGuhan)中;而22位活跃用户中,处于社群A和B的也分别有9位和10位,另外3位分处社群C和D中。当用户被分为一个社群时,表示这些用户间有密集的相互编辑行为。因此,对整体网络社群发现的结果揭示:“Islamophobia”词条2007年及以前的编辑行为主旋律是以一批核心用户和活跃用户为领导、围绕两个“核心战场”展开的激烈交锋,并在次中心的其他战场上开展不同程度的话语权争夺。
对三个分时网络间社群相似度的比较,首先要抽取分时网络的公共顶点。分时网络A与C仅有两个不存在公共边的公共顶点,且这两个顶点同时存在于分时网络B中。这表明不存在同时活跃于2005年及以前和2007年,却在2006年没有作出任何编辑行为的用户,显示出用户编辑行为的连续性。在时间上连续的分时网络A与B和B与C分别有10个和14个公共顶点,这些顶点间分别形成了29条和43条边。但是,两个网络(组)公共顶点组成的这些边中分别仅有3条和6条公共边,因此,两组分时网络的社群相似度都处于0.1~0.15这一极低的区间内(见表4)。由于社群相似度由公共顶点间边的重合比例定义,这一数据意味着在上一个时间区间内属于同一个社群中的用户,在下一个时间区间的网络中有极大概率分属于不同的社群,亦即:在两个不同时段内,编辑用户很少与同一位用户发生密集的相互编辑关系,而是会转向新的用户。
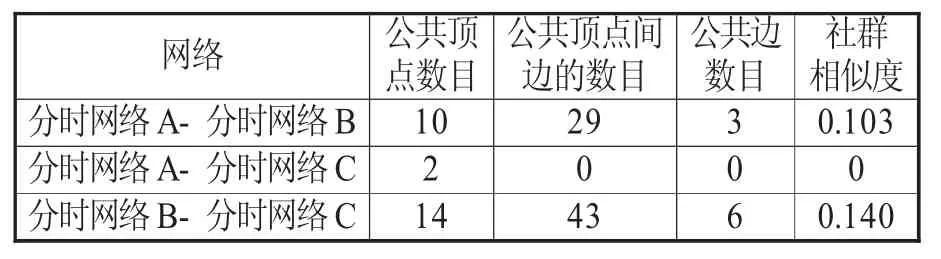
表4 网络间社群相似度
这一发现进一步说明了互惠性关系分析中得到的结论。在一个时段中产生频繁相互编辑关系、进行激烈话语权争夺的两位用户,有的在下一个时段中仍然活跃,但却不再频繁地相互编辑。这表明,在词条修订的过程中,大部分的争论都能够随着时间的推移达成共识或妥协。对一位活跃于两个时段的编辑用户而言,上一时段的辩争并不持续到下一时段。新的争论随着时间的推移继续产生,尽管用户过去的辩争对手依然在频繁参与(词条)编辑,但在新争论中,其辩争对手却往往出现了变化。在编辑的过程中,编辑用户的社会网络不断重组,反映出编辑关系从对立到协调的变化趋势。
4 结论
通过对英文维基百科词条“Islamophobia”讨论页文本的情感倾向分析和词条编辑用户的社会网络分析发现,就讨论页文本的情感倾向而言,在同一组讨论内用户的情感倾向随着时间的推移趋于激烈,而在不同组间的讨论中却趋于缓和;就词条编辑用户的社会网络而言,反映“A修订B,B反过来修订A”的互惠性关系比例逐年降低,编辑网络也大规模重组,即与某一编辑用户同属于一个社群、有着密集相互编辑关系的用户组成,在不同时段中呈现出明显的差异。
这些发现表明,讨论页中用户之间的讨论微观上趋向激化,宏观上趋向缓和;用户之间的编辑关系由对立变为协调。微观的激化与宏观的缓和、编辑关系的协调之间并不矛盾。相反,正是这样一种激烈讨论与迭代修订的过程,构成维基百科独特的协商调和机制:它不掩饰观点的分歧,反而通过提供讨论页这一渠道促成迥异观点间的充分对话。这种对话在某一组讨论的过程中趋向激化,却让对立的观点在尽情碰撞中促成理解之同情,“人们因此持续扩大自己的视野,并且经常以另一种观点来测试自己原有的观点”[5]137,推动不同立场间的相互理解。于是,一组讨论中愈发激化的情感倾向没有让辩争的双方彼此对立,加剧用户编辑过程的话语权争夺。与之相对,随着时间的推移,用户的编辑行为整体趋于理性。于是词条质量在讨论中得到提高,协商调和在辩争中得以实现。
