
基于树的物联网标识识别算法的研究
2019-08-22 10:00:24江凌云
计算机技术与发展 2019年8期
赵 迎,鲁 阳,凌 静,江凌云
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
物联网从发展到现在,一直是在各自垂直领域内构建出封闭的,紧耦合的竖井式的系统,各个系统之间缺少统一的交互。这些系统具有不同的系统架构和数据模型,系统之间的信息不能共享,互操作性成为了一个显著问题[1]。为了解决异构系统之间的交互,邹俊伟提出了Restful的开放式架构[2],衍生出了基于SOA的解决方案[3-4]。识别给定物品标识成为解决异构平台系统互通的首要问题。
国内外不同地区不同组织提出了适用于自身服务类型的标识符设计方案,以构成完整的标识体系。主流的有美国EPC global提出的EPC(electric product code),日本uID中心提出的uCode(ubiquitous code),韩国TTA(telecommunications technology association)提出的mRFID(mobile RFID code)和中国商务部提出的CPC(commerce product code)和Ecode(entity code),以及ITU和ISO/IEC提出的OID等。每个体系都十分完整,具有良好的兼容性和可扩展性,而且在所属地区和所属领域有着长久的发展和深厚的根基,没有一方吞并另一方的可能。但在万物互联的物联网时代,为打破信息壁垒,便于任何用户都可以查询或追踪到任何种类任何形式的信息,减少物流、经销、管理等方面的成本,需要实现不同标识体系间的互联互通,最大程度地做到信息共享。
实现不同标识体系间的互联互通的最大问题在于各标识体系使用的标识的异构性。为解决这个问题,文中提出了一种基于树形结构的匹配算法。使用Hash算法结合基于正则表达式的模糊匹配算法进行匹配过程。提出树型结构的匹配模型,降低了匹配次数,提出同层优先级排序的方法,使得信息量大的标识规则优先匹配,提高了匹配效率。由于每个标识体系结构完整,识别出标识符对应的体系后便可以快速完成物品信息的解析获取。
1 相关工作
