
一种时频平滑的深度神经网络语音增强方法
2019-08-20 03:47:26袁文浩梁春燕娄迎曦王志强
西安电子科技大学学报 2019年4期
袁文浩,梁春燕,娄迎曦,房 超,王志强
(山东理工大学 计算机科学与技术学院,山东 淄博 255000)
近年来,随着深度学习技术的发展,基于深度神经网络(Deep Neural Network,DNN)的语音增强受到人们的广泛关注。得益于深度神经网络强大的建模能力,通过对大量含有不同类型噪声的含噪语音样本数据进行训练与学习,该类方法相比传统的基于统计的语音增强方法在低信噪比和非平稳噪声环境下表现出更好的语音增强性能[1-3]。
为了提高基于深度神经网络的语音增强方法的性能,研究人员设计了多种不同的训练目标,并尝试采用不同的网络结构来建立语音增强模型。以含噪语音的理想二值掩码作为训练目标,文献[4]中采用全连接神经网络来训练一个二值分类器,通过对含噪语音中的各个时频单元进行分类得到对纯净语音的估计。文献[5]中采用连续的理想比率掩码代替理想二值掩码作为训练目标,并通过实验验证了:在相同结构的全连接神经网络下,理想比率掩码相比理想二值掩码显著地提升了语音增强模型的性能。为了在基于深度神经网络的语音增强方法中融入对相位信息的估计,文献[6]中设计了一种复数域上的训练目标——复数理想比率掩码,通过训练全连接神经网络同时估计纯净语音复数域特征的实部和虚部,间接实现了对纯净语音幅度和相位的同步估计。与上述基于时频掩蔽的训练目标不同,文献[7-8]直接使用归一化后的纯净语音的对数功率谱作为训练目标,通过训练全连接神经网络建立一个从含噪语音对数功率谱到纯净语音对数功率谱的非线性映射关系。
另外,由于绝大多数的语音增强方法都是针对时频域进行设计的,而语音信号在时间和频率两个维度上表现出来的二维相关性与图像非常类似,因此文献[12-13]中借鉴图像处理领域中广泛应用的卷积神经网络结构来处理语音增强问题。文献[12]中采用全卷积神经网络构造一个编码器-解码器模型来表达含噪语音时频谱和纯净语音时频谱之间的映射关系,由于采用了全卷积神经网络结构,相比全连接神经网络,该模型参数的数量显著减小。文献[13]中采用卷积神经网络建立了一种信噪比感知的语音增强模型,并通过实验验证了卷积神经网络相比全连接神经网络能够更好地提取语音信号的局部时频特征,因而具有更好的语音增强性能。
综合分析已有的基于深度神经网络的语音增强方法,其在网络结构的设计上一般基于图像领域或语音识别中的成功案例,并没有针对语音增强问题自身的特点来设计网络。实际上,不管是传统的基于统计的语音增强方法还是基于深度神经网络的语音增方法,其对含噪语音中语音成分的估计都是基于含噪语音的局部特征;而在时频域中,含噪语音最重要的局部特性就是时频单元之间的相关性[14]。在传统的语音增强方法中,基于含噪语音中的时频相关性,一般通过进行时域和频域的平滑来计算含噪语音的局部特征[15];而在基于深度神经网络的语音增强方法中,为了充分利用含噪语音中的时频相关性来提取局部特征,已有方法往往是通过采用与语音识别相同的对称窗形式的输入来实现的,这种非因果形式的输入对于具有更高实时性要求的语音增强来说,显然是不合适的。