本研究最突出的局限性在于:尽管从计算社会科学角度进行的实证研究证明,在“Islamophobia”编辑中观点的激烈碰撞会促成整体讨论趋向缓和、编辑关系趋向协调,但这种促进关系发挥效用的具体机理仍有待详细说明。另外,对某一个词条讨论和修改历史的深度挖掘能够证明在这一词条的发展过程中,协商调和而非群体极化占据主流,却不足以说明由以宗教为议题的“Islamophobia”词条得到的这一结论,普适于浩如烟海的各个主题的维基百科条目。而使用计算机自然语言处理技术尽管能够部分反映情感倾向,但计算机技术对复杂的自然语言文本的理解仍有较大的局限性。
针对未来研究的改进方向,最直接的是利用定性方法对词条讨论中观点的碰撞是如何导致词条编辑行为趋于理性的具体机理加以阐释。此外,在维基百科其他词条中进一步验证本研究通过个案得到的结论,以增强其说服力;使用维基百科讨论页文本作为训练数据进行机器学习,以优化集成学习中机器学习模型的效果,从而提升情感分析算法的整体信度,也是本研究方法论层面的一个改进方向。最后,对于组间情感倾向变化在两位用户进行9组及以上对话时异常值出现的原因,需要用其他数据加以验证。
本研究的意义在于:通过对“Islamophobia”词条的案例研究,对网络社会的重要议题——群体极化问题从实证的角度作出了验证。从方法论意义上,研究通过集成机器学习算法和基于规则的方法并行集成建立的模型进行情感分析、通过社群发现算法和图的相似度计算的思想进行社会网络分析,所建立的研究框架具有独创性;同时,这一框架具有较强的可复制性,可以在类似的计算社会科学研究和其他领域中推广。从内容意义上,研究初步证实了维基百科存在一种讨论与修订相结合、在观点激烈交锋中促成编辑行为协调的协商调和机制。这一在线协作书写中的机制对于抑制群体极化问题存在重要意义,值得新时期网络社会建设借鉴。
在新时期,各种立场的声音在网络上层出不穷,其中褊狭、激烈的声音不在少数,稍有不慎,就会因虚拟串联而无限放大。所以,警惕网络空间中的群体极化,保证社会粘性,是不容回避的问题。但是,即便是提出“群体极化”盛世危言的桑斯坦也认为:尽管新科技可能造成莫大的危险,但“它们带来的希望远多于危险”[5]142。一个由政府调控进行外部规训、(由)网络空间建立内部协商机制的环境,足以使网络这一新科技成为协商沟通机制的推动者,一如文字、纸张与印刷术在历史中起到的作用。维基百科便是建立这种环境的一个绝好范本。Rask指出:“尽管通常来说,维基百科更适合来自发达国家的参与者。但发展中国家的参与者一样可以从中受益。”[40]我国当然不必对维基百科的模式亦步亦趋,但通过讨论页刻意凸显而非掩盖群体差异、在激烈的讨论中让观点充分交锋而达成协调的理念,却是利用在线协作书写以发展协商调和、抑制群体极化的良好思路。
英国思想家约翰·密尔(John Stuart Mill)说:“(与不同于自身的人、不熟悉的思想模式)沟通一直是,尤其对现在来说,是我们进步的主要来源之一。”[41]135并不过分地说,维基百科正是一个在网络空间中促成这种沟通,抑制群体极化的有益尝试,其理念与运行机制,值得持续地研究、反思与借鉴。
猜你喜欢
现代财经-天津财经大学学报(2022年5期)2022-06-01
航天电子对抗(2022年2期)2022-05-24
北京航空航天大学学报(2021年9期)2021-11-02
英语文摘(2021年8期)2021-11-02
电脑知识与技术·经验技巧(2020年3期)2020-05-07
航天电子对抗(2019年4期)2019-06-02
读者·原创版(2015年11期)2015-03-01
意林(2014年2期)2014-02-11
互联网天地(2012年12期)2012-11-18