2014年G. Deng提出了一种基于特征提取机制的识别算法[5]。通过长度,单字节和扩展规则实现标识特征的提取。除了自定义的特征提取算法以外,还有字符串匹配算法。常见的字符串匹配方式有字符串相似性算法和哈希算法。
(1)相似性算法。
常用的相似性算法有余弦相似性算法,如式1:
(1)
其中,A、B为向量空间中的两个向量。
当使用它来做字符串相似性度量时,需要先将字符串向量化,通常使用词袋模型[6]进行向量化。例如:StringA=“apple”,StringB=“app”,词包为{‘a’,‘e’,‘l’,‘p’},若使用0,1判断元素是否在词包中,字符串可以转化为:StringA=[1111]和StringB=[1001]。根据余弦公式,可以计算字符串相似性为0.707。其他相似算法包括欧氏距离算法、编辑距离算法、海明距离算法、Dice距离算法等。但这些算法都不适用于该场景,无法确定参考对象,也就无法计算相似度。
(2)哈希算法。
哈希算法具有查找时间快的优点,常见的哈希算法有:BKDRHash、APHash、DJBHash、JSHash、RSHash。比如最常见的BKDRHash算法,公式见式2。
Hash[i] = Hash[i-1]*x+s[i]
(2)
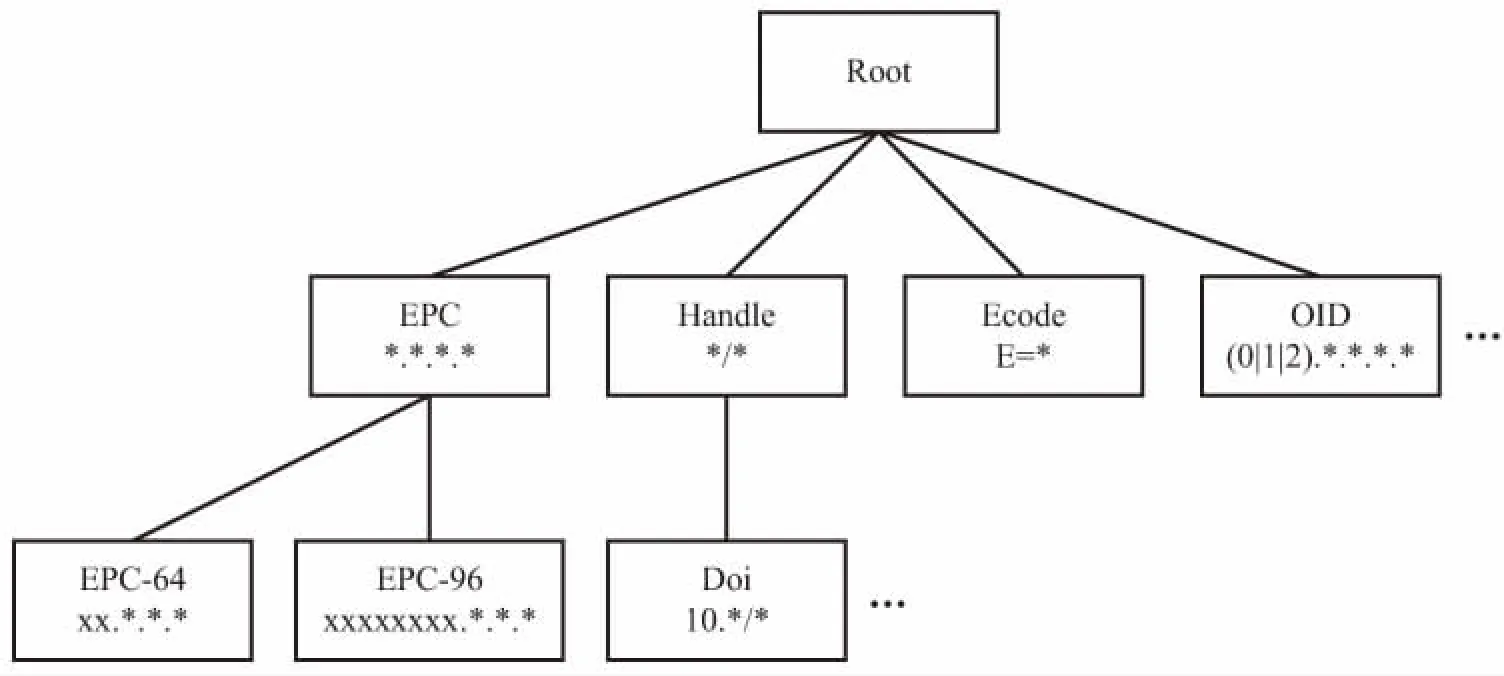
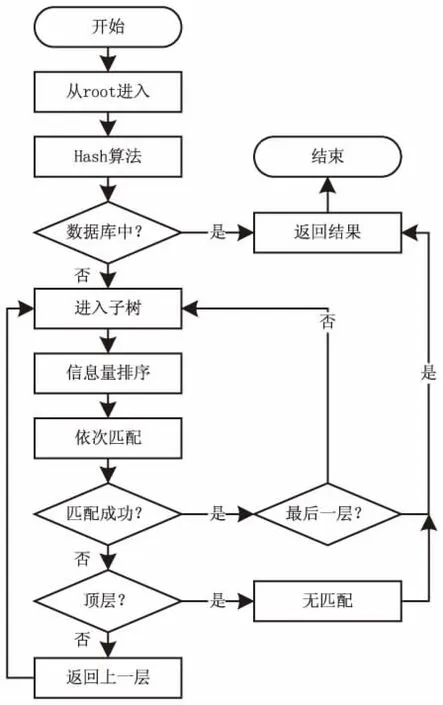
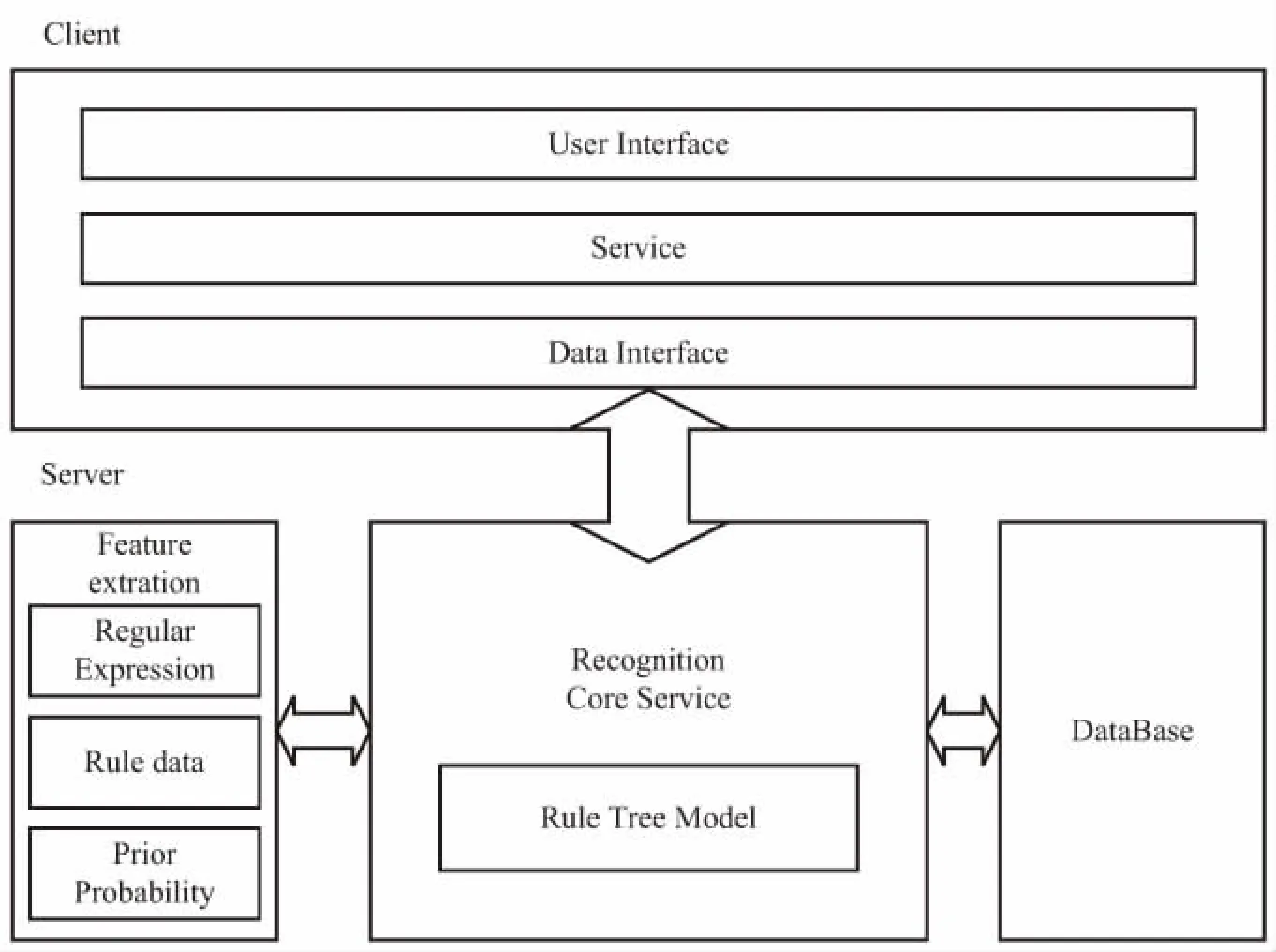
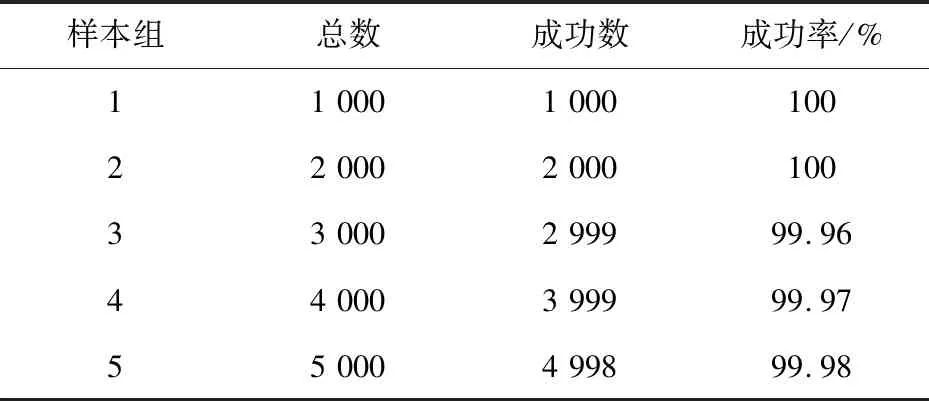
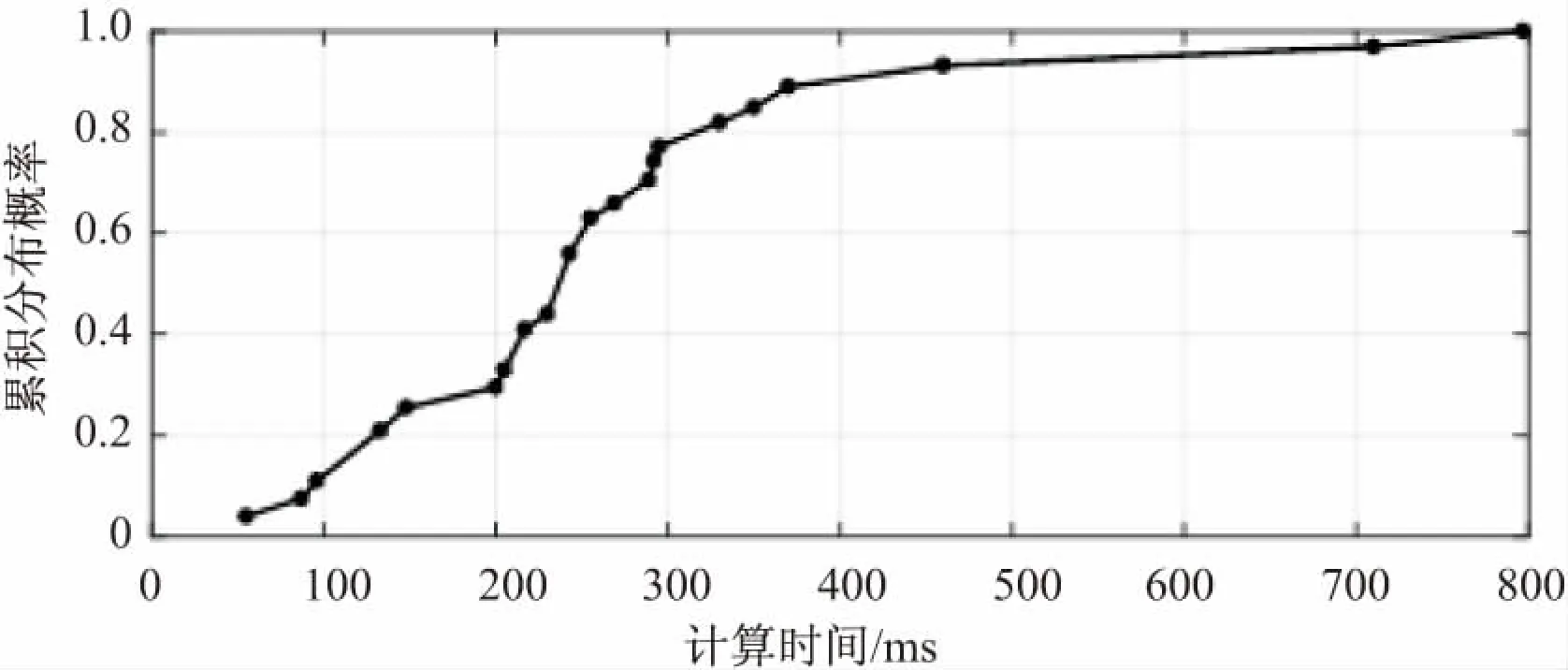
其中,x是哈希种子,常取数为31、131、1 313、13 131、131 313等;Hash[0]=0,1 通过分析,字符串相似性算法在该场景下没有对照对象,无法使用。哈希算法的前提是散列表存储中已经存有该字符串的Hash值,不能用于精确匹配。 对此,文中提出了一种基于树的匹配算法。在树形匹配领域,尤涛根据概率叠加的思想构建前件发生树,大大提高了搜索效率[7]。赵艳妮提出了一种基于有效路径权重的树匹配算法,提高了XML文档的搜索效率[8]。