在保证因果性的前提下,为了能够更加充分地利用含噪语音中的时频相关性来提高网络的语音增强性能,笔者借鉴传统语音增强方法中对于含噪语音局部特征的计算方法,在时间和频率两个维度采用两种不同的网络结构实现类似改进的最小控制递归平均中的时频平滑处理[15],设计一种更加适用于语音增强的时频平滑网络结构,并提出一种基于该网络的语音增强方法,最后通过语音增强实验对其性能进行客观评价。
1 基于深度神经网络的语音增强
将基于深度神经网络的语音增强作为一个回归问题进行解决,通过进行网络的训练,得到一个参数集合θ,从而构造含噪语音帧和增强语音帧之间的非线性映射函数fθ。网络的训练通常使用如下的均方误差代价函数:
(1)
其中,Pl是网络的输入,Tl是网络的训练目标,M是网络训练时采用的Mini-batch。为了保证语音增强系统的因果性,只使用l帧的特征作为对第l帧进行语音增强时的网络输入,即
Pl=log(|Yl|2) ,
(2)
其中,|Yl|2是通过短时傅里叶变换计算得到的含噪语音第l帧的功率谱。
目前入侵检测技术是网络安全防御中的一项重要技术,它是一种积极主动安全防护技术。入侵检测技术能够对内部入侵、外部入侵和其他类型的病毒入侵进行及时准确的处理,能够保证在网络系统受到真正的损害之前做出对应的处理操作。随着科技水平的不断提高与发展,入侵检测技术也在朝着智能化的方向发展。入侵检测的主要目的就是发现恶意的网络活动并及时的进行处理,保证网络能够正常的运行。一旦入侵检测系统发现不法网络入侵之后就会及时采取有效的措施来阻断入侵,并及时对不法分子进行定位。
2 时频平滑网络
2.1 时域和频域平滑
基于含噪语音相邻帧和相邻频带之间的相关性,改进的最小控制递归平均算法通过在时间和频率两个维度进行平滑处理来计算含噪语音的局部特征[15]。其中,频域的平滑是通过一个归一化窗来实现的:
(3)

(4)
进一步,通过引入卷积运算,式(3)的频域平滑可以改写为
(5)
这里b可以看成是一个长度为2ω+1的卷积滤波器,在改进的最小控制递归平均算法中被设为一个固定值。
由于语音增强在时间上的因果性,时域的平滑是通过一阶递归平均来实现的:
(6)
其中,αs是平滑参数,在改进的最小控制递归平均算法中同样被设为一个固定的常数。
可见,由于语音增强在频率和时间两个维度上存在的差异,为了计算含噪语音的局部特征,改进的最小控制递归平均算法在两个维度上采用了不同的平滑方法。
2.2 时频平滑网络
受改进的最小控制递归平均算法中的含噪语音特征计算方法启发,在使用深度神经网络进行语音增强时,为了更好地提取含噪语音的局部特征,可以采用具有递归特性的循环神经网络来对含噪语音进行时间维度上的特征平滑,同时采用卷积网络结构来对含噪语音进行频率维度上的特征平滑,通过采用两种不同结构的网络在时间和频率两个维度上建模,实现类似改进的最小控制递归平均算法中的基于时频平滑的特征计算。
