
关联挖掘技术支持下的数据库优化查询算法设计
2019-08-26 01:35刘向东
数字技术与应用 2019年5期
刘向东
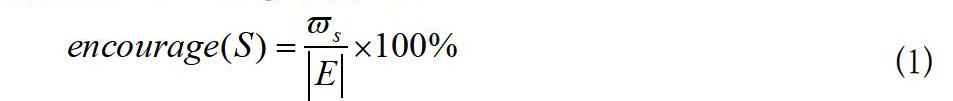
摘要:在一些大型数据库中,冗杂数据会导致查询精确度降低。基于此,提出关联挖掘技术支持下的数据库优化查询算法设计,包括数据库获取优化分析、内存数据查询的优化、关联规则频繁集的有效建立。实验证明本文设计算法与传统算法相比,在同等网络数据规模情况下,前者对于数据查询的判定精确度要高于后者,具有较高的有效性。
关键词:关联挖掘技术;数据库优化;查询算法;精确程度
中图分类号:TP183 文献标识码:A 文章编号:1007-9416(2019)05-0137-02
0 引言
伴随计算机网络与国民经济的快速发展,分布式系统的应用范围也随之加大,在进行数据挖掘的时候,分布式关联挖掘技术在每一个节点之间的协同和竞争、信息应用与计算机网络通讯效率上出现的问题逐渐加重,严重影响到关联挖掘技术的普及[1]。由于目前国内计算机技术的日益进步,对于一些大型数据库的使用要求也越来越多,一些大型甚至是超大型的数据库,在金融,文化,生物,航天航空等诸多专业领域获得了极其广泛地使用[2]。
1 关联挖掘技术支持下的数据库优化查询算法设计
1.1 数据库获取优化分析
數据库查询模块在计算应用的时候,首先需要做的是将运行环境进行初始化设置,其中包括环境参量的初始化、匹配文件的初始化、公共参数以及数据缓存的初始化[3]。之后再进行网络设施的初始化,最后实现数据库查询模块的工作流程,具体包括数据流的还原、阻拦一部分数据包以及关键数据包的相关处理分析和调整[4]。关键数据包的相关处理分析和调整主要是对功能不一样的数据包进行调改。数据获取过程中获取的主要内容是有关数据来源的记载信息、数据具体特点、获取数据需要等待的时间等。
1.2 内存数据查询的优化
本文分析的是关联挖掘技术支持下的数据库优化查询算法,在查询算法的基础上完成节省储存空间的实施效果,其中利用实时数据库的运算规则和查询算法完成优化查询的一系列设计,有关规则需要按照数据链接外表与基表的基本规则,来优化计算路径,如果是多链条链接,就仅仅需要判断表内数据的链接状况即可。
1.3 关联规则频繁集的有效建立
数据之间的关联原则某种程度上规定了数据的一些独特特征,当数据之间出现隐匿选调规则的时候,相对应的特征区内就会出现隐匿数据[5],从而组建成一个关联数据集合以便用来描述相匹配的关联原则:一旦全部数据组建的数据集合表示为:,包含系统内标记的全部事物,组成数据库,数据U的集合对应的是数据(i=1,2,…,n)。U的任何一个数据集合S表示E的数据任务集合,|S|=h则表示集合S的h项。若是E集合内中的一个数据,而且,则能够立即判断出数据中包含数据目集合S。数据集S的激励点能够通过数据集S在数据集合E内的任务数表示。数据集X的激励点用encourage(S)表示:
式(1)中,代表数据集合E的任务数,如果一数据S的激励点encourage(S)不会小于最低激励点,那么就可以判断出S是一个频繁数据集,否则S就是作为一个非频繁数据集而存在。按照以上具体定义,就可以得导一下的定理:
设S,W是数据集E中的任务集:
首先,如果,那么encourage(S)≥encourage(W)。
其次,当的时候,一旦S组委非频繁数据集而存在,那么W也属于非频繁数据集。
最后,当,如果W属于频繁数据集,那么S也作为频繁数据集而存在。
2 实验与效果分析
为了更加清楚、具体的看出本文设计算法的应用效果,特与传统的数据库查询算法进行对比,对其数据查询的精确度进行比较。
2.1 实验准备
为保证试验的准确性,将两种数据库查询算法设计置于相同的试验环境之中,进行数据查询的精确度能力的相关试验。试验环境设置内容见表1。
2.2 实验结果分析
试验过程中,通过两种不同设计同时在相同环境中进行工作,分析其数据查询的精确能力变化。效果对比图1所示。
通过实验结果的对比,可以明显看到,本文设计数据库优化查询算法与传统数据库查询算法相比,在同等网络数据规模情况下,前者对于数据查询的判定精确度要高于后者,且发挥较为稳定,实验证明,本文设计的数据库优化查询算法具有较高的有效性。
3 结语
本文对关联挖掘技术支持下的数据库优化查询算法设计进行分析,根据关联挖掘技术原理与公式计算分析数据,实现本文设计。实验论证表明,本文设计的方法具备极高的有效性。希望本文的研究能够为关联挖掘技术支持下的数据库优化查询算法设计的方法提供理论依据。
参考文献
[1] 林基明,班文娇,王俊义,童记超.基于并行遗传-最大最小蚁群算法的分布式数据库查询优化[J].计算机应用,2016,36(03):675-680.
[2] 张亚玲,王婷,王尚平.增量式隐私保护频繁模式挖掘算法[J].计算机应用,2018,38(01):176-181.
[3] 朱益立,邓珍荣,谢攀.基于有向无环图的频繁模式挖掘算法[J].计算机工程与设计,2017,38(05):1237-1241.
[4] 吴洋,温佩芝,邓星,朱立坤.一种改进的分布式数据库查询优化遗传算法[J].桂林电子科技大学学报,2015,35(03):217-221.
[5] 刘平,王晓,刘春.小差异化图像数据库中的特定特征挖掘方法设计[J].沈阳工业大学学报,2017,39(05):562-566.