郑津杨提出判决树和自动机相结合的方法对RFID进行分类[9]。张慧颖提出了一种基于DOM子树的数据抽取方法,提高了准确度[10]。 文中提出了基于树形结构的匹配算法,该算法使用Hash算法和基于正则表达式的模糊匹配算法。基于树的匹配算法包含下面几个步骤。首先用Hash算法快速检测当前的标识是否已经存储在数据库中,如果存在返回标识对应结果,否则进入树形匹配过程;接着构建合理的树形模型,减少树的匹配高度,以减少冗余匹配次数;在此基础上使用基于正则表达式的模糊匹配算法,需要将特定的物联网物品标识特征进行分析,提取特征抽象成正则表达式范式;最后对同层次的规则进行信息量优先排序,使用下文提出的匹配流程进行匹配。 正则表达式起源于1951年,当时美国数学家Stephen Cole Kleene用他的数学符号描述正则代数集。这些集合产生于理论计算机科学,自动机理论(计算模型)的子领域以及形式语言的描述和分类。它是提供给计算机操作和检验所要抽取的字符串数据的一种强大的工具,是一串由特定意义的字符组成的字符串,表示某种匹配的规则[11]。正则表达式能够应用在Linux、Windows等多种操作系统中,几乎所有的语言(如PHP、C#、Java)等都支持它。正则表达式用于匹配是非常有效的。丁麟轩提出了一种基于并行字符串索引的多步长正则表达式匹配算法[12],减少了开销,提高了吞吐率。李璋提出一种基于分布式存储的正则表达式匹配并行算法,提高了算法实时性[13]。 常见的正则表达式符号及其含义如表1所示。 表1 常见的正则表达式字符 文中给出Handle、doi、OID编码使用正则表达式的示例。如下: (1)匹配Handle码,Handle编码规范是“Handle前缀/Handle后缀”,则可以使用正则表达式“([a-zA-Z0-9\.]+)/([a-zA-Z0-9\.]+)”。其中“[a-zA-Z0-9\.]”表示包含小写字母、大写字母、数字和.在内的字符,“+”表示前面的符号集出现至少一次,所以整个表达式就是在/前后可以包含至少出现一次的包含字母、数字和.的字符。 (2)匹配Handle码体系下的doi编码,doi编码规范是“doi前缀(10.*) /doi后缀”,则可以使用正则表达式“10\.(\d+)/([0-9a-zA-Z]+)”。