传统循环神经网络受限于梯度消失问题,无法对含噪语音在时间维度上的长期依赖关系进行建模;而长短时记忆网络和门控循环单元(Gated Recurrent Unit,GRU)由于采用了门控机制,能够有效地缓解梯度消失问题,更适合用来对含噪语音在时间上的相关性进行建模。由于门控循环单元相比长短时记忆网络性能相近但结构更加简单,因此笔者以门控循环单元中的门控机制和递归结构为基础,构造一种能够同时在时间和频率两个维度上进行含噪语音特征平滑的时频平滑网络(Time-Frequency Smoothing Network,TFSN)。

在频率维度上,与门控循环单元中门控单元的计算方法不同,时频平滑网络通过对输入进行卷积来计算更新门和重置门:
Zl=σ(WZ*Hl-1+UZ*Xl+bZ) ,
(7)
Rl=σ(WR*Hl-1+UR*Xl+bR) ,
(8)
其中,“*”表示卷积运算,WZ、WR、UZ、UR分别表示相应的卷积滤波器,bZ、bR分别表示相应的偏置项,σ表示Sigmoid激活函数。
同样,单元状态的更新也是通过对输入进行卷积运算得到的
(9)
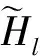
在时间维度上,时频平滑网络的基本单元间的时序关系与门控循环单元一致,是由更新门控制的递归过程:
(10)
对比式(6)与式(10),可知,时频平滑网络采用由频域特征计算得到的平滑参数代替式(6)中的αs,实现了类似改进的最小控制递归平均算法的时域平滑。
3 基于时频平滑网络的语音增强

图1 基于时频平滑网络的语音增强方法框图
为了利用时频平滑网络进行语音增强,设计了具有3层结构的时频平滑深度神经网络,网络的各层均为卷积滤波器个数为64的时频平滑网络基本单元,卷积滤波器的长度均为9,如图1所示。在进行模型训练时,以最小化公式(1)中的代价函数C(θ)为训练目标,以含噪语音和相应纯净语音的对数功率谱分别作为网络的输入和输出。为了保持训练过程的稳定,输入和输出均进行均值方差归一化处理;在语音增强时,将归一化处理后的含噪语音对数功率谱输入到训练好的网络中,网络的输出即为增强语音的对数功率谱。
4 实验与结果分析
4.1 训练集与测试集
为了构造包括含噪语音和相应纯净语音的训练集,采用TIMIT语音库的训练集作为纯净语音数据的来源[16],采用文献[17]中的100类真实噪声作为噪声数据的来源。训练集的合成方法如下:首先,从纯净语音数据中随机选取一段语音,并从噪声数据中随机选取一段噪声;其次,将语音段和噪声段的采样频率均转换为8kHz;然后从-10dB、-5dB、0dB、5dB和10dB五种信噪比中随机选择一种,并按照该信噪比将语音段和噪声段合成含噪语音;最后,重复上述过程,得到包含50 000段含噪语音和相应纯净语音的训练集。