其中(\d+)表示至少出现一位数字,([0-9a-zA-Z]+)表示字符(字母或数字)至少出现一次。 (3)匹配OID编码,OID编码规范是“(ITU-T|ISO|Joint-ISO-ITU-T).(国家|标准|注册机构|其他组织).…”,则可以使用正则表达式“[0-2]{1}\.((1?\d)|(2[0-3]))((\.\d+){4,})”。其中[0-2]{1}表示出现0,1,2数字中的一个,(1?\d)表示数字0到19,(2[0-3])表示数字20到23,所以((1?\d)|(2[0-3]))表示0-23。(\.\d+)表示.至少一位数字,{4,}表示表达式(\.\d+)至少出现4次。 为了优化匹配的次数,减少多余的无用匹配次数,通过分析思考和参考数据结构树模型,提出了基于树的匹配算法。在单链表中查找元素的时间复杂度是O(n),n是链表的长度。二叉树中查找元素的平均时间复杂度为O(logn)[14],n是二叉树的节点数。查找的次数大大减少,查找的次数是树的高度(层数)。如果使用线性结构,那么平均匹配次数是n/2,最差匹配次数是n,n是匹配规则的个数。如果构造出合理的树形结构的匹配规则树,平均查找次数是m次,m是构造的树的高度,在n越大时,m远小于n,大大减少了无用的匹配次数,最大程度避免了冗余匹配。构建的规则树如图1所示,由于版面限制,只画出了规则树的部分。查找算法的次数取决于树的宽度和深度,树太宽或者树太深都不能达到很好的效果,结合实际情况,选择合适的宽度将减小匹配次数。 图1 树形模型 为了进一步提高匹配效率,该方法使用了优先级思想。不同类型的物联网物品标识具有不同的特征,例如,不同种类的物联网标识符的长度不同,或者标识含有特殊符号。“规则”用于间接描述物联网物品标识的特征。一个物联网物品标识的每个特征是指一个“规则”。如果一种物联网物品标识具有一个特定的特征,则可以说这种物联网物品标识服从与之对应的“规则”。如果不是,则这种物联网物品标识不符合“规则”。例如,如果一个“规则”被定义为一个特定物联网物品标识的第一个字符为“A”,则一个输入字符串“Abcefg”完全服从上述“规则”。否则,如果物联网物品标识以“B”开始,那么物联网物品标识显然不遵守“规则”。