为了构造测试集,采用TIMIT语音库的测试集作为纯净语音数据的来源,采用Noisex92噪声库作为噪声数据的来源[18]。测试集的合成方法如下:首先,从噪声库中选择不同于训练集噪声的4类未知噪声,即N1(Factory2)、N2(Buccaneer1)、N3(Destroyer engine)和N4(HF channel);其次,将语音数据中的所有语音段和全部噪声段的采样频率均转换为8kHz;然后,按照-7dB、0dB和7dB三种信噪比将192段语音和4类噪声合成含噪语音(-7dB和7dB是与训练集不同的未知信噪比);最后,得到包含2 304(192×3×4)段含噪语音和相应的纯净语音的测试集。
训练集和测试集中计算对数功率谱特征所用的短时傅里叶变换的帧长均设为32ms(256点),帧移均设为16ms(128点),所得的对数功率谱特征维度为129。
4.2 评价指标
通过对测试集中的含噪语音进行语音增强,并对增强语音进行客观评估来衡量网络的语音增强性能。采用的增强语音客观评价指标包括语音质量感知评估(Perceptual Evaluation of Speech Quality,PESQ)[19]和短时客观可懂度(Short Time Objective Intelligibility,STOI)[20]。其中语音质量感知评估是国际电信联盟电信标准化部推荐的语音质量评估指标,其得分在-0.5和4.5之间,得分越高,表示增强语音的质量越好;短时客观可懂度是语音可懂度的评价指标,其得分在0和1之间,得分越高,表示增强语音的可懂度越好。
4.3 网络性能比较
为了验证时频平滑网络在语音增强上的有效性,将其与全连接神经网络和门控循环单元这两种常用于语音增强的网络进行对比。所用的全连接神经网络和门控循环单元同样具有3层结构,其中全连接神经网络每层的隐层节点数为1 024,门控循环单元的Cell维度为512;两种网络的训练同样使用式(1)中的代价函数C(θ),并且为了保持语音增强系统的因果性,两种网络的输入和输出同样是单帧的含噪语音对数功率谱和相应的纯净语音对数功率谱。
表1和表2分别给出采用全连接神经网络、门控循环单元和时频平滑网络对训练集含噪语音进行处理后,得到的4类噪声和3种信噪比下增强语音的平均语音质量感知评估和平均短时客观可懂度,并给出了含噪语音的平均语音质量感知评估和平均短时客观可懂度作为对比。可见,首先,在低信噪比噪声条件下,全连接神经网络增强后语音的平均语音质量感知评估相比含噪语音的更差。在全部的噪声条件下,全连接神经网络增强后语音的平均短时客观可懂度相比含噪语音的更差。这表明:由于全连接神经网络缺乏对时间维度上的序列信息进行建模的能力,当采用单帧的含噪语音特征作为输入时,全连接神经网络无法利用含噪语音相邻帧间的相关性,从而不能进行有效的语音增强。