由于不同物联网物品标识之间的先验概率差异以及不同“规则”范围的差异,规则匹配中包含的信息各不相同。例如,如果所有物联网标识符都遵守一个特定的“规则”,则该“规则”的匹配不能提供任何信息,因为事先已经知道匹配结果。为了评估包含在“规则”匹配中的信息,令w为上述信息,然后根据经典信息论[15],如式3: (3) 其中,p为给定物品标识服从规则的概率,q为不符合规则的概率,p+q=1。 算法流程如图2所示。 图2 算法流程 具体步骤如下: 步骤1:从root入口进入规则树,首先通过Hash映射算法,检查数据库中是否已经包含该标识,若存在,则直接返回结果,若无则进入步骤2。 步骤2:对该层的规则进行信息量大小的排序,信息量定义规则如上,信息量大的规则优先匹配。 步骤3:依次匹配排序好的规则序列,若匹配成功,则标记当前成功规则且记为rule1,若遍历全部规则都没有匹配成功,则返回匹配失败。 步骤4:进入rule1的子规则树中,重复执行步骤2、步骤3,循环迭代,若最终匹配成功,返回匹配结果,若失败则将该标识返回上一层。 图3是异构物品标识识别系统的实现框架,包括客户端(client)和服务端(server)。 图3 系统框架 客户端的体系结构由三部分组成:用户界面,程序和数据接口。用户界面呈现查询请求的结果,并为用户输入提供文本输入窗口。程序部分是处理后端传送的数据,为了显示给用户界面,进行一定的预处理,并提高用户体验和结果的准确性。 服务端的体系结构由三部分组成:识别核心服务,特征提取模块,数据库。识别核心服务是整个体系的核心部分,包含匹配树模型的构建和匹配算法。特征提取模块是为识别核心服务提供支持,负责将规则的特征提取出来,构建正则表达式,以及对规则的信息量进行优先级排序。数据库是存放信息数据,可以将已匹配的标识进行缓存,利用Hash算法可以快速检测待输入的数据是否已经存储在数据库中,如果有,将结果直接返回。 文中设计并实施了一些实验来检验系统的性能。实验设置如表2所示。台式机作为服务器,而Lenovo Y580笔记本作为客户端,其中安装了Chrome浏览器。客户端和服务器通过有线局域网连接。 在这个原型系统中,引入了100个物联网物品标识标准,从以下两个方面评估该系统的性能:识别率和识别速度。识别率是在物联网物品标识中成功识别的物联网物品标识的百分比;识别速度意味着花费在识别一个给定物联网物品所花费的时间。从100个标准中随机生成了15 000个实际的物品标识并将其提供给原型系统,实验样例如表3所示。综合识别率接近100%,表明原型算法有效。经过分析,EPC子类出现了极其相似的数据样本,需要进一步提取特征,构建模型。 表2 实验配置 表3 测试样本 此外,计算时间通过以下方式获得。首先,随机选择30个不同的物联网物品标识标准,然后生成每个标准的3个特定物联网物品标识;接下来,将这些生成的物联网物品标识逐个输入系统,并记录从开始到结果出现的时间。计算每个物联网物品标识标准的平均计算时间,并绘制累积分布概率图(见图4)。可以看出,平均计算时间约为280 ms,尽管计算时间需要进一步减少,但这是可以接受的。 图4 计算时间累积分布 如何识别给定物品标识的类型是物联网异构解析系统的一个关键点。针对这个问题,提出了一种基于树的匹配算法的物品标识识别系统。首先对物联网标识标准进行分析,提取出标准的特征,将特征抽象成范式。接着构建树形匹配模型,降低匹配的冗余度,然后对每一层使用信息量优先级排序,最后使用树形匹配算法进行匹配识别。基于上述算法构建了原型系统,实验结果表明该系统不仅识别率高,而且速度快。2 基于树的匹配算法
2.1 正则表达式

2.2 树形匹配模型
2.3 优先级排序
2.4 树匹配算法流程
3 原型系统
3.1 系统框架
3.2 实验环境
3.3 实验结果

4 结束语
猜你喜欢
花卉(2024年1期)2024-01-16 11:29:12
河北果树(2022年1期)2022-02-16 00:41:10
现代园艺(2017年19期)2018-01-19 02:50:30
现代园艺(2017年13期)2018-01-19 02:28:17
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
燕山大学学报(2014年1期)2014-03-11 15:28:11
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
测绘科学与工程(2013年6期)2013-03-11 15:07:57