其次,在所有噪声条件下,门控循环单元增强后语音的平均语音质量感知评估和平均短时客观可懂度相比含噪语音的和全连接神经网络的均有明显提高。这表明:门控循环单元通过对含噪语音中的长期依赖关系进行建模,在对某一帧进行语音增强时,能够充分利用该帧与其之前帧间的相关性,具有了较好的语音增强性能。最后,在大多数噪声条件下,时频平滑网络增强后语音的平均语音质量感知评估和平均短时客观可懂度相比门控循环单元的均有明显提高。这表明:时频平滑网络通过同时进行时间维度和频率维度上的特征平滑,充分利用了两个维度上的相关性,相比门控循环单元进一步提高了语音增强性能。
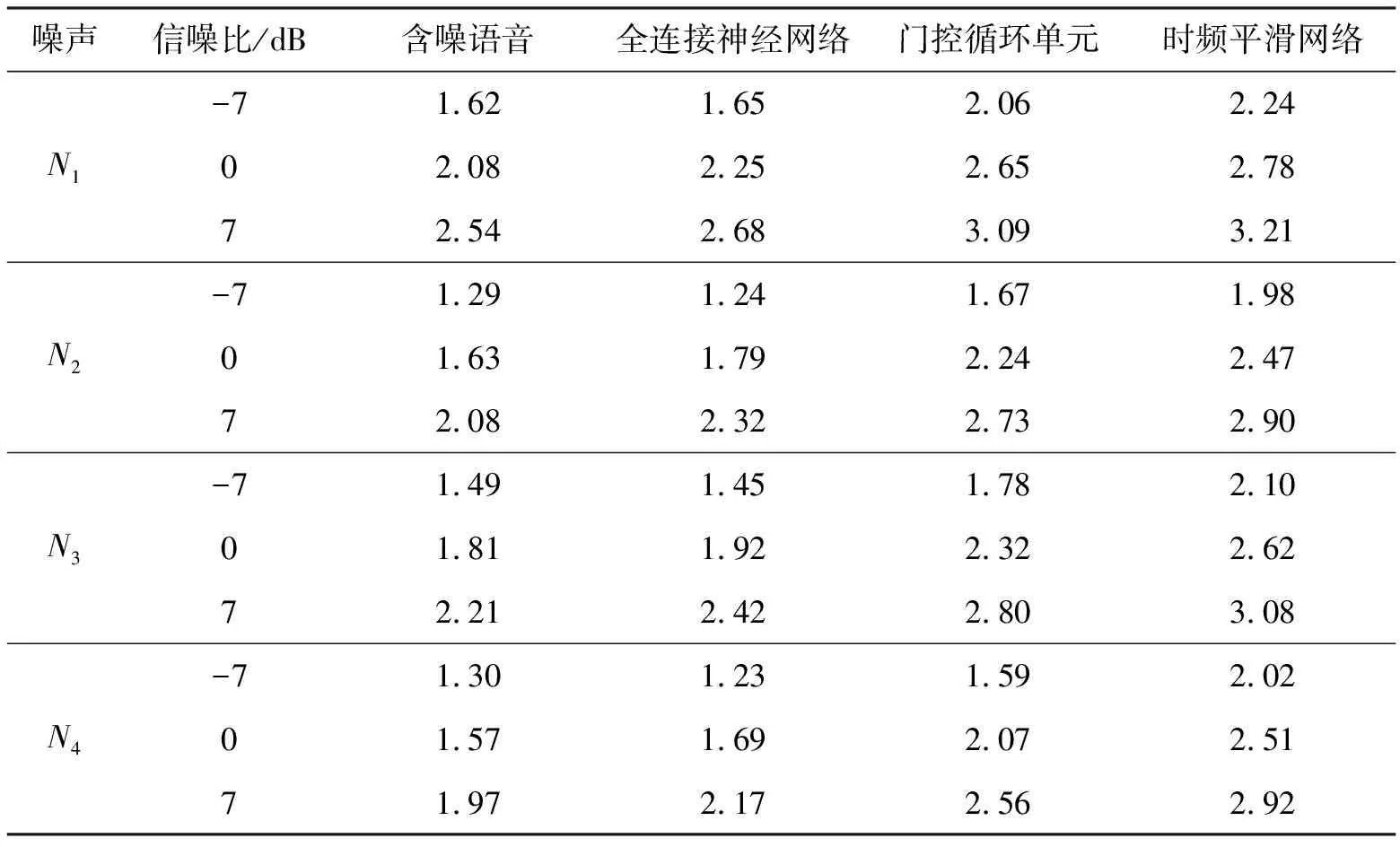
表1 不同网络增强语音的平均语音质量感知评估
为了进一步对比不同网络的语音增强性能,对3种网络增强后语音的语谱图进行直观分析。图2(a)给出一段含有N3噪声,信噪比为0 dB的含噪语音的语谱图;图2(b)~(d)分别给出了使用全连接神经网络、门控循环单元和时频平滑网络增强后语音的语谱图;图2(e)给出了原始纯净语音的语谱图。通过对比纯净语音的语谱图可见,全连接神经网络增强后的语音中仍然包含有大量的残留噪声成分,门控循环单元增强后的语音同样包含明显可见的残留噪声成分,而时频平滑网络增强后语音的残留噪声成分要明显少于全连接神经网络和门控循环单元的,其语谱图与纯净语音的语谱图最为接近,表明时频平滑网络相比其他两种网络具有更好的语音增强性能,这与客观评价的结果是一致的。

表2 不同网络增强语音的平均短时客观可懂度

图2 不同网络增强语音的语谱图对比
另外,由于卷积网络结构的参数共享特性,在上述的3种网络结构中,时频平滑网络的参数规模要远小于门控循环单元和全连接神经网络的。如表3所示,时频平滑网络的参数量大约是门控循环单元的38.57%,大约是全连接神经网络的68.64%。

表3 不同网络的参数规模比较
5 总 结
借鉴传统语音增强在时间和频率两个维度上采用不同的平滑方式来计算局部特征的方法,笔者在利用深度神经网络进行语音增强问题的建模时,采用门控循环神经网络结构来进行时域平滑,同时采用卷积网络结构来进行频域平滑,设计了一种时频平滑网络结构,并提出了基于时频平滑网络的语音增强方法。实验结果表明,笔者提出的时频平滑网络相比全连接神经网络和门控循环单元,在参数规模更小的前提下,明显提高了增强语音的语音质量和可懂度,具有更好的语音增强性能。然而,由于卷积运算相比乘积运算更为复杂,笔者所设计的网络结构虽然参数规模更小,但是运算速度并没有提高。下一步将针对基于深度神经网络的语音增强方法的处理速度进行深入研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
舰船科学技术(2015年8期)2015-02-27 15:38:48
电测与仪表(2014年17期)2014-04-04 11:56:48
电视技术(2014年19期)2014-03-11 15:38:20
